Spark RDD弹性分布式数据集
为啥要学Spark中的RDD??

RDD的全称叫做Resilient Distributed Datasets,即弹性分布式数据集。
之前我们学过MapReduce,它具有自动容错、平衡负载和可拓展性的优点,但是其最大缺点是采用非循环式的数据流模型,使得在迭代计算式要进行大量的磁盘IO操作。Spark中的RDD可以很好的解决这一缺点。
如何理解RDD ------------> 可以将RDD理解为一个分布式存储在集群中的大型数据集合,不同RDD之间可以通过转换操作形成依赖关系实现管道化,从而避免了中间结果的I/O操作,提高数据处理的速度和性能。
RDD是一个弹性可复原的分布式数据集!
RDD是一个逻辑概念,一个RDD中有多个分区,一个分区在Executor节点上执行时,他就是一个迭代器。
一个RDD有多个分区,一个分区肯定在一台机器上,但是一台机器可以有多个分区,我们要操作的是分布在多台机器上的数据,而RDD相当于是一个代理,对RDD进行操作其实就是对分区进行操作,就是对每一台机器上的迭代器进行操作,因为迭代器引用着我们要操作的数据!
还是不懂啥是RDD? 看这个试试 请用通俗形象的语言解释下:Spark中的RDD到底是什么意思? spark——spark中常说RDD,究竟RDD是什么?
五大特点:
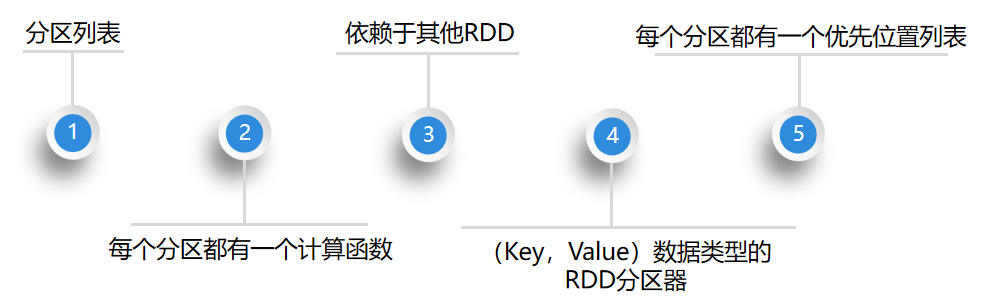
1. RDD的创建
我们通过Spark中的SparkContext对象调用textFile()方法加载数据创建RDD。(首先启动Spark集群,hadoop集群 一个是在spark下的bin里启动start-all.sh 一个是随便启动start.all-sh)
①通过本地文件创建RDD
启动Spark-shell 输入:/export/servers/spark/bin/spark-shell --master local[1]
从文件系统中加载 我在这个路径下创建了一个txt /export/data/temp/words.txt 导进去

②从文件系统中加载数据创建RDD
从hdfs上加载 刚才没开hadoop集群的现在开,并且重启spark服务
这次从hdfs上加载 输入:/export/servers/spark/bin/spark-shell --master spark://hadoop01:7077
从hadoop上拿东西下来 我的hadoop在 spark/input/words.txt 有文件(注意hadoop与文件系统的区别 文件系统有file://)


③通过并行方式创建RDD(建一个数组,通过数组建)


2.RDD处理过程
Spark用Scala语言实现了RDD的API,程序开发者可以通过调用API对RDD进行操作处理。RDD经过一系列的“转换”操作,每一次转换都会产生不同的RDD,以供给下一次“转换”操作使用,直到最后一个RDD经过“行动”操作才会被真正计算处理,并输出到外部数据源中,若是中间的数据结果需要复用,则可以进行缓存处理,将数据缓存到内存中。
转换算子和行动算子的区别: (不太懂可以看看这个 区别)
Ⅰ.转换算子返回的是一个新的RDD。行动算子返回的不是RDD,可能是map,list,string等,也可以没有返回。
Ⅱ.转换算子相当于逻辑的封装。行动算子调用sc.runjob执行作业,是对逻辑计算产生结果。
Ⅲ.sortBy算子 既有转换又有行动的功能,产生一个job,返回一个新的RDD。
①行动算子
行动算子主要是将在数据集上运行计算后的数值返回到驱动程序,从而触发真正的计算。下面,通过一张表来列举一些常用行动算子操作的API。






