yarn的简单学习
什么是yarn?什么是yarn?如果你想知道什么是yarn的话,我马上带你去研究!

yarn,全名:Yet Another Resource Negotiator,中文名:另一种资源协调者
它是hadoop集群的资源管理系统,从hadoop的第二个版本引入,yarn是新的hadoop资源管理器,因为代码需要资源,资源在各个zNode上,所以需要yarn对资源进行管理。
是通用资源管理系统和调度平台。那如何理解?
资源管理系统:集群的硬件资源,和程序运行有关 (比如说:内存,CPU)
调度平台:多个程序同时申请时进行分配(例如:FIFS)
通用:只关心资源,不关心你干啥(所以说啥子都可以接收,不是只接收RM的应用程序)(说了这么多不知道能不能稍微理解一点,不理解没关系,下面再进行更加深入的了解)
(yarn在hadoop下的sbin里)(Zookeeper记录数据 watch机制 解决高可用,但不是唯一解决高可用)(为什么用yarn,因为我们要把资源管理剥离出来了)
1.Yarn的构架组件
YARN还是经典的主从结构。大体上看,YARN服务由一个ResourceManager(RM)和多个NodeManager(NM)构成,ResourceManager为主节点(master),NodeManager为从节点(slave)
yarn一共有三个组件,分别是:(可能下面理解起来没那么容易,又是RM,又是Scheduler,又是AM,又是容器的,没关系,我尽量说的通俗一点)
1.ResourceManager,是集群资源的仲裁者,它包括两部分:一个是可插拔式的调度Scheduler,一个是ApplicationManager,用于管理集群中的用户作业。(简单说是总资源的老大,还有两个小弟SC和AM)
2NodeManager,它是在每个节点上有,管理该节点上的用户作业和工作流,也会不断发送自己Container使用情况给ResourceManager。(简单说是地方的老大,不断把容器的使用情况告诉总资源老大)
3.ApplicationMaster,用户作业生命周期的管理者,它的主要功能就是向ResourceManager(全局的)申请计算资源(Containers)并且和NodeManager交互来执行和监控具体的task。(是每个作业的管理者,工作是向总资源老大申请资源,并和地方老大进行沟通)
(yarn把程序内部管理交个一个applicationMaster的角色)(applicationMaster分配真正的资源,recousManager分配资源)
注:资源都是以Container(容器)作为资源分配单位
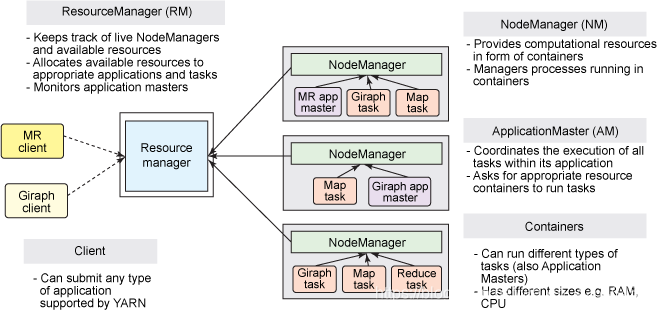
详细讲解:
ResourceManager





2.Yarn的交互流程
把🐘放进冰箱要几步?---->要3步,首先打开冰箱门,接着把🐘放进去,再把冰箱门关上、
那么Yarn提交一个应用程序要几步?
