
SpringMVC框架简介(详细)
第一步:
1. SpringMVC框架简介
1.1.SpringMVC框架作用:
SpringMVC框架:主要解决了VC之间的交互问题!
V—>C:如何通过界面,把请求交给服务器中的控制器;
C—>V:控制器接收到客户端发来的请求,最终控制器还会给界面响应,所以用户会看到页面。
1.2.MVC是什么?
MVC = Model(数据模型) + View(视图) + Controller(控制器)
注意:在SpringMVC框架中,并不关心M的问题!
MVC是设计程序的一种思想(不是一种技术,只是一种思想),它认为在一个项目当中,至少应该有这3种角色的分工,比如说一种角色,我们把它称之为View,那么它表示的是:你的软件的界面,你的项目中应该有一波文件是专门用来处理软件界面的,就像之前学的Html,就是专门用来做页面的。View—>Html。
另外,还应该有一些文件,是专门用来做控制器的,控制器是什么,具体表现为Servlet,Servlet的作用:接受客户端的请求并且给与相应,客户端发一个请求到服务器,就有Servlet被运行起来了,然后找个Servlet会执行里面的doGet()或者doPost()方法,最后,给出一个页面,给到客户端去,作为响应方式,控制器主要就是做这个的。Controller—>Servlet。
然后,除了控制器以外,我们认为在一个项目中,还应该有 Model,即:数据模型,数据模型是一个略大一点的概念,其中它有一部分是Dao,比如UserDao就归属于数据模型。Model—>Dao。
这就体现了一种分工合作思想,也会提高项目的管理和维护。
1.3.为什么学习SpringMVC框架?
在传统的Java EE开发模式下,是使用Servlet组件作为项目的控制器,假设项目中有“用户注册”的功能,则可能需要创建UserRegServlet,如果还有“用户登录”功能,则可能需要创建UserLoginServlet,以此类推,每增加1个新的功能,就需要开发一个新的Servlet,如果某个项目中有100个功能,就需要开发100个Servlet,如果有500个功能,就需要开发500个Servlet。而且,每个Servlet可能还需要添加相关的配置,所以,一旦Servlet的数量过多,就会不利于管理和维护,并且,在服务器运行时,需要创建很多Servlet类的对象,会消耗较多的内存空间。另外,Java EE的许多API并不简洁,在使用时并不是那么方便。
使用SpringMVC框架,以上问题都可以被解决。
2. SpringMVC核心组件(5个)
-
DispatcherServlet:前端控制器,用于接收所有请求;(最先接受请求,所以叫前端控制器)
-
HandlerMapping:处理器映射器,用于配置请求路径与Controller组件的对应关系;
-
Controller:控制器,具体处理请求的组件;
-
ModelAndView:Controller组件处理完请求后得到的结果,由数据与视图名称组成;
-
ViewResolver:视图解析器,可根据视图名称确定需要使用的视图组件。
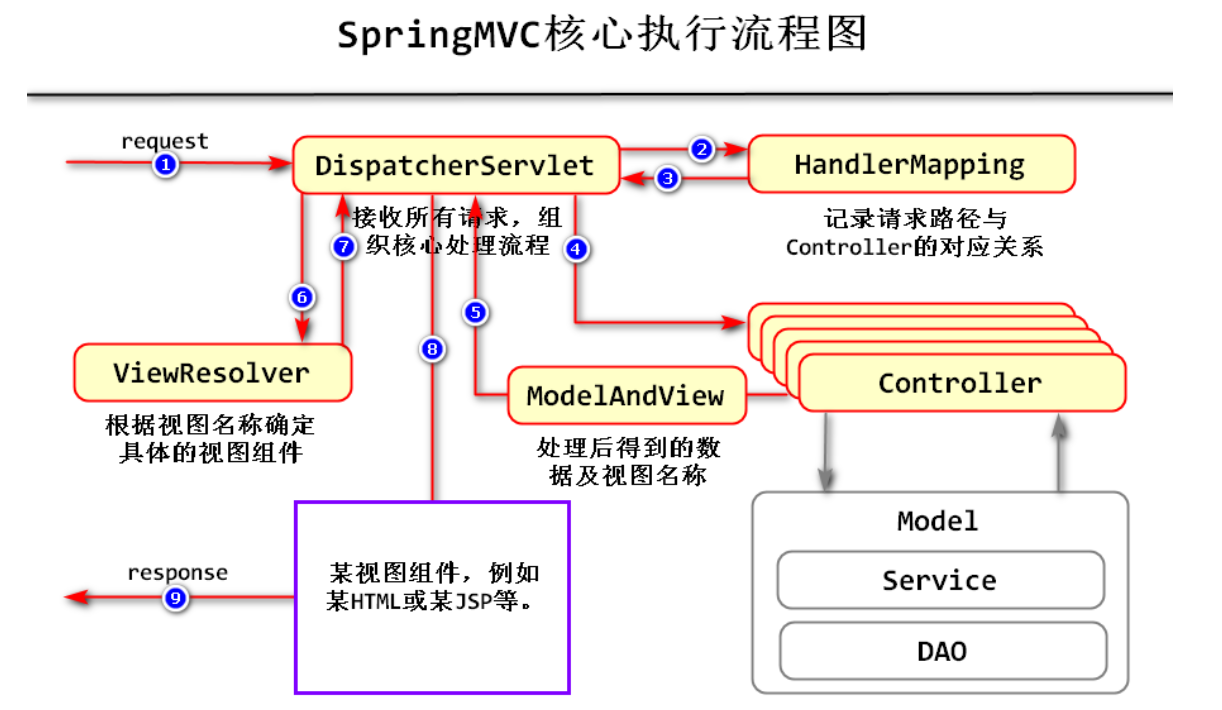
整个执行流程:
在SpringMVC中,所有请求被一个DispatcherServlet收到,然后再交给不同的Controller去处理这些请求,这个Controller(控制器)是写项目的时自己创建的,DispatcherServlet是不用创建的,是已经有的,一个项目中,我们会创建N个Controller,一个Controller负责处理N个请求。
那么什么样的请求被分到哪个Controller去处理呢?那就要用到HandlerMapping:他记录了请求路径与Controller的对应关系,就是说哪个网址的请求交个哪个控制器处理,是HandlerMapping专门来记录的。
在Controller实际的处理过程中,肯定会涉及到数据的访问,数据的增删改查,所以Controller会去找Model(数据模型),就是MVC里面的M,Model是分两个角色,一个是Service一个是DAO,但是Model这个环节不是SpringMVC所讨论的内容,所以图上是灰色。假设控制器把请求都处理好了,它就会返回一个结果,这个结果的类型就是ModelAndView,所以其实ModelAndView是Controller的返回结果,它表示的是处理后得到的数据和视图名称,这个Model表示的是数据,而View表示的是视图名称,所以第5步是返回这个结果。
但是第5步,返回的是视图的名称,而不是某个视图,返回的不是某个Html页面,返回的只是这个页面的名称的代号,这时DispatcherServlet看到这个返回的结果,但不知道是什么的,但是它会去问ViewResolver,即:视图解析器,可根据视图名称确定需要使用的视图组件,然后ViewResolver给DispatcherServlet一个答案,然后DispatcherServlet就可以找到视图组件,即第7步,然后第8、9步给与客户端响应。
整理后,SpringMVC流程为:
第一步:用户发送请求request [rɪˈkwest]到前端控制器DispatcherServlet。
第二步:前端控制器 请求 处理器映射器HandlerMapping查找 **Handler **(可以根据xml配置、注解进行查找)。
第三步:处理器映射器HandlerMapping向 前端控制器DispatcherServlet 返回 执行链对象HandlerExecutionChain。
执行链对象:一个Handler处理器+多个HandlerInterceptor拦截器对象
HandlerMapping会把请求映射为HandlerExecutionChain执行链对象(包含一个Handler处理器(页面控制器)对象,多个HandlerInterceptor拦截器对象),通过这种策略模式,很容易添加新的映射策略。
第四步:前端控制器调用处理器适配器HandlerAdapter去执行Handler。
第五步:处理器适配器在Handler处理器中执行Handler,Handler处理器就是平常所说的Controller控制器,是具体处理请求的组件。
第六步:Handler执行完成后,由控制器Controller给适配器HandlerAdapte返回ModelAndView。(数据模型和视图)
第七步:处理器适配器向前端控制器返回ModelAndView (ModelAndView是springmvc框架的一个底层对象,包括 Model和view)。
第八步:前端控制器请求视图解析器ViewResolver去进行视图解析 (根据逻辑视图名解析成真正的视图(jsp)),通过这种策略很容易更换其他视图技术,只需要更改视图解析器即可。
第九步:视图解析器向前端控制器返回View。
第十步:前端控制器进行视图渲染 (视图渲染将模型数据(在ModelAndView对象中)填充到request域)。
第十一步:前端控制器向用户响应结果(response )。
注意:
1.在SpringMVC框架中,会讨论到有两种控制器,DispatcherServlet前端控制器和Controller控制器,一般明确的说前端控制器,就是指DispatcherServlet,如果只是说控制器的话,就是指Controller。
2.上图是核心执行流程图,也就说它在执行过程中也会涉及到其他的组件,但是那些不是最核心的。
小知识:
每一个servlet必须在web.xml中,最少由8行代码来配置:
web.xml
<servlet>
<servlet-name></servlet-name>
<servlet-class></servlet-class>
</servlet>
<servlet-mapping>
<servlet-name></servlet-name>
<url-pattern></url-pattern>
</servlet-mapping>
3. SpringMVC HelloWorld
(此为:springmvc01项目)
3.1. 案例目标
当项目启动后,打开浏览器,输入http://localhost:8080/项目名称/hello.do网址,可以在浏览器中显示指定的内容!
3.2. 创建SpringMVC项目(5步)
1.创建Maven Project
创建Maven Project,在创建过程中,勾选Create a simple project,Group Id值为cn.tedu,Artifact Id为springmvc01,Packging必须选择war。
Group Id的作用:如果项目是独立运行的,那么Group Id的作用基本上没有。但是如果你的项目是需要被其他的项目所依赖,因为每次添加依赖的时候,都有<dependency>节点,在这个节点中,通过<groupId>和<artifactId>来决定要用的是哪个依赖,所以你的项目如果要被别的项目依赖的话,那别人就要知道你的<groupId>,否则就引用不了。
2.生成小奶瓶,即web.xml文件
创建好项目后,首先需要生成web.xml(小奶瓶),
3.在pom.xml中添加spring-webmvc依赖:
注意,依赖变了,不是spring-context而是spring-webmvc。
先手敲一个:
<dependencies>
</dependencies>
然后在这个<dependencies>中写:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>5.1.6.RELEASE</version>
</dependency>
</project>
在使用
spring-webmvc时,推荐使用4.2或以上版本。
注意:一个Maven项目中,只能有一个<dependencies>节点,然后添加的若干个依赖,全部往这个子级节点中加。
4.复制spring.xml文件
由于SpringMVC框架是基于Spring框架的,所以,之前学的Spring阶段的知识,在SpringMVC中都会被用上,所以,需要从前序项目中复制spring.xml文件到当前项目中,并删除原有的配置。
5.关联汤姆猫
项目右键——点击属性(Properties)——查找Targeted Runtimes
3.3. 配置DispatcherSerlvet(在web.xml中)【核心组件中的第1个组件】
1.配置第1步: 配置DispatcherSerlvet
根据上面的执行流程图,一个请求过来了,第一个工作的就是DispatcherSerlvet,所以首先让它工作起来。
而因为配置一个Serlvet必须在web.xml中,最少需要8行代码,所以如下:
为了保证DispatcherServlet能正常工作,首先,需要在src/main/webapp/WEB-INF中的web.xml中添加配置:在</welcome-file-list>结束之后补充代码:
<servlet>
<servlet-name>SpringMVC</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>SpringMVC</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
配置DispatcherSerlvet讲解:
1.两个<servlet-name>,内容不重要,主要要保持名称上下一致,即表示对同一个servlet的配置。为了不冲突,一般用servlet的类的名称(即:DispatcherServlet)来命名,而偷懒的用法是命名为:SpringMVC,因为在用SpringMVC框架的时候,用到的servlet只有这一个。
2.<url-pattern>表示的是:什么路径的请求,会被这个servlet所处理。对应的是用户访问服务器的时候,输入的网址。
3.*.do:通配符,通配所有。所有请求后缀为.do的请求发过来,就会被servlet处理。
用do,一是控制器发送到服务器的请求,有一定行为的处理,做了某些事情,do表示干活,做事的意思,二,也是选择do的主要原因,是因为平时在电脑中用文件的时候,没有哪个文件是以.do做扩展名的,所以在正常情况下没有人用的名字做扩展名就行。
所以,后续任何以.do结尾的请求,会被我们的SpringMVC框架处理,会走正常流程。
4.<servlet-class>,意思是servlet类,要写上servlet类的名字,显然,配置的是DispatcherServlet,所以类名是DispatcherServlet,但是这里要在前面写上包名。
不知道一个类的包名的做法:
可以在test中,建立一个类,在里面声明要查询包名的类,然后导包,复制即可。
例如:
package cn.tedu.spring;
import org.springframework.web.servlet.DispatcherServlet;
public class Demo {
DispatcherServlet ds;
}
注意不要复制import和空格和分号。复制后,可以按住Ctrl键来看有没有横线。
2.配置第2步:为加载Spring的配置文件,配置初始化参数
由于SpringMVC框架是基于Spring框架的,就需要加载Spring的配置文件,在DispatcherServlet类的父类FrameworkServlet类中,定义了名为contextConfigLocation属性,该属性的值就应该是Spring配置文件的路径,一旦指定了该属性值,当DispatcherServlet被创建时,就会自动读取所配置的文件!
(此为SpringMVC框架的工作特征之一)
查找源代码:
/** Explicit context config location. */
显式上下文配置位置,其实就是指定Spring配置文件的路径,这个路径默认是没有值的,但你只要给了它值,它就会自动的去读你所配置的文件。
@Nullable
private String contextConfigLocation;
属性是字符串类型的。
所以,需要在<servlet>中补充配置以上contextConfigLocation属性的值:
在第一个<servlet>节点中的子级中添加节点<init-param>:
<init-param>表示的是:初始化参数。
然后在<init-param>中添加两个节点:
<param-name>:初始化的参数的名称——属性名;
<param-value>:初始化的参数的值,就是Spring配置文件的名字:spring.xml,而这个文件在resources下面,所以前面加上classpath:(注意后面是冒号,不是点),这个classpath:依然表示的是resources文件夹。表示这个文件在resources文件夹下面,叫spring.xml。
<servlet>
<servlet-name>SpringMVC</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:spring.xml</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>SpringMVC</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
当Spring去创建DispatcherServlet对象的时候,就会去读这个classpath:spring.xml配置文件了,那么Spring什么时候创建DispatcherServlet对象呢?
Servlet的机制是,只要有请求过来,Tomcat就会创建它的对象。而在项目启动之后,并且Tomcat已经成功运行之后,但是还没有客户端发请求过来,那么DispatcherServlet就不会被new出来,只有第一次有某个请求(.do)过来才回去创建对象,这就像懒加载模式,但是这样是不对的。
因为现在DispatcherServlet加载spring.xml的配置文件,这个配置文件应该是配置一些软件运行环境,都是一些非常基础的配置,它应该在项目启动的时候就把这些环境准备好,而不是有请求来时才准备好,所以这个spring.xml还应该在项目启动时就被读取。
3.配置第3步:将DispatcherServlet配置为启动即初始化:
这个spring.xml还应该在项目启动时就被读取,使得项目启动就加载Spring的环境,所以,还应该将这个DispatcherServlet配置为启动即初始化:
所以添加<load-on-startup>1</load-on-startup>,这里的1表示的是true或者ok的意思,即:是否是启动的时候就加载了,是。(翻译:load:加载,on:当...的时候,startup:启动)
最终的web.xml中的最后配置为:
<servlet>
<servlet-name>SpringMVC</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:spring.xml</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>SpringMVC</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
经过配置后,由于存在<load-on-startup>1</load-on-startup>,所以,当Tomcat启动时,就会初始化DispatcherServlet,由于配置了初始化参数(<init-param>系列节点),所以,初始化后就会立即加载spring.xml文件!
网摘<load-on-startup></load-on-startup>知识点:
在servlet的配置当中,
5 的含义是:标记容器是否在启动的时候就加载这个servlet。当值为0或者大于0时,表示容器在应用启动时就加载这个servlet;当是一个负数时或者没有指定时,则指示容器在该servlet被选择时才加载。正数的值越小,启动该servlet的优先级越高。
- load-on-startup标记容器是否在启动的时候实例化并调用其init()方法的优先级。
- 它的值表示 servlet应该被载入的顺序。
- 当值为0或者大于0时,表示容器在应用启动时就加载并初始化这个servlet。
- .如果值小于0或未指定时,则表示只有在第一次请求的容器才在该servlet调用初始化函数。
- 正值越小,servlet的优先级越高,应用启动时就越先加载。
- 值相同时,容器就会自己选择顺序来加载。
4.检验配置是否正确:
接下来,可以检验以上配置是否正确。
1.先在spring.xml中添加组件扫描:
<context:component-scan base-package="cn.tedu.spring" />
2.然后,在组件扫描的包中创建任意类,并在类的构造方法中添加输出语句:(syst)
package cn.tedu.spring;
import org.springframework.stereotype.Component;
@Component
public class User {
public User() {
System.out.println("User.User()");
}
}
因为Tomcat启动时,会加载spring.xml,就会执行组件扫描,在扫描的包中找到User类,同时,因为User添加了@Component注解,所以,Spring框架就会创建User类的对象,导致User类的构造方法被执行,其中的输出语句就会被执行!
简单来说,就是Tomcat启动时,可以看到以上构造方法中输出的内容!
5.初次启动项目on Server
找到Servers面板,右键,选择Add and Remove,先把要执行的项目从左侧添加到右侧去,然后Finish。
然后回到Servers面板,点击右上的绿色播放键(Start the server)。
最后,会输出出现:User.User()。
6.注意:排版并不是ctrl+a和ctrl+i。
ctrl+i:不是排版的快捷键,它的正确描述是:修正缩进。
在Source中,correct indentation的快捷键就是ctrl+i,而correct indentation翻译过来就是正确缩进。
但是format排版不一样,排版还会帮助确定空白行,该有空白行的时候有空白行,多余的删掉。
3.4. 使用Controller处理客户端提交的请求【核心流程2、3、4】
SpringMVC底层执行原理上,是会走这个DispatcherServlet—>HandlerMapping流程,但是在实际编写代码时是不需要编写HandlerMapping的。那么不写,怎么确定请求路径和Controller控制器对应关系?那就在Controller控制器中通过注解解决这个问题。
所以如果自己写代码的时候,就直接写到第4步:Controller控制器,而不需要写HandlerMapping的类或者配置的。
所以,用控制器Controller实际处理用户请求:Controller控制器,在SpringMVC框架中是我们自己写的。所以:
1.创建HelloController控制类:
先在组件扫描的cn.tedu.spring包下创建HelloController控制类(该类的名称没有特殊要求,也不需要继承自指定的父类,或实现特定的接口。):
但是取名字的时候,只要是控制器,都会以Controller作为名称的后缀,规范的开发一般都是这样处理。
package cn.tedu.spring;
public class HelloController {
}
控制器类的命名
在组件扫描的cn.tedu.spring包下创建XXXXController类型的控制类时候,命名要注意:
在SpringMVC中,一个控制器内是可以写多个处理请求的方法的,一般都会放一起,比如与用户相关的,不管是登陆、注册还是改密码等,都放在UserController中所以,与用户相关的,都放在UserController里来。
如果现在要处理另外的数据,比如是一个博客系统,那就创建一个博客Controller,把发表博客、删除博客等请求的方法都放在这个控制器中。
所以,命名时,Controller是后缀,前缀用要处理的数据类型来表示,比如是用户数据,就是UserController,至于是哪种处理方式,则由里面的方法来决定。
2.添加@Controller注解:
控制器类必须添加@Controller注解!注意:不可以使用@Compontent、@Service、@Repository注解!即:
package cn.tedu.spring;
import org.springframework.stereotype.Controller;
@Controller
public class HelloController {
}
3.在类中添加处理请求的方法:
然后,应该在类中添加处理请求的方法!请求发过来,控制器类中有个方法被执行。
关于方法的声明原则:
- 应该使用
public权限;(因为一个请求过来,方法被执行,不是自己调用的,是被别人调用的) - 暂时使用
String作为返回值类型; - 方法的名称可以自定义;
- 方法的参数列表暂时留空。
所以,可以在以上控制器类中添加方法:
package cn.tedu.spring;
import org.springframework.stereotype.Controller;
@Controller
public class HelloController {
public String showHello() {
System.out.println("HelloController.showHello()");//为了能看到运行效果,加输出语句syst
return null; // 暂且返回null值,避免代码持续报错
}
}
4.使用@RequestMapping注解配置请求路径:
最后,在处理请求的方法之前,使用@RequestMapping注解配置请求路径,以绑定请求路径与方法的对应关系:(这个注解实现的作用就是流程图中HandlerMapping应该做的事情,这种关系是一种的绑定的关系。)
package cn.tedu.spring;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
@Controller
public class HelloController {
@RequestMapping("hello.do")//接受hello.do的请求,就会调用紧随其后的showHello这个方法
public String showHello() {
System.out.println("HelloController.showHello()");
return null; // 暂且返回null值,避免代码持续报错
}
}
注意:在控制台如何找到Tomcat占用端口号?