foreach不太会用



② 转换算子
RDD处理过程中的“转换”操作主要用于根据已有RDD创建新的RDD,每一次通过Transformation算子计算后都会返回一个新RDD,供给下一个转换算子使用。下面,通过一张表来列举一些常用转换算子操作的API

filter(func) 筛选东西 举个例子,比如筛选words.txt中的
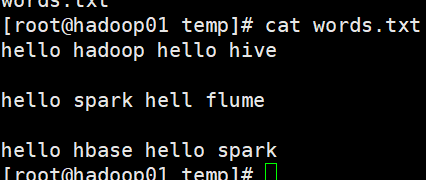
把hello筛选出来

啥!?竟然说我这个文件不存在,很明显是存在的,但最后结果是出来的


换成本地进入试试,也成功
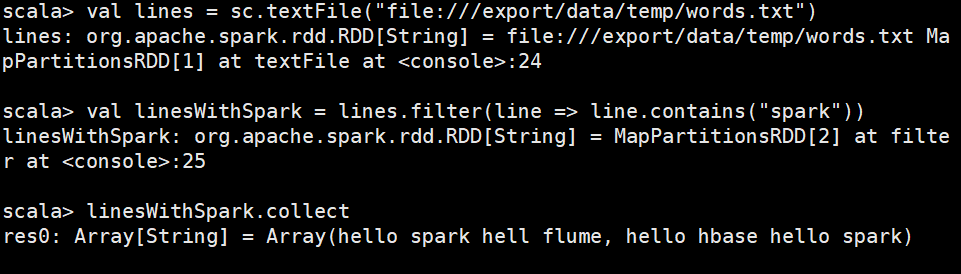
在上述代码中,filter() 输入的参数 line => line.contains("spark") 是一个匿名函数,其含义是依次取出lines这个rdd中的每一个元素,对于当前取到的元素,把它赋值给匿名函数中的line变量。若line中包含spark单词,就把这个元素加入到rdd(即 linesWithSpark)中,否则就丢弃该元素。
map(func)
将每个元素传递到函数func中,返回的结果是一个新的数据集
以下演示从words.txt 文件中加载数据的方式创建rdd,然后通过map操作将文件中的每一行内容都拆分成一个个的单词元素,这些单词组成的集合是一个新的rdd


因为我有几个空行,所以显示了几个Array("")


上述代码中,lines.map(line => line.split(" ")) 的含义是依次取出lines这个rdd中的每个元素,对于当前取到的元素,把它赋值给匿名函数中的line变量。由于line是一行文本,一行文本中包含多个单词,且用空格分隔,通过line.split("")匿名函数,将文本分成一个个的单词,每一行拆分后的单词都被封装到一个数组中,成为新的rdd(即words)中的一个元素。
flatMap(func)
不知道为何全拆了
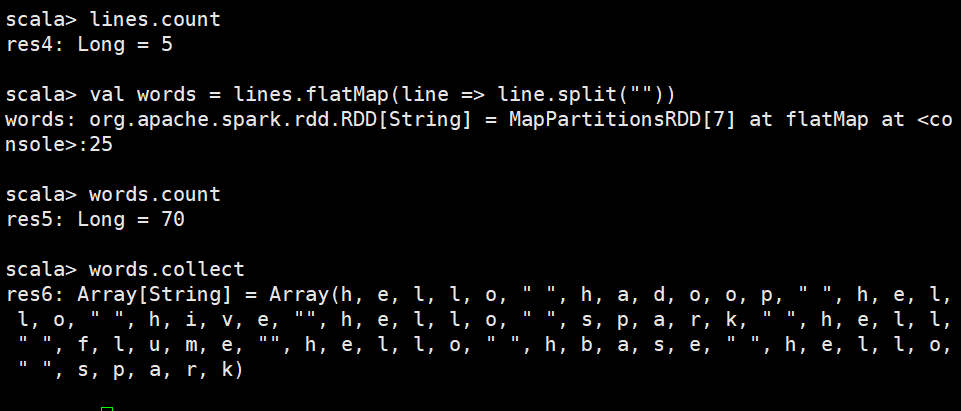
又试了试,发现我拆分的时候少个空格

