zookeeper简单学习
今天引入zooKeeper,来解决一些问题
首先还是那个问题?我们为啥学zooKeeper?

为了解决高可用性,保证出现故障正常使用,在hadoop中的namenode有第二备份,什么时候告诉客户端namenode变了,变成什么了,这时候就需要工具来进行协调
为了再次解决高可用性,这个工具不能挂掉没人管,所以工具r中也有备份,那接下来就是备份数据恢复,谁能恢复的更快,谁就拥有更高的可用性
Zookeeper就是其中的佼佼者,他能把这个数据同步的时间压缩的更短,请求响应更快。
还可以这么理解:是一个基于观察者模式设计的分布式管理框架,负责存储和管理数据,接受观察者的注册,一但数据发生变化,zookeeper就会通知注册的观察者去做出相应的反应(注册的观察者就是hadoop中的客户机)
简单来讲就是zookeeper在其中起协调作用,协调分布式系统,也就是hadoop
借鉴柳树的文章,想深刻理解为啥学zookeeper的可以看一下 -------> 为啥需要zookeeper
借鉴李狗蛋+1的文章,想zookeepe有更深刻的了解可以看看 --------->李狗蛋+1
下面开始简单学习一下zookeeper
1.zookeeper的简单介绍
通过上面解释为啥要学zookeeper,我们知道了一些。zookeeper为了减轻构建健壮的分布式系统,分布式协调服务的开源框架,用来解决的是分布式集群中应用系统的一致性和单点故障问题。
zookeeper以二进制存储,只能存放小量数据 最大2M左右,不能当数据库使用,但是可以放大数据的路径
2.zookeeper的特性
一致,可靠,顺序,原子(可能不太理解原子性,原子是不可再分的意思,指的就是事务请求要么成功,要么失败,不会出现那种成功但不完全成功,失败但不完全失败的情况)

3.zookeeper集群中都有哪些角色
1.Leader 一个集群中只有一个Leader,它是整个集群的核心,也是写操作(事务性请求)的唯一调度者和处理者(你想想看,如果所有人都能写,要多糟糕,一个人在A的地方写了个1,另一个人在A的地方写了个2,读的时候就会存在问题)
所以同时leader还要保证顺序性,可以发起和参与投票(当然也能进行读操作) 一个集群中只能有一个leader节点
简单讲就是:是核心,写操作(可能出现脏数据AB同时写),是大哥,保证集群事物处理顺序性,发起投票,唯一调度者
2.Follower 负责读操作(非事务性操作),如果收到写操作,会发给leder,可以参与投票 几个集群中可以有多个follower节点 (对于什么是投票?下面的zookeeper的两个机制会进行说明)
简单讲就是:读操作(如果有写操作,会发给大哥),参与投票
3.Observer 观察者,观察集群的最新状态,并同步状态。与follower功能基本相同,就是不参与投票,独立处理读操作,、
简单讲就是:观察,不参与竞争Leader
(其实除了这些还有一个竞选状态)(想更深了解一些,可以看这篇文章----------->ZooKeeper的三种角色(还是不太理解的可以看一下)
那这么看来boserver不多余吗????

