hadoop-2.9.2 HA集群搭建
确保每台机器上都有jdk,以下是机器配置。
| 应用/主机名 | zk1 | zk2 | zk3 | namenode1 | namenode2 | datanode1 | datanode2 | datanode3 | |
| zookeeper | y | y | y | ||||||
| namenode | y | y | |||||||
| datanode | y | y | y | ||||||
| journalnode | y | y | y | ||||||
| zkFC | y | y | |||||||
| resourcemanger | y | y | |||||||
| nodemanager | y | y | y | ||||||
1、3台zk,前面的博客已经搭建好了,我只是克隆几台,改了ip,不影响使用。
启动3台zk.
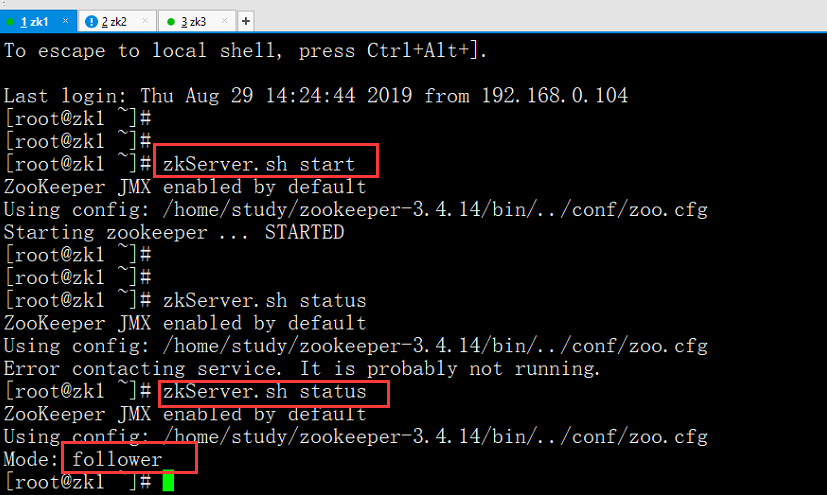
查看状态如果是上面的状态,那就ok.
2、准备两台namenode1,namenode2
我的hadoop位置

进入hadoop 配置文件目录,cd /hadoop-2.9.2/etc/hadoop
1).vi hdfs-site.xml
<property>
<name>dfs.nameservices</name>
<value>laolong</value>
</property>