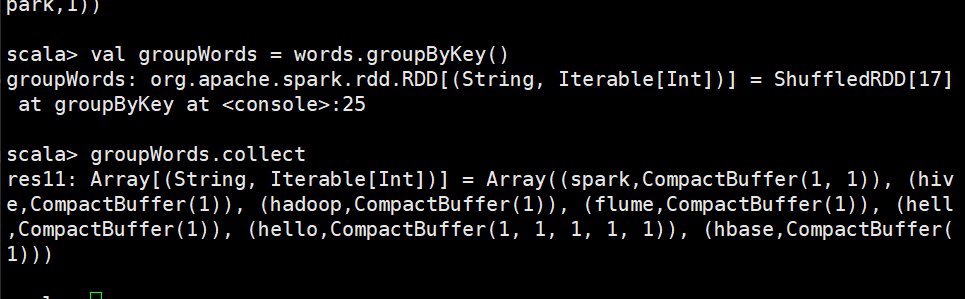
groupByKey()
groupByKey() 主要用于(key,value)键值对的数据集,将具有相同key的value进行分组,会返回一个新的(key,Iterable)形式的数据集。同样以文件words.txt 为例,描述如何通过groupByKey算子操作将文件内容中的所有单词进行分组。

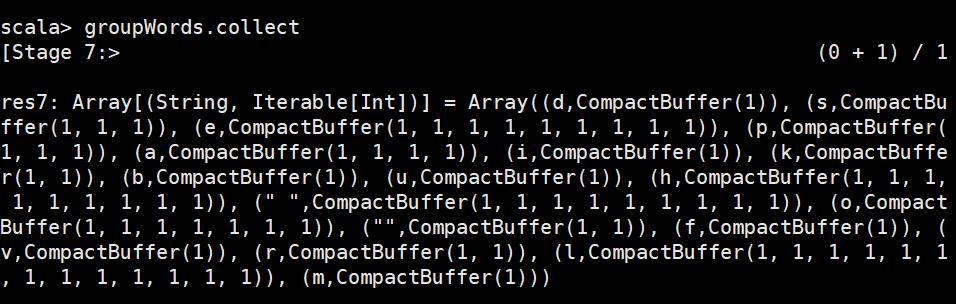
还是全拆了,我把空格删除再试试
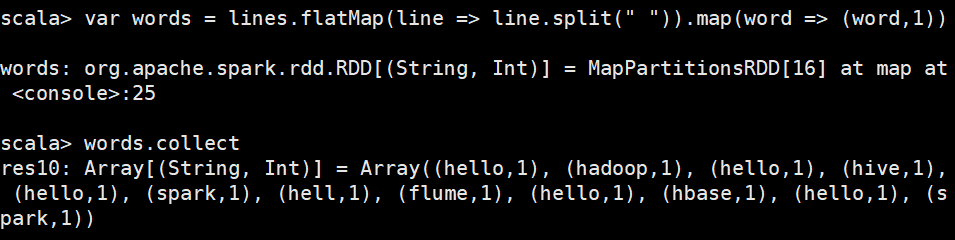
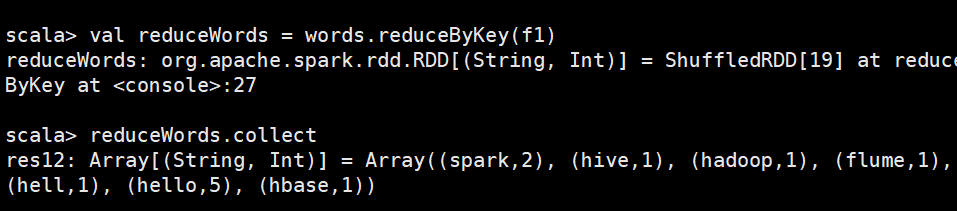
reduceByKey(func)
reduceByKey(func)主要用于(key,value) 键值对的数据集,返回的是一个新的(key,value)形式的数据集,该数据集是每个key传递给func函数进行聚合运算后得到的结果。
执行words.reduceByKey((a,b) => a + b) 操作,共分为两个步骤,分别是先执行reduceByKey操作,将所有key相同的value值合并到一起,生成一个新的键值对,比如(“spark”,(1,1,1));然后执行函数func的操作,即使用(a,b)=> a + b函数把(1,1,1)进行聚合求和,得到最终的结果,即(“spark”,3)