1.控制台上输出的:信息: 初始化协议处理器 ["http-nio-8080"]这个表示Tomcat占用的是8080端口。
2.请求方法中,如果返回的为null,等同于返回路径名,也就是是把@RequestMapping("reg.do")里面的reg.do路径取出来去掉.do,返回的就是reg,但是强烈不推荐这么做。
@RequestMapping("reg.do")
public String showReg() {
System.out.println("UserCoSntroller.showReg()");
return null;//如果此处返回null,等同于返回路径名,但是强烈不推荐
}
5.输入网址进行测试:
完成后,重新启动Tomcat,在浏览器中输入http://localhost:8080/springmvc01/hello.do进行访问,在浏览器的窗口将无法正常显示页面(因为没有做页面),在Eclipse的控制台中可以看到以上方法输出的内容,并且,如果在浏览器中刷新,将会提交多次请求,则Eclipse的控制台可以看到多次输出内容!
6.报错处理:
6.1.Tomcat报错怎么看?
当Tomcat报错的时候,肯定是看控制台,如果控制台中有LifecycleException这个异常,表示生命周期错误,这个异常是完全没有参考价值的!
但是如果出现ZipException,则jar包一定是有损坏的。看Maven Dependencies中,所有jar包文件都在.m2文件夹中,那就把这个.m2文件夹删掉,让它全部重新下载就行了。这个异常就是.m2文件夹中,某一个jar包或者多个jar包坏掉了。
6.2.如果代码没有问题却运行不对:
1.Project——Clean:项目清理一下;
2.Servers——Clean:把Tomcat清理一下。
3.如果两个都Clean了,还是不行,就把Tomcat删了,然后重新添加回来再试。注意,养成好习惯,Tomcat删了,左侧对应项目列表中的Servers也跟着一起删。
要是删了还不好用,可以更改重新添加Tomcat的版本。
到现在,根据SpringMVC核心执行流程图,已经到第4步了。下面是第5步和第6步。
3.5. 显示页面【核心流程第5、6步】
在SpringMVC中,响应给客户端的View可以是多种,例如JSP、Thymeleaf中的HTML模版页面等(就像讲的,PDF都行)……
1.在pom.xml中添加依赖(2个)
首先,应该确定所使用的页面技术,例如本次将使用Thymeleaf,则需要先在pom.xml中添加thymeleaf和thymeleaf-spring4相关的依赖:
(因为JSP目前属于淘汰阶段的一个技术,Thymeleaf就属于是JSP的替代品。)
还是上http://www.mvnrepository.com/这个网站,搜索thymeleaf和thymeleaf-spring4查找。
<!-- 这两个依赖是成套出现的,并且版本是完全对应的。 -->
<dependency>
<groupId>org.thymeleaf</groupId>
<artifactId>thymeleaf</artifactId>
<version>3.0.7.RELEASE</version>
</dependency>
<dependency>
<groupId>org.thymeleaf</groupId>
<artifactId>thymeleaf-spring4</artifactId>
<version>3.0.7.RELEASE</version>
</dependency>
添加依赖后,在Java Resources——Libraries——Maven Dependencies中有两个thymeleaf开头的jar包。
2.创建一个HTML页面
然后,在项目中,创建一个HTML页面,作为最终显示给客户端的页面,作为Thymeleaf的模版页面,应该放在/webapp/WEB-INF/下,或者,放在src/main/resorces/下,本次选择将HTML模版页面放在src/main/resources/下,所以,先在src/main/resources/下创建名为templates的文件夹(templates:模板。建这个文件夹是为了以后更规范的管理,搜索Folder),并在该文件夹中创建helloworld.html页面(名字自定义,随便起。右键templates,选择Html File,注意选择的文件夹是不是templates。),并且自定义页面的内容!例如:
注意:为什么要放在WEB-INF或者resorces文件夹下?
如果直接放在webapp下面,这个HTML页面是别人直接敲一个网址就能打开的,就不经过控制器了。
但是一般我们用Thymeleaf的话,更多是希望先从控制器过,也许控制器还会产生一次数据,把这些数据丢到页面上去显示,比如在Servlet里面可能产生一些数据,这些数据最终会被显示到页面上。例如:用户列表页面,应该是先通过Servlet调用Dao进行数据的查询,得到了数据,然后把数据显示在页面,最后客户端能够看到,
所以,一般来说,Thymeleaf的模版页面,是不应该放在公共直接可以访问的位置,也就是说不会直接放在webapp下面,而webapp下面的WEB-INF是一个非常特殊的文件夹,是直接访问是访问不到的,同理,resorces也是直接访问是访问不到的。
注意:创建helloworld.html页面,new HTML的时候,要点一下resorces。注意选择的文件夹是不是templates,因为默认创建文件的位置在webapp。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Hello, SpringMVC!!!</title>
</head>
<body>
<h1>欢迎使用SpringMVC框架!</h1>
</body>
</html>
3.更改请求方法的返回值
然后,打开HelloController控制器类,处理请求的方法的返回值改为"helloworld",也就是这个页面文件的文件名,但不包含.html,即:
package cn.tedu.spring;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
@Controller
public class HelloController {
@RequestMapping("hello.do")
public String showHello() {
System.out.println("HelloController.showHello()");
return "helloworld"; // 此处返回的就是HTML页面的文件名
}
}
4.在spirng.xml中补充配置
接下来,需要在spirng.xml中补充一系列配置:这配置不用背,是固定的配置。下面这些配置,工作时,都是复制粘贴的。
这些配置是要做什么的:
Controller返回一个字符串,SpringMVC怎么知道去templates文件夹去找,这就需要下面的配置:
配置步骤3: 配置模版解析器。这里配置了 value="/templates/" 这个文件夹的路径。
<!-- 配置模版解析器(有多种) -->
<!-- 当使用ClassLoaderTemplateResolver时,将以src/main/resources作为根文件夹 -->
<!-- 当使用ServletContextTemplateResovler时,将以webapp作为根文件夹 -->
<bean id="templateResolver" class="org.thymeleaf.templateresolver.ClassLoaderTemplateResolver">
//要配置ClassLoaderTemplateResolver父类中的5个属性:
<property name="characterEncoding" value="utf-8" />字符编码
<property name="templateMode" value="HTML" />模板模式
<property name="cacheable" value="false" />可缓存(不缓存,缓存页面易出问题)
<property name="prefix" value="/templates/" />前缀
//前缀指的是你的HTML页面放到哪个文件夹下面的,现在是以/resources为基础来放的
//注意:templates的两边/ 不能省略
<property name="suffix" value=".html" />后缀
//后缀:指文件的扩展名
//其实,最终工作的时候,会用前缀/templates/拼接上控制器返回的名字helloworld
//再拼接上后缀.html,从而得到这个文件到底是谁。
//src/main/resources/???
//src/main/resources/前缀(prefix) 返回值 后缀(suffix)
//src/main/resources/templates/helloworld.html
//相当于字符串的拼接
//所以也可以前缀和后缀都不写,但控制器返回的名字为:
//return "templates/helloworld.html";
</bean>
配置步骤2:配置模版引擎
<!-- 配置模版引擎 -->
<bean id="templateEngine" class="org.thymeleaf.spring4.SpringTemplateEngine">
<property name="templateResolver" ref="templateResolver" />
//templateResolver叫模板解析器,是SpringTemplateEngine父类中的一个属性
//但是没有模板解析器,所以还要在上面配置一个模板解析器
</bean>
【配置步骤1:配置视图解析器,也就是流程中的第6步:找ViewResolver:视图解析器】
<!-- 配置视图解析器 针对Thymeleaf的模版页面的ViewResolver(视图解析器)来配置 -->
<bean class="org.thymeleaf.spring4.view.ThymeleafViewResolver">//包名
//配置ThymeleafViewResolver的两个属性(只能看官方文档或者别人的博客文章,就是固定的)
//其一:只要看到characterEncoding(字符编码),就设置成utf-8
//其二:templateEngine(模板引擎),但是现在没有模板引擎,所以要先配置一个模板引擎出来
//这个属性的值,希望是上面的<bean>
<property name="characterEncoding" value="utf-8" />
<property name="templateEngine" ref="templateEngine" />
</bean>
注意:如果Eclipse意外关闭,但其中的Tomcat没有关闭,那么就找到用的Tomcat的位置,比如我的:D:\Tomcat\apache-tomcat-9.0.30\bin,在bin文件夹中找到shutdown.bat文件,运行即可。
或者重启电脑。
5.最后运行一下,测试
完成后,重新启动Tomcat,在浏览器中输入http://localhost:8080/springmvc01/hello.do进行访问,是可以看到刚才做的页面的。
3.6.小结:
一、创建SpringMVC项目,有5件事情要做:
1.小奶瓶:生成web.xml
解决小奶瓶的问题,也就是生成web.xml(WEB-INF文件夹下)
2.pom.xml中添加依赖
从之前的pom.xml中复制依赖,之前项目里面是3个依赖:
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>5.1.5.RELEASE</version>
</dependency>
<dependency>
<groupId>org.thymeleaf</groupId>
<artifactId>thymeleaf</artifactId>
<version>3.0.7.RELEASE</version>
</dependency>
<dependency>
<groupId>org.thymeleaf</groupId>
<artifactId>thymeleaf-spring4</artifactId>
<version>3.0.7.RELEASE</version>
</dependency>
<!-- 这两个依赖是成套出现的,并且版本是完全对应的。 -->
</dependencies>
3.复制spring.xml配置文件
复制过来后,里面的配置不用改,因为都是固定的,如果需要调整,可以根据自己来调整。
4.勾选Tomcat
点击项目右键——点击属性(Properties)——查找Targeted Runtimes ,勾选对应的Apache Tomcat版本
翻译:Targeted Runtimes :目标运行时
5.复制web.xml中的配置代码
找到之前项目的web.xml文件(src/main/webapp/WEB-INF中的web.xml),把之前关于DispatcherSerlvet配置的代码复制到新的项目中:
在</welcome-file-list>结束之后补充代码:
<servlet>
<servlet-name>SpringMVC</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:spring.xml</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>SpringMVC</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
注意:每次复制粘贴的时候,只复制所需要的代码,不要全选复制,因为项目名称什么的都不一样。
二、在依赖上添加注释,知道以后可以改哪些配置
1.在pom.xml中添加注释:
<dependencies>
<!-- SpringMVC (用SpringMVC框架的时候就必须要加这个依赖)-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>5.1.5.RELEASE</version>
</dependency>
<!-- Thymeleaf -->
<dependency>
<groupId>org.thymeleaf</groupId>
<artifactId>thymeleaf</artifactId>
<version>3.0.7.RELEASE</version>
</dependency>
<!-- Thymeleaf整合Spring (能够通过Spring能够更快捷的去配置和操作Thymeleaf)-->
<dependency>
<groupId>org.thymeleaf</groupId>
<artifactId>thymeleaf-spring4</artifactId>
<version>3.0.7.RELEASE</version>
</dependency>
</dependencies>
2.在web.xml中:配置DispatcherServlet的,可能修改的地方有2个:
<!-- 修改处(1/2):param-value节点:指定Spring配置文件的位置 -->
<servlet>
<servlet-name>SpringMVC</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<init-param>
<param-name>contextConfigLocation</param-name>
修改处1:
<param-value>classpath:spring.xml</param-value>
</init-param>
<load-on-startup>1</load-on-startup><!-- 1表示true,即启动就加载 -->
</servlet>
<!-- 修改处(2/2):pattern节点:映射的路径,即:接收哪些路径的请求 -->
<servlet-mapping>
<servlet-name>SpringMVC</servlet-name>
修改处2:
<url-pattern>*.do</url-pattern>
</servlet-mapping>
3.spring.xml的配置文件中,可能修改处有3个:
<!-- 修改处(1):组件扫描,配置要扫描的根包(以后可能会修改,可能根包会不一样) -->
<context:component-scan
base-package="cn.tedu.spring" />
<!-- 配置模版解析器 -->
<!-- 当使用ClassLoaderTemplateResolver时,将以src/main/resources作为根文件夹 -->
<!-- 当使用ServletContextTemplateResovler时,将以webapp作为根文件夹 -->
<!-- 修改处(2):prefix将结合控制器方法的返回值、suffix的值确定View文件的位置 -->
<bean id="templateResolver"
class="org.thymeleaf.templateresolver.ClassLoaderTemplateResolver">
<property name="characterEncoding" value="utf-8" />
<property name="templateMode" value="HTML" />
<property name="cacheable" value="false" />
<!-- 修改处(2-1):前缀。即此处以后可能会修改 -->
<property name="prefix" value="/templates/" />
<!-- 修改处(2-2):后缀。即此处以后可能会修改 -->
<property name="suffix" value=".html" />
</bean>
4.springmvc02项目
案例目标:希望通过设置两个网址并访问,一个网址可以打开一个用户注册的页面,另外一个网址可以打开用户登陆的页面。
创建SpringMVC项目的5步骤做完之后,要写一个控制器的类,然后在里面写方法,配置请求路径等操作,然后还需要写两个HTML页面,先后写无顺序,一般先写页面比较直观些。
所以先做页面:
1.还是在src/main/resources(resources:资源)中新建一个templates的文件夹,在templates文件夹中,右键新建HTML File文件,用户注册页面,命名为reg.html,如下:
reg.html:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>用户注册</title>
</head>
<body>
<h1>用户注册</h1>
<form>
<table>
<tr>
<td>用户名</td>
<td><input /></td>
</tr>
<tr>
<td>密码</td>
<td><input /></td>
</tr>
<tr>
<td>年龄</td>
<td><input /></td>
</tr>
<tr>
<td>手机号码</td>
<td><input /></td>
</tr>
<tr>
<td>电子邮箱</td>
<td><input /></td>
</tr>
<tr>
<td colspan="2"><input type="submit" value="注册" /></td>
</tr>
</table>
</form>
</body>
</html>
2.然后希望发送请求到服务器,来显示这个页面,在src/main/java,这个写java类的地方,new一个UserController类(注意控制器类的命名),包的名字写成cn.tedu.spring。
UserController类中代码:
package cn.tedu.spring;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
@Controller
public class UserController {
// http://localhost:8080/springmvc02/reg.do
@RequestMapping("reg.do")
public String showReg() {
System.out.println("UserController.showReg()");
return "reg"; // 如果此处返回null,等同于返回路径名,但是,强烈不推荐
}
}
启动Tomcat,运行一下,输入网址试试能不能打开页面。
3.除了实现用户的注册,还要实现用户的登录,在写第二个页面,还是在src/main/resources底下的templates文件夹中,复制reg.html粘贴一下,然后重命名为login.html,然后更改里面的代码:
login.html:Ctrl+f,把注册全部替换成登录。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>用户登录</title>
</head>
<body>
<h1>用户登录</h1>
<form>
<table>
<tr>
<td>用户名</td>
<td><input /></td>
</tr>
<tr>
<td>密码</td>
<td><input /></td>
</tr>
<tr>
<td colspan="2"><input type="submit" value="登录" /></td>
</tr>
</table>
</form>
</body>
</html>
4.希望能打开这个页面,则还是在类UserController中,加上方法处理相关的请求,还是复制之前的方法,然后更改即可:
最后,类UserController完全版:
package cn.tedu.spring;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
@Controller
public class UserController {
// http://localhost:8080/springmvc02/reg.do
@RequestMapping("reg.do")
public String showReg() {
System.out.println("UserController.showReg()");
return "reg"; // 如果此处返回null,等同于返回路径名,但是,强烈不推荐
}
//注意,如果返回的是:return "reg111";返回的名称拼不出一个有效的文件出来,没有对应的文件
//就会出现500错误。
// http://localhost:8080/springmvc02/login.do
@RequestMapping("login.do")
public String showLogin() {
System.out.println("UserController.showLogin()");
return "login";
}
}
启动Tomcat,运行一下,输入网址试试能不能打开页面。
5.如果想让注册页面和登录页面两个页面实现跳转,则在注册页面添加:已注册?则直接<a href="login.do">登录</a>。最后呈现的注册页面代码:
reg.html:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>用户注册</title>
</head>
<body>
<h1>用户注册</h1>
<form>
<table>
<tr>
<td>用户名</td>
<td><input /></td>
</tr>
<tr>
<td>密码</td>
<td><input /></td>
</tr>
<tr>
<td>年龄</td>
<td><input /></td>
</tr>
<tr>
<td>手机号码</td>
<td><input /></td>
</tr>
<tr>
<td>电子邮箱</td>
<td><input /></td>
</tr>
<tr>
<td colspan="2"><input type="submit" value="注册">已注册?则直接<a href="login.do">登录</a></td>
</tr>
</table>
</form>
</body>
</html>
第二步:
1. 接收客户端提交的请求参数
1.1. 使用HttpServletRequest接收请求参数(不推荐使用)
1.1.1注册页面reg.html添加代码
以注册为例,要使得客户端(网页)能够向服务器端(控制器,例如UserController)提交注册数据(就是填写用户名、密码之类的数据),首先,注册页面中的各个控件(例如输入框等)都必须配置name属性,以表示提交的数据的名称,因为服务器端不知道数据叫什么名字,就取不出来;并且,这些控件都必须在同一个<form>中,这个<form>还必须指定action属性,表示数据将提交到哪里去,取值应该是服务器端的某个URL,例如:
handle:表示处理的意思。
<form action="handle_reg.do">
<table>
<tr>
<td>用户名</td>
<td><input name="username" /></td>
</tr>
<tr>
<td>密码</td>
<td><input name="password" /></td>
</tr>
<tr>
<td>年龄</td>
<td><input name="age" /></td>
</tr>
<tr>
<td>手机号码</td>
<td><input name="phone" /></td>
</tr>
<tr>
<td>电子邮箱</td>
<td><input name="email" /></td>
</tr>
<tr>
<td colspan="2"><input type="submit" value="注册" /> 已注册?则直接<a href="login.do">登录</a></td>
</tr>
</table>
</form>
注意:之前学习的时候,在<form action="handle_reg.do">中,还有个属性是method,这个method叫(数据的)请求方式或者提交方式,常用的提交方式是在get和post中选取,默认的方式是get,但是get在注册的时候是不合适的。这里先不写,先不管。
数据将提交到:handle_reg.do这个URL中。
1.1.2参数列表中添加参数,调用getParameter()方法
接受请求参数,在SpringMVC中有好几种做法,有一种做法就和以前接受请求参数一样:以前在学Servlet阶段,接受请求参数的做法,就是需要一个request,通过这个request对象,去调用它的getParameter("")方法,即:request.getParameter("");去获取请求参数。但是现在没有这个request,没有怎么办?这就是SpringMVC很任性的一点,没有,但是需要,那么就在参数列表中添加HttpServletRequest request,该导包导包,如果导不了包,项目右键加入Tomcat就行。
这个HttpServletRequest是由Tomca提供的,只要有客户端往服务端发了请求,这个请求就会被Tomcat收到,而Tomcat收到客户端的请求后,就会把整个的请求封装为一个request的对象,SpringMVC框架在运行过程中,根据流程图,request请求被Tomcat收到后,Tomcat就会找,由DispatcherServlet来处理,拿request对象来调用DispatcherServlet,DispatcherServlet就会进一步把这个request去调用控制器Controller里面的方法。
String username = request.getParameter("username"); 这句代码中,等号左边的是自己取得变量名,等号右边的,getParameter方法里,括号内的值,就是之前reg.html里面的name属性的值。一般提倡的做法是,你描述的是同一个数据,就使用同样的名字,不需要区分开。
这个地方就是一个固定的方式来写。
笔记:在控制器中,接收请求参数时,可以在处理请求的方法的参数列表中添加HttpServletRequest接口类型的参数,在处理请求的过程中,调用该参数对象的String getParameter(String 参数名称)方法来获取请求参数,例如:在UserController中添加:
// http://localhost:8080/springmvc02/handle_reg.do
@RequestMapping("handle_reg.do")
public String handleReg(HttpServletRequest request) {
//没有request,就在参数列表中添加,这就是SpringMVC任性的地方。
System.out.println("UserController.handleReg()");
//有5个参数,所以写5个
String username = request.getParameter("username");
// 调用getParameter()方法,其中括号中的参数就是请求参数的名称,也就是页面各输入框的name值
String password = request.getParameter("password");
Integer age = Integer.valueOf(request.getParameter("age"));
/*
* 由于是年龄,用String就不合适了,所以用Integer,但是getParameter的返回值就是字符串,
* 所以等号左侧的类型换为Integer,但此时等号右侧没有强制类型转换选项,无法转换。
*
* 那么这时等号右侧可以用Integer包装类的静态方法paseInt,把整个字符串作为参数放进去,
* 所以代码可以写成:
* Integer age = Integer.parseInt(request.getParameter("age"));
*
* paseInt方法就是转换的方法,它的参数要求是把一个字符串类型的数据作为参数,返回的是int值
*
* 在java语言中的编程,除非要调用方法等特殊地方,否则,因为有自动拆装箱机制的存在,
* Integer和Int是可以混为一谈的。
* 但是这里强烈建议不使用paseInt方法,而是用Integer.valueOf方法
* Integer age = Integer.valueOf(request.getParameter("age"));
* 因为valueOf方法,虽然也是使用字符串作为参数,但是它的返回值是Integer,而parseInt方法
* 返回的是Int,这就是它们的区别。
*
* 强烈建议在等号的两侧尽量的保持一致,尽管有自动拆装箱的机制,如果类型一致的话,就不用拆箱或者
* 装箱了,这是更加合理的做法。
*
*/
String phone = request.getParameter("phone");
String email = request.getParameter("email");
System.out.println("username=" + username);
System.out.println("password=" + password);
System.out.println("age=" + age);
System.out.println("phone=" + phone);
System.out.println("email=" + email);
return null; // 相当于返回"handle_reg",最后,会打开handle_reg.html页面,此页面目前并不存在,在浏览器中会提示500错误,暂时不关心这个问题。
}
然后运行一下,然后在浏览器中打开http://localhost:8080/springmvc02/reg.do网址,最好刷新一下,怕浏览器有缓存,是前几天的效果,也可以右键查看源代码,看代码是不是跟刚刚改过的一致。如果还不行,就要清除浏览器缓存了。注意:测试的时候不要用中文,要用英文。测试成功后,可以再换中文。
输入注册信息,在控制台可以看到输入的5个数据。
这种做法一般是不推荐使用的!主要原因有:
- 接收参数的过程比较麻烦;
- 如果期望得到的数据的类型不是
String,则需要自行解决数据类型的数据; - 不便于执行单元测试。
1.2. 将请求参数声明为处理请求的方法的参数
(处理请求的方法就是handleReg方法)
当你需要一个来自客户端提交的用户名的时候,在public String handleReg(String username) {}方法的括号(方法参数)中就写一个username,就可以了,以此类推,密码、年龄都可以写上,只要保证:这些参数的名称与reg.html中的name属性保持一致即可。所以:
笔记:可以将所需要接收的请求参数直接声明为处理请求的方法的参数,甚至,期望得到的数据是什么类型,就直接声明为对应的类型即可,例如:
// http://localhost:8080/springmvc02/handle_reg.do
@RequestMapping("handle_reg.do")
public String handleReg(String username, String password,
Integer age, String phone, String email) {
System.out.println("UserController.handleReg()");
System.out.println("[2] username=" + username);//前面加[2],表示第2种做法
System.out.println("[2] password=" + password);
System.out.println("[2] age=" + age);
System.out.println("[2] phone=" + phone);
System.out.println("[2] email=" + email);
return null; // 相当于返回"handle_reg",最后,会打开handle_reg.html页面,此页面目前并不存在,在浏览器中会提示500错误,暂时不关心这个问题
}
使用这种做法时,需要保证名称的一致,即客户端提交的请求参数的名称,与处理请求的方法的参数名称需要是一致的!