1.启动AM,AM向RM注册(此时用户可以通过RM查看应用程序的运行状态)
2.AM通过RPC协议向RM申请和领取资源
3.AM得到资源,与NM通信,要求它启动任务
4.NM为任务设置好运行环境,将任务启动兵力写到脚本中,并通过运行脚本启动任务
5.各个任务通过RPC协议向AM汇报自己的状态和进度(此时用户可以通过RPC向AM查看应用程序的运行状态)
6.运行完成后,AM向RM注销自己
3.Yarn的集群部署规划
理论上Yarn可以部署在任意机器上,但实际上通常把NM和DN部署在同一台机器上(因为移动程序比移动数据成本低)
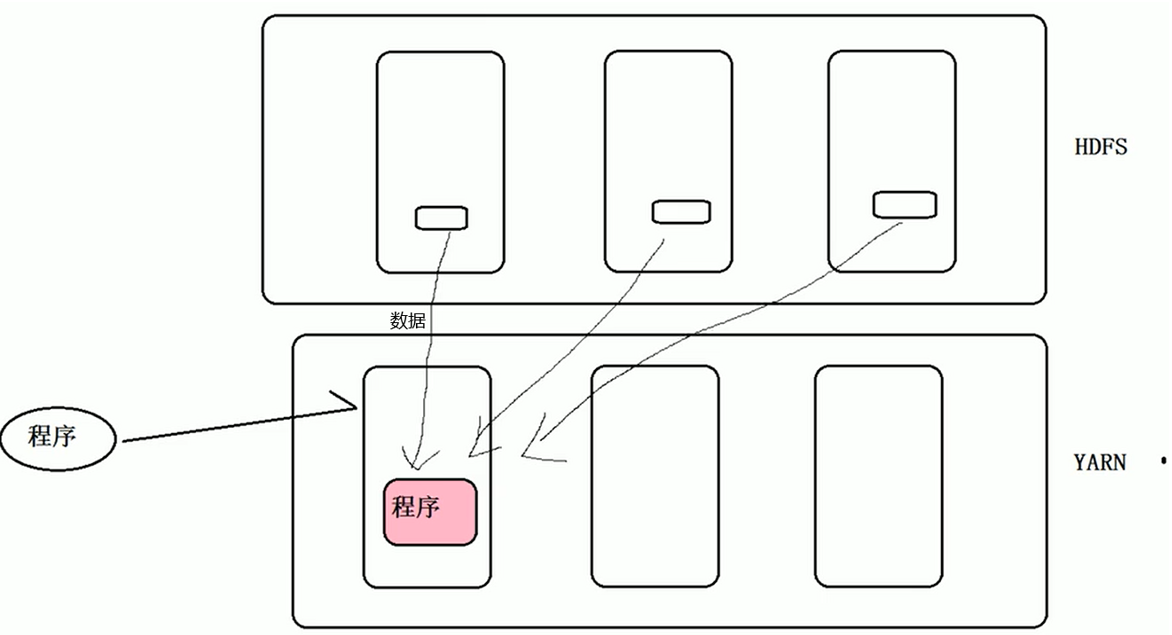
4.Yarn的重启机制
为了高可用性,使RM出现单点故障时,使Yarn正常工作
