我们在本章需要了解,掌握数据库、数据库系统、数据库管理系统的基本概念,了解数据库技术发展经历的三个阶段,掌握关系模型、SQL语言的基本概念,掌握MySQL的安装、配置、启动、登录等操作,了解常用图形化工具的使用。
数据库可以理解为excel,但是与excel不同之处在于关系模式,也就是相互之间的关系。
数据库的基本概念:
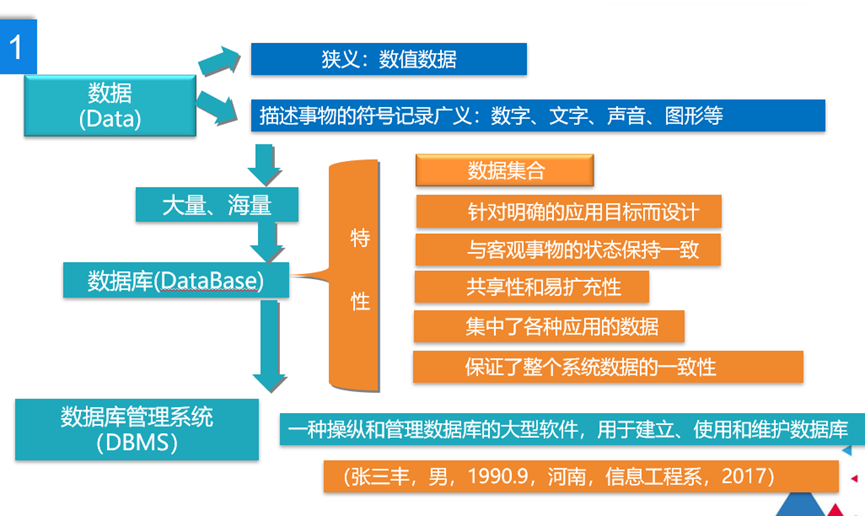
数据(Data):不仅包括普通意义上的数字,还包括文字、图像、声音等。也就是说,凡是在计算机中用来描述事物的信息都可称作数据。
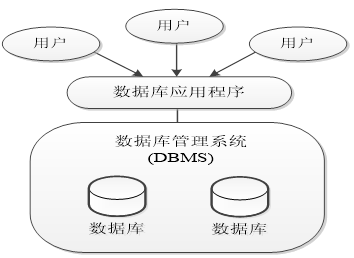
数据库(Database,DB):是按照数据结构来组织、存储和管理数据的仓库。
数据库管理系统(Database Management System,DBMS):专门用于创建和管理数据库的一套软件,介于应用程序和操作系统之间,如MySQL、Oracle等。
数据库应用程序:在很多情况下, DBMS无法满足用户对数据库的管理。此时,就需要使用数据库应用程序与DBMS进行通信、访问和管理DBMS中存储的数据。
数据库系统(DataBase System,DBS):是指在计算机系统中引入数据库后的系统,除了数据库,还包括数据库管理系统、数据库应用程序等。
数据库技术:是计算机领域重要的技术之一。主要应用在互联网、银行、通讯、政府部门、企事业单位、科研机构等领域,都存在着大量的数据。
信息是现实世界事物的存在方式或运动状态的反映,它通过符号、信号等具体形式表现出来。是客观存在的,数据是信息,但信息不一定是数据,数据是信息的物理实体,是具体表现形式,是信息的载体,信息是变化的,不一定是真实的,是一切物质和事务的属性,信息的符号化就是数据,信息是数据的逻辑意义(物理意义),信息可以独立存在
数据库技术研究的意义:
- 如何对数据进行有效的管理,包括如何组织和存储数据。
- 如何在数据库系统中减少数据存储冗余(处理重复数据)、实现数据共享(区分前两个阶段)、保障数据安全(钱),以及高效地检索和处理数据。
(聚类分析)
数据库技术的发展:
任何一种技术都不是凭空产生,而是经历了长期的发展过程。通过了解数据库技术的发展历史,可以理解现在的数据库技术是基于什么样的需求而诞生的。
数据库技术的发展主要分为3个阶段,分别是人工管理阶段,文件系统阶段和数据库系统阶段
人工管理阶段:人工进行处理
文件系统阶段:
文件系统阶段的特点:
- 数据在计算机外存设备上长期保存,可对数据反复进行操作。
- 通过文件系统管理数据,文件系统提供了文件管理功能和存取方法。
- 在一定程度上实现了数据独立性和共享性,但都非常薄弱。
数据库系统阶段:
为了提高数据管理的效率,解决多用户、多应用程序共享数据的需求,数据库技术应运而生,由此进入了数据库系统阶段。
数据库系统阶段的特点:
- 数据结构化:数据库系统实现了整体数据的结构化,这是数据库主要的特征之一。
- 数据共享:数据只需保存一份,其他软件都通过数据库系统存取数据。
- 数据独立性高:数据的独立性包含逻辑独立性和物理独立性。
- 数据统一管理与控制:包含安全控制、完整控制和并发控制。
数据模型
数据库的类型通常按照数据模型(Data Model)来划分。
数据模型是数据库系统的核心和基础。
数据模型是对现实世界数据特征的抽象,用来描述数据,可理解成一种数据结构。
在数据库的发展过程中,出现了3中基本的数据模型,层次模型,网状模型和关系模型,建立在关系模型上的数据库称为关系数据库。
数据建模
数据建模是对现实世界中的各类数据的抽象组织,以确定数据库的管辖范围、数据的组织形式等。
将文字转换为E-R图,将E-R转换为二维表,就是我们所主要需要学习的东西
基本概念
1.实体(Entity)是指客观存在并可相互区分的事物。
例如,学生、班级、课程都是实体。实体就是一个个具体的事物,比如我是一个学生,一个老师,一个班级,这是都是实体
2.属性(Attribute)是指实体所具有的某一特性,一个实体可由若干个属性来描述。属性就是具体的事物的细分
例如,学生实体的属性有学号、学生姓名和学生性别。
3.属性由两部分组成,分别是属性名和属性值。
例如,学号和学生姓名是属性名,而“1、张三”这些具体值是属性值。(1是学号,学生姓名是张三)