提交的数据类型必须是可以被转换的类型。如果将某些数据声明为非String类型,例如以上代码中的Integer age,就需要客户端必须提交正确的参数,因为SpringMVC会自动完成类型转换,如果客户端提交的值是"aaa"这种无法转换的值,或没有填写年龄值就相当于提交了一个空字符串"",就会导致转换失败!
1.3. 将请求参数封装为自定义的数据类型
这种做法是解决1.2方法的不足。
当请求参数较多时,可以将这些请求参数封装在自定义的数据类型中,例如:
1.新写一个类User
public class User {
//统一加上私有的
private String username;
private String password;
private Integer age;
private String phone;
private String email;
// 通过Eclipse或其它开发工具,自动生成所有属性的SET/GET方法,自动生成toString()方法
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
@Override
public String toString() {
return "User [username=" + username + ", password=" + password + ", age=" + age + ", phone=" + phone + ", email=" + email + "]";
}
}
需要注意:各属性的名称需要与请求参数的名称保持一致,并且,每个属性都有规范名称的SET/GET方法!其本质是SpringMVC框架要求SET/GET方法的名称与请求参数能对应!
2.然后,在处理请求的方法的参数列表中,直接将自定义数据类型添加到参数列表中即可:
@RequestMapping("handle_reg.do")public String handleReg(User user) { System.out.println("UserController.handleReg()"); System.out.println(user); return null; // 相当于返回"handle_reg",最后,会打开handle_reg.html页面,此页面目前并不存在,在浏览器中会提示500错误,暂时不关心这个问题}
1.4. 小结
使用HttpServletRequest接收请求参数的做法肯定是不推荐的,以后再也不要这样用了!第一个做法废弃了。
用第3种做法:(这种效率/性能要比第2种要低一点,但是更利于维护,这里不讨论性能问题。)
当请求参数的数量较多(通常>=5个)时,或者,请求参数本身或数量可能发生变化时,优先使用封装的做法,也就是以上1.3的做法,以保证处理请求的方法的声明是不需要调整的;
写代码的宗旨:强烈不推荐修改方法的声明!
用第2种做法:
当请求参数的数量较少(通常<=3个)时,并且,请求参数是相对固定的,优先使用直接声明为方法的参数的做法,也就是以上1.2的做法。
另外,以上1.2和1.3介绍的2种方式是可以同时使用的!(并不互相排斥)例如:用户注册时,还需要填写验证码,很显然,验证码不应该是用户的属性之一,所以,在用户数据的User类中不会有验证码属性,在设计处理请求的方法的参数列表时,可以使用User用于接收客户端提交的用户数据,另使用一个参数用于接收客户端提交的验证码!
2. 控制器向页面转发数据
2.1. 使用HttpServletRequest转发数据
没有处理后续的页面,所以写一个登录页面:login.html,写上两个name和一个action。
<!DOCTYPE html><html><head><meta charset="UTF-8"><title>用户登录</title></head><body> <h1>用户登录</h1> <form action="handle_login.do"> <table> <tr> <td>用户名</td> <td><input name="username" /></td> </tr> <tr> <td>密码</td> <td><input name="password"/></td> </tr> <tr> <td colspan="2"><input type="submit" value="登录"></td> </tr> </table> </form></body></html>
假设,在处理登录时,能够判断用户名、密码是否正确,例如:
模拟登录:假设root/1234是正确的用户名/密码
(equals方法:常量写在左侧来调用equals,变量写在参数里面。)
// http://localhost:8080/springmvc02/handle_login.do@RequestMapping("handle_login.do")public String handleLogin(String username, String password) { //因为只有用户名和密码,所以用第2种方法 System.out.println("UserController.handleLogin()"); System.out.println("username=" + username); System.out.println("password=" + password); // 模拟登录:假设root/1234是正确的用户名/密码 // 先判断用户名 if ("root".equals(username)) {//常量写在左侧来调用equals,变量写在参数里面。 // 用户名正确,还需要判断密码 if ("1234".equals(password)) { // 密码也正确,则登录成功,暂且不处理,依然显示500 } else { // 密码错误,登录失败 return "error"; } } else { // 用户名错误,登录失败 return "error"; } return null;}
然后,创建对应的error.html用于显示错误信息!
在templates文件夹中new一个HTML File页面:
error.html
<!DOCTYPE html><html><head><meta charset="UTF-8"><title>操作错误</title></head><body><h1>操作错误</h1></body></html>
然后,登录http://localhost:8080/springmvc02/handle_login.do网址,输入用户名和密码来测试。
正确是500,只要错误了,就都是操作错误。
但是,在error.html不适合直接编写错误信息的描述,因为如果是不同的错误原因导致的,则描述就应该不相同!这些描述应该是由控制器去组织语言,然后,把这些数据转发到error.html,而error.html就只负责数据的呈现即可!
这时候页面是无法显示到底是什么错误的,所以我们希望从控制器这里来描述错误的原因,然后在error这里只负责显示错误的信息就可以了。控制器中把一句话,比如字符串,传到error.html里面去,这就是转发,控制器向页面转发。转发数据也有几种做法,即2.1、2.2、2.3。
当需要转发数据时,1.在控制器的处理请求的方法的参数列表中添加HttpServletRequest类型的参数,2.然后,在需要转发数据时,调用该参数对象的setAttribute(String name, Object value)方法将数据进行封装即可,例如:
首先需要封装转发的数据:
// http://localhost:8080/springmvc02/handle_login.do@RequestMapping("handle_login.do")public String handleLogin(String username, String password,HttpServletRequest request) { System.out.println("UserController.handleLogin()"); System.out.println("username=" + username); System.out.println("password=" + password); // 模拟登录:假设root/1234是正确的用户名/密码 // 先判断用户名 if ("root".equals(username)) { // 用户名正确,还需要判断密码 if ("1234".equals(password)) { // 密码也正确,则登录成功,暂且不处理 } else { // 密码错误,登录失败 //首先需要封装转发的数据: String msg = "密码错误"; request.setAttribute("errorMessage", msg); //所以就是往request中封装了这样的一个数据:封装进去给它取得名字叫errorMessage, //值就是上面的字符串:msg。 //相当于把数据放进去,(Message:消息)。 return "error"; } } else { // 用户名错误,登录失败 //首先需要封装转发的数据: String msg = "用户名不存在"; request.setAttribute("errorMessage", msg); return "error"; } return null;}
以上代码中,调用setAttribute()方法时,第1个参数"errorMessage"是自定义的名称,后续,在页面中将根据这个名称来获取数据!由于该名称会应用到Thymeleaf表达式中,所以,不可以使用表达式的非法字符,例如不可以使用减号-,否则会被表达式误解读为某个减法运算!
然后,在Thymeleaf的模版页面中,在需要显示数据的位置,通过Thymeleaf表达式进行显示即可:
<!DOCTYPE html><html><head><meta charset="UTF-8"><title>操作错误</title></head><body><h1>操作错误</h1><h3>操作失败:<span th:text="${errorMessage}">xxxxx</span></h3>//相当于把数据取出来</body></html>
然后还是登陆网址测试。
注意:这种做法是需要使用HttpServletRequest的,依然存在“不便于执行单元测试”的问题!
所以我们会使用新的做法来解决这个问题。
2.2. 使用ModelMap封装需要转发的数据(推荐这种做法)
使用ModelMap的做法与使用HttpServletRequest几乎相同!即:
1.参数列表加一个:ModelMap modelMap。
2.modelMap.addAttribute(),用modelMap调用addAttribute方法。
改的地方只有3个。
@RequestMapping("handle_login.do")public String handleLogin(String username, String password, ModelMap modelMap) { System.out.println("UserController.handleLogin()"); System.out.println("username=" + username); System.out.println("password=" + password); // 模拟登录:假设root/1234是正确的用户名/密码 // 先判断用户名 if ("root".equals(username)) { // 用户名正确,还需要判断密码 if ("1234".equals(password)) { // 密码也正确,则登录成功,暂且不处理 } else { // 密码错误,登录失败 String msg = "[ModelMap] 密码错误"; modelMap.addAttribute("errorMessage", msg); return "error"; } } else { // 用户名错误,登录失败 String msg = "[ModelMap] 用户名不存在"; modelMap.addAttribute("errorMessage", msg); return "error"; } return null;}
ModelMap 的源代码:
public class ModelMap extends LinkedHashMap<String, Object> { //对于一个Map来说,它的泛型已经定死了,key一定是字符串类型,value一定是Object类型。 /** * Construct a new, empty {@code ModelMap}. */ public ModelMap() { }
由于ModelMap是LinkedHashMap的子类,所以,它也是一种Map,则相对HttpServletRequest而言,是更加易于执行单元测试的!并且,相对HttpServletRequest而言,ModelMap这种数据类型更加轻量级一些!(消耗的CPU或者内存会小一些,会更快一些。)
在以上代码中,调用的addAttribute()方法的源代码是:
public ModelMap addAttribute(String attributeName, @Nullable Object attributeValue) { Assert.notNull(attributeName, "Model attribute name must not be null"); put(attributeName, attributeValue); return this;}
所以,这个方法封装数据的本质依然是调用了Map的put()方法,只不过,在调用put()方法之前,对Key的值进行了是否为null的检查!在实际编写代码时,如果能保证Key的值不是null,那么调用ModelMap对象的addAttribute()方法或put()方法其实没有本质的区别!
有ModelMap,就优先用。
2.3. 使用ModelAndView作为处理请求的方法的返回值(了解即可)
首先,一般情况下,并不推荐使用这种做法!用起来不方便,几乎无意义。
应该先将方法的返回值类型声明为ModelAndView类型,其中,Model表示的就是转发的数据,View就是视图,所以,在处理过程中,通过ModelAndView的相关API封装数据和视图:
@RequestMapping("handle_login.do")public ModelAndView handleLogin(String username, String password) {//上面的返回值类型改了,String——ModelAndView System.out.println("UserController.handleLogin()"); System.out.println("username=" + username); System.out.println("password=" + password); // 模拟登录:假设root/1234是正确的用户名/密码 // 先判断用户名 if ("root".equals(username)) { // 用户名正确,还需要判断密码 if ("1234".equals(password)) { // 密码也正确,则登录成功,暂且不处理 } else { // 密码错误,登录失败 //new一个Map Map<String, Object> model = new HashMap<String, Object>(); //往model里放数据 model.put("errorMessage", "[ModelAndView] 密码错误"); ModelAndView mav = new ModelAndView("error", model); //error是视图,model是数据 return mav; } } else { // 用户名错误,登录失败 Map<String, Object> model = new HashMap<String, Object>(); model.put("errorMessage", "[ModelAndView] 用户名不存在"); ModelAndView mav = new ModelAndView("error", model); return mav; } return null;}
由于这种做法相对使用ModelMap而言更加复杂,代码也不够直观,所以,一般并不推荐使用这种做法!
3. 重定向
想要达成的效果:假设注册成功后,需要到“登录”页面。
假设注册成功后,需要到“登录”页面,则不可以使用转发的做法,因为使用转发到登录时,URL并不会发生变化,就会导致URL(网址)和页面内容不匹配的问题,并且,如果刷新页面,会重复提交注册请求!在这里,就必须使用重定向的做法!
在SpringMVC中,如果控制器中处理请求的方法返回值是String类型的,则重定向的语法是:
return "redirect:目标路径";//redirect翻译:重定向
以上语法中,目标路径指的是要打开哪个页面,取值应该是这个页面的地址,也就是在浏览器的地址栏中看到地址,可以使用绝对路径,也可以使用相对路径。
在下面代码中:
【当前位置】http://localhost:8080/springmvc02/handle_reg.do
【目标位置】http://localhost:8080/springmvc02/login.do
相对路径就是把两个路径中,前面相同的部分都不写了,而只写有区别的地方,这就是相对路径,前提是只有最后一节不同,前面都相同。
当然,这么写:
return "redirect:http://localhost:8080/springmvc02/login.do";也是可以的。
完整代码例如:在类UserController中:
//http://localhost:8080/springmvc02/handle_reg.do@RequestMapping("handle_reg.do")public String handleReg(User user, ModelMap modelMap) { System.out.println("UserController.handleReg()"); System.out.println(user); // 假设:root用户名已经被占用,不允许注册,其它用户名注册均视为成功 if ("root".equals(user.getUsername())) { String msg = "注册失败,用户名已经被占用"; modelMap.addAttribute("errorMessage", msg); return "error"; } //不写else,顺着往下执行就行 // 如果代码能执行到这个位置,就表示注册成功,需要到“登录”页 // 【当前位置】http://localhost:8080/springmvc02/handle_reg.do // 【目标位置】http://localhost:8080/springmvc02/login.do return "redirect:login.do"; //这就是相对路径,注意要加.do,是路径而不是视图名称}
什么时候用转发,什么时候用重定向?如何区分?
一个简单原则,都用转发,看页面对不对,或者刷新一下,要是行就继续转发,不行就用重定向。
能转发,就全转发了再说,转发了感觉不合适,再重定向。
4. 关于@RequestMapping注解
在处理请求的方法之前添加@RequestMapping注解(后面括号里是一个String数组,默认是有{}大括号的),可以配置请求路径与处理请求的方法之间的映射关系!也就是访问某个路径时,就会调用注解后方的方法!
其实,还可以将这个注解添加在控制器类的声明之前!例如:
2个注解不区分先后顺序:
@Controller@RequestMapping("user")public class UserController { }
一旦在类的声明之前添加了该注解,当前类中配置的所有请求路径中,都需要添加该注解配置的值,例如原本的路径是http://localhost:8080/springmvc02/login.do,就要通过http://localhost:8080/springmvc02/user/login.do才可以访问!
为什么要配置注解呢,因为在一个完整的项目中,有很多操作会用上相同的单词,但是又不能冲突,所以可以加前缀(或者后缀),但是不能一个一个的加,所以方法是:在类之前,比如加user,然后在方法之前就直接写就行。
强烈推荐在每一个控制器类的声明之前都使用@RequestMapping注解配置路径中的层级。
统一配置在类的上方,简化配置时要写的代码。
那么现在代码,在类UserController中:
if ("root".equals(username)) { //用户名正确,还需要判断密码 if("1234".equals(password)) { //密码也正确,则登陆成功 // 【当前路径】http://localhost:8080/springmvc02/user/handle_login.do // 【目标路径】http://localhost:8080/springmvc02/index.do //登录成功——>要去index.do,index.do前面没有user,怎么办? //则用return "redirect:../index.do"; return "redirect:../index.do"; }else { //密码错误,登陆失败 String msg = "[modelMap]密码错误";
../表示回到上一层路径,往上先回一层路径。所以,原本是在http://localhost:8080/springmvc02/user/handle_login.do中handle_login.do这个位置,../一下,相当于是回到了http://localhost:8080/springmvc02/这个地址,即springmvc02/这个位置右侧来了,然后再来找index.do,就是找得到了。
每一个../,都表示往上回一层。回多层,就写多个。
在类的声明之前添加了注解后,类之前的注解值,会和方法之前的注解值,组合起来,形成完整的路径配置值,在组合时,会先忽略这2个配置值的两端多余的/符号!SpringMVC框架会自行添加必要的/,也就是说,在类和方法之前的配置值是:
类前: 方法前:user login.douser /login.do/user login.do/user /login.douser/ login.douser/ /login.do/user/ login.do/user/ /login.do
以上8种配置方式是完全等效的!推荐使用第1种做法,或第4种做法(要么都写,要么都不写),切忌不要随意使用多种不同的方式,避免出现语义不明!
