flume 简单学习
hive完事了 今天辅助系统 三个组件 数据采集flume 任务调度 oozie 数据导出 sqoop
除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集、结果数据导出、任务调度等不可或缺的辅助系统,
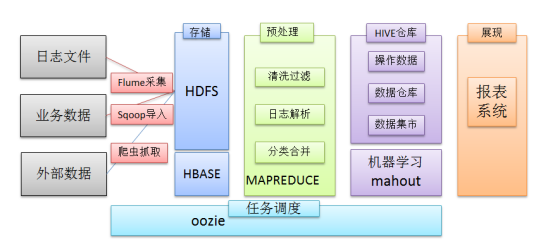
任务调度 oozie Azkaban 工具对比
最终拿到数据展现出来
一.flume (数据采集)
分布式 集群形式
Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
1.运行机制
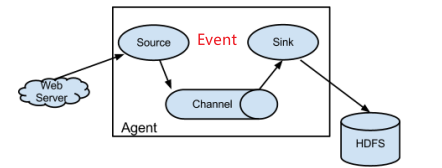
核心组件:agent (系统由agent连接组成)(数据传递员,内部有三个组件)
①Source:采集源,用于跟数据源对接,以获取数据
②Sink:下沉地,采集数据的传送目的,用于往下一级agent传递数据或者往最终存储系统传递数据
③Channel:angent内部的数据传输通道,用于从source将数据传递到sink
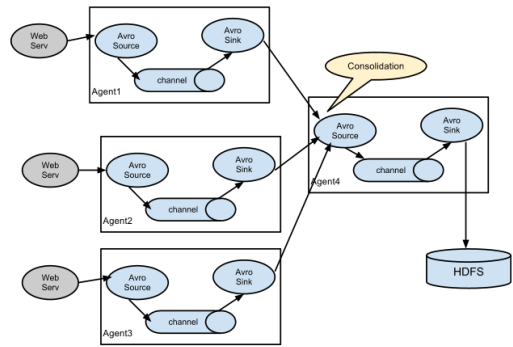
系统结构图(多个)
2.Flume安装部署(已有Hadoop,因为采集的数据要存在hdfs中)(执行时用户名需与Hadoop用户名相同)

3.解压出来 输入:tar -zxvf apache-flume-1.6.0-bin.tar.gz -C /export/servers/(解压完后先去下面安装uginx因为我们需要uginx的环境)
4修改环境变量(根据自己的环境变量就行)
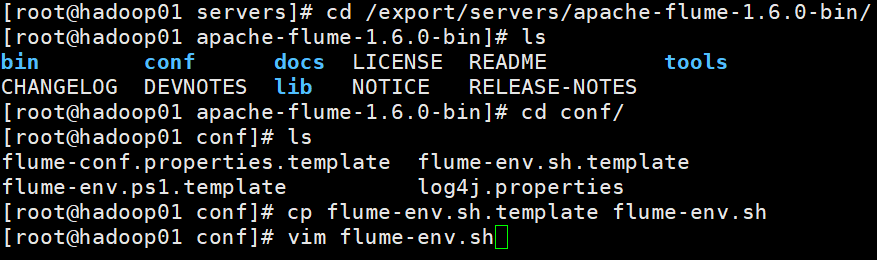
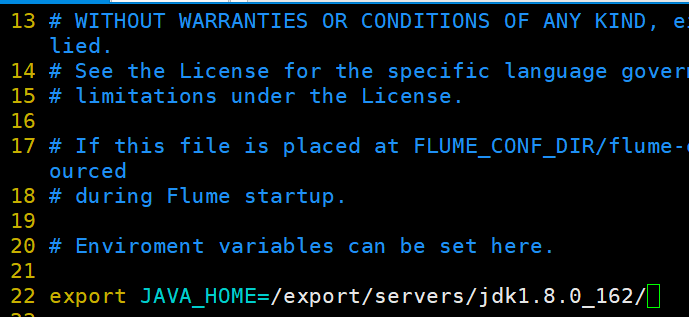
5.测试环境是否正常
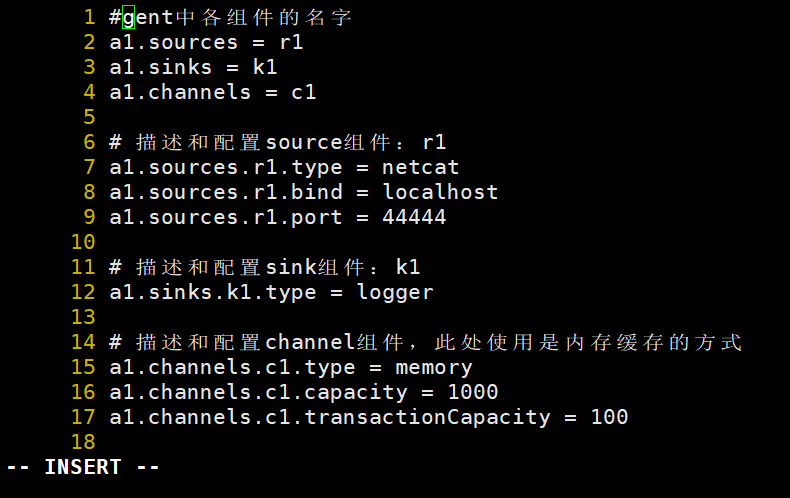
①先在flume的conf目录下新建一个文件 vi netcat-logger.conf
# 从网络端口接收数据,下沉到logger
# 采集配置文件,netcat-logger.conf
#其中该agent名为a1,sources名为r1,sinks名为k1,channels名为c1
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1

