Kubernetes 同一个 Node 节点内的 Pod 不能通过 Service 互访
前言
最近在测试 Kubernetes 应用的时候,发现了一个非常蛋疼的问题:同一个 Node 节点内的 Pod 不能通过 Service 互访。
各种百度、google,都没有查到有效的解决方法,一度怀疑是我部署的集群有问题,经过多天的折腾,终于找到问题所在,下面进行一下记录,作为一个实验报告吧~~
环境信息
| Kubernetes版本 | v1.18.8 |
| 网络组件 | flannel:v0.12.0-amd64 |
|
组件部署方式 |
flannel 使用 DaemonSet 部署,coreDns 使用Deployment 部署,其他组件(etcd、kube-apiserver、kube-controller-manager、kube-scheduler、kubelet、kube-proxy)使用二进制部署 |
|
kube-proxy运行模式 |
ipvs |
| 资源名称 | 资源类型 | Cluster-IP | 网关 | 所在节点 | 监听端口 |
| mars1 | Pod | 10.244.0.18 | 10.244.0.1 | k8s1 | / |
| mars2 | Pod | 10.244.2.31 | 10.244.2.1 | k8s2 | / |
| mars3 | Pod | 10.244.1.43 | 10.244.1.1 | k8s3 | / |
| nginx-app | Deployment | / | / | / | |
| nginx-app-57679cfb75-6z8nq | Pod | 10.244.0.19 | 10.244.0.1 | / | 80 |
| nginx | Service | 10.98.171.178 | k8s1 | 8080 |
kubectl get pod -o wide
kubectl get svc
kubectl get deployment
现象
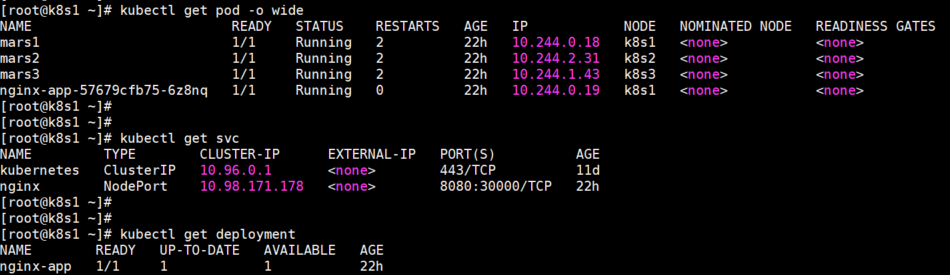
1、mars1、mars2、mars3 三个 Pod 访问 nginx-app-57679cfb75-6z8nq 这个 Pod 的 80 端口是正常的