@RequestMapping底层:
在@RequestMapping注解的源代码中,大致有:
@Target({ElementType.METHOD, ElementType.TYPE})@Retention(RetentionPolicy.RUNTIME)@Documented@Mappingpublic @interface RequestMapping { /** * 为当前映射关系分配一个名称,没有实际作用; * 以下代码中的name()表示注解的参数名称; * 以下代码中的String表示注解的参数的值的类型; * 以下代码中的default ""表示注解的参数的默认值; * 在使用时的语法可以是:@RequestMapping(name="") */ String name() default ""; /** * 该属性的作用是配置请求路径 * value是注解的默认属性,例如配置为@RequestMapping("")与@RequestMapping(value="")是等效的; * 注意,如果同一个注解中配置多个属性,则每个属性都必须显式的声明属性名称,包含默认属性; * 显示的:就是明确通过代码体现出来的。 * * 以下代码中的String[]表示注解的参数的值的类型是字符串数组(可以写多个值) * 注意,如果该属性的值只有1个时,不需要显式的将值写为数组类型,直接写数组元素即可 * 例如配置为@RequestMapping("login.do")与@RequestMapping({"login.do"})是等效的; * 所以,如果要配置的路径是login.do时,以下4种配置方式都是等效的: * @RequestMapping("login.do") * @RequestMapping(value="login.do") * @RequestMapping({"login.do"}) * @RequestMapping(value={"login.do"}) * 其中的value,是可写可不写的。 * * 这就是注解中配置属性值的特点,明明声明的是String数组,但是写不写成数组是随便的,如果有2个值或者更多值,那就必须写成数组,如果只有一个,就可以随便写了。 * * 以下代码中的@AliasFor("path")表示以下属性与path属性是等效的 * 也就是说: * @RequestMapping(value={"reg.do,"register.do"}) 与 * @RequestMapping(path={"reg.do,"register.do"})使用的语法和功能上完全没有区别。 */ @AliasFor("path") String[] value() default {}; /** * 注意:以下属性从SpringMVC框架4.2开始加入,更早期的版本不识别以下属性 */ @AliasFor("value") String[] path() default {};//path:路径 /** * 限制请求方式 * 例如配置为@RequestMapping(path="handle_login.do", method=RequestMethod.POST) * 则表示handle_login.do路径的请求只能通过POST方式来访问 * 如果请求方式不匹配,就会出现405错误 */ /* RequestMethod:枚举类型,有: * GET,HEAD,POST,PUT,PATCH,DELETE,OPTIONS,TRACE。 * 常用的是GET,POST。 */ RequestMethod[] method() default {};//数组,可以同时允许GET和POST。 }
附1:转发与重定向
转发:以登录为例,当服务器端的控制器接收到客户端的请求后,可以对用户名、密码等数据进行判断,并得到结果,假设登录失败,在控制器类中却不适合编写页面的代码响应到客户端,所以,就在服务器端也创建了error.html等相关页面,将由控制器将处理登录后的结果数据转发给error.html页面,由页面负责显示!所以,转发是服务器内部的控制器类和页面协作完成同一项任务处理的过程!
重定向:以登录为例,假设登录成功,其实整个数据处理就已经结束了,在服务器端,并没有数据需要转发到某个页面来显示,即使需要“跳到主页”,也不属于“处理登录”的控制器的任务,而应该是开启另一个新的任务!
转发,整个过程中,客户端只发出了1次请求,无论是控制器类的工作,还是页面的工作,它们的合作,是服务器端内部的行为;
重定向,整个过程中,客户端发出了2次请求,分别是客户端第1次发出请求后,服务器端给出了重定向的响应(HTTP响应码为302,客户端只要收到了302就会发出下一次请求),然后,客户端会根据这次响应,自动发出第2次请求!
所以,转发和重定向最大的区别在于:转发过程中,客户端只发出了1次请求,而重定向时,客户端还会发出第2次请求,以至于,转发时,浏览器的地址栏中的URL是不变的,而重定向时,URL是第2次请求的地址。
另外,由于转发是服务器内部的行为,所以,在控制器中的任何数据都可以转发到页面,由页面负责显示,而重定向是2次不同的请求,基于HTTP协议是无状态协议,没有结合其它技术时,第1次处理请求时产生的数据是不可以用于第2次处理请求的!
无状态协议:客户端给服务器发来一个请求,服务器处理完了之后,就不认识客户端了,就不知道了,这就是无状态协议的特点。客户端第2次发请求过去,服务器不认识了。
百度百科:无状态协议是指比如客户获得一张网页之后关闭浏览器,然后再一次启动浏览器,再登录该网站,但是服务器并不知道客户关闭了一次浏览器。无状态服务器是指一种把每个请求作为与之前任何请求都无关的独立的事务的服务器。
转发和重定向区别详解
作为一名java web开发的程序员,在使用servlet/jsp的时候,我们必须要知道实现页面跳转的两种方式的区别和联系:即转发和重定向的区别。
1、request.getRequestDispatcher().forward()方法,只能将请求转发给同一个WEB应用中的组件;而response.sendRedirect() 方法不仅可以重定向到当前应用程序中的其他资源,还可以重定向到同一个站点上的其他应用程序中的资源,甚至是使用绝对URL重定向到其他站点的资源。
如果传递给response.sendRedirect()方法的相对URL以“/”开头,它是相对于整个WEB站点的根目录;如果创建request.getRequestDispatcher()对象时指定的相对URL以“/”开头,它是相对于当前WEB应用程序的根目录。
2、重定向访问过程结束后,浏览器地址栏中显示的URL会发生改变,由初始的URL地址变成重定向的目标URL;请求转发过程结束后,浏览器地址栏保持初始的URL地址不变。
3、HttpServletResponse.sendRedirect方法对浏览器的请求直接作出响应,响应的结果就是告诉浏览器去重新发出对另外一个URL的访问请求,这个过程好比有个绰号叫“浏览器”的人写信找张三借钱,张三回信说没有钱,让“浏览器”去找李四借,并将李四现在的通信地址告诉给了“浏览器”。于是,“浏览器”又按张三提供通信地址给李四写信借钱,李四收到信后就把钱汇给了“浏览器”。
由此可见,重定向的时候,“浏览器”一共发出了两封信和收到了两次回复,“浏览器”也知道他借到的钱出自李四之手。
request.getRequestDispatcher().forward()方法在服务器端内部将请求转发给另外一个资源,浏览器只知道发出了请求并得到了响应结果,并不知道在服务器程序内部发生了转发行为。这个过程好比绰号叫“浏览器”的人写信找张三借钱,张三没有钱,于是张三找李四借了一些钱,甚至还可以加上自己的一些钱,然后再将这些钱汇给了“浏览器”。
由此可见,转发的时候,“浏览器”只发 出了一封信和收到了一次回复,他只知道从张三那里借到了钱,并不知道有一部分钱出自李四之手。
4、request.getRequestDispatcher().forward()方法的调用者与被调用者之间共享相同的request对象和response对象,它们属于同一个访问请求和响应过程;
而response.sendRedirect()方法调用者与被调用者使用各自的request对象和response对象,它们属于两个独立的访问请求和响应过程。对于同一个WEB应用程序的内部资源之间的跳转,特别是跳转之前要对请求进行一些前期预处理,并要使用HttpServletRequest.setAttribute方法传递预处理结果,那就应该使用request.getRequestDispatcher().forward()方法。不同WEB应用程序之间的重定向,特别是要重定向到另外一个WEB站点上的资源的情况,都应该使用response.sendRedirect()方法。
5、无论是request.getRequestDispatcher().forward()方法,还是response.se
————————————————
版权声明:本文为CSDN博主「liubin5620」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/liubin5620/article/details/79922692
附2:常见的HTTP响应码
2字头表示:OK
3字头的表示:重定向
4字头的表示:客户端错误
5字头表示:服务器端错误
-
200:正确;不考虑实际要处理的功能,只考虑通信过程是否OK。发一个请求过去,给了一个响应回来,只要服务器端能正常给响应,就是正确。不管登录成功还是失败。 -
206:正确,仅会在断点续传的请求与响应过程中出现;比如像迅雷等下载工具,它每次请求服务器的数据,其实只用请求一片数据,访问的也是同一个文件。这种下载,在向服务器发请求的时候,会在请求头中间添加一个range,这个range表示的是访问的,请求的数据的区间段,本身是以字节为单位的,比如1G的文件,先下载了300M,暂停后又开始下载,则range(301M,1024M)。写客户端的接触的多一些。 -
301:静态重定向;重定向的目标都是同一个,那么就是静态重定向;静态重定向是需要手动设置的,否则一般默认是动态的302。 -
302:动态重定向;重定向的位置有没有可能发生变化,如果重定向的目标是同一个,那就是静态重定向,但是如果重定向的目标不一样:如果中间有if判断,那么同一个处理过程中,产生的分支重定向目标不一样,就是动态重定向。静态和动态的区别:静态的有利于网络爬虫去爬这个页面,而动态重定向,一般爬虫不爬,因为爬到哪里去说不准,而对于网络推广来说,是需要爬虫的,所以如果希望推广,那么就手动设置成301。
-
400:提交的请求参数不正确,可能是参数格式不正确,或没有提交必要的参数; -
404:尝试请求的资源不存在;(客户端的错误) -
405:请求方式错误;比如必须是post请求,发送了get请求。 -
500:服务器内部错误,分好多种,一般在开发环境的控制台会有错误信息。
第三步:
HTTP 协议中 URI 和 URL 有什么区别?
URI:uniform resource identifier,统一资源标识符。
URL:uniform resource locator,统一资源定位器。
URI包括URL,URL是URI当中的一种。
具体解释(取自知乎):(https://www.zhihu.com/question/21950864)
统一资源标志符URI就是在某一规则下能把一个资源独一无二地标识出来。
拿人做例子,假设这个世界上所有人的名字都不能重复,那么名字就是URI的一个实例,通过名字这个字符串就可以标识出唯一的一个人。
现实当中名字当然是会重复的,所以身份证号才是URI,通过身份证号能让我们能且仅能确定一个人。
那统一资源定位符URL是什么呢。也拿人做例子然后跟HTTP的URL做类比,就可以有:
动物住址协议://地球/中国/浙江省/杭州市/西湖区/某大学/14号宿舍楼/525号寝/张三.人
可以看到,这个字符串同样标识出了唯一的一个人,起到了URI的作用,所以URL是URI的子集。URL是以描述人的位置来唯一确定一个人的。
在上文我们用身份证号也可以唯一确定一个人。对于这个在杭州的张三,我们也可以用:
身份证号:123456789 来标识他。
所以不论是用定位的方式还是用编号的方式,我们都可以唯一确定一个人,都是URl的一种实现,而URL就是用定位的方式实现的URI。
回到Web上,假设所有的Html文档都有唯一的编号,记作html:xxxxx,xxxxx是一串数字,即Html文档的身份证号码,这个能唯一标识一个Html文档,那么这个号码就是一个URI。
而URL则通过描述是哪个主机上哪个路径上的文件来唯一确定一个资源,也就是定位的方式来实现的URI。
对于现在网址我更倾向于叫它URL,毕竟它提供了资源的位置信息,如果有一天网址通过号码来标识变成了http://741236985.html,那感觉叫成URI更为合适,不过这样子的话还得想办法找到这个资源咯…
所以URI包含URL:
URI 不一定非得是通过号码确定的。URI 是在「某一规则」下标识出一个资源的字符串,通过地址或者通过号码都是可行的规则,其中通过地址规则实现的 URI 可以被称作 URL ,URL 是 URI 的一种实现,所以URI 作为更宽泛的定义是包含了 URL 的,就像三角形包含等边三角形一样。
注意:只要符合schema://server[:port]/path这种格式的,都叫URI(要不要port都是可选的)。
关于session
A自己小节:
1.什么是session?
session是在浏览器和服务器交互的会话的一种会话跟踪技术,来进行会话控制的一种服务器存储数据的方式。
为了在一次会话中解决2次HTTP的请求的关联,让它们产生联系,让这两个页面都能读取到这个全局的session信息。而session信息存在于服务器端,与cookie 是存在客户端不同,用户不可以随意修改,所以也就很好的解决了安全问题。
2.session_id:
用这个唯一的session_id 来绑定一个用户。一个用户在一次会话上就是一个session_id。
只要是同一个浏览器,访问的是同一个服务器,则session_id是相同的,把浏览器关了,再重新打开,session_id会发生改变。
其中原理:每次我们访问一个页面,如果有开启session,也就是有session_start() 时,就会自动生成一个session_id 来标注是这次会话的唯一ID,同时也会自动往cookie里写入一个名字为PHPSESSID的变量,它的值正是session_id,当这次会话没结束,再次访问的时候,服务器会去读取这个PHPSESSID的cookie是否有值有没过期,如果能够读取到,则继续用这个session_id,如果没有,就会新生成一个session_id,同时生成PHPSESSID这个cookie。由于默认生成的这个PHPSESSID cookie是会话,也就是说关闭浏览器就会过期掉,所以,下次重新浏览时,会重新生成一个session_id。
3.session怎么保存数据?
往session里面写入数据,同样也是用到session_id。session_id是32位的,服务器会用 sess_前缀 + session_id 的形式存在这个临时目录下,所以,每一次生成的session_id都会生成一个文件,用来保存这次会话的session信息。
HTTP请求一个页面后,如果用到开启session,会去读cookie中的PHPSESSID是否有,如果没有,则会新生成一个session_id,先存入cookie中的PHPSESSID中,再生成一个sess_前缀文件。当有写入$SESSION的时候,就会往sess文件里序列化写入数据。当读取的session变量的时候,先会读取cookie中的PHPSESSID,获得session_id,然后再去找这个sess_sessionid文件,来获取对应的数据。由于默认的PHPSESSID是临时的会话,在浏览器关闭后,会消失,所以,我们重新访问的时候,会新生成session_id和sess这个文件。
B网上讲解:
客户端向服务端发送请求的时候,会携带一个数据,这个数据是JEESSIONID,亦可以理解为session_id,而服务器接受到这个数据,会根据这个数据形成一个相当于是Map的数据结构,从数据的存储结构来说,和Map没有区别。
如果提交的是JSESSIONID:111,那么在Map中,key就是111,就是ID,value就是Session_111,同一个浏览器访问同一个服务器,每次带的JSESSIONID就是相同的值,是不变的,每一个客户端访问到服务器,都有一个属于自己的数据,但是关闭浏览器后会变化。而这个Session Id其实是随机生成的,不会是一个固定的值。所以有时的体验是:浏览器关闭了,登录信息就没有了。
服务器处理机制:超时删除机制,服务器会对无用的Session Id及其对应的数据(Value),超时删除,在Tomcat里面可以设置超时时间(一般15-30分钟),长时间没有人使用就会删除。一个Session Id长时间没有给服务器发请求,则服务器会清除这个Session Id对应的数据。并不是一个网页长时间没有操作,这样解释是不严谨的,而应该是:key对应的客户端长时间没有向服务器发送请求。
一个Tomcat最多同时连接数量,按照设计来说,一般是设计200-1000个用户同时连接。访问量更大的话,会加服务器。
关于Session不可用(消失)的原因
- 1.客户端浏览器问题。客户端将浏览器关闭了,即使再次打开,或使用其它浏览器访问,都无法访问到此前对应的Session数据,从体验上来说,就是Session不可用了,或用户的登录信息已经不可用了;
- 2.客户端超时。客户端长时间没有向服务器发送新的请求,则服务器会清除该客户端此前产生的Session数据;
- 3.服务器重启。Tomcat重启,Session数据是Tomcat在服务器内存中维护的数据,只要Tomcat重启,甚至整个服务器重启,都会导致这些数据消失!(服务器关闭,Session也会被清除。Tomcat重启,所有的Session就没有了。)
注意:Session是会存在盗用的问题,用来盗用Session Id,但是一般情况下,正常访问来说Session Id是随机数,而这个随机数的范围特别特别大,所以很难生成2个相同的Id,出现重复Id的概率极其低。
哪些数据应该保存到Session中?
-
用户身份的标识,例如用户的id,或用户名等等;
-
使用频率非常高的数据,例如用户名、用户头像等等;
-
不便于使用其它技术或存储方案来临时保存的数据。
1. 使用HttpSession
在SpringMVC框架中,在处理请求的过程中,如果需要访问Session(包含存入数据和取出数据),那么在处理请求的方法的参数列表中直接添加HttpSession类型的参数,在处理过程中,调用该参数对象的API即可访问数据!
假设:当用户成功登录后,将用户的ID和用户名保存到Session中,则可以:
// http://localhost:8080/springmvc02/handle_login.do
@RequestMapping(path="handle_login.do", method=RequestMethod.POST)
public String handleLogin(String username, String password,
ModelMap modelMap, HttpSession session) {
System.out.println("UserController.handleLogin()");
// 模拟登录:假设root/1234是正确的用户名/密码
// 先判断用户名
if ("root".equals(username)) {
// 用户名正确,还需要判断密码
if ("1234".equals(password)) {
// 密码也正确,则登录成功
session.setAttribute("uid", 3366);
session.setAttribute("username", "root");
// 【当前路径】http://localhost:8080/springmvc02/user/handle_login.do
// 【目标路径】http://localhost:8080/springmvc02/main/index.do
return "redirect:../main/index.do";
} else {
// 密码错误,登录失败,暂不关心这段代码
}
} else {
// 用户名错误,登录失败,暂不关心这段代码
}
}
当把数据存储到Session中了,后续就可以随时从Session中再将这些数据取出!
假设,在显示主页时,需要将用户的ID和用户名取出,组织成欢迎语显示在页面!
当前是使用MainController中的showIndex()方法来显示主页的,所以,应该先在showIndex()方法的参数列表中添加HttpSession类型的参数,在处理过程中,调用该参数对象的getAttribute()方法即可获取数据:
@RequestMapping("index.do")
public String showIndex(HttpSession session) {
System.out.println("MainController.showIndex()");
Integer uid = Integer.valueOf(session.getAttribute("uid").toString());
String username = session.getAttribute("username").toString();
System.out.println("uid=" + uid);
System.out.println("username=" + username);
return "index";
}
然后,要将数据显示在页面中,还需要在showIndex()中将数据进行封装,以便于后续转发数据!所以,先在showIndex()方法的参数列表中添加ModelMap类型的参数,并在获取到相关数据之后,将需要转发的数据进行封装:
@RequestMapping("index.do")
public String showIndex(HttpSession session, ModelMap modelMap) {
System.out.println("MainController.showIndex()");
// 从Session中获取数据
Integer uid = Integer.valueOf(session.getAttribute("uid").toString());
String username = session.getAttribute("username").toString();
// 测试
System.out.println("uid=" + uid);
System.out.println("username=" + username);
// 封装需要转发的数据
modelMap.addAttribute("uid", uid);
modelMap.addAttribute("username", username);
return "index";
}
最后,在index.html页面中,通过Thymeleaf表达式显示这些数据即可:
<h3>欢迎您!<span th:text="${username}">用户名</span>(<span th:text="${uid}">用户ID</span>)!</h3>
在SpringMVC框架中,其实另外提供了一套处理Session数据的做法,可以将需要存入到Session的数据直接封装在ModelMap对象中,并结合相关注解进行处理,但是,目前更多还是使用HttpSession进行处理!甚至在大型项目中,Session机制本身就是一个无用机制,所以,一般也不纠结这个问题!
2. SpringMVC拦截器
2.1. 拦截器的基本概念
拦截器(Interceptor)是SpringMVC中的组件,可以使得若干个请求路径在被处理时,都会执行拦截器中的代码,并且,拦截器可以选择阻止程序继续向后执行,或选择放行,那么,程序就可以继续执行!
例如,在项目中,可能有很多请求都是需要登录后才可以访问的,如果在每个处理请求的方法中对Session进行相同的判断,是不易于代码的阅读、管理、维护的,就可以把这种判断Session的代码写在拦截器中,并配置好相关的若干路径,则当客户端提交的是这些路径中的请求时,拦截器就会被执行,其中的代码就可以对Session进行判断,最终选择阻止或放行!由于这些代码只需要在拦截器中编写一次即可,所以,非常利于代码的管理与维护!
所以,拦截器的本质就是将请求给“拦”下来,进行相关判断检查后,选择阻止或放行!
2.2. 拦截器的基本使用
在SpringMVC中,可以自定义类,实现HandlerInteceptor拦截器接口,这个类就会是一个拦截器类!例如:
public class LoginInterceptor implements HandlerInterceptor { public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { System.out.println("LoginInterceptor.preHandle()"); return false; } public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception { System.out.println("LoginInterceptor.postHandle()"); } public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception { System.out.println("LoginInterceptor.afterCompletion()"); }}
拦截器类还必须在Spring的配置文件中进行配置,所以,还要在spring.xml中添加:
<!-- 配置拦截器链 --><mvc:interceptors> <!-- 配置第一个拦截器 --> <mvc:interceptor> <!-- 拦截路径,配置时,必须使用/作为第1个字符 --> <mvc:mapping path="/main/index.do"/> <!-- 拦截器 --> <bean class="cn.tedu.spring.LoginInterceptor"/> </mvc:interceptor></mvc:interceptors>
初步测试,如果拦截器中的preHandle()返回false,表示阻止运行,并且,页面会显示一片空白!如果返回true,就表示放行,是程序会按照原有流程执行!
所以,可以在preHandle()方法中实现登录验证:
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { System.out.println("LoginInterceptor.preHandle()"); // 判断用户是否已登录,如果登录,则放行,否则,阻止运行 if (request.getSession().getAttribute("uid") == null) { String contextPath = request.getContextPath(); response.sendRedirect(contextPath + "/user/login.do"); return false; // 阻止运行 } return true; // 放行}
在拦截器中,还有postHandle()方法和afterCompletion()方法,当拦截器的执行结果为放行时,这2个方法会在控制器执行之后再执行,严格的说,postHandle()是在控制器之后执行的方法,而afterCompletion()会在整个框架处理流程结束之前的那一刻被执行!这2个方法都是在控制器之后执行的方法,所以,并不具备真正意义上的“拦截”效果!