②启动agent采集数据(去这个路径下,/export/servers/apache-flume-1.6.0-bin/bin/,这个路径下才有flume-ng这个文件)
bin/flume-ng agent --conf conf/ --conf-file conf/netcat-logger.conf --name a1 -Dflume.root.logger=INFO,console

有这个进程

③输入telnet进行连接(什么!?你说你的电脑显示不是内部和外部命令,这么做:控制面板-------->程序和功能--------------->点击左上角打开 turn windows feaures on or off选项,在新窗口中勾选telnet Client即可)
(linux下没有的话就去找教程吧。。。或者留言问我要三个rpm包解出来也行)
④配置一下flume的home etc/profile 之后记得source一下这个文件夹

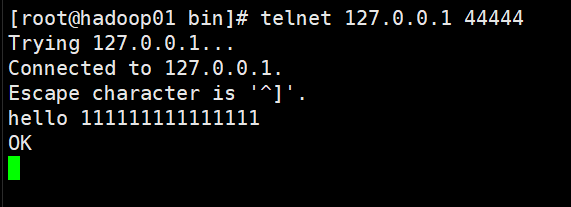
输入命令!开始监听! 还是那个监听命令:flume-ng agent -c conf -f netcat-logger.conf -n a1 -Dflum,console

看效果

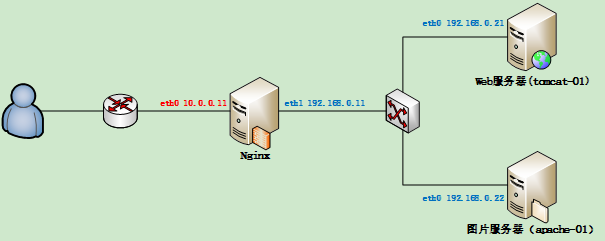
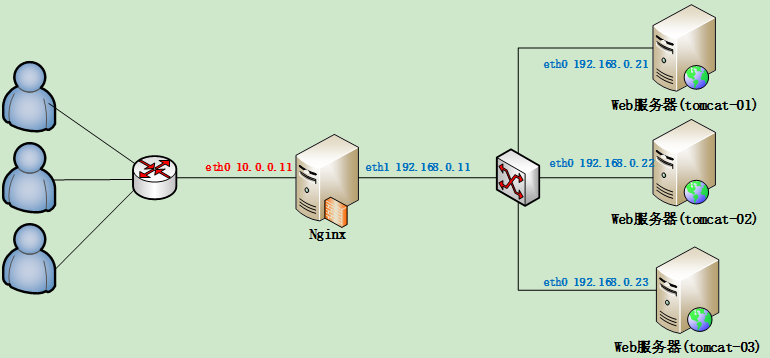
二.Nginx(负载均衡,反向代理)(用flume采集nginx日志)
反向代理:网上发请求给代理服务器,代理服务器接到请求,转发给内部指定服务器,同时将结果返回网上,此时代理服务器对外表现为一台服务器。
负载均衡:大家伙一起干活,减轻每台服务器的任务
1.安装nginx

