
Linux下windows中文文本文件乱码问题
table of content:
- 乱码问题
- 用gedit选择正确的字符编码打开文件
- 文件转码
- 总结
§乱码
Fedora安装时默认用UTF-8字符编码方式, 这么做有国际化的好处(和很多用utf-8的地方兼容), 但是也有兼容问题. 比如:
中文编码在windows下不是utf-8编码, 因为政策要求, 在中国销售的软件要用国标码 (即GBK, GB2312, GB18030(最新的))
所以中文windows用GB18030的编码, 这就导致一个小问题. 在linux下打开windows的文件出现乱码, 如图
用Gedit打开一个GB18030编码的文件 (双击打开时)
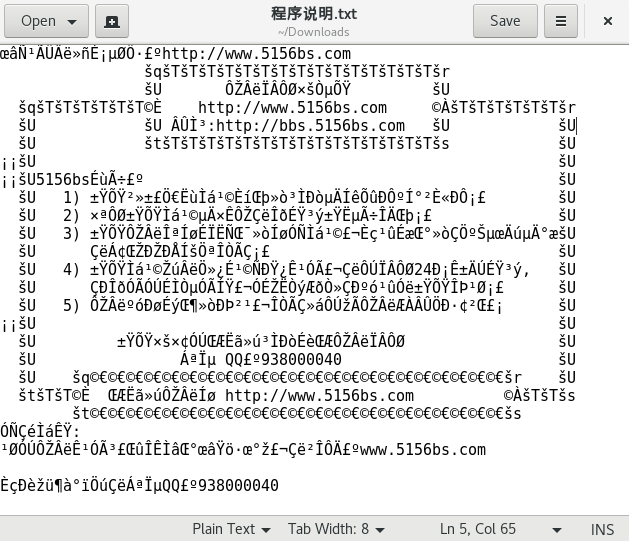
为什么会这样, 因为gedit用解码utf-8的方式编码(decode) 用GB18030编码的文本, 就像用解释英语解释一段法语一样,翻译出一堆没意义的句子.
§以正确字符编码(character encodings)打开
解决乱码的方法很简单, gedit本身支持很多种字符编码, 如图

1. 用gedit的打开Open打开文件,
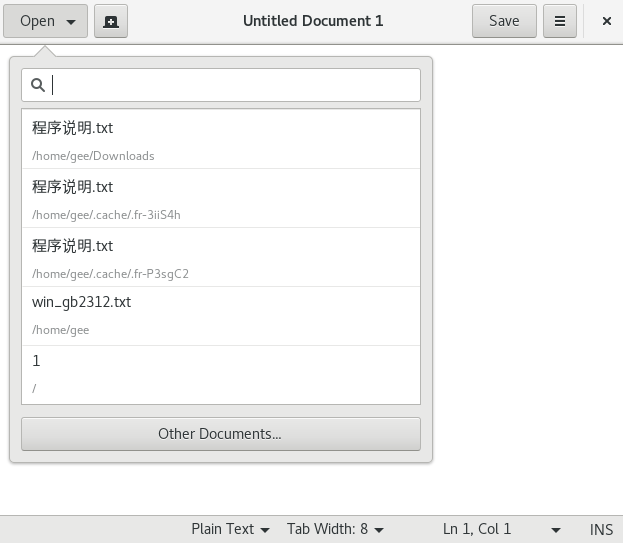 选择其它文件(other documents...)
选择其它文件(other documents...)
2.
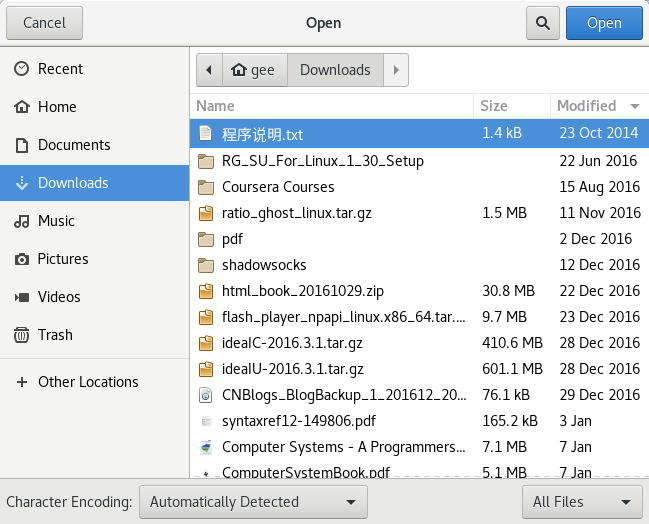 (左下角的Character encoding 处选择正确的字符编码)
(左下角的Character encoding 处选择正确的字符编码)

