Python - 1 爬虫-正则表达式re | xpath | css选择器 |
1. re 正则表达式 提取数据
用法:

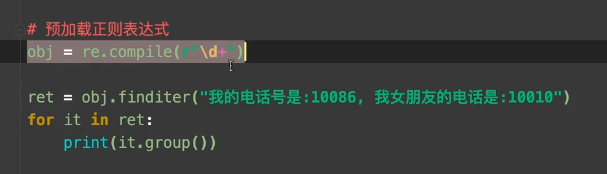
实战 :
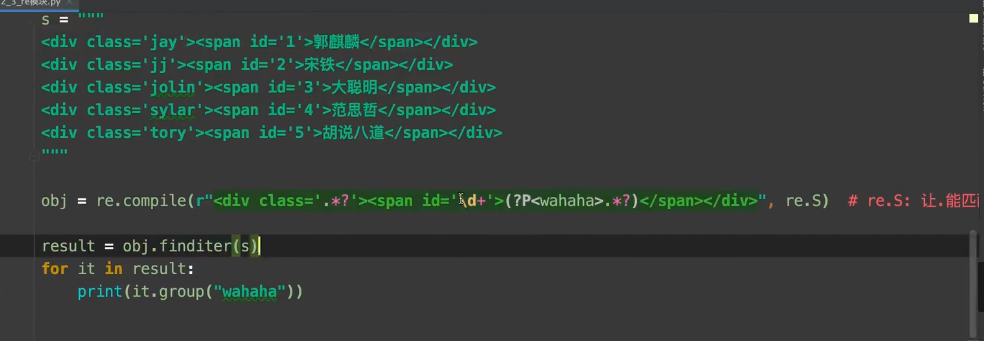
案例 :
2. xpath 提取数据
方法一
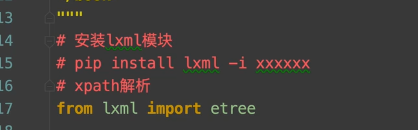
1. 引用
2. 用法