输入:tar -zxvf nginx-1.8.1.tar.gz -C /export/servers
2.检查安装环境 输入:./configure --prefix=/export/servers/nginx (我的虚拟机连不上外网,下载不了包,所以没办法演示了)
(如果出现缺包报错 ./configure: error: C compiler cc is not found 下载对应的包就行了yum -y install gcc pcre-devel openssl openssl-devel)
可以查看一下进程情况

nginx安装不成功?上网去查,从yum上搬东西就行。yum配置不好?找不到解决方案? 直接用这个吧,别的大佬配置好的,把/etc/yum.repos.d/的文件备份删除,换成这些 配置文件 password:0muz
小案例
案例一:监控文件夹
首先你要有/home/hadoop/flumeSpool/这个文件夹,因为哦我们监控的就是它
输入:flume-ng agent -c ./conf -f ./conf/spool-logger.conf -n a1 -Dflume.root.logger=info,console

接下来往那个文件夹下放文件 随便拷贝一个文件过去 发现被监控到了


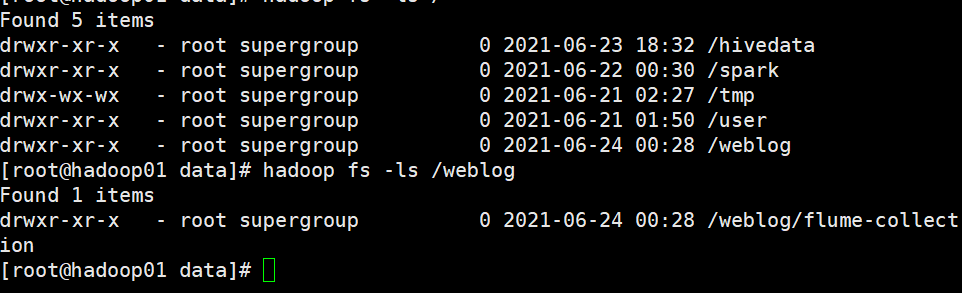
案例二采集目录到HDFS
现在Hadoop下建立一个文件夹 /home/hadoop/logs 目的是把

再建立一个配置文件

开始监控

我们接下来往那个文件夹里放文件

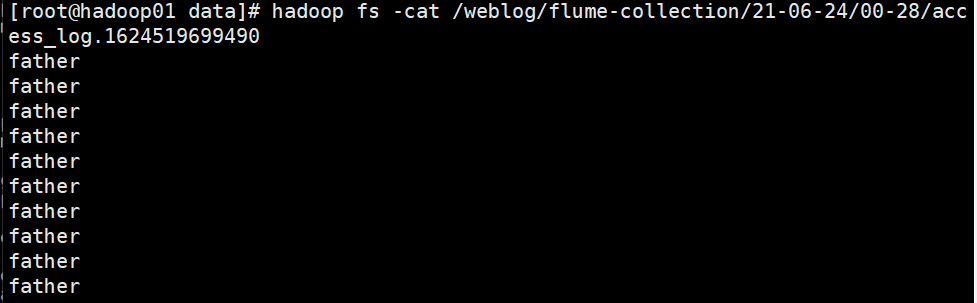
发现监听到了(注意这里只能监听到文件的变化,如果放入文件夹,不会监听到)

在hadoop上也能看到


 浙公网安备 33010602011771号
浙公网安备 33010602011771号