2.3. 关于拦截器的配置
在Spring的配置文件中,可以对拦截器所映射的路径进行详细配置,在每一个<mvc:interceptor>节点中,都可以添加若干个<mvc:mapping>节点,以配置若干个需要被拦截的路径,例如:
<mvc:interceptors> <mvc:interceptor> <!-- 可以配置若干个需要被拦截的路径 --> <mvc:mapping path="/main/index.do"/> <mvc:mapping path="/user/password.do"/> <mvc:mapping path="/user/info.do"/> <mvc:mapping path="/blog/addnew.do"/> <mvc:mapping path="/blog/edit.do"/> <mvc:mapping path="/blog/delete.do"/> <!-- 拦截器 --> <bean class="cn.tedu.spring.LoginInterceptor"/> </mvc:interceptor></mvc:interceptors>
在配置映射路径时,还可以使用星号(*)作为通配符,表示匹配任意资源,例如,以上配置就可以改为:
<mvc:interceptors> <mvc:interceptor> <!-- 可以配置若干个需要被拦截的路径 --> <mvc:mapping path="/main/index.do"/> <mvc:mapping path="/user/*"/> <mvc:mapping path="/blog/*"/> <!-- 拦截器 --> <bean class="cn.tedu.spring.LoginInterceptor"/> </mvc:interceptor></mvc:interceptors>
但是,在SpringMVC的拦截器配置中,1个星号只能表示某个资源,并不能通配多层级的路径,例如/blog/*可以表示/blog/addnew.do、/blog/delete.do等,却不可以匹配到/blog/2020/list.do,也就是,路径中间的层级不同时,是无法匹配的!****如果一定要通配多层级路径的任意资源,需要使用2个星号(**),以上代码就可以改为:
<mvc:interceptors> <mvc:interceptor> <!-- 可以配置若干个需要被拦截的路径 --> <mvc:mapping path="/main/index.do"/> <mvc:mapping path="/user/**"/> <mvc:mapping path="/blog/**"/> <!-- 拦截器 --> <bean class="cn.tedu.spring.LoginInterceptor"/> </mvc:interceptor></mvc:interceptors>
当使用了通配符之后,可能会出现匹配范围过大的问题,例如,以上配置了/user/**,则修改密码/user/password.do、查看资料/user/info.do都是可以被拦截,但是,用户注册/user/reg.do、用户登录/user/login.do也会被拦截,如果是应用于“验证登录的拦截器中”,则表现为“打开注册/登录页面也是要求事先已经登录的”!很显然是不合理的!
为了解决匹配范围过大的问题,在SpringMVC中配置拦截器时,还可以添加<mvc:exclude-mapping>节点,用于添加“例外”(“排除”)清单,例如:
<mvc:interceptors> <mvc:interceptor> <!-- 可以配置若干个需要被拦截的路径 --> <mvc:mapping path="/main/index.do"/> <mvc:mapping path="/user/**"/> <mvc:mapping path="/blog/**"/> <!-- 配置若干个排除的路径,即拦截器不予处理的路径 --> <mvc:exclude-mapping path="/user/reg.do" /> <mvc:exclude-mapping path="/user/register.do" /> <mvc:exclude-mapping path="/user/handle_reg.do" /> <mvc:exclude-mapping path="/user/login.do" /> <mvc:exclude-mapping path="/user/handle_login.do" /> <!-- 拦截器 --> <bean class="cn.tedu.spring.LoginInterceptor"/> </mvc:interceptor></mvc:interceptors>
在以上
<mvc:interceptor>的配置中,必须先配置<mvc:mapping>节点,再配置<mvc:exclude-mapping>节点,最后配置<bean>节点!
所以,可以把<mvc:mapping>配置的路径理解为“黑名单”,就是需要拦截的路径,而<mvc:exclude-mapping>配置的路径理解为“白名单”,不予处理的路径。
2.4. 拦截器与过滤器的区别
拦截器:Interceptor 【 in ter 赛 per ter】
过滤器:Filter 【飞 哦 特】
其实面试题问两者的区别的时候,其实更多的是想知道什么时候用哪个,什么时候用另外一个。
两者的相同点:
拦截器和过滤器都可以应用于若干个路径,并且使得这些路径的请求在被处理时,都会经过相关检查,最终决定阻止或放行,在同一个项目中,可以有多个拦截器,也可以有多个过滤器,都可以形成“链”。(链的效果:比如说一个请求路径涉及到2个拦截器(或过滤器),那么这2个拦截器(或过滤器)任何一个阻止这个路径,它都执行不到后面去)。
两者的区别:
1.归属不同。过滤器是Java EE中的组件,需要在web.xml中配置,依赖于Servlet;拦截器是SpringMVC框架中的组件,需要在SpringMVC中配置,依赖于框架;
2.执行时间不同。过滤器是在所有的Servlet组件之前执行的,而拦截器的第1次执行是在DispatcherServlet之后、在Controller组件之前执行的!
3.配置不同。一个过滤器就只有一个配置的路径(但是可以配置多个过滤器),并且只能配置需要过滤的路径(黑名单),却不可以添加例外(白名单),并且,每个路径的配置的节点格式比较繁琐,而拦截器的配置却灵活简洁!所以,在一般情况下,都会优先使用拦截器。
4.两者的本质区别:拦截器(Interceptor)是基于Java的反射机制,而过滤器(Filter)是基于函数回调。从灵活性上说拦截器功能更强大灵活些,Filter能做的事情,都能做,而且可以在请求前,请求后执行,比较灵活。Filter主要是针对URL地址做一个编码的事情、过滤掉没用的参数、安全校验,太细的话,还是建议用interceptor。不过还是根据不同情况选择合适的。
5.但是如果配置字符编码过滤器的时候,则必须使用过滤器,而不能替换成拦截器。比如,解决SpringMVC框架中POST请求提交中文会乱码的问题。
一、组件归属不同:
过滤器(Filter)是Java EE中的组件,而拦截器(Interceptor)是SpringMVC框架中的组件 ,所以,只要用java语言做一个web项目,都可以有过滤器,但是只有被SpringMVC框架处理的请求,才可能被拦截器处理,例如在SpringMVC框架中,将DispatcherServlet映射的路径配置为*.do,那么,只有以.do为后缀的请求才可能被拦截器处理,其它后缀的请求不会被拦截器处理!
拦截器的执行时间节点:可能在(SpringMVC核心执行流程图)图中是4、5、9号点,那么如果有某个请求,比如*.jpg或者*.png访问某个图片,那么如果客户端的请求是访问图片的话,就根本就不走这个流程,那拦截器也就是无法拦截,所以,拦截器,相对来说是建立在整个SpringMVC框架基础之上的,如果请求不从核心执行流程图的体系中过,拦截器也不可能工作。但是过滤器是不一样的,过滤器是Java EE中的组件,任何请求都可以配置为是过滤器来处理的。
二、执行时间不同:
过滤器是在所有的Servlet组件之前执行的,而拦截器的第1次执行是在DispatcherServlet之后、在Controller组件之前执行的!
拦截器的执行时间节点可能在(SpringMVC核心执行流程图)图中是4、5、9号点。
而过滤器是在1号点就执行了的。
三、配置不同:
过滤器是需要在web.xml中进行配置的,配置的格式例如:
<filter> <filter-name>过滤器名称,是自定义的值</filter-name> <filter-class>过滤器类的全名</filter-class></filter><filter-mapping> <filter-name>过滤器名称,与以上配置的相同</filter-name> <url-pattern>映射的路径_1</url-pattern></filter-mapping><filter-mapping> <filter-name>过滤器名称,与以上配置的相同</filter-name> <url-pattern>映射的路径_2</url-pattern></filter-mapping>...<filter-mapping> <filter-name>过滤器名称,与以上配置的相同</filter-name> <url-pattern>映射的路径_N</url-pattern></filter-mapping>
可以看到,过滤器的配置中,一个过滤器就只有一个配置的路径(但是可以配置多个过滤器),并且只能配置需要过滤的路径(黑名单),却不可以添加例外(白名单),并且,每个路径的配置的节点格式比较繁琐,而拦截器的配置却灵活得多,并且配置的代码也更加简洁!
那么优先使用哪个呢?根据上诉区分的3点来看:
1.在绝大部分的项目中,使用了SpringMVC框架肯定是一个Java EE项目,所以,拦截器和过滤器都是可以使用的,并且,将DispatcherSerlvet的映射路径配置为了/*,则所有请求都可以被拦截器处理,则过滤器和拦截器的区别就不明显了;——>区别不大
2.在Java EE技术中,使用Servlet作为处理请求的组件,过滤器是在其之前执行的,在SpringMVC中,使用Controller作为处理请求的组件,拦截器是在其之前执行的,所以,过滤器和拦截器都可以实现拦截效果,区别也不大;——>区别不大
3.在配置方面,拦截器的配置更加简洁、灵活,所以,在一般情况下,都会优先使用拦截器。主要还是因为配置简单 。
这也是为什么会有拦截器的原因,其实在框架中,出现的每一种技术或者每一种机制,一定是解决传统模式下的不足才出现的,如果传统的Java EE已经做得足够好了,这个框架肯定不会做拦截器了,既然框架选择去做拦截器,就一定有其存在的价值和必要,为什么在SpringMVC框架中有拦截器,主要就是因为过滤器的配置太麻烦了。
2.5. 解决SpringMVC框架中POST请求提交中文会乱码的问题
必须使用过滤器的情况!过滤器无法被取代,因为他的执行时间无法被取代,他是执行在1号点,所有的servlet之前的。
(注意,前提是POST请求中的提交乱码,如果是Get请求应该不会乱码,即使乱码,也是调整Tomcat里面的配置)
SpringMVC框架默认使用的编码都是ISO-8859-1,这种编码是不支持中文的!
如果要使得每个请求提交的数据都使用utf-8编码,是不可以使用拦截器来实现的,因为拦截器在DispatcherServlet 之后才会被执行,而DispatcherServlet在接收请求参数时已经按照默认编码进行处理了,后续再声明接收请求参数的编码,是没有任何意义的!所以,解决这个问题,只能通过过滤器来解决!
在SpringMVC框架中,本身就提供了CharacterEncodingFilter的过滤器类!所以,只需要在web.xml中配置应用这个过滤器,并配置它使用的字符编码即可:(Character:[ˈkærəktər] 特征、特性。Encoding:[ɪnˈkoʊdɪŋ] 编码)
下面的代码不需要背 ,也不会变。
<!-- 配置字符编码过滤器 --><filter> <filter-name>CharacterEncodingFilter</filter-name> <filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class> <init-param> <param-name>encoding</param-name> <param-value>utf-8</param-value> </init-param></filter> <filter-mapping> <filter-name>CharacterEncodingFilter</filter-name> <url-pattern>/*</url-pattern></filter-mapping>
这也是拦截器和过滤器的区别之一,在这种情况下只能用过滤器。
彻底搞清拦截器和过滤器的区别(网摘)
转载Java技术 最后发布于2019-01-03 23:04:00 阅读数 4291 收藏
一、引言
本来想记录一下关于用户登陆和登陆之后的权限管理、菜单管理的问题,想到解决这个问题用到Interceptor,但想到了Interceptor,就想到了Filter,于是就想说一下它们的执行顺序和区别。关于Interceptor解决权限和菜单管理的问题,在放在下一篇写吧,就酱紫。
二、区别
1、过滤器(Filter)
首先说一下Filter的使用地方,我们在配置web.xml时,总会配置下面一段设置字符编码,不然会导致乱码问题:
配置这个地方的目的,是让所有的请求都需要进行字符编码的设置,下面来介绍一下Filter。
(1)过滤器(Filter):它依赖于servlet容器。在实现上,基于函数回调,它可以对几乎所有请求进行过滤,但是缺点是一个过滤器实例只能在容器初始化时调用一次。使用过滤器的目的,是用来做一些过滤操作,获取我们想要获取的数据,比如:在Javaweb中,对传入的request、response提前过滤掉一些信息,或者提前设置一些参数,然后再传入servlet或者Controller进行业务逻辑操作。通常用的场景是:在过滤器中修改字符编码(CharacterEncodingFilter)、在过滤器中修改HttpServletRequest的一些参数(XSSFilter(自定义过滤器)),如:过滤低俗文字、危险字符等。
2、拦截器(Interceptor)
拦截器的配置一般在SpringMVC的配置文件中,使用Interceptors标签,具体配置如下:
mvc:interceptors
mvc:interceptor
<mvc:mapping path="/" />
</mvc:interceptor>
mvc:interceptor
<mvc:mapping path="/" />
</mvc:interceptor>
</mvc:interceptors>
(2)拦截器(Interceptor):它依赖于web框架,在SpringMVC中就是依赖于SpringMVC框架。在实现上,基于Java的反射机制,属于面向切面编程(AOP)的一种运用,就是在service或者一个方法前,调用一个方法,或者在方法后,调用一个方法,比如动态代理就是拦截器的简单实现,在调用方法前打印出字符串(或者做其它业务逻辑的操作),也可以在调用方法后打印出字符串,甚至在抛出异常的时候做业务逻辑的操作。由于拦截器是基于web框架的调用,因此可以使用Spring的依赖注入(DI)进行一些业务操作,同时一个拦截器实例在一个controller生命周期之内可以多次调用。但是缺点是只能对controller请求进行拦截,对其他的一些比如直接访问静态资源的请求则没办法进行拦截处理。
三、总结
对于上述过滤器和拦截器的测试,可以得到如下结论:
(1)、Filter需要在web.xml中配置,依赖于Servlet;
(2)、Interceptor需要在SpringMVC中配置,依赖于框架;
(3)、Filter的执行顺序在Interceptor之前,具体的流程见下图;
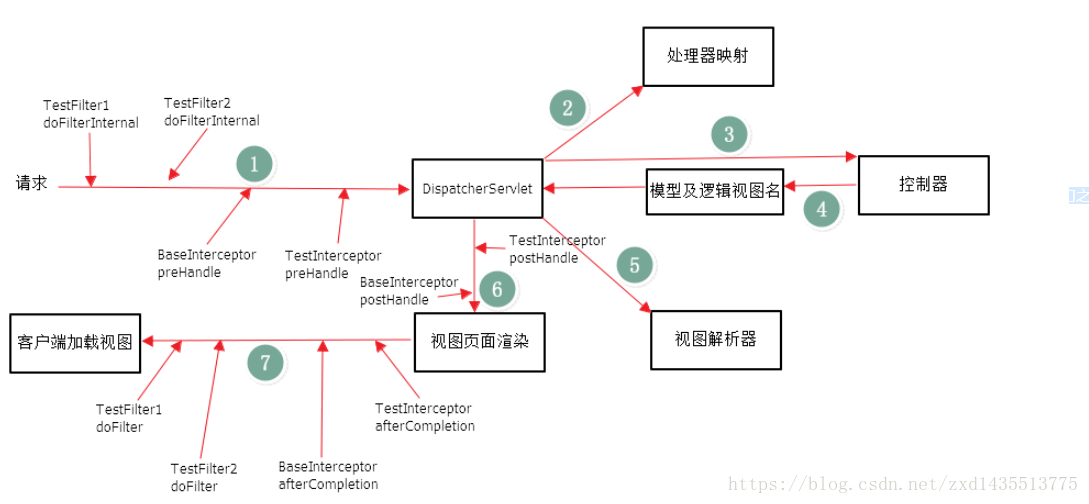
(4)、两者的本质区别:拦截器(Interceptor)是基于Java的反射机制,而过滤器(Filter)是基于函数回调。从灵活性上说拦截器功能更强大些,Filter能做的事情,都能做,而且可以在请求前,请求后执行,比较灵活。Filter主要是针对URL地址做一个编码的事情、过滤掉没用的参数、安全校验(比较泛的,比如登录不登录之类),太细的话,还是建议用interceptor。不过还是根据不同情况选择合适的。
喜欢本文的朋友们,欢迎关注微信公众号“Java面试达人”,收看更多精彩内容
文中出处:https://blog.csdn.net/longzhongxiaoniao/article/details/85727725
session的到底是做什么的?(网摘非常好)
转载站在村口的牛书记 最后发布于2018-02-22 16:20:47 阅读数 56723 收藏
前言:
今天就来彻底的学一些session是个啥东西,我罗列了几个需要知道的要点:
1.session 是啥?
2.怎么保存的?
3.如何运行?
4.有生命周期吗?
5.关闭浏览器会过期吗?
6.Redis代替文件存储session
7.分布式session的同步问题
session是啥?
首先,我大致的知道,session是一次浏览器和服务器的交互的会话,会话是啥呢?就是我问候你好吗?你回恩很好。就是一次会话,那么对话完成后,这次会话就结束了,还有我也知道,我们可以将一个变量存入全部的$_SESSION['name']中,这样php的各个页面和逻辑都能访问到,所以很轻松的用来判断是否登陆。
这是我之前理解的session,当然也是对的,只是解释的太肤浅,理解的太表面了,面试官如果听到这样的答案其实是不太满意的。我参考了其他的很多资料,彻底理解清楚session。
在说session是啥之前,我们先来说说为什么会出现session会话,它出现的机理是什么?我们知道,我们用浏览器打开一个网页,用到的是HTTP协议,学过计算机的应该都知道这个协议,它是无状态的,什么是无状态呢?就是说这一次请求和上一次请求是没有任何关系的,互不认识的,没有关联的。但是这种无状态的的好处是快速。
所以就会带来一个问题就是,我希望几个请求的页面要有关联,比如:我在www.a.com/login.php里面登陆了,我在www.a.com/index.php 也希望是登陆状态,但是,这是2个不同的页面,也就是2个不同的HTTP请求,这2个HTTP请求是无状态的,也就是无关联的,所以无法单纯的在index.php中读取到它在login.php中已经登陆了!
那咋搞呢?我不可能这2个页面我都去登陆一遍吧。或者用笨方法这2个页面都去查询数据库,如果有登陆状态,就判断是登陆的了。这种查询数据库的方案虽然可行,但是每次都要去查询数据库不是个事,会造成数据库的压力。
所以正是这种诉求,这个时候,一个新的客户端存储数据方式出现了:cookie。cookie是把少量的信息存储在用户自己的电脑上,它在一个域名下是一个全局的,只要设置它的存储路径在域名www.a.com下 ,那么当用户用浏览器访问时,php就可以从这个域名的任意页面读取cookie中的信息。所以就很好的解决了我在www.a.com/login.php页面登陆了,我也可以在www.a.com/index.php获取到这个登陆信息了。同时又不用反复去查询数据库。
虽然这种方案很不错,也很快速方便,但是由于cookie 是存在用户端,而且它本身存储的尺寸大小也有限,最关键是用户可以是可见的,并可以随意的修改,很不安全。那如何又要安全,又可以方便的全局读取信息呢?于是,这个时候,一种新的存储会话机制:session 诞生了。
我擦,终于把session是怎么诞生的给圆清楚了,不容易啊!!!
好,session 诞生了,从上面的描述来讲,它就是在一次会话中解决2次HTTP的请求的关联,让它们产生联系,让2两个页面都能读取到找个这个全局的session信息。session信息存在于服务器端,所以也就很好的解决了安全问题。
session的运行机制和是怎么保存的?
既然,它也是一种服务区存储数据的方式,肯定也是存在服务器的某个地方了。确实,它存在服务器的/tmp 目录下,这一点我们接下来慢慢讲。
我们先说下它的运行机制,是怎么分配的。我们主要用PHP中session的机制,其实各种语言都差不多。
如果这个时候,我们需要用到session,那我们第一步怎么办呢?第一步是开启session:
session_start();
这是个无任何返回值的函数,既不会报错,也不会成功。它的作用是开启session,并随机生成一个唯一的32位的session_id,类似于这样:
4c83638b3b0dbf65583181c2f89168ec
session的全部机制也是基于这个session_id,它用来区分哪几次请求是一个人发出的。为什么要这样呢?因为HTTP是无状态无关联的,一个页面可能会被成百上千人访问,而且每个人的用户名是不一样的,那么服务器如何区分这次是小王访问的,那次是小名访问的呢?所以就有了找个唯一的session_id 来绑定一个用户。一个用户在一次会话上就是一个session_id,这样成千上万的人访问,服务器也能区分到底是谁在访问了。
我们做个试验,看看,是不是这样的:
我们在php.iyangyi.com 域名下的a.php 页面中,输入如下代码:
session_start(); echo "SID: ".SID."
