python循环导入
介绍
之前在刚开始接触flask的时候,就碰到了循环引用的问题。问题是这样的
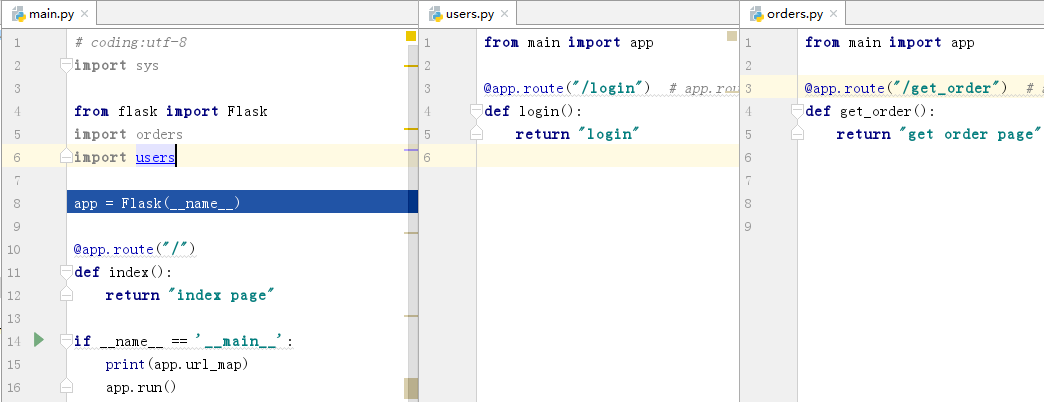
运行main.py,结果报错

如果注释掉任意一行import的代码
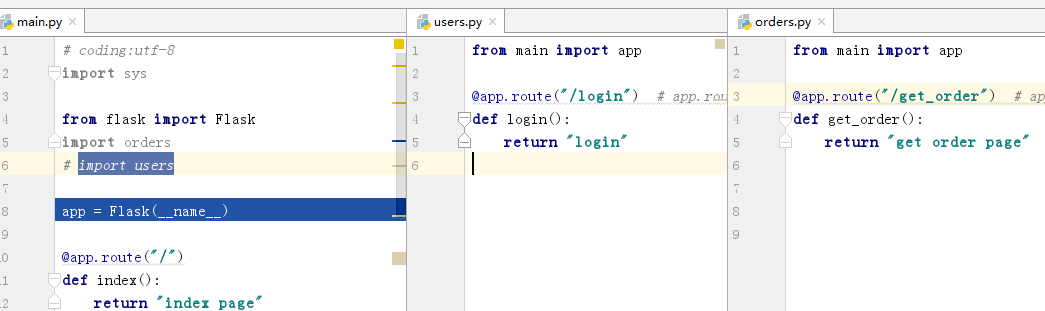
结果就是正确的了

回顾包
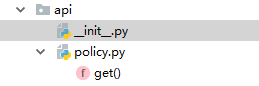
在__init__文件里面增加一个和外面py文件名相同的函数

此时在api这个包的外面这样调用:from api import policy 此时调用的是函数,如果把函数注释,此时调用的是api包里的名为police.py的文件
对于一个包而言,可以先这样简单地理解:__init__里定义的变量加上包里其他的py文件都是这个包的属性,如果__init__定义的变量和包里的
py文件重名,则以__init__里的优先。
绝对导入和相对导入
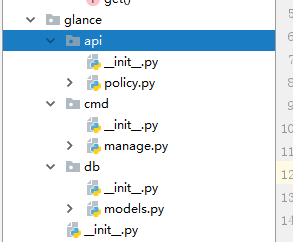
文件内容
#文件内容
#policy.py
def get():
print('from policy.py')
#manage.py
def main():
print('from manage.py')
#models.py
def register_models(engine):
print('from models.py: ',engine)
想使用glance这个包的时候, 可以通过from ... import ... 的方式一层层去寻找。但是如果直接通过import导入就有问题,因为我们只是import 文件夹,此时这个文件夹和里面的py文件并没有建立关系,或者说文件夹里的所有
py文件并没有被python解释器解释加载到内存中,既然没有加载到内存中又怎么可以使用呢。所以在import glance的时候就应该让包里的所有py文件都被python解释器解释一遍(也就是运行一遍)。
认识包的时候应该对比着模块的相关内容来理解。import 模块 的时候会创建响应的名称空间把模块执行一遍,import 包的时候 会创建响应的名称空间执行里面的__init__方法。所以在每个包里的__init__动点手脚,如下

# 在于glance同级的test.py中就可以这样来使用
import glance
glance.cmd.manage.main()
上面导入的方式是相对导入,相对导入的优点是把这个包移动到其他位置,里面的代码不需要更改,只需要在外层调用的时候把调用路径更改一下就行。这里再补充一句:执行一个py文件,在里面导入包的时候,先查看sys.modules里有没有这个包,没有就从当前执行的py文件的sys.path里去寻找包,找不到就报错。相对导入的缺点是如下:
我在glance包的api包的policy文件里面想使用glance包的cmd包的manage的东西
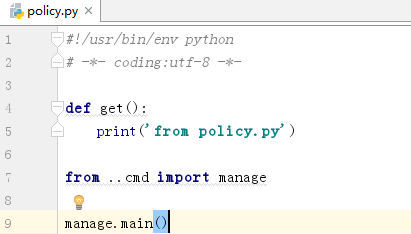
单独执行policy.py会报错

