luogu
珠心算:给定一列数,其中有几个数是另外两个数之和
1、一开始想到的就是三重for循环:

#include <iostream> #include <cstdio> using namespace std; const int maxn = 1001; int a[maxn],n; int main() { cin>>n; for(int i = 1;i<=n;i++) { cin>>a[i]; } int tot = 0; for(int k = 1;k<=n;k++) for(int i = 1;i<=n-1;i++) for(int j = i+1;j<=n;j++) if(a[k] == a[i] + a[j] && a[i] != a[j]) tot++; cout<<tot<<endl; return 0; }
满心欢喜,以为一下就用暴力找到了答案正解,于是发现,不能AC
通过比较输出结果:
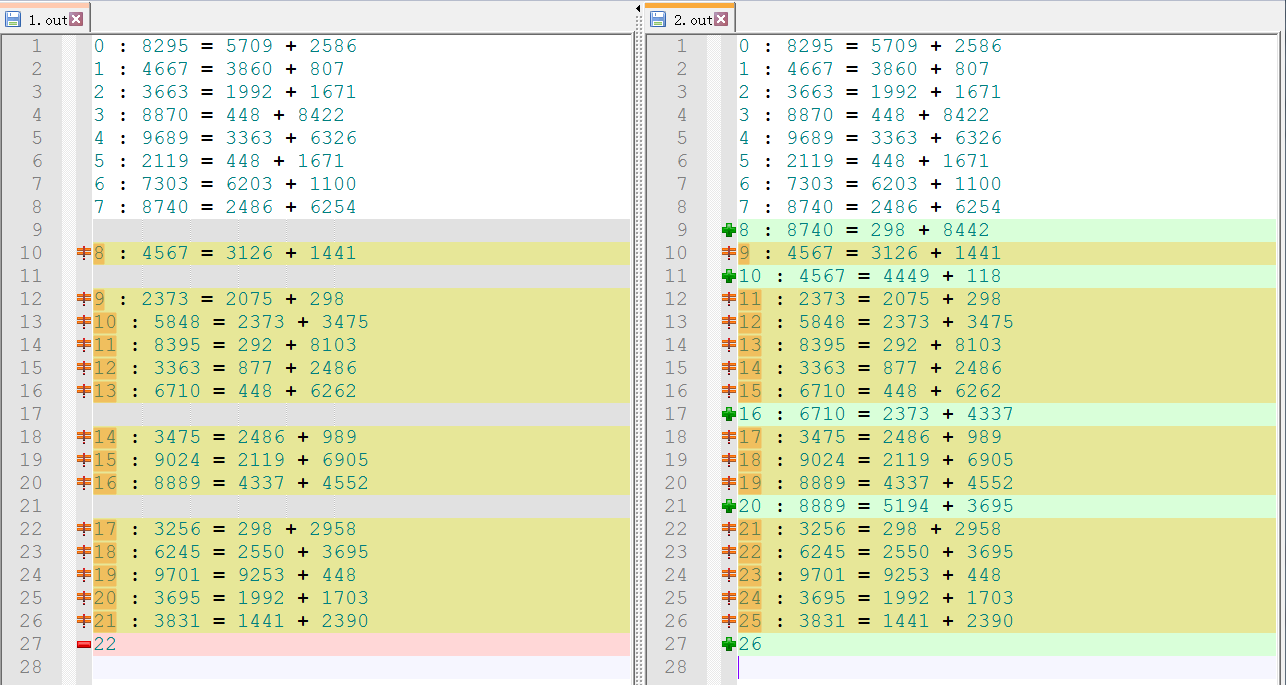
发现原来存在这样的情况:如果一个数等于其他对数之和,那就有几对就算了几次,而本题是计算有多少个数是另外两个数之和,即只算一次就可以了。于是傻傻的不再理解正解答案中的什么k++,i = j = 1;
直接多用一个数组,如果找到了置为1,后面如果再找到就不增加了。
于是AC代码就呼之欲出了:
#include <iostream> #include <cstdio> using namespace std; const int maxn = 1001; int a[maxn],n; int f[10001]; int main() { cin>>n; for(int i = 1;i<=n;i++) { cin>>a[i]; f[a[i]] = 0; } int tot = 0; for(int k = 1;k<=n;k++) for(int i = 1;i<=n-1;i++) for(int j = i+1;j<=n;j++) if(a[k] == a[i] + a[j] && a[i] != a[j]) if(!f[a[k]]) { tot++; f[a[k]] = 1; } cout<<tot<<endl; return 0; }
ISBN:
#include <iostream> #include <cstdio> #include <cstring> #include <ctype.h> using namespace std; string s; int main() { cin>>s; int len = s.size(),sb,sum = 0,tot = 1; for(int i = 0;i<len-1;i++) { if(isdigit(s[i])) { sum += (s[i] - '0') * tot; tot++; } } sum %= 11; char c = (sum == 10 ? 'X' : (sum + '0')); if(c == s[len-1]) cout<<"Right"<<endl; else{ for(int i = 0;i<len-1;i++) cout<<s[i]; cout<<c<<endl; } return 0; }
统计单词数真的是做的让人无语,七拼八凑的终于得了70分
#include <iostream> #include <cstdio> #include <cstring> #include <ctype.h> using namespace std; const int maxn = 1e6+10; char str[11]; string s; char ans[maxn][11]; int main() { //freopen("P1308_5.in","r",stdin); gets(str); getline(cin,s); int len = s.size(), r = 0, h = 0; for(int i = 0;i<len;i++) if(isalpha(s[i])) s[i] = tolower(s[i]); for(int i = 0;i<strlen(str);i++) str[i] = tolower(str[i]); int