"; echo "session_id(): ".session_id()."
"; echo "COOKIE: ".$_COOKIE["PHPSESSID"];
我们访问一下a.php页面,看能输出什么?
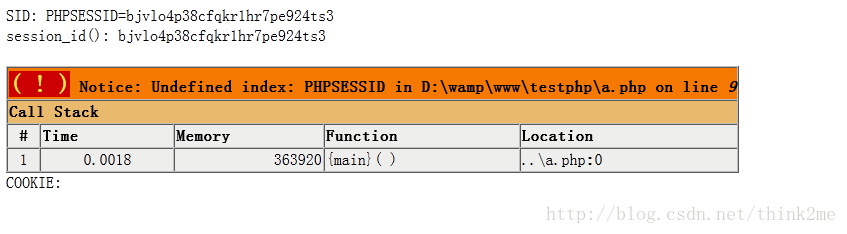
我们看到居然还有一个警告。我们先一个一个的看。首先SID这个常量,我们没有给它赋值,它居然能有输出,其次session_id()这个系统方法是输出本次生成的session_id。最后$_COOKIE['PHPSESSIID'] 没有值,这个我们接下来说。
好,我们再次刷新这个页面,我们能看到什么?
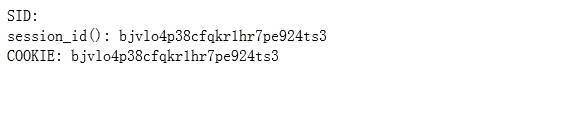
奇怪的事情发生了。SID 没有值了,$_COOKIE['PHPSESSID']中有值了。而且,2次刷新,session_id 都是一样
的:bjvlo4p38cfqkr1hr7pe924ts3,实际情况下,只要不关闭网页,怎么刷新都是一样:
既然我们看到COOKIE中有值了,我们,打开firebug开看到底是什么:
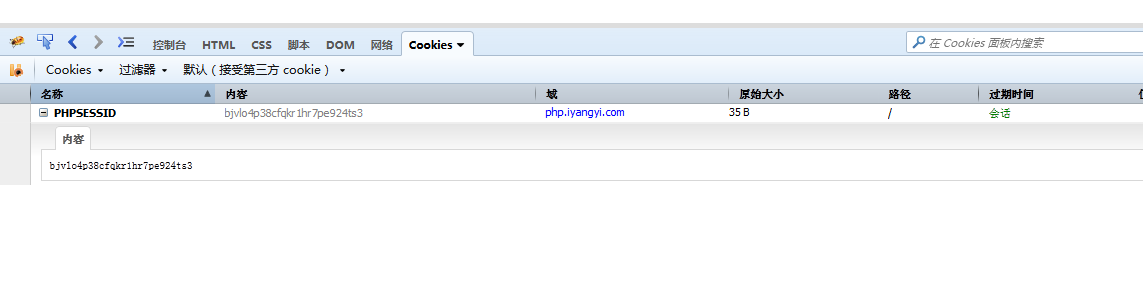
而且这个PHPSESSID的过期时间是会话,什么意思呢?就是浏览器只要不关就一直不存,浏览器一关就过期,消失了。
好,我们关掉浏览器,重新打开a.php页面,看看有没有什么变化:
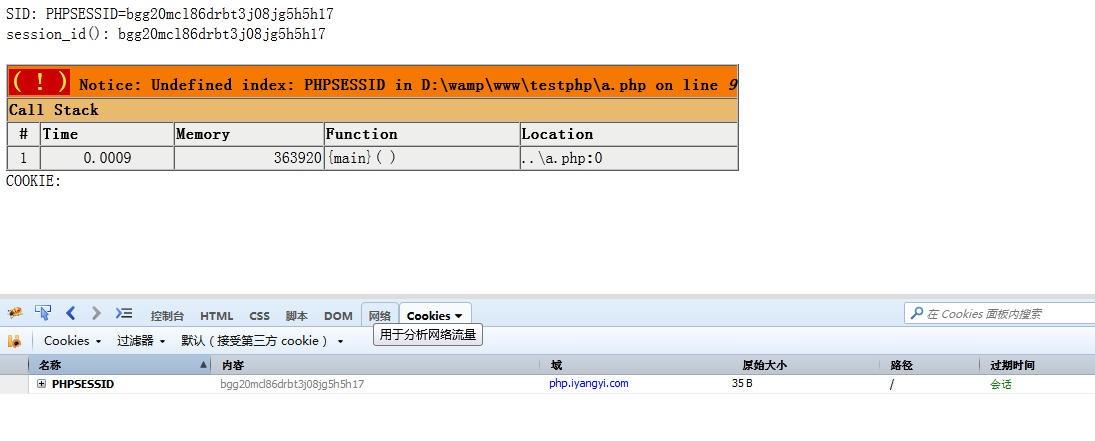
你看,是不是又回到当初第一次打开时候的样子。
OK,解惑的时候到了:
每次我们访问一个页面,如果有开启session,也就是有session_start() 时,就会自动生成一个session_id 来标注是这次会话的唯一ID,同时也会自动往cookie里写入一个名字为PHPSESSID的变量,它的值正是session_id,当这次会话没结束,再次访问的时候,服务器会去读取这个PHPSESSID的cookie是否有值有没过期,如果能够读取到,则继续用这个session_id,如果没有,就会新生成一个session_id,同时生成PHPSESSID这个cookie。由于默认生成的这个PHPSESSID cookie是会话,也就是说关闭浏览器就会过期掉,所以,下次重新浏览时,会重新生成一个session_id。
好,这个是session_id,就用来标识绑定一个用户的,既然session_id生成了。那么当我们往session里面写入数据,是如何保存的,答案是保存在服务器的临时目录里,根据php.ini的配置,我机子上的这个session是存在D:\wamp\tmp 目录里的。我们先说是存在这个目录下,然后待会将如何修改。
那么它是怎么存的呢?
同样也是用到session_id。session_id是32位的,服务器会用 sess_前缀 + session_id 的形式存在这个临时目录下,比如上面这个例子:
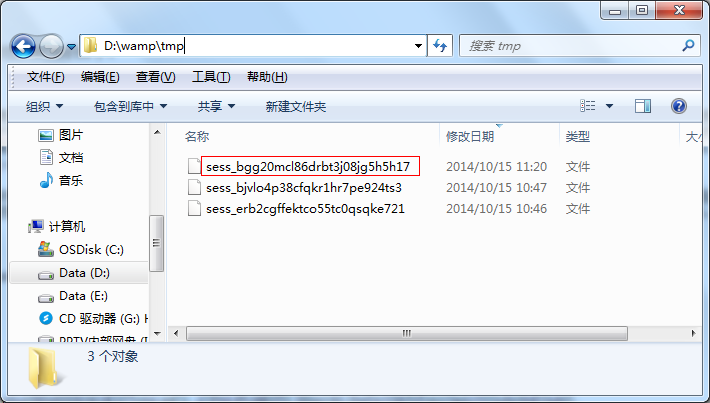
所以,每一次生成的session_id都会生成一个这样的文件,用来保存这次会话的session信息。
我们往session里写入些数据,来看看session是怎么往这个文件里写数据的,我们同样在a.php页面继续加上写入session的语句:
$_SESSION['hello'] = 123;$_SESSION['word'] = 456;
然后,我刷新页面,由于我并没有关闭页面,就这是说这次会话还没结束,那么肯定还会是同样的session_id : bjvlo4p38cfqkr1hr7pe924ts3
然后,我们 用编辑器打开它的存储文件sess_bgg20mcl86drbt3j08jg5h5h17这个文件,看看里面是啥?
hello|i:123;word|i:456;
是序列化的数据,我们肉眼也能读出来。当我们往$_SESSION全局变量里写数据时,它会自动往这个文件里写入。读取session的时候,也会根据session_id 找到这个文件,然后读取需要的session变量。
这个sess文件不会随着客户端的PHPSESSID过期,也一起过期掉,它会一直存在,出息GC扫描到它过期或者使用session_destroy()函数摧毁,我们在下面讲到session·回收的时候会说到。
我们大致总结下:
HTTP请求一个页面后,如果用到开启session,会去读cookie中的PHPSESSID是否有,如果没有,则会新生成一个session_id,先存入cookie中的PHPSESSID中,再生成一个sess_前缀文件。当有写入$_SESSION的时候,就会往sess_文件里序列化写入数据。当读取的session变量的时候,先会读取cookie中的PHPSESSID,获得session_id,然后再去找这个sess_sessionid文件,来获取对应的数据。由于默认的PHPSESSID是临时的会话,在浏览器关闭后,会消失,所以,我们重新访问的时候,会新生成session_id和sess_这个文件。
好。session生成和保存将清楚了。我们再来看前面提到的几个变量:
echo "SID: ".SID."<br>";echo "session_id(): ".session_id()."<br>";echo "COOKIE: ".$_COOKIE["PHPSESSID"];
SID 是一个系统常量,SID包含着会话名以及会话 ID 的常量,格式为 "name=ID",或者如果会话 ID 已经在适cookie 中设定时则为空字符串,第一次显示的时候输出的是SID的值,当你刷新的时候,因为已经在cookie中存在,所以显示的是一个空字符串。
session_id() 函数用来返回当前会话的session_id,它会去读取cookie中的name,也就是PHPSESSID值。
session的相关配置
上面巴拉巴拉废话说了那么多,应该是可以理解session的一套机制了的,我接下来看看,前面零星的提到了php.ini里面有关于session相关的配置。我们打开php.ini来,搜索session相关,我主要把用到的几个给列出来:
[Session]session.save_handler = filessession.save_path = "d:/wamp/tmp"session.use_cookies = 1session.name = PHPSESSIDsession.auto_start = 0session.cookie_lifetime = 0session.serialize_handler = phpsession.gc_divisor = 1000session.gc_probability = 1session.gc_maxlifetime = 1440
主要我们用到的,常见的大概就是这几个。我们一个一个的说。
session.save_handler = files 表示的是session的存储方式,默认的是files文件的方式保存,sess_efdsw34534efsdfsfsf3r3wrresa, 保存在 session.save_path = "d:/wamp/tmp" 里,所有这2个都是可配值得。我们上面的例子就是用的这种默认的方式。
save_handler 不仅仅只能用文件files,还可以用我们常见的memcache 和 redis 来保存。这个我们后面来说。
session.use_cookies 默认是1,表示会在浏览器里创建值为PHPSESSID的session_id,session.name = PHPSESSID 找个配置就是改这个名字的,你可以改成PHPSB, 那这样就再浏览器里生成名字为PHPSB的session_id 。`(∩_∩)′
session.auto_start = 0 用来是否需要自动开启session,默认是不开启的,所有我们需要在代码中用到session_start();函数开启,如果设置成1,那么session_id 也会自动就生成了。
session.cookie_lifetime = 0 这个是设置在客户端生成PHPSESSID这个cookie的过期时间,默认是0,也就是关闭浏览器就过期,下次访问,会再次生成一个session_id。所以,如果想关闭浏览器会话后,希望session信息能够保持的时间长一点,可以把这个值设置大一点,单位是秒。
gc_divisor, gc_probability, gc_maxlifetime 这3个也是配合一起使用,他们是干嘛的呢?他们是干大事情的,回收这些sess_xxxxx 的文件,它是按照这3个参数,组成的比率,来启动GC删除这些过期的sess文件。gc_maxlifetime是sess_xxx文件的过期时间。具体可以参考这个,我觉得他说我比我清楚: session的垃圾回收机制
session的垃圾回收
我们通过上面的各种,已经清楚session的种种了,它会产生各种的sess_前缀的文件,久而久之就会形成垃圾数据,而且正常的session读取也会造成压力,所以及时的清理是蛮有用的。
\1. 代码处理
php代码中有几个函数是用来清理过期的session信息的,主要是这几个:
unset($_SESSION['hello']);session_unset();session_destroy();setcookie(session_name(), '', time()-42000, '/');
unset 这是是常用的销毁标量的方法,不多说,唯一要说的是删除session ,就是将这个sess_xxx的文件的hello变量给删除了,其他的变量该有的都保存着。而 session_unset() 这个不穿参数,这个是销毁sess_xxx文件中的所有变量,但是这个sess_xxx文件还是保存着。而session_destroy 则更狠角了,它是直接将这个sess_xxx文件给删掉。
一般退出操作里面,我们也会将session_name() 获得到的PHPSESSID也给过期掉,删掉,因为网页没关,不这样删除的话,刷新之后,找个值是存在的,服务器将会重新创建一个一模一样session_id的sess文件。
\2. php gc 自动删除
php.ini中的几个销毁sess_xxx文件的配置,在上面说了:
session.gc_divisor = 1000session.gc_probability = 1session.gc_maxlifetime = 1440
简单说下,其实上面的一个超链接的博客讲的很清楚了,php触发gc删除过期的sess_x的文件的概念是这样计算的:概率= gc_probability/gc_divisor,上面的默认的参数,也就是说概念是1/1000的概念,在页面启动session_start() 函数时候,会触发gc删除过期的sess_文件。这个概率其实是蛮小的
所以,我们可以将这个概念调整大一点,比如:将gc_probability 也调成1000,那gc_probability/gc_divisor 就等于1了,也就是百分一百会触发。这样就垃圾回收概率就大的多。
用redis存储session
上面七七八八说了很多关于session的存储啊机制啊等。现在说说如果用redis 存储session。之前说的都是用文件files存储,现在想用redis,好处有哪些?
- 更快的读取和写入速度。redis是直接操纵内存数据的,肯定是要比文件的形式快很多。
- 更好的设置好过期时间。文件存储的sess_sdewfrsf文件其实被删除掉还是要考运气的和概率的,很有可能造成sess_文件没即时删除,造成存储磁盘空间过多,和读取SESSION就变慢了。
- 更好的分布式同步。设置redis 的主从同步,可以快速的同步session到各台web服务器,比文件存储更加快速。
总的说来,用redis来存储SESSION速度更快,性能更高。
要做的第一件事,当然就是安装redis了。具体安装和配置php与redis,就不细说了,可以参考我写的redis相关:redis安装与配置
redis 安装好了之后,接下来就是修改php.ini了。将原来的files 改成redis:
session.save_handler = redissession.save_path = "tcp://127.0.0.1:6381"
需要用到tcp来连接redis,如果你设置reids 有密码访问的话,这样加上就可以了:tcp://127.0.0.1:6381?auth=authpwd
重启web服务器后,你就可以正常使用SESSION了。和之前使用files存储SESSION一模一样。
我们看下redis 是怎么存储session的。它是用了有别于文件存储使用sess_前缀的名字,它用PHPREDIS_SESSION: 前缀,再加上session_id 的形式,是一个string 字符串类型,带生存周期的。
PHPREDIS_SESSION:i9envsatpki9q8kic7m4k68os5
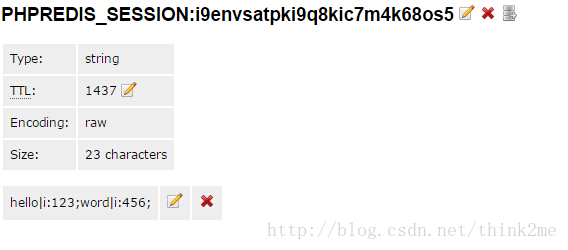
你会发现,它的值和文件存储session一模一样,都是用php序列化后存储,而且有明确的过期时间,是根据配置:session.gc_maxlifetime = 1440 来设定的,默认1440秒。当然你可以修改成其他的。
我们写入和读取每页还是一模一样,包括删除和情况,都是一模一样,没有什么变化:
session_start(); //开启session,如果读不到cookie,会重新生成一个session_id,redis里面也会新生成一个。echo "SID: ".SID."<br>";echo "session_id(): ".session_id()."<br>";echo "COOKIE: ".$_COOKIE["PHPSESSID"];$_SESSION['hello'] = 123; // 写入session 。会序列化后写入redis中$_SESSION['word'] = 456;var_dump($_SESSION['word']); //读session。会从redis读到,解序列后,读出这个值。redis 1440秒过期后,将读不到。unset($_SESSION['hello']); // 删除 hello 的session 。会删除 redis的hello值session_unset(); // 清空redis 中这个session_id的所有值。session_destroy(); // 删除掉这个PHPREDIS_SESSION:i9envsatpki9q8kic7m4k68os5 key。
session同步
在做了web集群后,你肯定会首先考虑session同步问题,因为通过负载均衡后,同一个IP访问同一个页面会被分配到不同的服务器上,如果不同的服务器用的是不同的reidis服务,那么可能就会出现,一个登录用户,一会是登录状态,一会又不是登录状态。所以session这个时候就要同步了。刚好,我们选择用redis作为了存储,是可以在多台redis 服务器中同步的。
具体可以搜索 reidis主从同步或者redis 集群
参考资料:
http://blog.sina.com.cn/s/blog_5f54f0be0100xs7e.html
http://star0708.blog.163.com/blog/static/181091248201341710100381/
http://baike.baidu.com/view/25258.htm?fr=aladdin
http://www.cnblogs.com/hongfei/archive/2012/06/17/2552434.html
关于Session和Cookie的简单介绍(网摘)
在web开发中,Session和Cookie是常用的会话跟踪技术,分别可以在服务端和客户端记录用户的信息。在本篇博客中会对他们做一个简单的介绍。
1.Cookie
1.1Cookie机制
理论上讲,一个用户的所有的请求都属于同一个会话,不能与其他的用户混淆,如A加入到购物车的商品不能出现在B的购物车内。
然而实际上,Web应用使用HTTP协议传输数据,而HTTP属于无状态协议,一旦数据交换完毕就会断开连接,也就意味着无法从连接上跟踪会话。
1.2什么是Cookie
Cookie实际上时一小段文本,其工作原理是,如果服务端需要记录一段信息,就是要response想浏览器发送一段Cookie,客户端保存,浏览器在发送请求时会将URL连同Cookie一起发送给服务器,这样服务器就可以通过它来确认客户身份。
在浏览器地址栏输入javascript:alert(document.cookie)可以查看服务器发送的Cookie
1.3服务器操作Cookie
//javax.servlet.http.Cookie对象使用key-value属性对的形式保存用户状态,一个Cookie对象保存一个属性对,一个request或者response同时使用多个Cookierequest.getCookie();//获取客户端提交的所有的Cookie,返回Cookie[]resopnse.setCookie();//向客户端发送Cookie
1.4Javascript操作Cookie
<script>document.write(document.cookie);</script>
不过,W3C规定,A网站的JS不能操作B网站的Cookie。
1.5Cookie的不可跨域性
需要注意的是,虽然网站images.google.com与网站www.google.com同属于Google,但是域名不一样,二者同样不能互相操作彼此的Cookie。
用户登录网站www.google.com之后会发现访问images.google.com时登录信息仍然有效,而普通的Cookie是做不到的。需要设置domain属性。
1.6关于保存中文
中文不同于英文属于ASCII字符占两个字节,而是属于Unicode字符占四个字节,所以要使用UTF8编码,否则会乱码。
1.7 Cookie的其他属性
String name 该Cookie的名称,一旦创建,名称便不可更改
Object value
int maxAge 失效时间,正数表示maxAge后失效;负数表示关闭浏览器后失效;0表示删除;默认-1;
Sting path 路径,只有在路径下的程序才可以访问Cookie,注意最后一个字符应该是“/”
String domain 域名,设置可与访问该Cookie的域名,注意第一个字符应该是“.”
