spark简单学习
为啥学spark
中间结果输出:基于MapReduce的计算引擎通常会将中间结果输出到磁盘上,进行存储和容错。出于任务管道承接的,考虑,当一些查询翻译到MapReduce任务时,往往会产生多个Stage,而这些串联的Stage又依赖于底层文件系统(如HDFS)来存储每一个Stage的输出结果
Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补MapReduce的不足。
spark -----> 弥补Mapreduce不足(产生多个Stage)(具有快,易用,通用,兼容性)
spark比mapreduce更加灵活,计算模型不限于Map和Reduce。存储是在内存中,而不是本地磁盘。能够减少IO开销。MapReduce计算中间结果,保存在磁盘中,Hadoop低层实现备份机制,保证数据容错;SparkRDD实现基于Lineage的容错机制和设置检查点方式的容错机制。
1.Spark环境部署
①将包传到文件夹中,解压,改名 输入:tar -zxvf spark-2.3.2-bin-hadoop2.7.tgz -C /export/servers/ 改名:mv spark-2.3.2-bin-hadoop2.7/ spark(到指定文件夹下改名哈)


②

③复制slaves.template文件,并重命名为slaves,编辑slaves配置文件,主要是指定Spark集群中的从节点IP,由于在hosts文件中已经配置了IP和主机名的映射关系,因此直接使用主机名代替IP

④分发文件 修改完成配置文件后,将spark目录分发至hadoop02和hadoop03节点 输入:scp -r /export/servers/spark/ hadoop03:/export/servers/
⑤启动Spark集群(在sbin下启动)
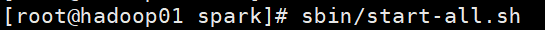
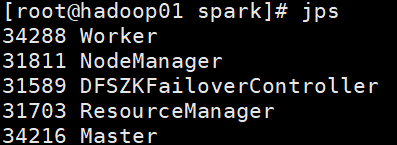

2.第一个案例
①提交SparkPi程序。

②PI值计算成功


③Spark-Shell是一个强大的交互式数据分析工具,初学者可以很好的使用它来学习相关API。运行Spark-Shell命令。在spark/bin目录中,执行下列命令进入Spark-Shell交互环境:

进入普通spark集群 bin/spark-shell --master spark://hadoop01:7077
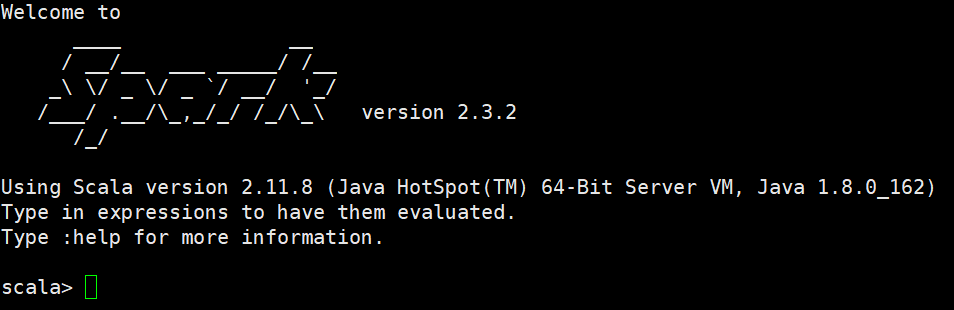
现在我们使用scala语言开发单词计数的spark程序
首先在hdfs的/spark/input路径下建立一个words.txt
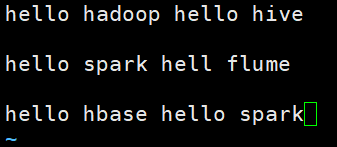
整合spark和hdfs 先修改spark-env.sh配置文件 之后重启集群服务以及重启spark集群服务

再次启动交互式界面 bin/spark-shell --master local[2]
spark-shell 本省就是一个driver,它会初始化一个SparkContext对象为sc,用户可以直接调用。编写scala代码实现单词计数

3.第二个案例(求平均值)
①建一个数组,可以看成是科目和分数的对偶

②再建一个相似的数组

③再建一个,可以看成三个学生

④三个合成一个

⑤按照第一个分组

⑥求和除以长度 的平均值

4.第三个案例(重要函数操作过程)
①创建一个lines

②按照空格分割

③合成一个

④每个单词后面给个1

⑤分组分开

⑥计算得
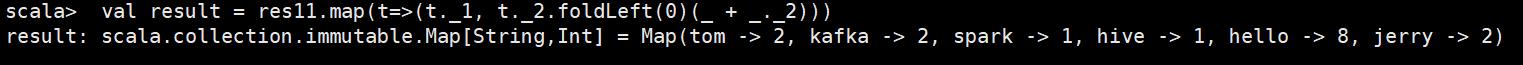
注第2到第5 可以直接通过这句话得到 val grouped = lines.flatMap(_.split(" ")).map((_,1)).groupBy(_._1)

nice!
终于成了,就离谱!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号