基于Hadoop集群开发shell采集脚本
需求分析:
touch access.log access.log.1 access.log.2
建立一个带上传文件夹
mkdir -p /export/data/logs/toupload
创建Shell脚本
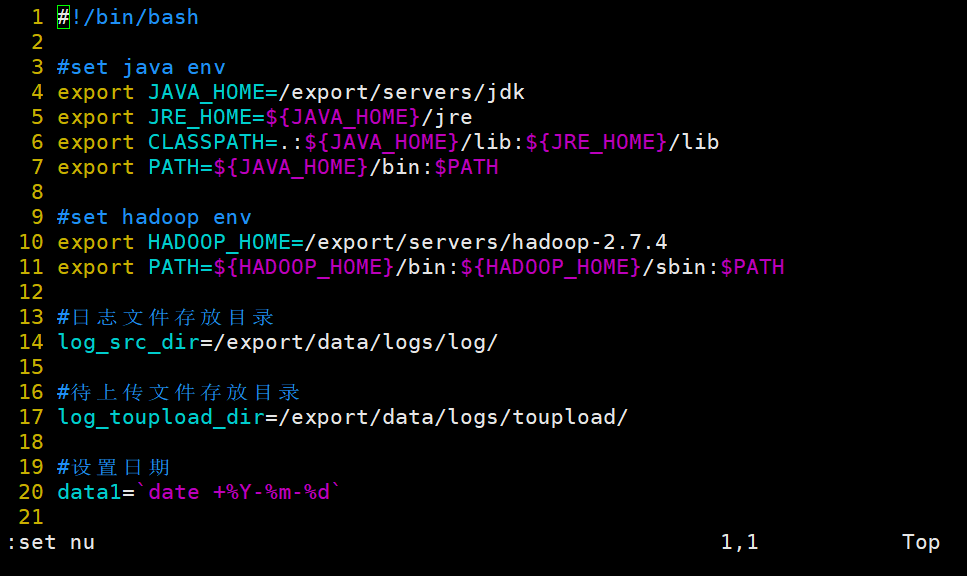
#!/bin/bash
#set java env
export JAVA_HOME=/export/servers/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#set hadoop env
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
#版本1的问题:
#虽然上传到Hadoop集群上了,但是原始文件还在。如何处理?
#日志文件的名称都是xxxx.log1,再次上传文件时,因为hdfs上已经存在了,会报错。如何处理?
#如何解决版本1的问题
# 1、先将需要上传的文件移动到待上传目录
# 2、在将文件移动到待上传目录时,将文件按照一定的格式重名名
# /export/software/hadoop.log1 /export/data/click_log/xxxxx_click_log_{date}
#日志文件存放的目录
log_src_dir=/export/data/logs/log/
#待上传文件存放的目录
log_toupload_dir=/export/data/logs/toupload/
#设置日期
date1=`date +%Y-%m-%d`
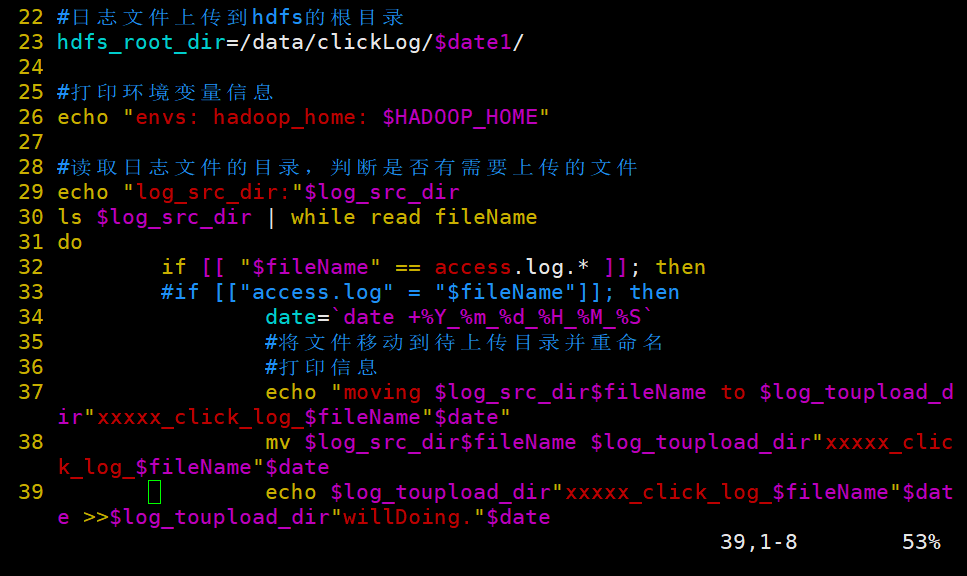
#日志文件上传到hdfs的根路径
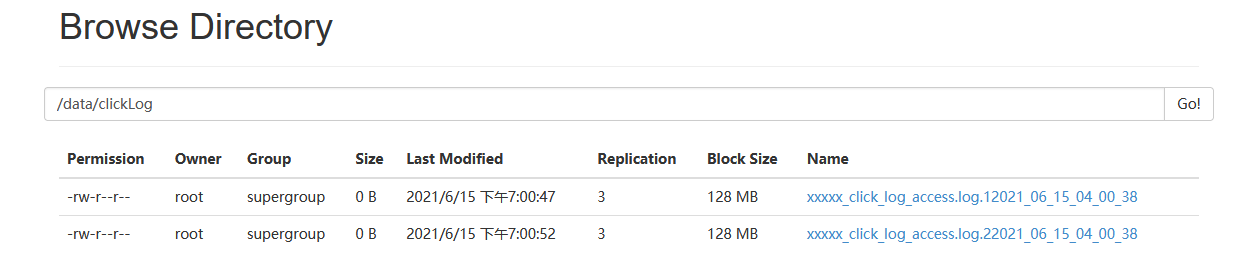
hdfs_root_dir=/data/clickLog/$date1/
#打印环境变量信息
echo "envs: hadoop_home: $HADOOP_HOME"
#读取日志文件的目录,判断是否有需要上传的文件
echo "log_src_dir:"$log_src_dir