String comment 说明,浏览器用来显示
1.8利用Cookie实现永久登录
cookie保存用户名+密码,直接保存密码比较危险,可以进行加密,或者可以不保存密码,保存上次登录的时间戳,然后把maxAge设置为Integer.MAX_VALUE
还有一种方式,将用户名进行一定规则的加密,然后将加密后的ssid与用户名保存,登陆时比对即可实现不查询数据
2.Session
2.1Session机制
Session是服务端记录客户端状态的机制,使用简单,但是增加了服务器的存储压力。Session机制决定了当前客户只会获取到自己的Session,而不会获取到别人的Session。各客户的Session也彼此独立,互不可见。
2.2什么是Session
客户端访问服务器是,服务器回通过session的方式将信息保存下来,当客户端再次访问服务器时,只需要检查服务器中Session的状态就可以了。为了高效的存储速度,服务器会把Session存储到内存中,每个用户有一个独立的Session,如果Session过于复杂,那么再大量用户访问的情况下可能存在内存溢出。
2.3服务器操作Session
//javax.servlet.http.HttpSession。每个来访者对应一个Session对象,Session对象是在客户端第一次请求服务器的时候创建的HttpSession session = request.getSession(); // 获取Session对象session.setAttribute(“loginTime”, new Date()); // 设置Session中的属性session.getAttribute(“loginTime”); // 获取Session属性
2.4Session的生命周期
Session在第一次访问服务器的时候就创建了,创建之后 ,用户继续访问就会刷新最后访问时间,此时服务器会认为该Session活跃了一次。
2.5Session的有效期
服务器会把长时间没有活跃的Session从内存删除,这个时间就是Session超时时间maxInactiveInterval,可以通过对应的getMaxInactiveInterval()获取,通过setMaxInactiveInterval(longinterval)修改,也可以在web.xml中修改。
另外,通过调用Session的invalidate()方法可以使Session失效。
Tomcat中Session的默认超时时间为20分钟。通过setMaxInactiveInterval(int seconds)修改超时时间。可以修改web.xml改变Session的默认超时时间。例如修改为60分钟:
注意:
2.6Session常用方法
void setAttribute(String attribute, Object value) 设置Session属性。value参数可以为任何Java Object。通常为Java Bean。value信息不宜过大
String getAttribute(String attribute) 返回Session属性
Enumeration getAttributeNames() 返回Session中存在的属性名
void removeAttribute(String attribute) 移除Session属性
String getId() 返回Session的ID。该ID由服务器自动创建,不会重复
long getCreationTime() 返回Session的创建日期。返回类型为long,常被转化为Date类型
long getLastAccessedTime() 返回Session的最后活跃时间。返回类型为long
int getMaxInactiveInterval() 返回Session的超时时间。单位为秒。超过该时间没有访问,服务器认为该Session失效
void setMaxInactiveInterval(int second) 设置Session的超时时间。单位为秒
void invalidate() 使该Session失效
2.7 对浏览器的要求
虽然Session保存在服务器,对客户端是透明的,它的正常运行仍然需要客户端浏览器的支持。这是因为Session需要使用Cookie作为识别标志。HTTP协议是无状态的,Session不能依据HTTP连接来判断是否为同一客户,因此服务器向客户端浏览器发送一个名为JSESSIONID的Cookie,它的值为该Session的id(也就是HttpSession.getId()的返回值)。Session依据该Cookie来识别是否为同一用户。
该Cookie为服务器自动生成的,它的maxAge属性一般为–1,表示仅当前浏览器内有效,并且各浏览器窗口间不共享,关闭浏览器就会失效。
因此同一机器的两个浏览器窗口访问服务器时,会生成两个不同的Session。但是由浏览器窗口内的链接、脚本等打开的新窗口除外。这类子窗口会共享父窗口的Cookie,因此会共享一个Session。
注意:新开的浏览器窗口会生成新的Session,但子窗口除外。子窗口会共用父窗口的Session。例如,在链接上右击,在弹出的快捷菜单中选择“在新窗口中打开”时,子窗口便可以访问父窗口的Session。
2.8URL地址重定向
如果客户端浏览器将Cookie功能禁用,或者不支持Cookie怎么办?例如,绝大多数的手机浏览器都不支持Cookie。Java Web提供了另一种解决方案:URL地址重写。
URL地址重写的原理是将该用户Session的id信息重写到URL地址中。服务器能够解析重写后的URL获取Session的id。这样即使客户端不支持Cookie,也可以使用Session来记录用户状态。
http://localhost:8080/lqcs/platform/console/main.ht;jsessionid=05AFE2DB628C017317326E38C2C2E656
既然WAP上大部分的客户浏览器都不支持Cookie,索性禁止Session使用Cookie,统一使用URL地址重写会更好一些。Java Web规范支持通过配置的方式禁用Cookie,在以后的博客中会做相关的介绍。
Session介绍(网摘)
Session原理
Web三大概念:cookie,session,application
Session:记录一系列状态
Session与cookie功能效果相同。Session与Cookie的区别在于Session是记录在服务端的,而Cookie是记录在客户端的。
解释session:当访问服务器否个网页的时候,会在服务器端的内存里开辟一块内存,这块内存就叫做session,而这个内存是跟浏览器关联在一起的。这个浏览器指的是浏览器窗口,或者是浏览器的子窗口,意思就是,只允许当前这个session对应的浏览器访问,就算是在同一个机器上新启的浏览器也是无法访问的。而另外一个浏览器也需要记录session的话,就会再启一个属于自己的session
原理:HTTP协议是非连接性的,取完当前浏览器的内容,然后关闭浏览器后,链接就断开了,而没有任何机制去记录取出后的信息。而当需要访问同一个网站的另外一个页面时(就好比如在第一个页面选择购买的商品后,跳转到第二个页面去进行付款)这个时候取出来的信息,就读不出来了。所以必须要有一种机制让页面知道原理页面的session内容。
问题:如何知道浏览器和这个服务器中的session是一一对应的呢?又如何保证不会去访问其它的session呢?
原理解答:就是当访问一个页面的时候给浏览器创建一个独一无二的号码,也给同时创建的session赋予同样的号码。这样就可以在打开同一个网站的第二个页面时获取到第一个页面中session保留下来的对应信息(理解:当访问第二个页面时将号码同时传递到第二个页面。找到对应的session。)。这个号码也叫sessionID,session的ID号码,session的独一无二号码。
session的两种实现方式(也就是传递方式):第一种通过cookies实现。第二种通过URL重写来实现
第一种方式的理解:就是把session的id 放在cookie里面(为什么是使用cookies存放呢,因为cookie有临时的,也有定时的,临时的就是当前浏览器什么时候关掉即消失,也就是说session本来就是当浏览器关闭即消失的,所以可以用临时的cookie存放。保存再cookie里的sessionID一定不会重复,因为是独一无二的。),当允许浏览器使用cookie的时候,session就会依赖于cookies,当浏览器不支持cookie后,就可以通过第二种方式获取session内存中的数据资源。
第二种方式的理解:在客户端不支持cookie的情况下使用。为了以防万一,也可以同时使用。
如果不支持cookie,必须自己编程使用URL重写的方式实现。
如何重写URL:通过response.encodeURL()方法
encodeURL()的两个作用
第一个作用转码(说明:转中文的编码,或者一些其他特殊的编码。就好比如网页的链接中存在中文字符,就会转换成为一些百分号或者其他的符号代替。)
第二个作用:URL后面加入sessionID,当不支持cookie的时候,可以使用encodeURL()方法,encodeUTL()后面跟上sessionID,这样的话,在禁用cookie的浏览器中同时也可以使用session了。但是需要自己编程,只要链接支持,想用session就必须加上encodeURL()。
提示:若想程序中永远支持session,那就必须加上encodeURL(),当别人禁用了cookie,一样可以使用session。
简单的代码例子:在没有使用encodeURL()方法前的代码

在使用encodeURL()方法后的代码

看下图,当重写URL 的时候,每一次访问的时候都会将sessionID传过来,传过来了,就没有必要再在cookie里读了。
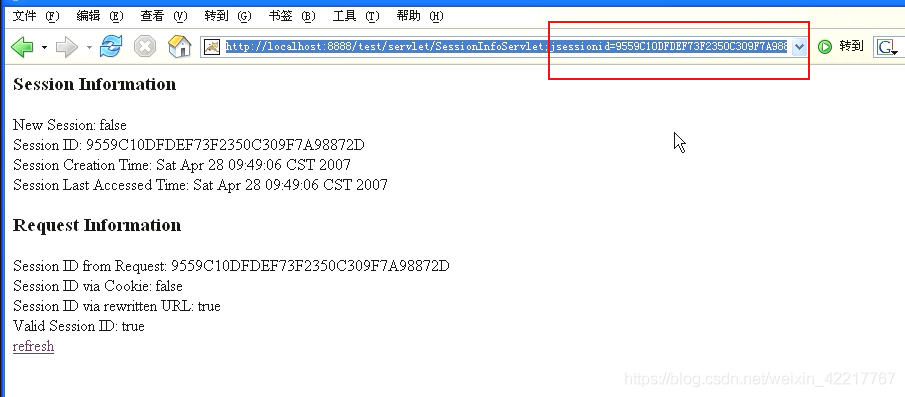
规则:
如果浏览器支持cookie,创建session多大的时候,会被sessionID保存再cookie里。只要允许cookie,session就不会改变,如果不允许使用cookie,每刷新一次浏览器就会换一个session(因为浏览器以为这是一个新的链接)
如果不支持cookie,必须自己编程使用URL重写的方式实现session
Session不像cookie一样拥有路径访问的问题,同一个application下的servlet/jsp都可以共享同一个session,前提下是同一个客户端窗口。
Session中的一些常用方法说明
isNew():是否是新的Session,一般在第一次访问的时候出现
getid():拿到session,获取ID
getCreationTime():当前session创建的时间
getLastAccessedTime():最近的一次访问这个session的时间。
getRrquestedSessionid: 跟随上个网页cookies或者URL传过来的session
isRequestedSessionIdFromCookie():是否通过Cookies传过来的
isRequestedSessionIdFromURL():是否通过重写URL传过来的
isRequestedSessionIdValid():是不是有效的sessionID
其中下面的结果图对应上面的8个方法
其对应的代码
session有期限:
当一个网站的第一个窗口关掉了,而没有继续接着访问第二个页面,就没有使用到session。那么session会在中断程序后立刻关闭session吗?这个时候session就需要给它保留的时间,当最近一次访问的时候开始计时,每刷新一次重写开始计时。当隔了这么久的时间,没有访问这个session后,对不起,要关闭这个session了。session有过期时间,session什么时候过期,要看配置,
session能干什么:
session就是服务器里面的一块内存,内存里面能放任何东西,只要是名值对就可以了。
session里面的名字永远都是String类型
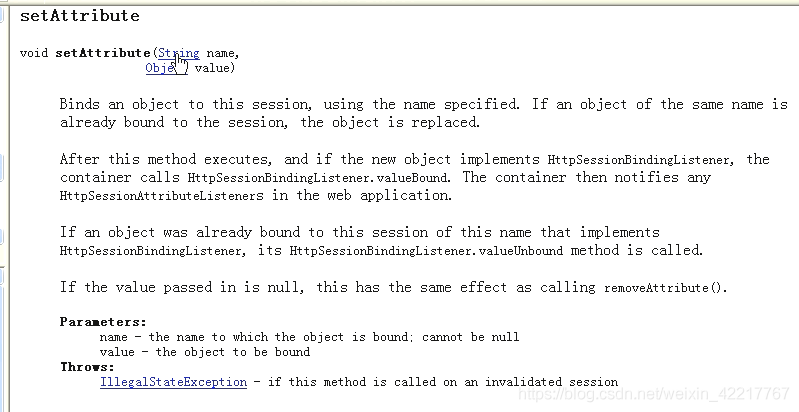
关于Spring框架的小结
1.什么是Spring框架?
Spring是一种轻量级框架,旨在提高开发人员的开发效率以及系统的可维护性。
Spring框架主要是用于创建对象和管理对象的!
-
1.Spring框架主要解决了创建对象和管理对象的问题(比如:UserController);
-
创建对象的3种方式:
-
通过无参数构造方法来创建;
-
<!-- id属性:自定义名称,后续将根据这个名称来获取对象,推荐使用类名将首字母改为小写 --><!-- class属性:需要Spring框架创建哪个类的对象,必须取值是类的全名,即包名与类名 --><bean id="date" class="java.util.Date"></bean>
-
-
通过类中的静态工厂方法来创建;
-
<!-- factory-method:工厂方法的名称,不需要添加参数的括号,且必须与方法名称完全一致 --><bean id="calendar" class="java.util.Calendar" factory-method="getInstance"></bean>
-
-
通过其它类的实例的工厂方法来创建。
-
<!-- 先配置工厂(最原始的方式,用无参构造方式) --><bean id="studentFactory" class="cn.tedu.spring.StudentFactory"></bean><!-- 再配置需要创建对象的类 --><!-- factory-bean与factory-method属性:调用谁的哪个方法可以创建对象 --><bean id="student" class="cn.tedu.spring.Student" factory-bean="studentFactory" factory-method="newInstance"></bean>
-
-
-
-
2.Spring框架的优点在于可以实现解耦,降低组件之间的耦合度(在项目阶段再复习理解);
-
3.掌握通过
<bean>节点配置类,使得Spring能创建并管理这个类的对象;- 用
<bean>节点中的id属性和class属性;
- 用
-
4.了解由Spring管理的对象的作用域(是否单例,懒汉式或饿汉式)与生命周期;(这个使用频率不高)
-
由Spring所管理的对象,默认都是单例的;
-
在Spring的配置文件中,可以为
<bean>节点添加scope属性,scope = singleton是默认的,表示单例,scope = prototype表示非单例; -
所以,如果希望某个类的对象不是单例的,可以配置为:
<bean id="user" class="cn.tedu.spring.User" scope="prototype"></bean> -
还可以在
<bean>节点添加lazy-init属性,以配置单例模式的情况下,是否为懒汉式加载,lazy-init="false",表示"饿汉式加载",此为默认,不写就是默认;lazy-init="true",表示"懒汉式加载";比如:<bean id="user" class="cn.tedu.spring.User" lazy-init="false"> </bean>
-
-
5.掌握通过SET方式为属性注入值,学会区分
value和ref的使用;-
<property>节点:用于配置属性的值;name属性:需要配置值的属性名称,实际是set方法对应的名称;value属性:需要配置值的属性的值; -
值能直接写,就用
value,值不能直接写,对应的值是整个的另外一个<bean>,就用ref=上面这个<bean>的id。 -
<bean id="user" class="cn.tedu.spring.User"> <property name="password" value="123456"/> <property name="age" value="23"/></bean> -
注入List集合类型的值:在
<bean>中添加<list>和<value>,(注意:用array和list都是可以的,但不提倡); -
注入数组类型的值:在
<bean>中添加<array>和<value>; -
注入Set集合类型的值:在
<bean>中添加<set>和<value>; -
注入Map类型的值:在
<bean>中添加<map>和<entry>;
-
-
6.了解通过构造方法为属性注入值;
- 一般在设计项目写代码的时候,都会要求每个类都有无参数构造方法,所以绝大部分需要被Spring管理的组件都具有这样的特点,那么需要为属性注入值的时候,就用Set方式注入值就可以了,就不用构造方法注入值了,所以只是了解就行。
- 使用构造方法注入时,并不要求每个属性都有SET/GET方法;
- 配置时:
constructor-arg节点:配置构造方法的参数。index属性:参数的位置,即第几个参数。
-
7.掌握通过
<util:properties>节点读取.properties中的配置信息;-
这种方式配置Spring时,就和之前的不太一样了:与
<bean>节点并列,在Spring的配置文件中,需要使用<util:properties>节点来读取这个文件,这个节点与<bean>节点是同一个级别的节点,不要将这个节点写在<bean>的子级!在配置时:<util:properties id="jdbc" location="classpath:jdbc.properties"></util:properties><!-- util:properties节点:用于读取.properties文件中的配置信息 --><!-- location属性:需要读取的文件的位置。 (location翻译:位置)--><!-- classpath:指的就是resources文件夹 -->
-
-
8.掌握通过Spring表达式读取另一个Bean中的属性值或者元素;
-
获取另一个Bean中的某个属性的值。
Spring表达式的基本结构/格式就是使用
#{}框住某个式子,如果需要获取另一个Bean中指定的属性的值,格式为:#{Bean的id.属性的名称},例如:在Spring的配置文件中,需要配置为:<bean id="valueBean" class="cn.tedu.spring.ValueBean"> <!-- 属性值是Person对象的username的属性值 --> 因为是Set方式为属性注入值,一定是在<bean>的子级里去加<property> <property name="username" value="#{person.username}"></property> -
获取另一个类的集合属性中的某一个元素。
如果要访问的是
List集合中的某个值,Spring表达式的语法是:#{Bean的id.List集合的属性名[索引位置]}注意:数组和Set集合也是用这种方法。
则配置Spring为:
<!-- 属性值是SampleBean对象中的names(List类型)中的第3个值 --><property name="name" value="#{sampleBean.names[2]}"/> -
获取
Map或Properties类型的数据中的某个元素。获取
Map或Properties类型中的值时,Spring表达式的语法是:#{Bean的id.Map或Properties类型数据的名称.Map的Key或Properties的属性名}则Spring需要配置为:
<!-- 属性值是SampleBean类(对象)中的profile属性(Properties类型)中的gender的值 -->在类SampleBean有://name:Jack, age:25, gender:Maleprivate Properties profile;<property name="gender" value="#{sampleBean.profile.gender}"/><!-- 属性值是SampleBean类(对象)中的session属性(Map类型)中的password的值 -->在类SampleBean有:// {username=root,password:1234, from:Beijing}private Map<String, String> session;<property name="password" value="#{sampleBean.session.password}"/>
-
-
9.掌握组件扫描的机制,及相关配置;
-
组件扫描的机制:
1.在Spring的配置文件中添加:
<context:component-scan base-package="cn.tedu.spring"/>2.在类前添加注解:
@Component当Spring的配置文件被加载时,Spring框架就会扫描以上配置的
cn.tedu.spring包及其子包下的所有内容,检查这些包中是否存在组件,如果存在,就会自动创建这些组件的对象!//【条件1:】这个类在这个包中
//【条件2:】组件注解
//两个条件缺一不可
-
-
10.掌握
@Compontent、@Controller、@Service、@Repository注解的使用;-
还可以使用
@Controller、@Service、@Repository这几种注解,在Spring框架的作用范围之内,它们的作用与@Compontent是完全等效的,使用方式也完全相同,在需要添加注解时,添加以上任意一个即可!(注意,其他框架这几个注解不一定等效。)
这些注解的语义是不同的,后续添加其它有特殊定位的组件,例如控制器类型的组件就应该添加
@Controller注解,业务类型的组件就应该添加@Service注解,处理数据持久化的组件就应该添加@Repository注解,其它类型的组件就应该添加@Compontent注解!
-
-
11.了解
@Scope、@Lazy、@PostConstruct、@PreDestroy注解的使用;-
在类的声明之前添加
@Scope注解可以配置该类被Spring框架管理时是否单例!该注解中可以添加参数"singleton"或"prototype":当设置为@Scope("singleton")时,表示单例,这是默认的管理方法,默认是单例(且饿汉式加载),还可以设置为@Scope("prototype"),表示非单例。 -
使用
@Lazy注解可以配置该类是否为懒加载模式,可以在这个注解中配置的值是布尔值!一般,如果该类不需要是懒汉式加载,则不添加该注解,如果需要是懒汉式加载,直接添加@Lazy注解即可,因为@Lazy和@Lazy(true)是一样的,并不需要设置注解参数!同时,需要先保证该类是单例模式的,才讨论是否懒加载的问题。 -
在自定义的生命周期方法之前添加
@PostConstruct可以表示该方法是生命周期方法中的初始化方法,添加@PreDestroy注解就表示销毁方法。Construct:构造方法 Destroy:销毁 Post:在什么之后 Pre:在什么之前
PostConstruct:在构造方法之后 PreDestroy:在销毁之前
-
-
自动装配的机制:Spring框架会在容器中查询匹配的对象,为需要自动装配的Bean的属性自动赋值!
-
理解自动装配中的
byName和byType的装配机制;-
自动装配的配置就不用了写那么多了,只是在
<bean>标签中加入一个autowire属性即可:在配置时,autowire属性的常用取值可以是byName,表示“按照名称实现自动装配”,也可以是byType,表示“按照类型实现自动装配”,还有其它取值,但一般不使用! -
按照名字自动装配:
<bean id="userDao" class="cn.tedu.spring.UserDao"></bean> <bean id="userLoginServlet" class="cn.tedu.spring.UserLoginServlet" autowire="byName"><!-- autowire="byType" --></bean>按照名字自动装配中Spring 的本质是,当看到UserLoginServlet这个类,在
<bean>中有自动装配的时候,Spring就会去找UserLoginServlet这个类,看这个类中有哪些Set方法,然后在配置里看这个Set方法有没有与之一样名字的<bean>节点,有的话,就把这个<bean>作为参数,拿来调用了: -
按照类型自动装配。
当取值为
byType时,对各个名称都没有要求(包括SET方法,也只需要是以set作为前缀即可,后缀没有任何要求),只要类型能够匹配,就可以实现自动装配的效果!但是,能够匹配类型的对象必须最多只有1个,如果有2个或更多个,则在加载Spring配置文件时就会报错!
-
-
12.理解
@Autowired和@Resource这2个自动装配注解的区别;- 共同点:使用这2种注解都可以实现自动装配!