kubectl exec mars1 -- nc -v -z -w 5 10.244.0.19 80 kubectl exec mars2 -- nc -v -z -w 5 10.244.0.19 80 kubectl exec mars3 -- nc -v -z -w 5 10.244.0.19 80
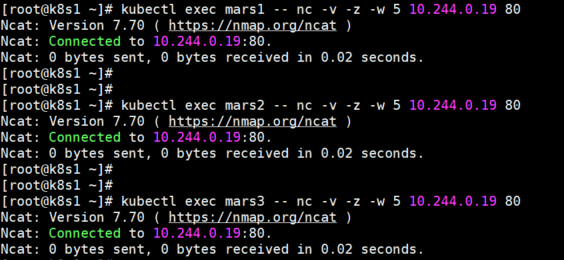
2、mars1 不能访问 nginx 这个 Service 的 8080 端口,mars2、mars3 可以访问 nginx 这个Service 的 8080 端口
kubectl exec mars1 -- nc -v -z -w 5 10.98.171.178 8080 kubectl exec mars2 -- nc -v -z -w 5 10.98.171.178 8080 kubectl exec mars3 -- nc -v -z -w 5 10.98.171.178 8080
3、多次尝试后,发现当两个 Pod 处于同一个 Node 节点时,就不能通过 Service 的 IP+端口互访
即如果把 nginx 的 Pod 调度到 k8s2 节点的话,就会变成 mars2 不能访问 10.98.171.178:8080,调度到 k8s3 节点的话,mars3 不能访问 10.98.171.178:8080。
排查过程
1、首先在 Google 、百度上面各种查,大多数的文章主要是针对 kubelet 的 hairpinMode 配置,该配置必须设置为 hairpin-veth 或者 promiscuous-bridge,查看了一下,我当前的配置是 hairpinMode: promiscuous-bridge,没有问题,尝试修改为 hairpin-veth 并重启 kubelet ,问题依旧。
#在所有 Node 节点执行 sed -i 's/hairpinMode: promiscuous-bridge/hairpinMode: hairpin-veth/' /var/lib/kubelet/config.yaml systemctl restart kubelet
2、同时需要 /sys/devices/virtual/net/docker0/brif/veth-xxx/hairpin_mod 内容设置为1,查了配置已经均为1,没有问题。
3、尝试把 kube-proxy 的运行模式改为 iptables 并重启 kube-proxy ,问题依旧。