然后,文件就正常打开啦:
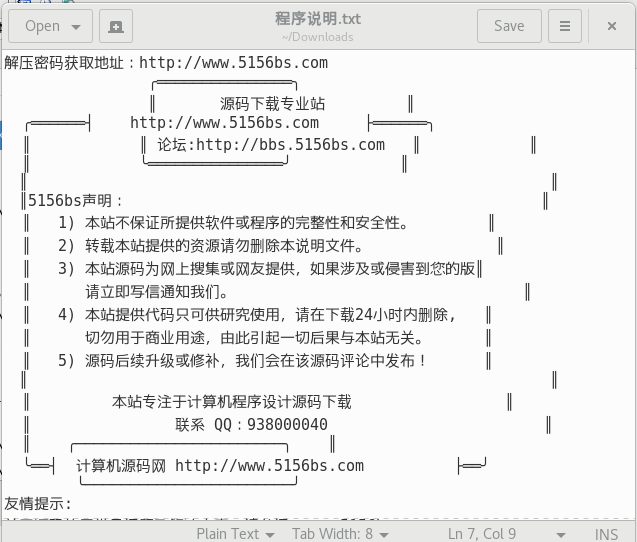 (请忽略文本内容, 只是刚好是这个文件而已, 不是给网站打广告......)
(请忽略文本内容, 只是刚好是这个文件而已, 不是给网站打广告......)
此外, 如果用命令行的方式打开一个文件可以用gedit --encoding 相应编码 的方式来打开
§转码
用gedit打开一个文件
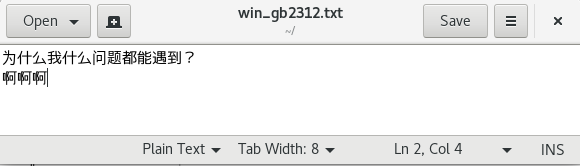 (此文件用gb2312编码)
(此文件用gb2312编码)
另存为  saveas
saveas 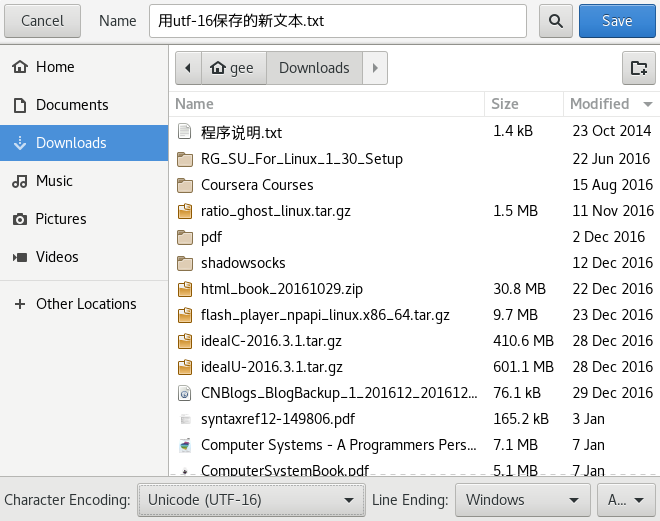 此时在左下角选择utf-16的编码,点击save
此时在左下角选择utf-16的编码,点击save
此时新文件就是utf-16格式的, 在终端用file命令可以看到文件的新编码
$ file 用utf-16保存的新文本.txt 用utf-16保存的新文本.txt: Little-endian UTF-16 Unicode text, with CRLF, CR line terminators
也有其它工具用来转码, 将gb18030转为utf-8, 比如 iconv
用法: iconv [options] [-f from-encoding] [-t to-encoding] [inputfile]...
$ file win_gb2312.txt win_gb2312.txt: ISO-8859 text, with CRLF line terminators $ iconv -f gb2312 -t utf-8 win_gb2312.txt -o utf_encoding.txt # (-o选项指定输出文件) $ file utf_encoding.txt utf_encoding.txt: UTF-8 Unicode text, with CRLF line terminators
§总结
这些方法都有不可忽视的缺点: 那就是你要提前知道文件的原编码方式是啥, 不然就要一个一个试.
如何查看一个文件的编码方式, 可以用file命令查看, 但是file命令不可靠, 一个gb2312编码的文件file命令判断为ISO-8859...
所以还是不够"智能"啊..这些软件...


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律