HDFS的简单学习
上一篇文章将Hadoop环境搭建完毕,下面我们学习一些HDFS的工作原理
HDFS ---> 分布式文件系统 简单说就是把很多数据文件分开放在很多的服务器上,采取分开的方式对很多很多的数据进行分析
一.HDFS特点:
1、支持超大文件
大数据有很多数据,所以能够通过HDFS对很多很多数据进行控制,这个其他做的可能并不是那么好。因为机制原因对小文件反而效果没有那么好。
2、检测和快速应对硬件故障
HDFS拥有备份功能,一个节点挂掉后因为有数据备份,会很快的进行数据更新,将数据从其他节点拿过来。
3、流式数据访问
一般都是批量处理,而不是用户交互式处理,应用程序能以流的形式访问数据库。主要的是数据的吞吐量,而不是访问速度。因此HDFS不适合于低延迟的数据访问,HDFS的是高吞吐量。
4、简化的一致性模型
适合的模型是:一次写入多次读出,可不断追加,但不可修改。
4、高扩展性
数据能够在namenode容量的限制下,不断扩充datanode容量
可能你有这样的疑惑?那HDFS与传统云盘有何区别?

我个人理解:1.HDFS能够处理大量大文件,传统云盘并不能,传统云盘当扩充需要花费money,当容量达到PB就很大了,但是HDFS能够存储更多的数据
2.HDFS拥有备份功能,当子节点datanode挂掉后,会有其他子节点补充,同时又拥有信息备份功能(比如说第一个子节点存储资源 A B ; 第二个子节点存储资源 B C ; 第三个子节点存储资源 C A),所以说当一个挂掉后会有信息进行补充
但是传统云盘不具备!云盘不会给你备份,如果你将云盘中的文件删除后(删除到回收站能恢复不叫备份!那只是把你的文件从一个文件夹拿到另外一个文件夹!时间过后仍然会彻底消失),文件将不存在
3.HDFS适合大吞吐量,高延迟场景,而传统云盘适合低吞吐,低延迟
4.传统云盘,能够不断写入修改读出,但是HDFS只能进行追加写入,读出(一次写入,多次读出)
可能以还有这样的疑惑?那HDFS能开发成云盘吗?

个人理解:如果不修改,只是不断追加和读取,可以作为云盘
二:HDFS中四个节点之间的关系
我理解HDFS中有四个节点,分别是:1.HDFS Client 2.NameNode 3.Secondary NameNode 4.DataNode
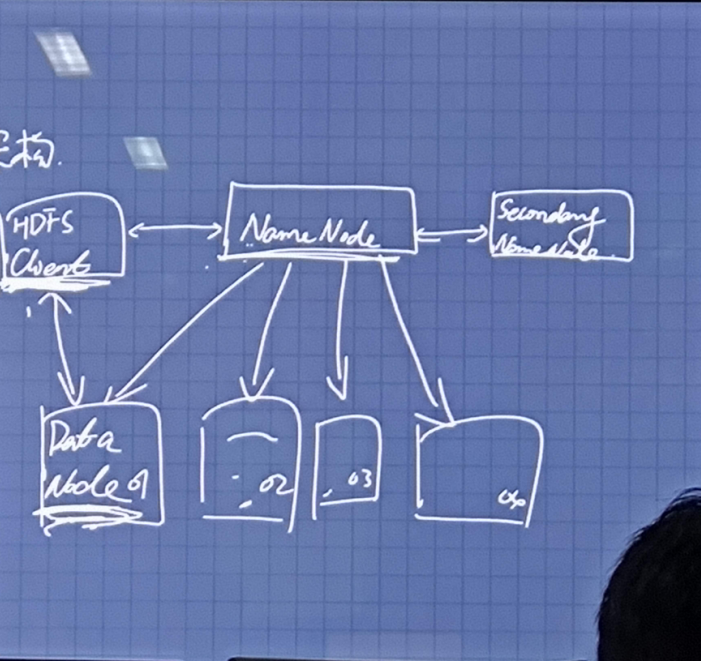
1.HDFS Client
客户端请求访问HDFS时,无论是读还是写都是通过向namenode申请来进行,namenode作为大哥,大哥同意后,客户端可以与datanode进行沟通
会将文件进行分份,每128字节分一份(不同系统好像不同)