4、没办法之下只能抓包分析,由于一开始使用的镜像是 nginx官方镜像、busybox官方镜像,不方便进行抓包,于是自行用 centos 的官方镜像安装了一些测试工具进行调试,上面的 mars1、mars2、mars3、nginx-app 都是使用该镜像生成的。
(1)首先看看正常访问的抓包结果:在 mars2 及 nginx-app-57679cfb75-6z8nq 上面抓包(两者在不同的 Node 节点上),mars2 上面使用自身的 IP为条件,nginx-app-57679cfb75-6z8nq 上面使用 80 端口为条件,然后在 mars2 上面使用 nc 命令访问 nginx 这个 Service 的 8080 端口,结果如下:
mars2 的抓包结果
tcpdump -vnn -i eth0 host 10.244.2.31
nginx-app-57679cfb75-6z8nq 的抓包结果
tcpdump -vnn -i eth0 port 80
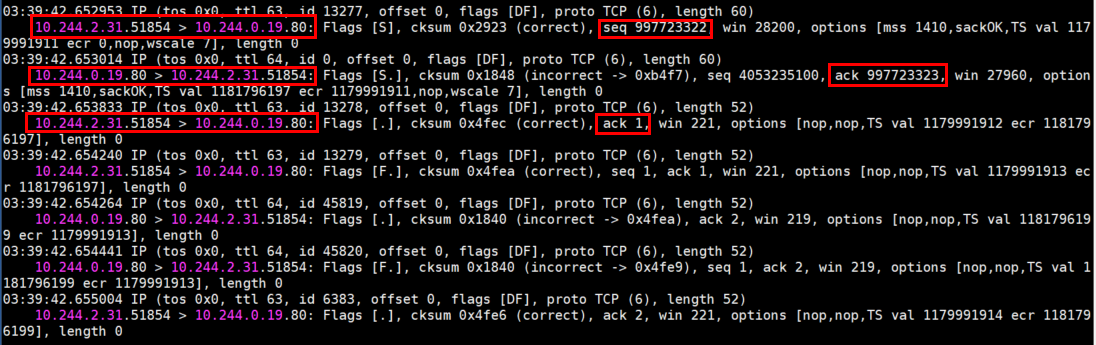
可以看到,在 mars2 上面是自身的随机端口访问 Service 的 8080 端口,然后收到了 Service 的返回,正常建立了 TCP 三次握手。
而在 nginx-app-57679cfb75-6z8nq 上面,可以看到源 IP 是 mars2 的 Pod IP,也就是说,Service 只是对访问的流量进行了 DNAT,没有做 SNAT,但这样的话为什么 nginx-app-57679cfb75-6z8nq 直接给 mars2 的 Pod IP 回包,而 mars2 收到的包的源 IP 却又变成了 Service 的 IP 呢,我理解是因为 mars2 和 nginx-app-57679cfb75-6z8nq 不在同一个 Node 节点上,所以回包会经过网关 10.244.0.1 ,而网关会自动做一次回包的 SNAT ,把 nginx-app-57679cfb75-6z8nq 的 IP 转成 Service 的 IP,所以 mars2 收到的回包源 IP 就变成了 Service 的 IP。
到了这里,问题的答案似乎已经呼之欲出了,接下来进行第二个抓包试验。
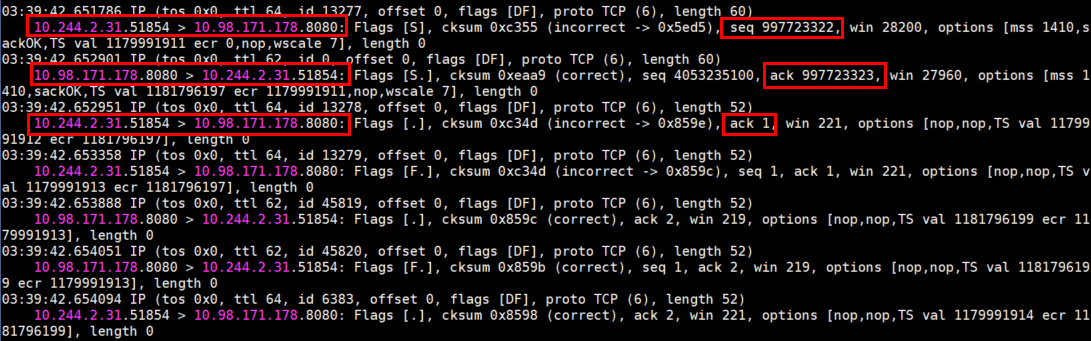