<property>
<name>dfs.ha.namenodes.laolong</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.laolong.nn1</name>
<value>namenode1:8020</value> //两台namenode
</property>
<property>
<name>dfs.namenode.rpc-address.laolong.nn2</name>
<value>namenode2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.laolong.nn1</name>
<value>namenode1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.laolong.nn2</name>
<value>namenode2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://datanode1:8485;datanode2:8485;datanode3:8485/abc</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.laolong</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/journalnode</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
2).vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://laolong</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.9</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>zk1:2181,zk2:2181,zk3:2181</value>
</property>
3).vi slaves
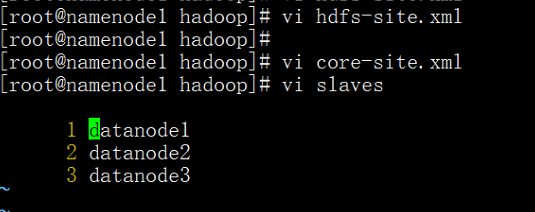
4).vi yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>lyhadoop</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>namenode1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>namenode2</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>zk1:2181,zk2:2181,zk2:2181</value>
</property>
5).vi hadoop-env.sh

6).先启动三个JournalNode:./hadoop-daemon.sh start journalnode
7).在其中一个namenode上格式化:hdfs namenode -format
8).把格式化的文件拷贝到另一台namenode上,可以通过scp方式拷贝
9).在其中一个namenode上初始化zkfc:hdfs zkfc -formatZK
10).启动集群:start-dfs.sh stop-dfs.sh 停止
启动 后,通过浏览器访问
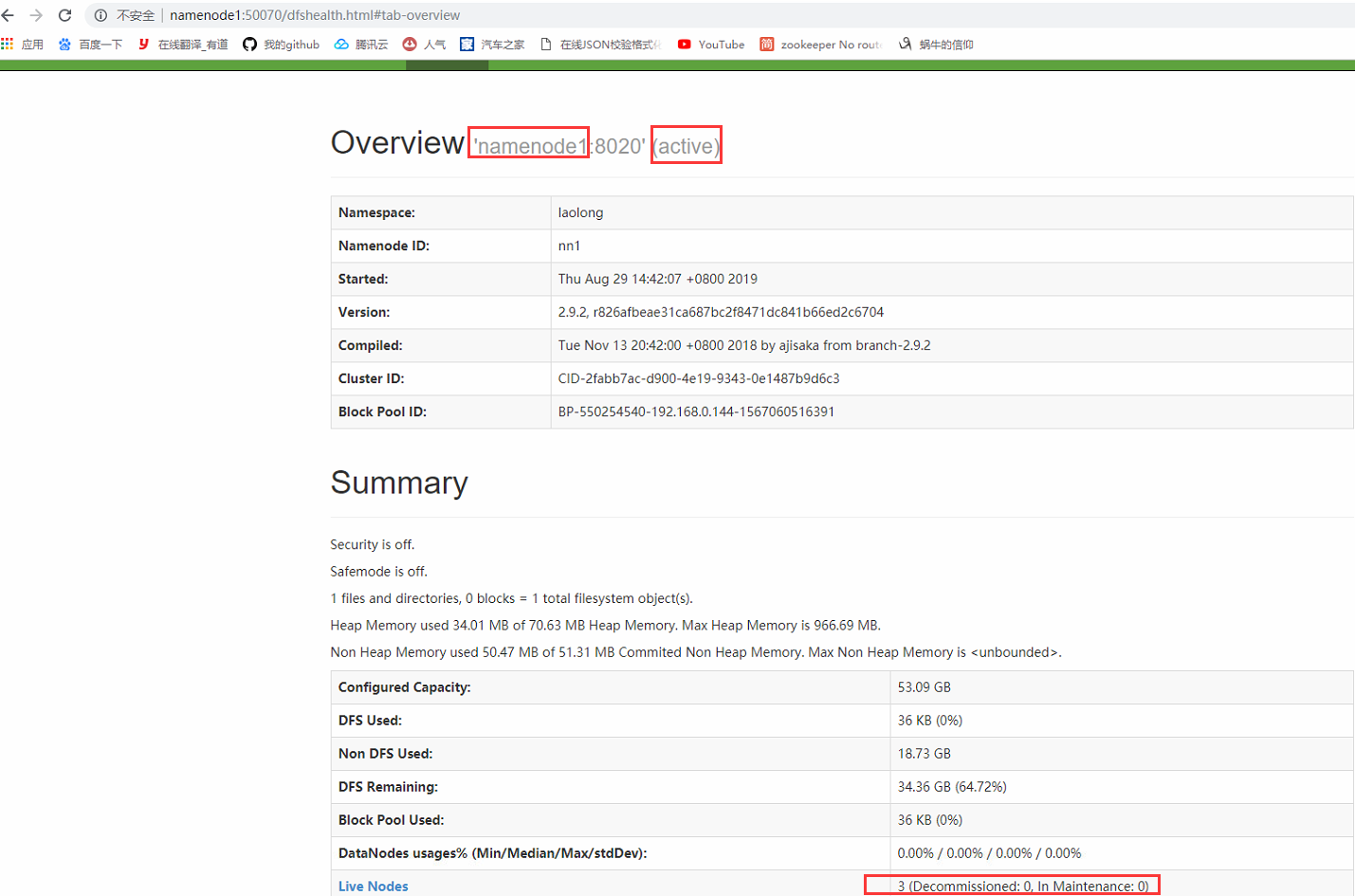
访问另一台namenode
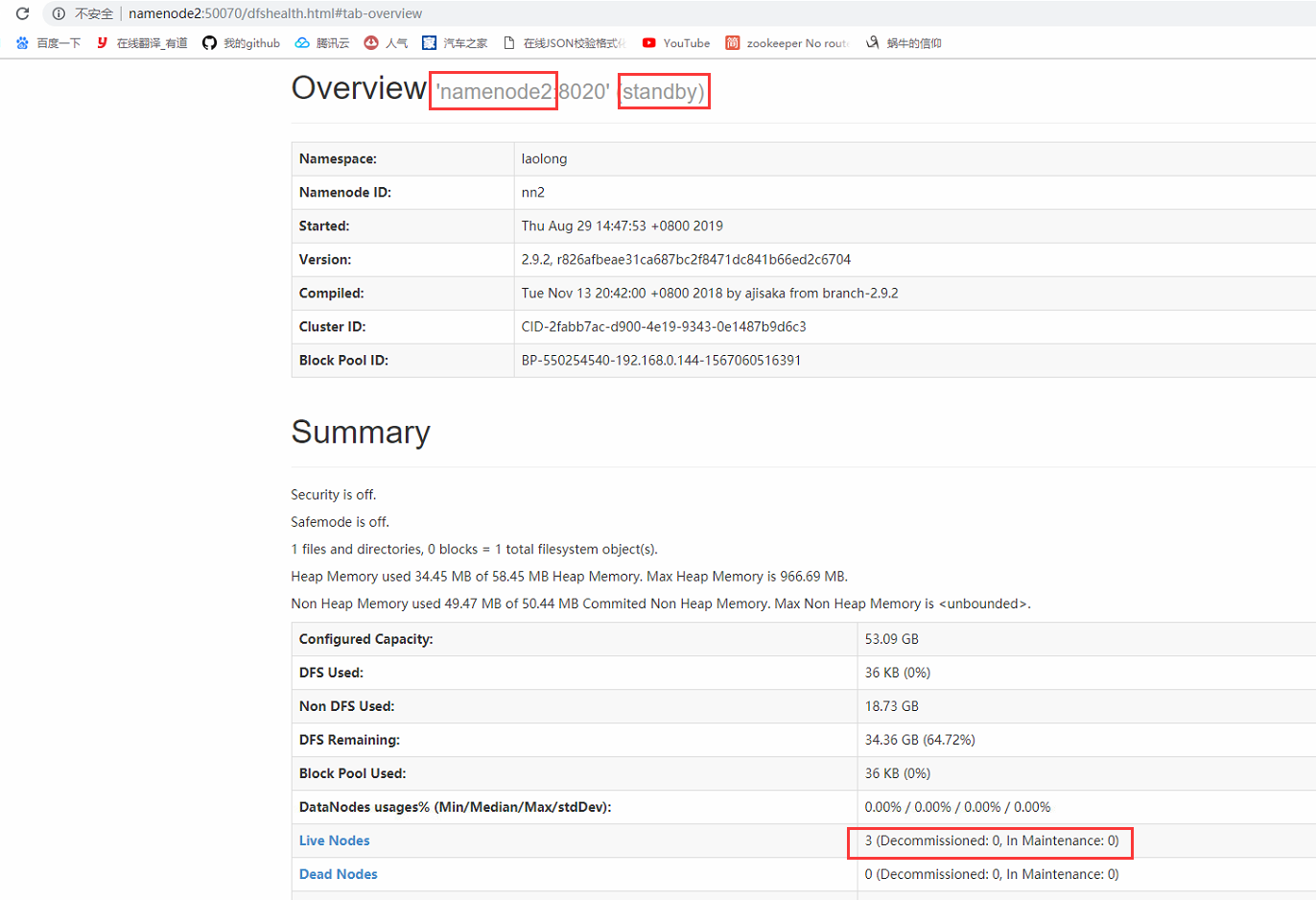
假如把active的namenode kill ,看看能不能实现自动切换呢?
namenode1 不能访问了

那namenode2呢?
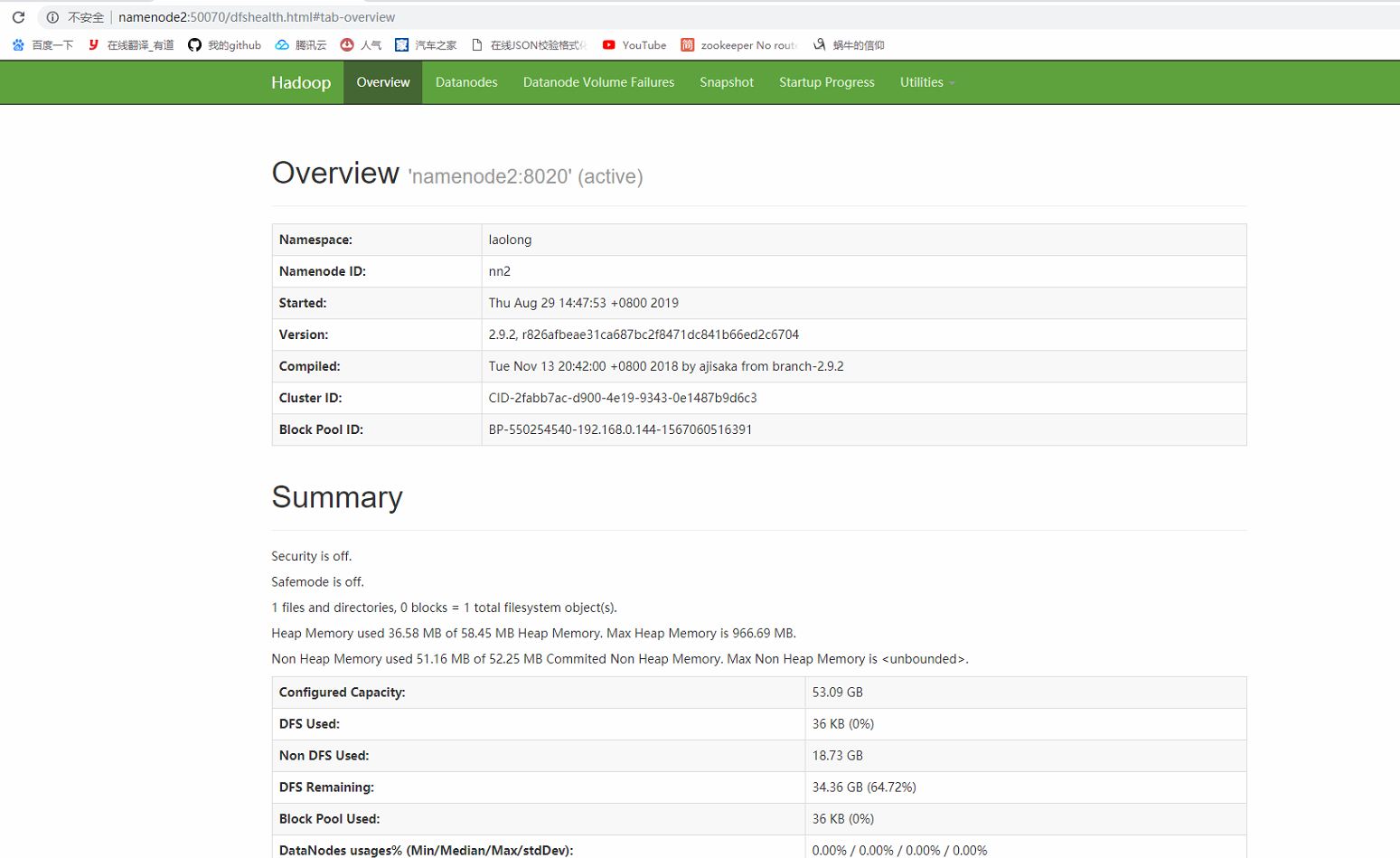
这样就实现了namenode的切换。
11).start-yarn.sh
启动后,如下
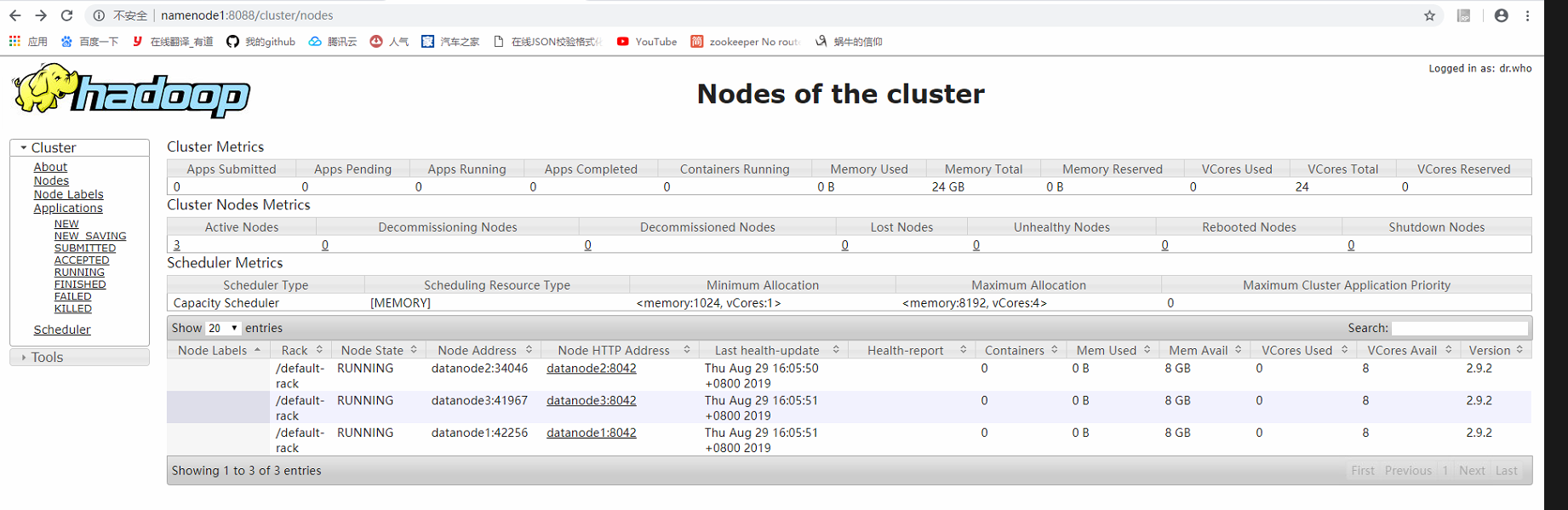
至此,完成HA集群搭建。只是记录我学习的,很多不明白的,希望大家指点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号