这是因为单独执行这个文件的时候 ..不清楚是什么,或者说在下一层直接裸奔是不认识..这种方式,通过..找不到对应的目录。
但是如果在glance包的外面的test.py直接调用import glance就不会报错,因为这个导入是从上到下,有glance这个根目录,从上到下的时候.和..都会记住对应的位置。
这就是相对导入的缺点,但是这也不是很大的问题,因为我们在使用一个包的时候往往是在外面调用而不是单独去执行里面的一个py文件。
绝对导入

此时test.py和glance是同一级目录,执行test.py的时候,是以test.py去计算sys.path,所以以绝对导入包的时候绝对路径应该以test.py所在目录为根目录。如果此时把glance整个
包移动到和test.py同级的xxoo目录,那么glance包里的__init__文件的导入路径就需要更改了,这是绝对导入的缺点。优点是导入清晰,而且不存在相对导入出现的在一个单独
的py文件导入别的包内容执行这个py文件会报错的情况
glance/
├── __init__.py from .api import *
from .cmd import *
from .db import *
├── api
│ ├── __init__.py __all__ = ['policy','versions']
│ ├── policy.py
│ └── versions.py
├── cmd __all__ = ['manage']
│ ├── __init__.py
│ └── manage.py
└── db __all__ = ['models']
├── __init__.py
└── models.py
import glance
glance.policy.get()
其实我是这样理解__all__ 和 from ... import *的: from ... import *从__all__里拿到字符串,然后通过反射去相应的对象里去找相关属性
import本质
看上面问题之前,先来看一下下面的问题
[A.py]
from B import D
class C:pass
[B.py]
from A import C
class D:pass
为什么执行A的时候不能加载D呢?如果将A.py改为:import B就可以了。这是怎么回事呢?
这跟Python内部import的机制是有关的,具体到from B import D,Python内部会分成几个步骤:
- 在sys.modules中查找符号"B"
- 如果符号B存在,则获得符号B对应的module对象
从<module B>的__dict__中获得符号"D"对应的对象,如果"D"不存在,则抛出异常 - 如果符号B不存在,则创建一个新的module对象
,注意,这时,module对象的__dict__为空
执行B.py中的表达式,填充的__dict__
从的__dict__中获得"D"对应的对象,如果"D"不存在,则抛出异常
所以,这个例子的执行顺序如下:
1、执行A.py中的from B import D
由于是执行的python A.py,所以在sys.modules中并没有<module B>这个dict。
2、执行B.py中的from A import C
在执行B.py的过程中,会碰到这一句, 首先检查sys.modules这个module缓存中是否已经存在<module A>了, 由于这时缓存还没有缓存<module A>, 所以类似的,Python内部会为A.py创建一个module对象(
3、再次执行A.py中的from B import D
这时,由于在第1步时,创建的<module B>, 但是,注意,从整个过程来看,我们知道,这时<module B>还是一个空的对象,里面啥也没有, 所以从这个module中获得符号"D"的操作就会抛出异常。 如果这里只是import B,由于"B"这个符号在sys.modules中已经存在,所以是不会抛出异常的。
flask循环导入分析
知道了import的本质之后,我们就能看出最开始提出的问题所在了。
- main.py: 执行import order,此时在sys.modules字典里面创建一个key为“order”的字符串,value是一个空对象,这时就需要去执行order的代码,去填充这个对象
- order.py: 执行from main import app,此时在sys.modules字典没有main,所以创建一个key为“main”的字符串,value是一个空对象.这时就需要去执行main的代码,去填充这个对象
- main.py: 执行import order,发现sys.modules字典有order,继续往下走,import user,此时在sys.modules字典里面创建一个key为“user”的字符串,value是一个空对象,这时就需要去执行user的代码,去填充这个对象
- user.py: 执行from main import app,此时在sys.modules字典有main,那么从main对应的对象拿app,因为这个对象还是空的(main.py还没构建完成),所以拿东西的时候出现错误
那么问题又来了,去掉任意一个import之后虽然不报错,但是路由只有main.py的路由生效,import的并没有生效,这又是为什么呢?明明在users.py里面已经用app.route进行路由绑定了呀?


从上面两个图就能看出端倪,在user.py进行绑定的app是m这个名称空间里的,而实际运行的app却是__main__里面的,通过debug模式可以比较清晰地看到user.py的app.route其实就是在import user里面做的,在import user执行完毕之后,__main__里面继续往下走,这时候走到app=Flask(name),这时__main__名称空间才第一次创建app这个对象,而user.py的app.route的app并不是__main__里的app对象,而是m这个名称空间的对象