2.NameNode
负责客户端请求的响应,负责管理整个文件系统的元数据,是大哥。啥是元数据?就是这样-->/ckj.avi 2 (blk-01,blk-02,blk-03) blk-01:node01,node02 blk-02:node02,node03 (意思就是把文件分成三份,把第一份装到第一个和第二个节点,第二份装到第二个和第三个节点)
有镜像文件和日志文件
3.Secondary NameNode
也有镜像文件和日志文件,镜像文件实时更新,日志文件间断更新,如果namenode挂掉后,会将镜像给namenode(与namenode之间有个公共日志管理系统,可以通过日志恢复)(那公共日志管理系统死掉怎么办?后面的zookeepr会说)
4.DataNode
负责管理用户的文件数据块,每一个文件块可以有多个副本,并存放在不同的datanode上,Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量
因为有备份功能,所以说,一份文件会存好几份,但是访问时访问那个呢?会访问离客户端最近的那个。
拥有心跳机制,不断告诉namenode大哥,他还活着,当他不在告诉大哥他还活着时,大哥会认为他挂掉了,并将他的数据重新放在另外一个blk上
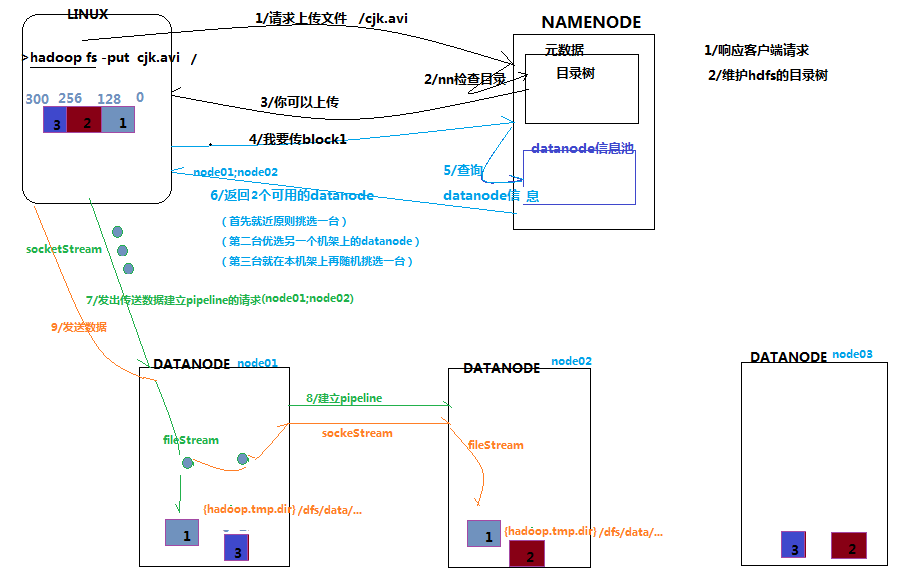
客户请求上传文件流程
首先客户端请求上传,和namenode说一声,nomenode检查一些自己,发现没有,告诉客户端,你可以传,客户端说我要传blk1,nomenode告诉客户端,你可以传到datanode的node1和node2,客户端知道后,建立连接,传过去了
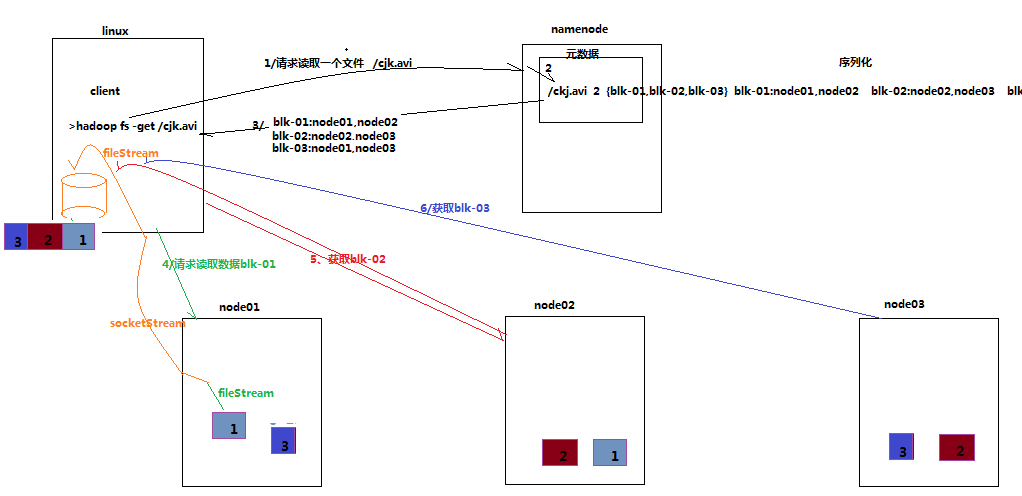
客户端请求读文件流程
步骤基本一样,客户端请求读文件,还是要问我大哥namenode,namenode知道后产生一条元数据给客户端,告诉你,blk1里面有node1,node2,blk2里面有node2,node3,blk3里面有node3,node1,客户端知道后开始读取
secondary namenode与namenode通信流程
namenode里面存储大量镜像文件(Fsimage)和日志文件(Edits),但是随着时间的推移,日志会占很大的空间,这时候将镜像文件及日志文件给secondary namenode ,secondary namenode 将镜像文件和日志文件进行压缩,合并成新的镜像文件,再趁namenode不注意,传给mamemode作为namenode的镜像文件