4.联系(Relationship)是指实体与实体之间的联系,有一对一、一对多、对多对三种情况。如果以下三种情况在哪里加外键
当1对1时 无
1对N,在n那边加外键
M对N,新建一个表去进行1对1
5.E-R图
E-R图也称为实体-联系图(Entity Relationship Diagram)。
E-R图是一种用图形表示的实体联系模型,由Peter Chen于1976年提出。
E-R图提供了表示实体型、属性和联系的方法,用来描述现实世界的概念模型。
在E-R图中:
实体:用矩形框表示,将实体名写在框内。
属性:用椭圆框表示,将属性名写在框内,用连线将实体与属性连接。
联系:用菱形框表示,将联系名写在框内,用连线将相关的实体连接,并在连线旁标注联系类型(一对一“1:1”、一对多“1:n”、多对多“n:m”)。
关系(Relation)一词与数学领域有关,它是集合基础上的一个重要的概念,用于反映元素之间的联系和性质。
从用户角度来看,关系模型的数据结构是二维表,即通过二维表来组织数据。
一个关系对应一张二维表,表中的数据包括实体本身的数据和实体间的联系。
关系模式(Relation Schema):是关系的描述,通常可以简记为“关系名(属性1,属性2,…,属性n)”。
例如,学生(学号,姓名,性别,出生年月)。
属性(Attribute):二维表中的列称为属性,每个属性都有一个属性名。
元组(Tuple):二维表中的每一行数据称为一个元组。
域(Domain):域是指属性的取值范围,例如,性别属性的域为男、女。
键(Key):在二维表中,唯一标识某一条记录,又称为关键字、码。一般称之为主键,而经过其他表引入的称为外键
例如,学生的学号具有唯一性,学号可以作为学生实体的键。而学生姓名可能存在重名,不适合作为键。
关系模型的完整性:为了保证数据库中数据的正确性和相容性,需要对关系模型进行完整性约束。完整性通常包括实体完整性、参照完整性和用户自定义完整性
- 实体完整性:要求关系中的主键不能重复,且不能取空值。空值是指不知道、不存在或无意义的值。
- 参照完整性:要求关系中的外键要么取空值,要么取被参照关系中的某个元组的主键值。
- 用户自定义完整性:是用户针对具体的应用环境定义的完整性约束条件,由DBMS检查用户自定义的完整性。
每个表中应该含有的信息,一共4个表
零件表:(零件号,零件名,单价)
产品表:(产品号,产品名,型号)
供应商表:(供应商号,供应商号,地址)
数量表:(零件号,产品号,供应商号,数量)
供应是这4个表之间的联系
=======================================================================================================================
第二章:数据库基本操作
2.1 数据库操作:
创建数据库:create database 数据库名称
创建相同名称的数据库:create database if not exists 数据库名称(与前一个名称相同)
if not exists 作用:创建两个相同名称的数据库,程序会报错,加if not exists后程序不再报错,但是会返回一条警告消息
查看错误信息:show warns
查看数据库:1.查看MySQL服务器下所有数据库:show databases
2.查看指定数据库的创建信息show create database 数据库名称
选择数据库:use 数据库名称
删除数据库:drop database 数据库名称
添加注释:/* */
注意:1.换行、缩进和结尾分隔符,多行书写时可以按回车键换行,在命令行窗口也可以使用"\g"结尾,效果与分号相同。2.大小写问题:MySQL的关键字在使用时不区分大小写。3.反引号的使用:为了避免自定义名称与系统的命令(例如关键字)冲突,最好使用反引号('')包裹数据库名称、字段名称和数据表名称。
2.2 数据表操作:
创建数据表:create table 表名
查看数据表:show tables (查看数据表)/show table status [from 数据库名](from+数据库名:该条信息从哪个库来的,[]表明括号内为非必选项)
修改数据表:
1.修改数据表名称:alter table 旧表名 rename [to|as] 新表名/rename table 旧表名1 to 新表名1[,旧表名2 to 新表名2]......