如果RM出现故障重启后,之前的信息将会消失,正在执行的作业会失败
所以就有了保留工作和不保留工作的区别:不保留工作RM,只保存APP提交的信息和最终执行状态;保留工作RM保存APP运行状态
5.搭建高可用集群
为实现高可用,我们要消除单点故障。
注:HDFS的HA机制通过双namenode协调工作,各自保存一份元数据,日志文件只有一份,只有active的namenode才可以写,所有namenode都可以读。
由zkfailover监控自己所在的namenode,在active的挂掉之后,切换另外一台,同时防止脑裂现象(第一台假死,后来又活了)
模拟高可用:
1.active的namenode假死挂掉
2.zkfailover监控到委派新的namenode
3.新的namenode怕第一台没死透,在补一刀,通过kill补一刀,如果没杀死,再调用用户定义好的程序
4.新的namonode切换状态,上位成功

开始搭建高可用
1.节点角色规划

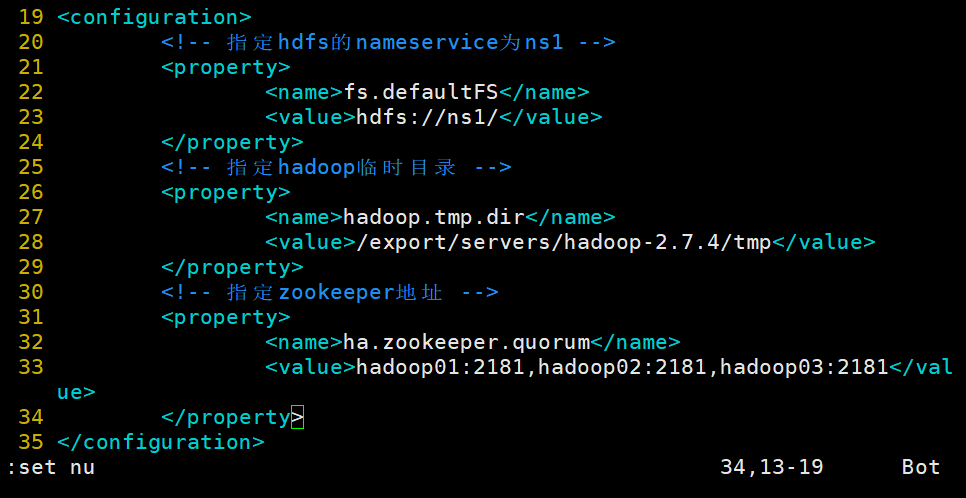
2.修改hadoop中的core-site-xml文件,实现hadoop高可用
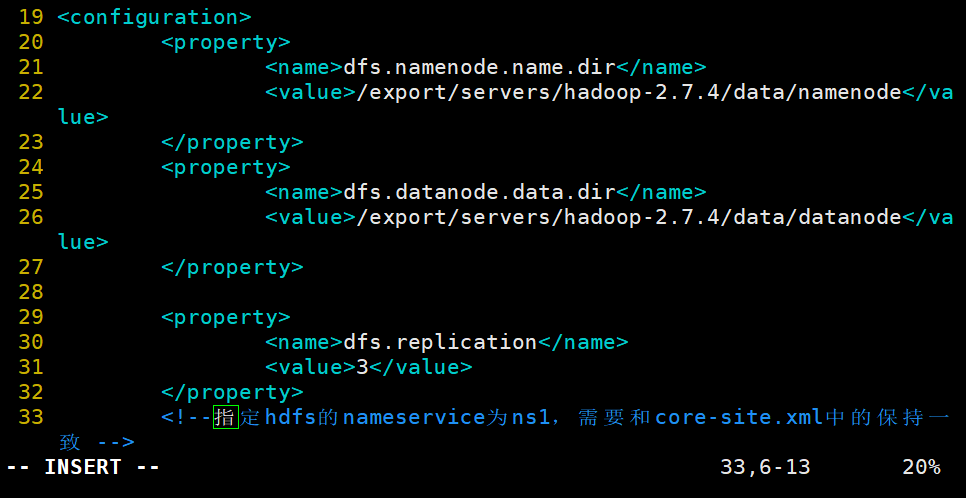
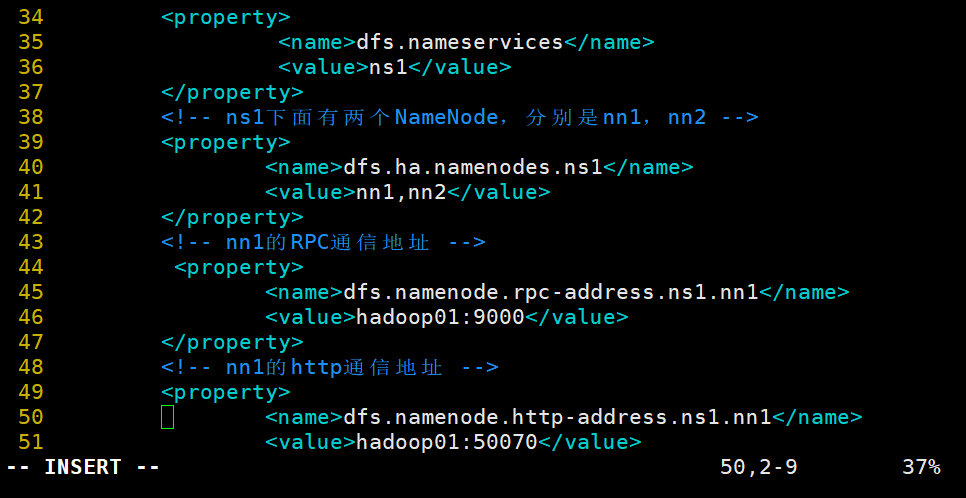
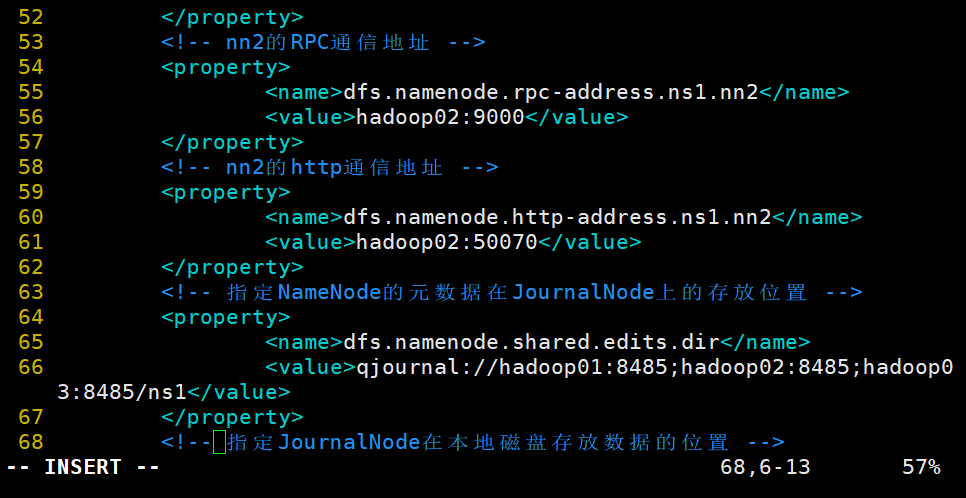
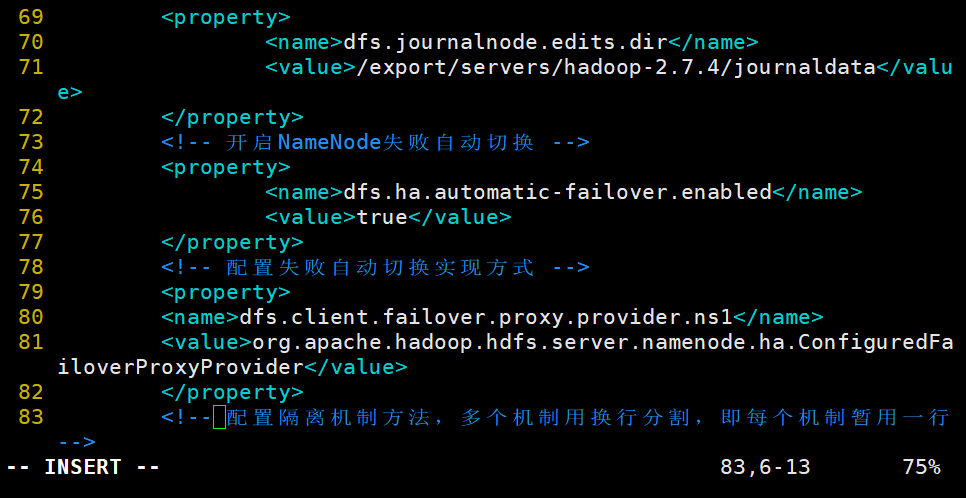