ls $log_src_dir | while read fileName
do
if [[ "$fileName" == access.log.* ]]; then
# if [ "access.log" = "$fileName" ];then
date=`date +%Y_%m_%d_%H_%M_%S`
#将文件移动到待上传目录并重命名
#打印信息
echo "moving $log_src_dir$fileName to $log_toupload_dir"xxxxx_click_log_$fileName"$date"
mv $log_src_dir$fileName $log_toupload_dir"xxxxx_click_log_$fileName"$date
echo $log_toupload_dir"xxxxx_click_log_$fileName"$date >> $log_toupload_dir"willDoing."$date
fi
done
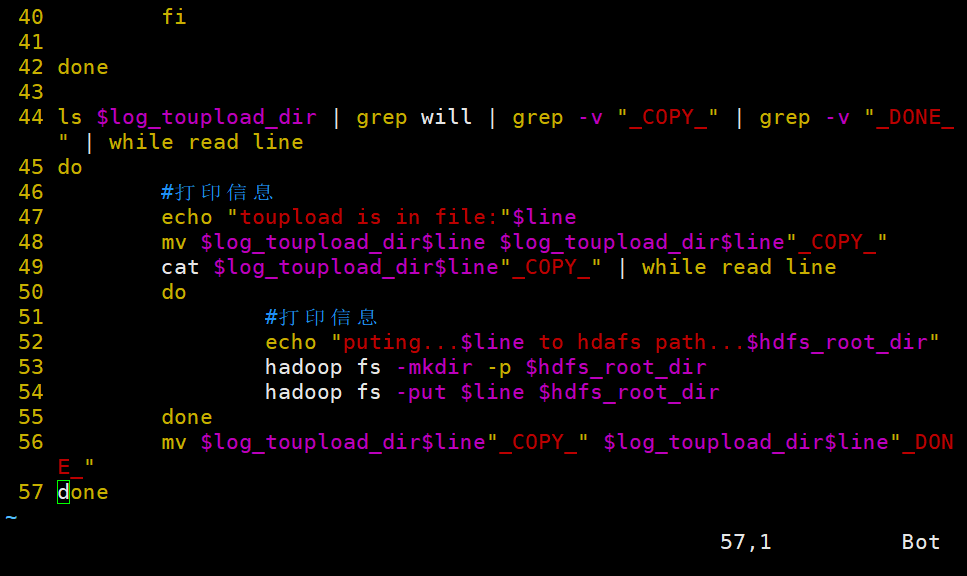
ls $log_toupload_dir | grep will |grep -v "_COPY_" | grep -v "_DONE_" | while read line
do
#打印信息
echo "toupload is in file:"$line
mv $log_toupload_dir$line $log_toupload_dir$line"_COPY_"
cat $log_toupload_dir$line"_COPY_" |while read line
do
#打印信息
echo "puting...$line to hdfs path.....$hdfs_root_dir"
hadoop fs -mkdir -p $hdfs_root_dir
hadoop fs -put $line $hdfs_root_dir
done
mv $log_toupload_dir$line"_COPY_" $log_toupload_dir$line"_DONE_"
done
这样在开启集群的情况下运行脚本便可以把文件夹中的日志文件过滤上传
实验现象:
上传成功,符合条件的文件消失