2.修改表选项:alter table 表名
查看表结构:
1.查看数据表的字段信息:desc 数据表名(查看所有字段的信息)desc 数据表名 字段名(查看指定字段的信息)
2.查看数据表的创建语句:show create table 表名
3.查看数据表结构:show [full] coumns from 数据表名[from 数据库名]/show [full] columns from 数据库名.数据表名
修改表结构:
1.修改字段名:alter table 数据表名 change 旧字段名 新字段名 字段类型[字段属性]
2.修改字段类型:alter table 数据表名 modify 字段名 新类型[字段属性]
3.修改字段位置:alter table 数据表名 modify 字段名1 数据类型[字段属性][first|after 字段名2]
4.新增字段:alter table 数据表名 add 新字段名 字段类型[first|after 字段名]/alter table 数据表名 add (新字段名1 字段类型1,新字段名2 字段类型2,.....)
5.删除字段:alter table 数据表名 drop 字段名
6.删除数据表:drop table 数据表1[,数据表2]...
补充关于modify:
2.3 数据操作:
添加数据:
为所有字段添加数据:insert [into] 数据表名
为部分字段添加数据:insert [into] 数据表名(字段名1[,字段名2]...)
一次添加多行数据:insert [into] 数据表名 +多行数据
查询数据:
1.查询表中全部数据:select * from 数据表名
2.查询表中部分字段:select {字段名1,字段名2,字段名3,...} from 数据表名
3.简单条件查询数据:select * /{字段名1,字段名2,字段名3,...}from 数据表名 where 字段名 =值
修改数据:
update 数据表名 set 字段名1 =值1[,字段名2 =值2,...][where条件表达式]
删除数据:delete from 数据表名 [where条件表达式]
删除数据有两种情况:1.删除指定行:delete from 表名 where 条件
2.删除所有表中数据:delete from 表名 注意区分 delete 和 drop table
第三章:数据类型与约束
3.1 数据类型:
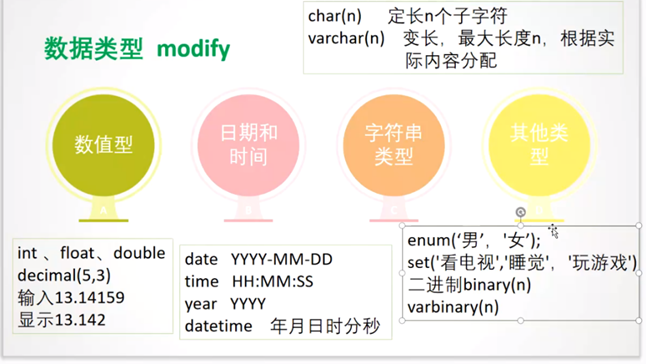
数字类型:整数类型(int)/浮点数类型(float单精度/double双精度)/定点数类型(decimal,通过decimal(M,D)设置位数,精数)/BIT类型(BIT(M),M为位数,1-64位)
时间和日期类型:date/datetime
字符串类型:char(固定长度字符串(定长))/varchar(可变长度字符串(不定长))/text(文本)
3.2 表的约束
(共五种,可以在创建表时设置,也可以在修改表结构时调整/添加):
默认约束(表中字段为默认值,若为数值,直接写入;若为字符,由单引号引起):字段名 数据类型 default 默认值(BLOB,text不支持)
非空约束(该字段必有值,不为空):字段名 数据类型 not null
唯一约束(该字段可为空,但是若有数据则不可重复,只能唯一存在):unique(字段名1,字段名2,...)