区别:
@Resource注解是javax包中的注解,它是优先byName来装配的,如果byName无法装配,则会自动尝试byType装配,在byType装配时,要求匹配类型的对象必须有且仅有1个,如果无法装配,则会报告错误;与上面讲的自动装配不同。@Autowired注解是Spring框架中的注解,它是优先byType来装配的,但是,这个过程中,只会检索匹配类型的对象的数量,并不直接装配,如果找到的对象的数量是0个,则直接报错,如果找到的对象的数量是1个,则直接装配,如果找到的对象的数量(类型)超过1个(2个或更多个),则会尝试byName来装配,如果byName装配失败,则报错。(虽然进行试验不能直接看出来,但是这个答案的依据是来自Spring的官方文档,是正确的。)面试时,要知道区别后应该怎么用?
在实际开发项目时,绝大部分情况下,需要装配的对象都是有且仅有1个的,并且命名都是规范的,所以,无论
byType或byName都是可以装配成功,就不必在乎装配方式和做法,在以上2个注解的选取方面,通常也没有明确的要求! -
13.关于Spring AOP会在项目阶段末期再讲。
关于SpringMVC框架的小结
-
1.MVC = Model(数据模型) + View(视图) + Controller(控制器)
-
理解MVC的思想,MVC = Model(厨房:数据加工的) + View + Controller(服务员:直接接触的);
-
SpringMVC框架主要解决了V与C之间的交互问题;
-
-
2.认识SpringMVC框架中的核心组件:
DispatcherServlet、HandlerMapping、Controller、ModelAndView、ViewResolver;-
DispatcherServlet:前端控制器,用于接收所有请求;(最先接受请求,所以叫前端控制器)
-
HandlerMapping:处理器映射器,用于配置请求路径与Controller组件的对应关系;
-
Controller:控制器,具体处理请求的组件;
-
ModelAndView:Controller组件处理完请求后得到的结果,由数据与视图名称组成;
-
ViewResolver:视图解析器,可根据视图名称确定需要使用的视图组件。
-
-
3.理解SpringMVC框架的核心执行流程(参考流程图);
-
第一步:用户发送请求request [rɪˈkwest]到前端控制器DispatcherServlet(
弟死白扯)。第二步:前端控制器 请求 处理器映射器HandlerMapping查找 **Handler **(可以根据xml配置、注解进行查找)。
第三步:处理器映射器HandlerMapping向 前端控制器DispatcherServlet 返回 执行链对象HandlerExecutionChain。
执行链对象:一个Handler处理器+多个HandlerInterceptor拦截器对象
HandlerMapping会把请求映射为HandlerExecutionChain执行链对象(包含一个Handler处理器(页面控制器)对象,多个HandlerInterceptor拦截器对象 in ter 赛 per ter),通过这种策略模式,很容易添加新的映射策略。HandlerExecutionChain(汗的了 ,爱 sei Q 深[ˌeksɪˈkjuːʃn] ,菜恩)第四步:前端控制器调用处理器适配器HandlerAdapter(
汗的了 额带破特)去执行Handler。第五步:处理器适配器在Handler处理器中执行Handler,Handler处理器就是平常所说的Controller控制器,是具体处理请求的组件。
第六步:Handler执行完成后,由控制器Controller给适配器HandlerAdapte返回ModelAndView。(数据模型和视图)
第七步:处理器适配器向前端控制器返回ModelAndView (ModelAndView是springmvc框架的一个底层对象,包括 Model和view)。
第八步:前端控制器请求视图解析器ViewResolver
(瑞招我)去进行视图解析 (根据逻辑视图名解析成真正的视图(jsp)),通过这种策略很容易更换其他视图技术,只需要更改视图解析器即可。第九步:视图解析器向前端控制器返回View。
第十步:前端控制器进行视图渲染 (视图渲染将模型数据(在ModelAndView对象中)填充到request域)。
第十一步:前端控制器向用户响应结果(response
瑞死棒次)。
-
-
4.理解SpringMVC框架的核心配置:在web.xml中关于
DispatcherServlet的配置,在spring.xml中关于组件扫描的配置和视图解析器的一系列配置;-
1.配置
DispatcherServlet:<servlet> <servlet-name>SpringMVC</servlet-name> //两个<servlet-name>,内容不重要,主要要保持名称上下一致,即表示对同一个servlet的配置。一般用`servlet的类的名称,而偷懒的用法是命名为:SpringMVC。 <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class> //为加载Spring的配置文件,配置初始化参数 <init-param> //初始化参数 <param-name>contextConfigLocation</param-name>//初始化的参数的名称——属性名 <param-value>classpath:spring.xml</param-value>//初始化的参数的值 </init-param> <load-on-startup>1</load-on-startup> //启动即初始化。正值越小,servlet的优先级越高,应用启动时就越先加载。</servlet><servlet-mapping> <servlet-name>SpringMVC</servlet-name> <url-pattern>*.do</url-pattern> //什么路径的请求,会被这个servlet所处理 //通配符,通配所有。所有请求后缀为.do的请求发过来,就会被servlet处理。</servlet-mapping> -
2.配置组件扫描:
(1)先在spring.xml中添加组件扫描:
<context:component-scan base-package="cn.tedu.spring" />(2)然后,在组件扫描的包中创建任意类,并在类的构造方法中添加输出语句:(syst)
-
3.配置视图解析器:
配置视图解析器,就要先配置模板引擎,配置模版引擎,就要先配置模板解析器,模板解析器中配置5个属性:字符编码、模板模式、可缓存、前缀、后缀。
实质:前缀拼接上控制器返回的名字再拼接上后缀,从而得到这个文件到底是谁。
配置步骤3: 配置模版解析器。这里配置了 value="/templates/" 这个文件夹的路径。<!-- 配置模版解析器(有多种) --><!-- 当使用ClassLoaderTemplateResolver时,将以src/main/resources作为根文件夹 --><!-- 当使用ServletContextTemplateResovler时,将以webapp作为根文件夹 --><bean id="templateResolver" class="org.thymeleaf.templateresolver.ClassLoaderTemplateResolver"> //要配置ClassLoaderTemplateResolver父类中的5个属性: <property name="characterEncoding" value="utf-8" />字符编码 <property name="templateMode" value="HTML" />模板模式 <property name="cacheable" value="false" />可缓存(不缓存,缓存页面易出问题) <property name="prefix" value="/templates/" />前缀 //前缀指的是你的HTML页面放到哪个文件夹下面的,现在是以/resources为基础来放的 //注意:templates的两边/ 不能省略 <property name="suffix" value=".html" />后缀 //后缀:指文件的扩展名 //其实,最终工作的时候,会用前缀/templates/拼接上控制器返回的名字helloworld //再拼接上后缀.html,从而得到这个文件到底是谁。 //src/main/resources/??? //src/main/resources/前缀(prefix) 返回值 后缀(suffix) //src/main/resources/templates/helloworld.html //相当于字符串的拼接 //所以也可以前缀和后缀都不写,但控制器返回的名字为: //return "templates/helloworld.html";</bean>配置步骤2:配置模版引擎<!-- 配置模版引擎 --><bean id="templateEngine" class="org.thymeleaf.spring4.SpringTemplateEngine"> <property name="templateResolver" ref="templateResolver" /> //templateResolver叫模板解析器,是SpringTemplateEngine父类中的一个属性 //但是没有模板解析器,所以还要在上面配置一个模板解析器</bean>【配置步骤1:配置视图解析器,也就是流程中的第6步:找ViewResolver:视图解析器】<!-- 配置视图解析器 针对Thymeleaf的模版页面的ViewResolver(视图解析器)来配置 --><bean class="org.thymeleaf.spring4.view.ThymeleafViewResolver">//包名 //配置ThymeleafViewResolver的两个属性(只能看官方文档或者别人的博客文章,就是固定的) //其一:只要看到characterEncoding(字符编码),就设置成utf-8 //其二:templateEngine(模板引擎),但是现在没有模板引擎,所以要先配置一个模板引擎出来 //这个属性的值,希望是上面的<bean> <property name="characterEncoding" value="utf-8" /> <property name="templateEngine" ref="templateEngine" /></bean>
-
-
5.掌握自定义控制器,并在控制器中接收客户端提交的请求;
-
1.先在组件扫描的包下创建控制器类;
-
2.命名:以Controller作为名称的后缀,前缀用要处理的数据类型来表示;
-
3.控制器类必须添加
@Controller注解(只能用这个); -
4.在类中添加处理请求的方法!请求发过来,控制器类中有个方法被执行。
关于方法的声明原则:
- 应该使用
public权限; - 暂时使用
String作为返回值类型; - 方法的名称可以自定义;
- 方法的参数列表暂时留空。
- 应该使用
-
5.在处理请求的方法之前,使用
@RequestMapping注解配置请求路径,以绑定请求路径与方法的对应关系:@RequestMapping注解后面的括号内填写参数:@Controllerpublic class HelloController { @RequestMapping("hello.do")//接受hello.do的请求,就会调用紧随其后的showHello这个方法 public String showHello() { System.out.println("HelloController.showHello()"); return null; // 暂且返回null值,避免代码持续报错 return "helloworld"; // 此处返回的就是HTML页面的文件名 }}
-
-
6.掌握处理请求时,2种接收客户端提交的请求参数;
-
(1)使用HttpServletRequest接收请求参数(不推荐使用)。在处理请求的方法的参数列表中添加
HttpServletRequest接口类型的参数,在处理请求的过程中,调用该参数对象的String getParameter(String 参数名称)方法来获取请求参数。但是这种做法一般是不推荐使用的!主要原因有:接收参数的过程比较麻烦;如果期望得到的数据的类型不是String,则需要自行解决数据类型的数据;不便于执行单元测试。例如:在
UserController中添加:@RequestMapping("handle_reg.do")public String handleReg(HttpServletRequest request) { System.out.println("UserController.handleReg()"); //有5个参数,所以写5个 String username = request.getParameter("username"); String password = request.getParameter("password"); Integer age = Integer.valueOf(request.getParameter("age")); String phone = request.getParameter("phone"); String email = request.getParameter("email"); System.out.println("username=" + username); System.out.println("password=" + password); System.out.println("age=" + age); System.out.println("phone=" + phone); System.out.println("email=" + email); return null; // 相当于返回"handle_reg",最后,会打开handle_reg.html页面,此页面目前并不存在,在浏览器中会提示500错误,暂时不关心这个问题。} -
(2)将请求参数声明为处理请求的方法的参数。可以将所需要接收的请求参数直接声明为处理请求的方法的参数,甚至,期望得到的数据是什么类型,就直接声明为对应的类型即可。
例如:在
UserController中添加:@RequestMapping("handle_reg.do")public String handleReg(String username, String password, Integer age, String phone, String email) { System.out.println("UserController.handleReg()"); System.out.println("[2] username=" + username);//前面加[2],表示第2种做法 System.out.println("[2] password=" + password); System.out.println("[2] age=" + age); System.out.println("[2] phone=" + phone); System.out.println("[2] email=" + email); return null; // 相当于返回"handle_reg",最后,会打开handle_reg.html页面,此页面目前并不存在,在浏览器中会提示500错误,暂时不关心这个问题}当请求参数较多时,可以将这些请求参数封装在自定义的数据类型中,这种做法是解决(2)方法的不足。
-
-
7.掌握转发数据;
-
1.使用HttpServletRequest转发数据。(这种做法依然存在“不便于执行单元测试”的问题!)
-
(1)在控制器的处理请求的方法的参数列表中添加
HttpServletRequest类型的参数 -
(2)然后,在需要转发数据时,调用该参数对象的
setAttribute(String name, Object value)方法将数据进行封装即可,例如: -
@RequestMapping("handle_login.do")public String handleLogin(String username, String password,HttpServletRequest request) { String msg = "密码错误"; request.setAttribute("errorMessage", msg); //所以就是往request中封装了这样的一个数据:封装进去给它取得名字叫errorMessage, //值就是上面的字符串:msg。}
-
-
2.使用ModelMap封装需要转发的数据(推荐这种做法)。使用
ModelMap的做法与使用HttpServletRequest几乎相同!即:1.参数列表加一个:ModelMap modelMap。
2.modelMap.addAttribute(),用modelMap调用addAttribute方法。
由于
ModelMap是一种Map,则相对HttpServletRequest而言,是更加易于执行单元测试的!并且更加轻量级一些!如果能保证Key的值不是null,那么调用ModelMap对象的addAttribute()方法或put()方法都行!
-
-
8.掌握重定向;
-
在SpringMVC中,如果控制器中处理请求的方法返回值是
String类型的,则重定向的语法是:return "redirect:目标路径";//redirect翻译:重定向以上语法中,目标路径指的是要打开哪个页面,取值应该是这个页面的地址,也就是在浏览器的地址栏中看到地址,可以使用绝对路径,也可以使用相对路径。
-
-
9.转发与重定向的区别:
-
转发,整个过程中,客户端只发出了1次请求,无论是控制器类的工作,还是页面的工作,它们的合作,是服务器端内部的行为;
重定向,整个过程中,客户端发出了2次请求,分别是客户端第1次发出请求后,服务器端给出了重定向的响应(HTTP响应码为302,客户端只要收到了302就会发出下一次请求),然后,客户端会根据这次响应,自动发出第2次请求!
所以,转发和重定向最大的区别在于:转发过程中,客户端只发出了1次请求,而重定向时,客户端还会发出第2次请求,以至于,转发时,浏览器的地址栏中的URL是不变的,而重定向时,URL是第2次请求的地址。
-
-
10.掌握使用Session;
-
session是啥?
首先,我大致的知道,session是一次浏览器和服务器的交互的会话,会话是啥呢?就是我问候你好吗?你回恩很好。就是一次会话,那么对话完成后,这次会话就结束了,还有我也知道,我们可以将一个变量存入全部的$_SESSION['name']中,这样php的各个页面和逻辑都能访问到,所以很轻松的用来判断是否登陆。
这是我之前理解的session,当然也是对的,只是解释的太肤浅,理解的太表面了,面试官如果听到这样的答案其实是不太满意的。我参考了其他的很多资料,彻底理解清楚session。
在说session是啥之前,我们先来说说为什么会出现session会话,它出现的机理是什么?我们知道,我们用浏览器打开一个网页,用到的是HTTP协议,学过计算机的应该都知道这个协议,它是无状态的,什么是无状态呢?就是说这一次请求和上一次请求是没有任何关系的,互不认识的,没有关联的。但是这种无状态的的好处是快速。
所以就会带来一个问题就是,我希望几个请求的页面要有关联,比如:我在www.a.com/login.php里面登陆了,我在www.a.com/index.php 也希望是登陆状态,但是,这是2个不同的页面,也就是2个不同的HTTP请求,这2个HTTP请求是无状态的,也就是无关联的,所以无法单纯的在index.php中读取到它在login.php中已经登陆了!
那咋搞呢?我不可能这2个页面我都去登陆一遍吧。或者用笨方法这2个页面都去查询数据库,如果有登陆状态,就判断是登陆的了。这种查询数据库的方案虽然可行,但是每次都要去查询数据库不是个事,会造成数据库的压力。
所以正是这种诉求,这个时候,一个新的客户端存储数据方式出现了:cookie。cookie是把少量的信息存储在用户自己的电脑上,它在一个域名下是一个全局的,只要设置它的存储路径在域名www.a.com下 ,那么当用户用浏览器访问时,php就可以从这个域名的任意页面读取cookie中的信息。所以就很好的解决了我在www.a.com/login.php页面登陆了,我也可以在www.a.com/index.php获取到这个登陆信息了。同时又不用反复去查询数据库。
虽然这种方案很不错,也很快速方便,但是由于cookie 是存在用户端,而且它本身存储的尺寸大小也有限,最关键是用户可以是可见的,并可以随意的修改,很不安全。那如何又要安全,又可以方便的全局读取信息呢?于是,这个时候,一种新的存储会话机制:session 诞生了。
我擦,终于把session是怎么诞生的给圆清楚了,不容易啊!!!
好,session 诞生了,从上面的描述来讲,它就是在一次会话中解决2次HTTP的请求的关联,让它们产生联系,让2两个页面都能读取到找个这个全局的session信息。session信息存在于服务器端,所以也就很好的解决了安全问题。
-
关于Session不可用(消失)的原因?
- 1.客户端浏览器关闭或者更换。
- 2.客户端超时。
- 3.服务器重启。
-
哪些数据应该保存到Session中?
- 用户身份的标识,例如用户的id,或用户名等等;
- 使用频率非常高的数据,例如用户名、用户头像等等;
- 不便于使用其它技术或存储方案来临时保存的数据。
-
在SpringMVC框架中,在处理请求的过程中,如果需要访问Session(包含存入数据和取出数据),那么在处理请求的方法的参数列表中直接添加
HttpSession类型的参数,在处理过程中,调用该参数对象的API即可访问数据! -
例如:
-
@RequestMapping(path="handle_login.do", method=RequestMethod.POST)public String handleLogin(String username, String password, ModelMap modelMap, HttpSession session) { System.out.println("UserController.handleLogin()"); if ("root".equals(username)) { // 用户名正确,还需要判断密码 if ("1234".equals(password)) { // 密码也正确,则登录成功 session.setAttribute("uid", 3366); session.setAttribute("username", "root");// 【当前路径】http://localhost:8080/springmvc02/user/handle_login.do// 【目标路径】http://localhost:8080/springmvc02/main/index.do return "redirect:../main/index.do"; } else { // 密码错误,登录失败,暂不关心这段代码 } } else { // 用户名错误,登录失败,暂不关心这段代码 }}
-
-
11.掌握拦截器的使用;
-
拦截器的本质就是将请求给“拦”下来,进行相关判断检查后,选择阻止或放行。
-
在SpringMVC中,自定义类实现
HandlerInteceptor拦截器接口,这个类就会是一个拦截器类! -
拦截器中的
preHandle()返回false,表示阻止运行,如果返回true,就表示放行。 -
配置拦截器:
<!-- 配置拦截器链 --> <mvc:interceptors> <!-- 配置第一个拦截器 --> <mvc:interceptor> <!-- 拦截路径,配置时,必须使用/作为第1个字符 --> <!-- 可以配置若干个需要被拦截的路径 --> <mvc:mapping path="/main/index.do"/> <!-- 拦截器 --> <bean class="cn.tedu.spring.LoginInterceptor"/> </mvc:interceptor> </mvc:interceptors> -
可以把
<mvc:mapping>配置的路径理解为“黑名单”,而<mvc:exclude-mapping>配置的路径理解为“白名单”。
-
-
12.理解拦截器与过滤器的区别;
-
拦截器:Interceptor 【 in ter 赛 per ter】
过滤器:Filter 【飞 哦 特】
其实面试题问两者的区别的时候,其实更多的是想知道什么时候用哪个,什么时候用另外一个。
两者的相同点:
拦截器和过滤器都可以应用于若干个路径,并且使得这些路径的请求在被处理时,都会经过相关检查,最终决定阻止或放行,在同一个项目中,可以有多个拦截器,也可以有多个过滤器,都可以形成“链”。
两者的区别:
1.归属不同。过滤器是Java EE中的组件,需要在web.xml中配置,依赖于Servlet;拦截器是SpringMVC框架中的组件,需要在SpringMVC中配置,依赖于框架;
2.执行时间不同。过滤器是在所有的Servlet组件之前执行的,而拦截器的第1次执行是在
DispatcherServlet之后、在Controller组件之前执行的!3.配置不同。一个过滤器就只有一个配置的路径(但是可以配置多个过滤器),并且只能配置需要过滤的路径(黑名单),却不可以添加例外(白名单),并且,每个路径的配置的节点格式比较繁琐,而拦截器的配置却灵活简洁!所以,在一般情况下,都会优先使用拦截器。
4.两者的本质区别:拦截器(Interceptor)是基于Java的反射机制,而过滤器(Filter)是基于函数回调。从灵活性上说拦截器功能更强大灵活些,Filter能做的事情,都能做,而且可以在请求前,请求后执行,比较灵活。Filter主要是针对URL地址做一个编码的事情、过滤掉没用的参数、安全校验,太细的话,还是建议用interceptor。不过还是根据不同情况选择合适的。
5.但是如果配置字符编码过滤器的时候,则必须使用过滤器,而不能替换成拦截器。比如,解决SpringMVC框架中POST请求提交中文会乱码的问题。
-
-
13.掌握配置
CharacterEncodingFilter以解决处理POST请求时中文乱码的问题。-
前提是POST请求中的提交乱码,如果是Get请求应该不会乱码,即使乱码,也是调整Tomcat里面的配置。
-
SpringMVC框架默认使用的编码都是
ISO-8859-1,这种编码是不支持中文的! -
配置字符编码过滤器:
<!-- 配置字符编码过滤器 --> <filter> <filter-name>CharacterEncodingFilter</filter-name> <filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class> <init-param> <param-name>encoding</param-name> <param-value>utf-8</param-value> </init-param> </filter> <filter-mapping> <filter-name>CharacterEncodingFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping>
-