location[len]; memset(location,0,sizeof(location)); for(int i = 0;i<len;i++) { if(s[i] != ' '){ if(h == 0) location[r] = i; ans[r][h++] = s[i]; } else{ ans[r][h] = '\0'; r++; h = 0; } } int tot = 0; int t = 0;int flag1 = 0; for(int i = 0;i<=r;i++) { int flag = 1; for(int j = 0;j<strlen(str);j++) if(ans[i][j] != str[j]) flag = 0; if(flag && strlen(str) == strlen(ans[i])) tot++; if(flag && !flag1) { flag1 = 1; t = location[i]; } } if(!tot) cout<<-1<<endl; else cout<<tot<<" "<<t<<endl; return 0; }
再也无法找到可以改进的地方了,于是看一下题解,发现原来可以这么简单,字符串题目就是这样,很多字符的使用方式不清楚,造成了束手无策的局面。
#include <iostream> #include <cstdio> #include <cstring> #include <ctype.h> using namespace std; string s1,s2; int main() { freopen("P1308_7.in","r",stdin); getline(cin,s1); getline(cin,s2); for(int i = 0;i<s1.size();i++) s1[i] = tolower(s1[i]); for(int i = 0;i<s2.size();i++) s2[i] = tolower(s2[i]); s1 = ' ' + s1 + ' '; s2 = ' ' + s2 + ' '; if(s2.find(s1) == string::npos) { cout<<-1<<endl; } else{ int a1 = s2.find(s1); int a2 = a1, s = 0; while(a2 != string::npos) { s++; a2 = s2.find(s1,a2+1); } cout<<s<<" "<<a1<<endl; } }
find我知道,只是用了发现会覆盖单词出现的,这里巧妙的用了两个字符串都加了空格
P1553 数字反转做得我伤心

一开始想依次判断整数、小数、百分数、分子分母数,后来发现不行,太累赘了,太SB了,不是一个正经的人应该做得事,一度放弃,后来,就尝试找到每个. / %的位置,这时候尝试用string.find(a1) != string :: npos找到字符的位置。
代码如下:
#include <iostream> #include <cstdio> #include <cstring> using namespace std; string s; int main() { cin>>s; int len = s.size(),loc = 0,flag = 0; char a = '.', b = '/', c = '%'; loc = len; if(s.find(a) != string :: npos) loc = s.find(a), flag = 1; if(s.find(b) != string :: npos) loc = s.find(b), flag = 1; if(s.find(c) != string :: npos) loc = s.find(c), flag = 1; int t = loc - 1; while(s[t] == '0') t--; if(t < 0) cout<<0; else{ for(int i = t;i>=0;i--) cout<<s[i]; } if(flag) { cout<<s[loc]; if(s[loc+1]) { int t = loc + 1, t1 = len - 1; while(s[t] == '0') t++; while(s[t1] == '0') t1--; if(t > t1) cout<<0; else{ for(int i = t1;i>=t;i--) cout<<s[i]; } } } return 0; }