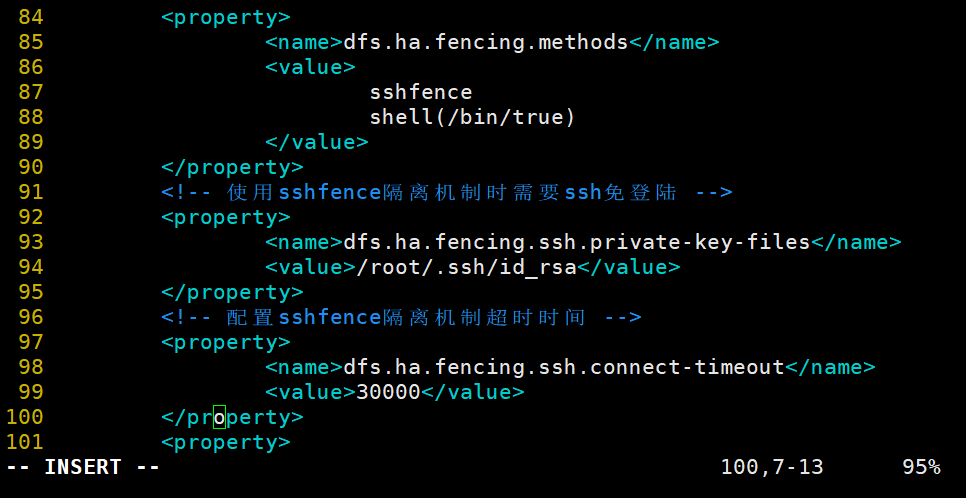
3.修改hdfs-site.xml文件,配置namenode端口地址和通信方式,指定namenode元数据存放位置,开启namenode失败自动切换及配置sshfence
4.修改mapred-site.xml 文件,配置MapReduce计算框架为yarn
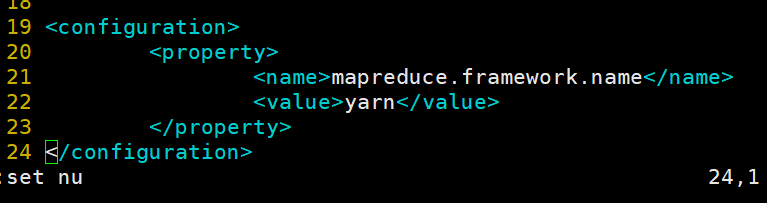
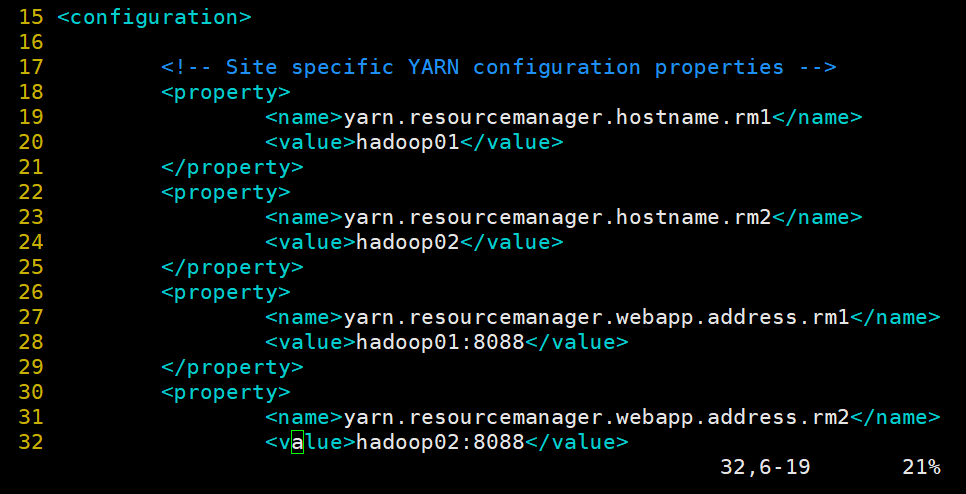
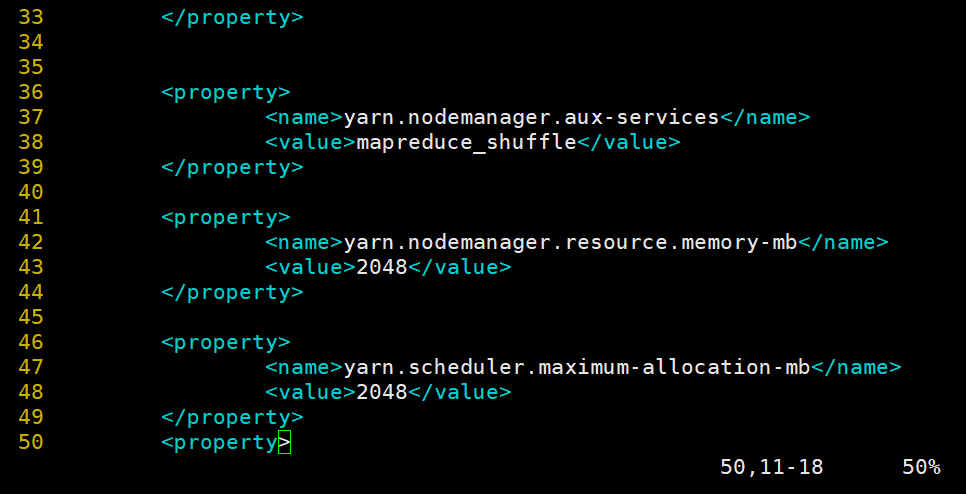
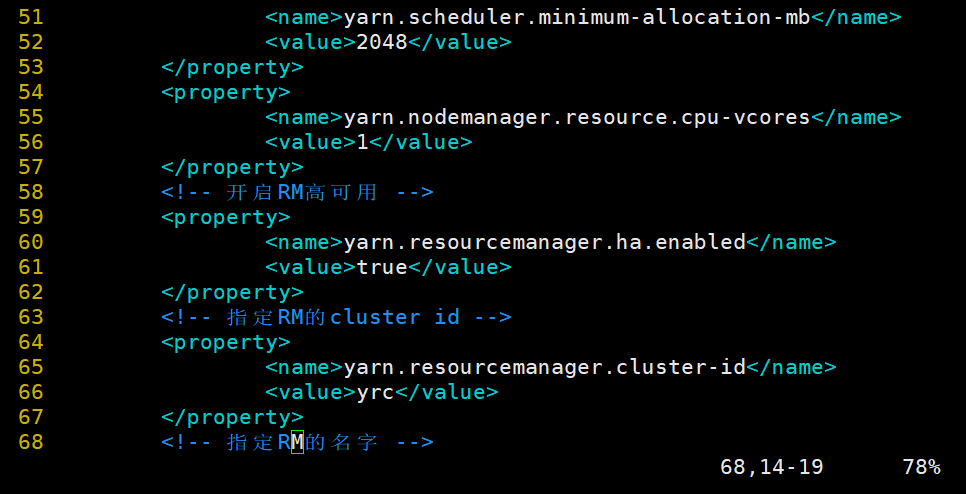
5.修改yarn-site.xml 文件,开启ResourceManager高可用,执行ResourceManager的端口名称地址,并配置zookeeper集群地址
5.修改slaves下主机名
6.修改hadoop-env.sh ,配置Jdk环境变量

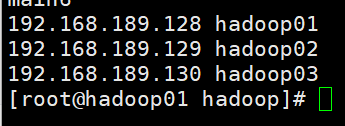
7.hosts文件配置如下(在etc下)
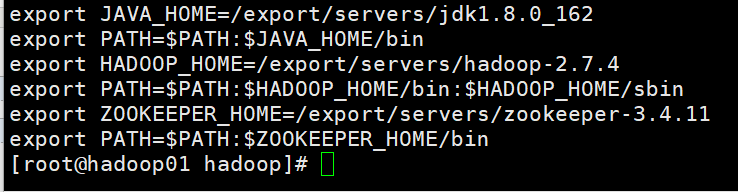
8.修改profile文件配置(在etc下)
9.修改zoo.cfg文件 输入:vim /export/servers/zookeeper-3.4.11/conf/zoo.cfg
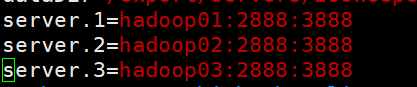
6.启动高可用集群
1.