方法二
sel = parsel.Selector(resp) # 当前图片的数量 num = sel.xpath('//div[@id="pages"]/a/text()')
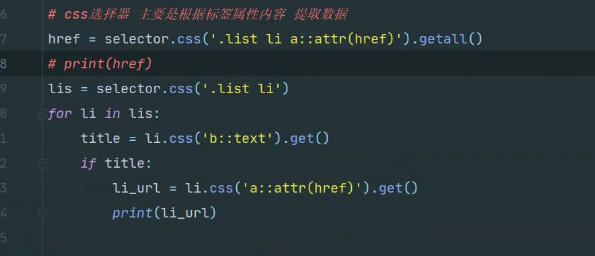
3.css 选择器
1. getall () 获取一个列表
2. get() 是在循环种 使用获取一个对象
列表页的使用
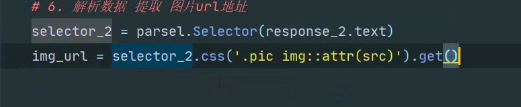
详情页使用
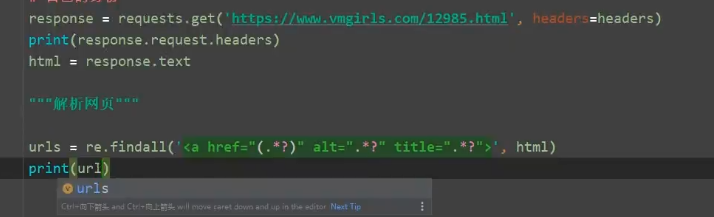
1. re 爬取 网站
import requests import re url = 'https://www.dytt89.com' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36' } resp = requests.get(url, headers=headers) resp.encoding = 'gb2312' print(resp.text) # 解析数据 正则表达式 规则 obj1 = re.compile(r'2022必看热片.*?<ul>(?P<lianjie>.*?)</ul>', re.S) obj2 = re.compile(r"<li><a href='(?P<lianurl>.*?)'", re.S) obj3 = re.compile(r'<div class="title_all"><h1>(?P<title>.*?)</h1></div>', re.S) #提取数据 finditer finditer 到正则表达式所匹配的所有子串 返回 一个迭代器 res1 = obj1.finditer(resp.text) # 存放所有链接 ch_urls = [] for it in res1: ul = it.group('lianjie') # 提取链接 res2 = obj2.finditer(ul) for itt in res2: # 拼接链接 urls =url + itt.group('lianurl') ch_urls.append(urls) for href in ch_urls: resp = requests.get(href, headers=headers) resp.encoding = 'gb2312' print(resp.text) res3 = obj3.search(resp.text) print(res3.group('title')) break # 终止 拿一个数据测试
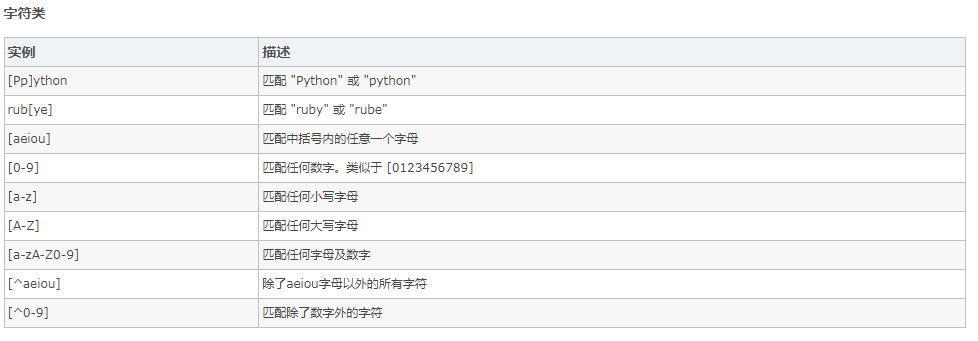
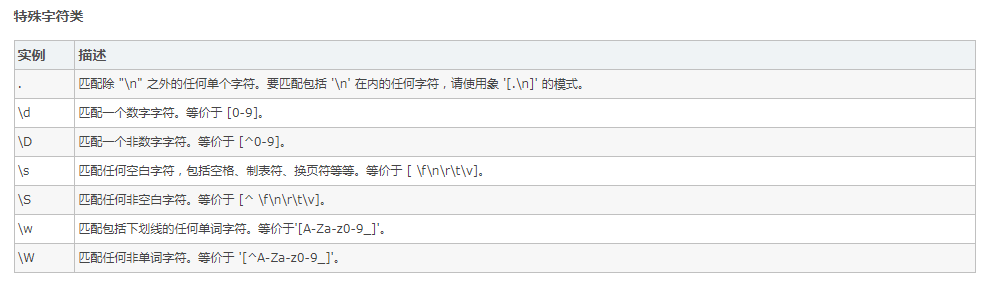
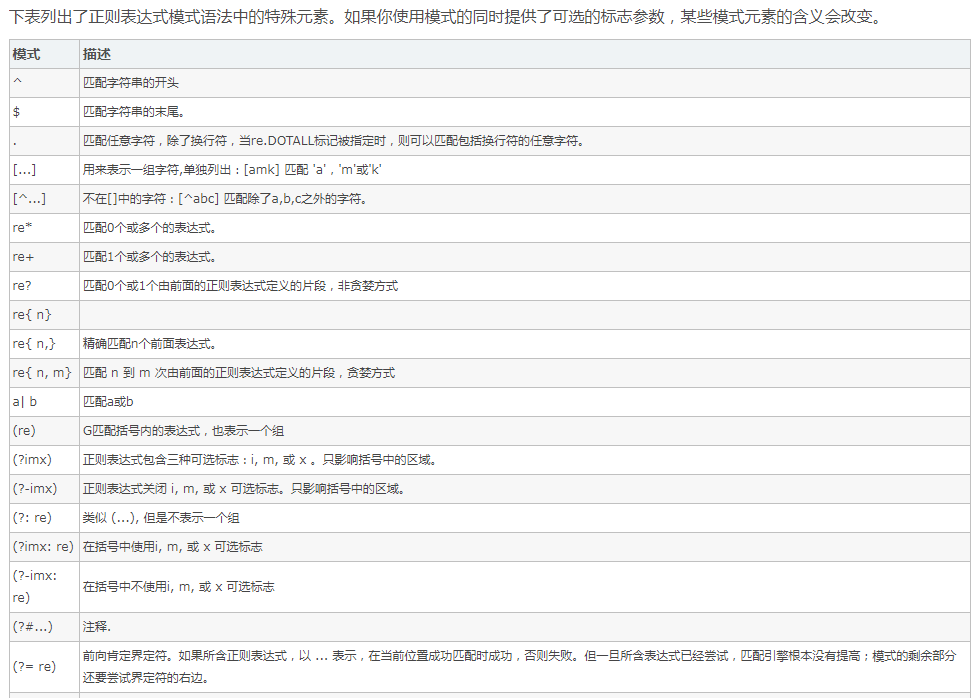
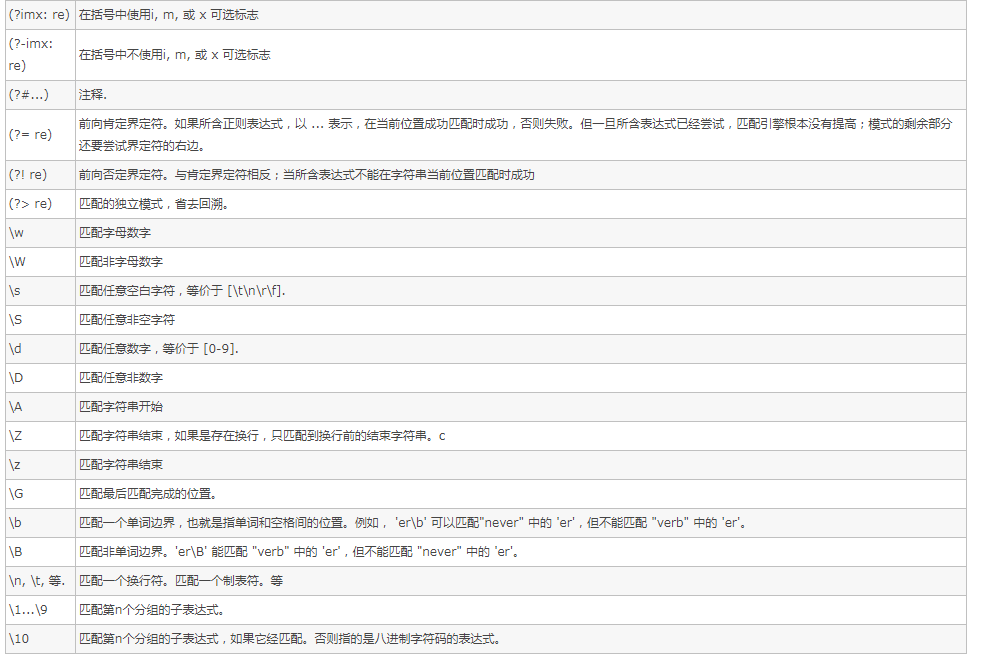
规则 :


 浙公网安备 33010602011771号
浙公网安备 33010602011771号