三个小案例
案例一 spark实现运营案例
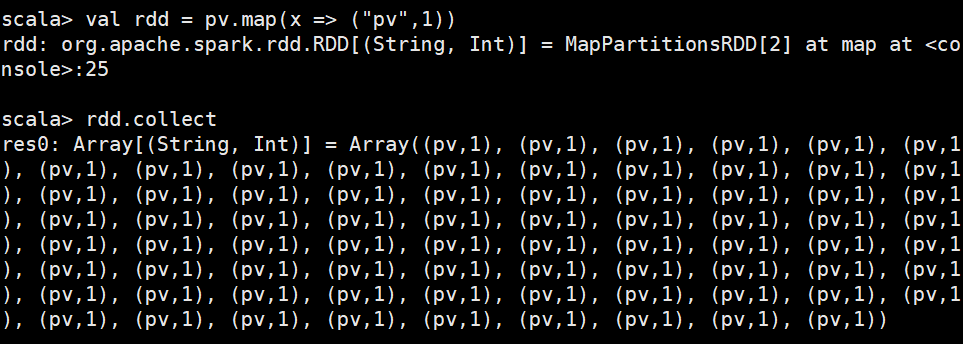
模拟从网页上获取日志,通过日志分析用户的pv操作进行了多少次
1.把logs日志文件建立在linux上

2.进入scala-shell中上传文件 /export/servers/spark/bin/spark-shell --master local

3.进行区分,整成(pv ,1)
4.进行合并操作用 通过 reduceByKey()

案例二 查看访问时间
上传文件

拆分

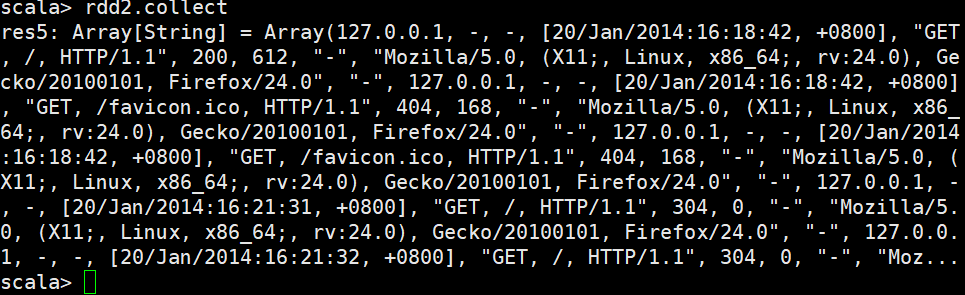
计数

合并

排序

案例三 独立访客
所谓独立访客,就是把每个IP给分出来,然后计数
上传文件

按照空格分割
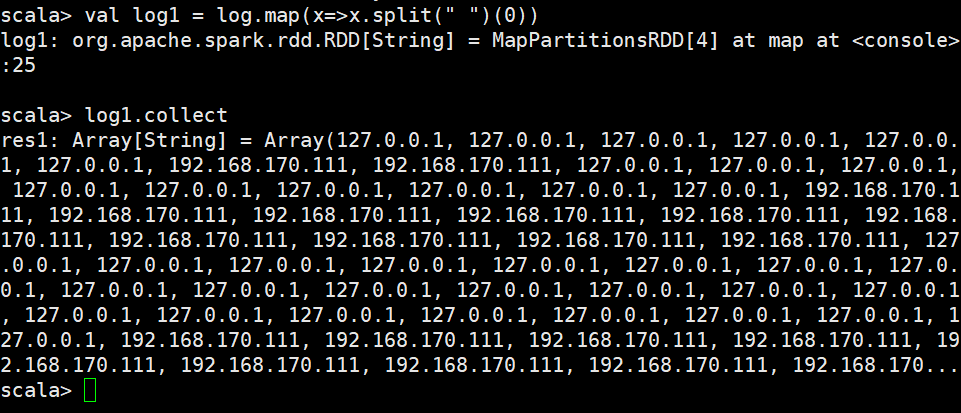
去重

写1

相加求和 记得用reduceByKey

下载文件


嘿嘿,结束昨天的任务~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号