2.启动集群各个节点监控namenode的管理日志的journalNode,输入:hadoop-daemon.sh start journalnode

3.在hadoop-ha-01 节点上格式化namenode,并将格式化后的目录复制到hadoop-ha-02上,输入:hadoop namenode -format (注意个格式化前去删除,这边指定在data/目录下。直接cd 到 data目录 执行 rm -rf ./*)
在第二台上同步 输入:bin/hdfs namenode -bootstrapStandby
4.接下来启动hafs,ZKFC监听,yarn,使Hadoop在zookeeper上进行注册
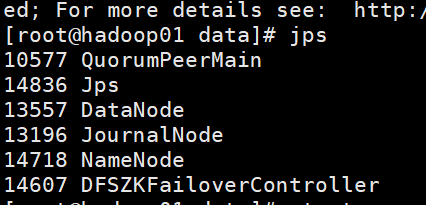
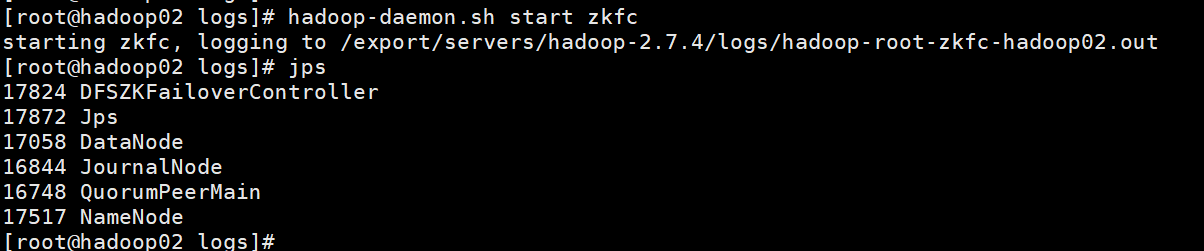
测试:namenode1是active namenode2是standby

杀死1的,发现2变成active了
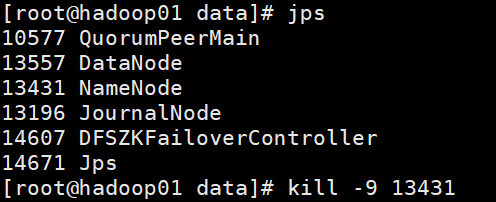

yarn一样

捋一下步骤:
1.配置主机名以及映射关系(为了通过主机名访问)
2.ssh免密登录(为了分发的时候不输入密码)
3.修改配置文件(为了实现高可用 core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml 四大配置文件)
4.修改slaves文件(指定Datanode的节点)
5.指定jdk的地址(修改 hadoop-env.sh)
6.配置hadoop环境变量 (在/etc/profile 下)
7.执行改变(source /etc/profile 使配置文件立刻生效)
8.分发给02,03(为了使大家一样)
9.启动journalnode(journalnode就是活着的往里写,准备的读,三台都启动journalnode使能够互相监控,出现问题时,成功上位,确定主从关系)
10.格式化namenode(使配置生效,让存储空间明白该按什么方式组织存储数据)
11格式化zkfc(zkfc全名zookeeper故障转移)
12.主从信息同步(使信息一致能够完成通信)
13.启动所有和zkfc
注:通过journalnode确定那台namenode是activte状态,并将信息同步到standby状态的namenode,当发生故障时,通过zkfc完成故障转移,由zkfc完成将standby状态的namenode转变成active
小提示:
1.mapreduce 不利于扩展
2.Yarn是多主多从,主 ResourceManager (最终仲裁者) 从 nodemanager
3.RM接收作业提交,通过NM分配 资源以容器形式给予
4.applicationMaster也是一个容器
5.scheduler是可插拔组件,在调度时先AM,AM向大哥要资源,AM的得到资源与NM通信
6.NM使用RM命令,启动容器,监视资源使用情况
7.通常把Nodemanager和DataNode部署在一台机器上(有数据的地方就可能产生计算,移动程序的成本比移动数据高)HDFS与YARN通常在一起(分配资源找yarn,运行是再把数据拿到yarn太耗成本)
8.关于高可用------>重启机制 yarn死掉咋整?用Zookeeper解决单点故障(用监听和*****)
9.get只能监听数据变化情况,不能监听文件变化情况
问题:
1.zookeeper和yarn都是分布式管理系统,有什么区别?
1.RM是通过scheduler分配资源还是通过NM分配资源?????
2.如何理解多主多从,即是nodemanager又是nodemanager?
3.resourcemanager和nodemanager和AM有什么区别?
1.zookeeper是起协调作用,通过watch机制和选举机制对系统各个节点之间进行协调,统一配置处理,解决高可用问题。而yarn起资源调度作用,对磁盘空间的资源,内存,通讯贷款等资源就绪管理分配。
仍然不太懂的可以看看这篇文章 ----------> YARN和Zookeeper的区别
2.RM通过NM分配资源
3.RM是老大,NM是地方老大,AM是应用程序老大
不太理解的Yarn资源调度系统的可以看看这个大佬的 Yarn资源调度系统
不太理解hadoop集群中zkfc的作用和工作过程的看看这个 hadoop集群中zkfc的作用和工作过程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号