还有一个问题!HDFS的容量受谁的影响?

当Datanode挂掉或者不足时,会将新的Datanode挂到namenode下,会无限挂吗?不会!因为每挂一个datanode,会将150元数据放在大哥Namenode那里,所以说,Namenode大小限制着HDFS容量,当然这是主要原因,还有诸多原因。
三:HDFS中常用命令
-help 功能:输出这个命令参数手册
-ls 功能:显示目录信息 示例: hadoop fs -ls hdfs://hadoop-server01:9000/ 备注:这些参数中,所有的hdfs路径都可以简写 -->hadoop fs -ls / 等同于上一条命令的效果
-mkdir 功能:在hdfs上创建目录 示例:hadoop fs -mkdir -p /aaa/bbb/cc/dd
-moveFromLocal 功能:从本地剪切粘贴到hdfs 示例:hadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd
-moveToLocal 功能:从hdfs剪切粘贴到本地 示例:hadoop fs - moveToLocal /aaa/bbb/cc/dd /home/hadoop/a.txt
--appendToFile 功能:追加一个文件到已经存在的文件末尾 示例:hadoop fs -appendToFile ./hello.txt hdfs://hadoop-server01:9000/hello.txt 可以简写为: hadoop fs -appendToFile ./hello.txt /hello.txt
-cat 功能:显示文件内容 示例:hadoop fs -cat /hello.txt
-tail 功能:显示一个文件的末尾 示例:hadoop fs -tail /weblog/access_log.1
-text 功能:以字符形式打印一个文件的内容 示例:hadoop fs -text /weblog/access_log.1
-chgrp -chmod -chown 功能:linux文件系统中的用法一样,对文件所属权限 示例: hadoop fs -chmod 666 /hello.txt hadoop fs -chown someuser:somegrp /hello.txt
-copyFromLocal 功能:从本地文件系统中拷贝文件到hdfs路径去 示例:hadoop fs -copyFromLocal ./jdk.tar.gz /aaa/
-copyToLocal 功能:从hdfs拷贝到本地 示例:hadoop fs -copyToLocal /aaa/jdk.tar.gz
-cp 功能:从hdfs的一个路径拷贝hdfs的另一个路径 示例: hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
-mv 功能:在hdfs目录中移动文件 示例: hadoop fs -mv /aaa/jdk.tar.gz /
-get 功能:等同于copyToLocal,就是从hdfs下载文件到本地 示例:hadoop fs -get /aaa/jdk.tar.gz
-getmerge 功能:合并下载多个文件 示例:比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,... hadoop fs -getmerge /aaa/log.* ./log.sum
-put 功能:等同于copyFromLocal 示例:hadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
-rm 功能:删除文件或文件夹 示例:hadoop fs -rm -r /aaa/bbb/
-rmdir 功能:删除空目录 示例:hadoop fs -rmdir /aaa/bbb/ccc
-df 功能:统计文件系统的可用空间信息 示例:hadoop fs -df -h /
-du 功能:统计文件夹的大小信息 示例: hadoop fs -du -s -h /aaa/*
-count 功能:统计一个指定目录下的文件节点数量 示例:hadoop fs -count /aaa/
-setrep 功能:设置hdfs中文件的副本数量 示例:hadoop fs -setrep 3 /aaa/jdk.tar.gz
小知识点:
1.如果两台namenode都是standby,强制将一台变为active 命令:hdfs haadmin -transitionToActive --forceactive --forcemanual nn1