改了两次:一个是如果输入的是0.0的话,那么也要输出0.0,所以整数那里输出不应该加<<endl了。还有就是1234567890/1234567890,分子和分母的0都应该要去掉。

这道题真的是让我搞得不要不要的,
1、一开始在统计每个字符出现的最大次数竟然都错了,
for(int i = 0;i<len;i++)
a[s[i] - 'A']++;
maxL = max(maxL, a[s[i] - 'A']);
这里因为没有考虑到还有其他的字符,所以首先数组不应该只开成int a[26];
统计字符最大出现字数要分开进行:
for(int i = 0;i<len;i++)
if(s[i] >= 'A' && s[i] <= 'Z')
a[s[i] - 'A']++;
for(int i = 0;i<26;i++)
if(a[i] > maxL) maxL = a[i];
2、还有它这里是按每个字母出现的次数来打印输出的,所以外层应该是for(int i = maxL;i>0;i--),内层为:大写字母的26个字母,然后因为每行行末不能有多余的空格或换行,所以要设置首位标记。
接着最大的挑战出来了:就是怎样让每一行最后一个※后不再出现空格,因为原来的代码是:
for(int i = maxL;i>0;i--){
int flag = 0,
for(int j = 0;j<=25;j++){
char c;
if(a[j] < i) c = ' ';
else c = '*';
if(!flag) { cout<<c; flag = 1;}
else cout<<' '<<c;
}
cout<<endl;
}
这里就要再设置一个位置:表示最后一个大于等于当前最高位置的字母在哪里,就在这进行换行,而不再输出多余的空格。

int tt = 0;
for(int k = 25;k>=0;k--)
if(a[k] >=i) {tt = k; break; }
#include <iostream> #include <cstdio> #include <cstring> #include <algorithm> using namespace std; string s,s1,s2,s3,s4; int a[101]; int main() { getline(cin,s1); getline(cin,s2); getline(cin,s3); getline(cin,s4); s = s1 + s2 + s3 + s4; int len = s.size(),maxL = 0; for(int i = 0;i<len;i++) if(s[i] >= 'A' && s[i] <= 'Z') a[s[i] - 'A']++; for(int i = 0;i<26;i++) if(a[i] > maxL) maxL = a[i]; for(int i = maxL;i>0;i--){ int flag = 0,tt = 0; for(int k = 25;k>=0;k--) if(a[k] >=i) {tt = k; break; } for(int j = 0;j<=25;j++){ char c; if(a[j] < i) c = ' '; else c = '*'; if(!flag) { cout<<c; flag = 1;} else cout<<' '<<c; } cout<<endl; } int flag1 = 0; for(int i = 0;i<26;i++){ char t = i + 'A'; if(!flag1) {cout<<t,flag1 = 1;} else cout<<' '<<t; } return 0; }
最后出现的两个测试点RE的情况,只要在分别统计每个字母出现的次数那里,再加一层条件区分:if(s[i] >= 'A' && s[i] <= 'Z'),从一分未得到最后的AC是一个艰难的过程,不过喜悦和成就感也是显而易见的。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?