主键约束(表中必有约束,唯一且不为空,一般写primary key 无需再写not null,可以是单字段做主键,也可以是多字段做主键,即primary key(a,b)):primary key (字段名1,字段名2,...)
外键约束(将表进行关联,即ER图中的联系):constraint 外键名 foreign key 字段名 references 主表名(字段名)
第四章
4.2 数据库设计范式:
由于本章所学不多只搞好范式即可
第一范式(NF)(数据不可分):指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,也就是实体中的某个属性能有多个值,或者不能有重复的属性
第二范式(2NF)(2NF遵从唯一性,非主键字段需完全依赖主键):以NF为基础,满足2NF的前提是满足NF,2NF要求实体的属性完全依赖于主键,不能仅依靠主键的一部分(对于复合主键而言)
第三范式(3NF)(非主键字段不能相互依赖):以2NF为基础,满足3NF的前提是满足2NF,3NF要求一个数据表中每一列数据都和主键直接相关,而不能间接相关
第五章:单表操作
5.1数据操作:
清空数据:truncate [table] 表名
去除重复记录:select 字段列表 from 数据表表名 (select distinct 字段名 as 用户编号 from 表名 where uid=‘1001’(附加条件))
5.2排序与限量:
一、排序:
1.单字段排序:select */字段列表(字段名)(具体行或者列) from 表名 order by 字段名 asc/desc(升序/降序)
2.多字段排序:select */字段列表 from 表名 order by 字段名1 asc/desc [,字段名2 asc/desc]....
限量:Select */具体行或者列 from 表名 where order by ()asc/desc (限制条件,升序/降序) limit 数字/m[,n](从第m+1行开始,共显示n行数据) eg:0,2(从第0+1行开始显示2行数据)
5.3分组与聚合函数:
分组统计:select 字段名 from 表名 where条件表达式 group by 字段名
分组排序:select 字段名 from 表名 where条件表达式 group by 字段名 [asc/desc]
多分组统计:select 字段名 from 表名 where条件表达式 group by 字段名1 [asc/desc],[,字段名2[asc/desc]]....
统计筛选:select 字段名 from 表名 where条件表达式 group by 字段名 [asc/desc],having条件表达式
别名:select 原名称 as 想改的名称(改名) 或者 select 原名称 想改的名称(去掉as) from 所在表名
聚合函数:count(统计数量),sum(求和),avg(平均值),max(最大值),min(最小值) select字段名,count/max/…(限制条件) from表名 group by 主键
拓展:
一、Where与having条件:select from where 条件 group by … having 条件二者区别:
1.语法位置不同
2.执行顺序(先where,在分组;having只能跟在分组结果上筛选数据)
3.统计函数不能写在where之后
二、数据查询结构式:
select *列名,列名|函数|表达式 from 表名 where 条件(不能写函数)group by.列名.having.条件(可以写函数) order by 列名 limit m[,n](m,n是数字)
三、
6类条件:
(1)表达式=、 >、<、 >=、<=、!=、<>
(2)逻辑查询 A and B (AB条件都满足)、 A or B(AB条件满足一个即可)
(3)模糊查询 字段名 like '王%' _ 1个字符 %表示0或多个字符
(4)空值查询 null 、not null select...from... where 字段名 is null 注意:不要写 字段名=null
(5)范围查询 between ..x.and...y not between...and... 注意:可以与>= <=互换,包括x,y
(6)列表in查询 in(a,b,c,...) 注意:可以同or互换
第六章:多表操作
6.1多表查询:
连接查询:
1.交叉查询(表1的第一行把表2的所有行连一遍,表1的第二行把表2的所有行连一遍,以此类推):select 查询字段(例如c.cid cid,c.name cname,g.id gid,g.name gname) from 表1 fross join 表2
2.内连接:select 查询字段 from 表1 join 表2 on 匹配条件
3.左外连接:select 查询字段 from 表1 left join 表2 on 匹配条件
4.右外连接:select 查询字段 from 表1 right join 表2 on 匹配条件
#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=
本文来自博客园,作者:凡是过去,皆为序曲,转载请注明原文链接:https://www.cnblogs.com/longhai3/p/15887863.html
如有疑问,欢迎提问
#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=#+=

 浙公网安备 33010602011771号
浙公网安备 33010602011771号