随着集群中 Follow 服务器的数量越来越多,一次写入等相关操作的投票也就变得越来越复杂,并且 Follow 服务器之间彼此的网络通信也变得越来越耗时,导致随着 Follow 服务器数量的逐步增加,事务性的处理性能反而变得越来越低。
其实因为 Observer 不参与 Leader 节点等操作,并不会像 Follow 服务器那样频繁的与 Leader 服务器进行通信。因此,可以将 Observer 服务器部署在不同的网络区间中,这样也不会影响整个 ZooKeeper 集群的性能,也就是所谓的跨域部署。
如果有人对这个问题还存在疑惑,可以看一下这篇文章---------------->集群中 Observer 的作用以及 与 Follow 的区别
4.zookeeper集群中数据模型
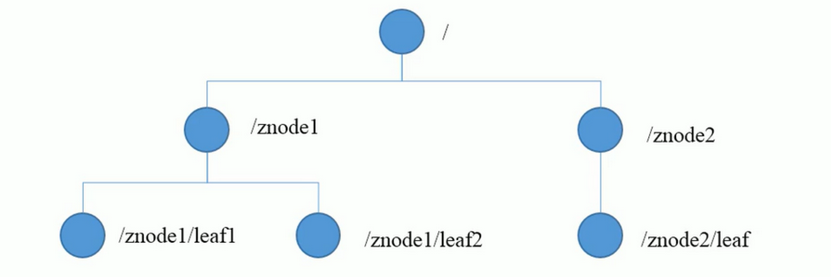
Zookeeper是由节点组成的树,树中的每个节点被称为—Znode。每个节点都可以拥有子节点。每一个Znode默认能够存储1MB的数据,每个Znode都可以通过其路径唯一标识,如图中第三层的第一个Znode,,它的路径是/app1/p_1。Zookeeper数据模型中每个Znode都是由三部分组成,分别是stat、data、children。
统一命名服务:在分布式环境下 需要对服务进行统一的命名,便于识别
统一配置管理:分布式环境下 配置文件同步非常常见 对配置文件修改后希望同步到各个节点上
数据存储类似文件系统,就像/代表根目录,如/long/shi/san
create /zk "test" 创建一个新的Znode节点“以及与他关联的字符串
ls2/ 查看数据及更新次数
Znode的类型在创建时被指定,一旦创建就无法改变。Znode有两种类型,分别是临时节点和永久节点。
临时节点:就是临时的,它们对所有的客户端还是可见的。(需要注意的是临时节点不允许拥有子节点)
永久节点: 该生命周期不依赖于会话,并且只有在客户端显示执行删除操作的时候,它们才能被删除。(可以拥有子节点)
5.zookeeper集群中两种机制
第一种机制-------------->zookeeper的watcher机制
Zookeeper允许客户端向服务端注册一个Watch监听,当服务端的一些事情触发这个监听,会实现分布式的通知功能。(系统更新,通知其他人)
为啥要有这样的机制?是为了使系统知道namenode死了,使客户端知道secondary活了在哪。
举个例子:晚上班主任要开会,班长A和所有同学B收到了通知,但是中途老师有事情开不了会了,老师想告诉你可是不认识你,只能让班长告诉所有同学(老师就是namenode,班长就是watchr,同学就是zookeeper)
zookeeper集群是给我们提供服务的,可以提供计算服务(例如单词),而hadoop则是运用这种服务是可用性更高。
同时还具有分布式通知功能 zookeeper允许客户端向服务端注册一个watch监听(可能有多个watch,不同的注册方式(借钱案例,保险公司案例))
注意:要先注册watch才能触发
第二种机制--------------->zookeeper的选举机制
选举机制非常的神奇!!!
Zookeeper为了保证各节点的协同工作,在工作时需要一个Leader角色,而Zookeeper默认采用FastLeaderElection算法,且投票数大于半数则胜出的机制。(所以说,理想的状态是奇数个机器,不然没法选)
服务器ID: 设置集群myid参数时,参数分别为服务器1、服务器2、服务器3,编号越大FastLeaderElection算法中权重越大。
数据ID: 是服务器中存放的最新数据版本号,该值越大则说明数据越新,在选举过程中数据越新权重越大。
逻辑时钟: 逻辑时钟被称为投票次数,同一轮投票过程中逻辑时钟值相同,逻辑时钟起始值为0,每投一次票,数据增加。与接收到其它服务器返回的投票信息中数值比较,根据不同值做出不同判断。


还有一些小问题:
1.leader死掉后如何通知其他人?如何使其他人上位?
2.客户端监听的这个Znode是必须是领导者吗?还是说可以是任意一个Znode?
3.Zookeeper是适合安装奇数台服务器,还是只能安装奇数台服务器?
自我回答:
1.Ledaer死后,Zookeeper内部自动协调,根据权重产生新的Leader
2.也就是说Hadoop中的namenode向zookeeper注册了一个znode,zookeeper中的一个服务不断监听这个zonde,客户端监听的znode不一定是领导者,就像上面说的,可以是追随者和观察者,只有当有写操作的时候才会把消息传给领导者
3.适合安装,如果非要杠的话,也是可以安装偶数台的
另外还看到一篇有关的有意思的文章分享给大家 --------> 面试官:zookeeper集群的leader挂了怎么办


 浙公网安备 33010602011771号
浙公网安备 33010602011771号