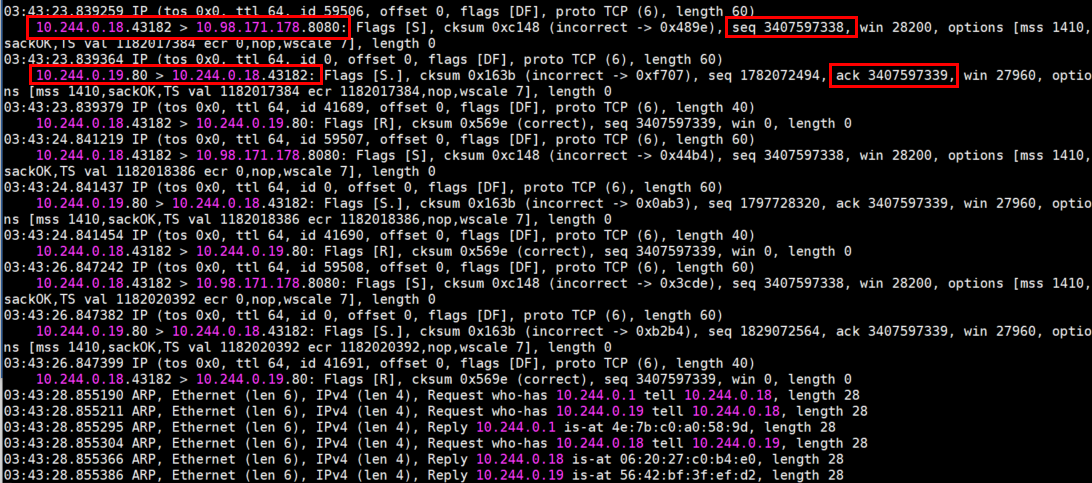
(2)再来看看访问不正常的抓包结果:在 mars1 及 nginx-app-57679cfb75-6z8nq 上面抓包(两者在相同的 Node 节点上),mars1 上面使用自身的 IP为条件,nginx-app-57679cfb75-6z8nq 上面使用 80 端口为条件,然后在 mars1 上面访问 nginx 这个 Service 的 8080 端口,结果如下:
mars1 的抓包结果
tcpdump -vnn -i eth0 host 10.244.0.18
nginx-app-57679cfb75-6z8nq 的抓包结果
tcpdump -vnn -i eth0 port 80
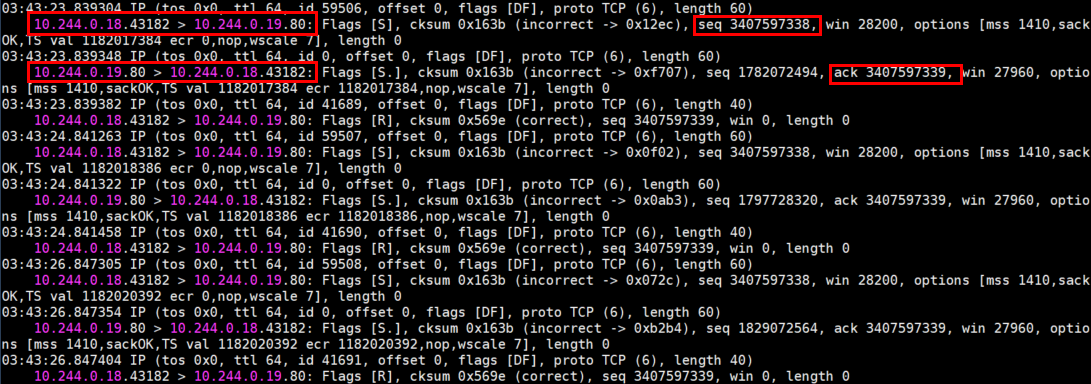
以上两个截图进一步验证了我的猜想, 原因就在于 Service 没有对访问它的流量做 SNAT ,nginx-app-57679cfb75-6z8nq 直接以 mars1 的 Pod IP 为目标 IP ,以自身的 Pod IP 为源 IP 进行回包。而由于两者是在同一个 Node 节点,处于同一个子网,走的是二层通信,没有经过网关,也不会有 NAT 转换。mars1 其实是已经接收到了 nginx-app-57679cfb75-6z8nq 的回包,但因为回包的源 IP+端口(10.244.0.19:80)和它发出去的请求的目标 IP+端口(10.98.171.178:8080)不一致,直接把包丢弃了。
既然问题的原因已经找到了,那么解决的方向就是如何让 Service 对访问它的流量做 SNAT 。又经过一番排查,发现了 kube-proxy 有一个配置项 masqueradeAll ,当前的配置为 false 。
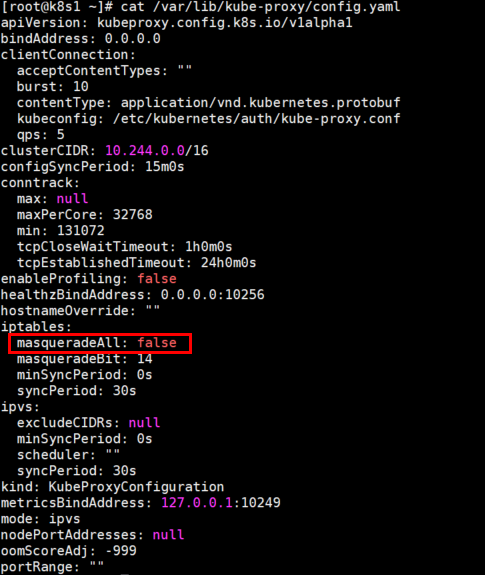
根据字面意思,是把流量进行伪装,这不就是 iptables 里面的 MASQUERADE 吗,又找了 google 爸爸,查到这个配置项的作用:
| masquerade-all | 如果使用纯 iptables 代理,对所有通过集群 Service IP发送的流量进行 SNAT(通常不配置) |
看起来就是我要的结果,把配置文件里面的值改成 true 并重启 kube-proxy。
#在所有 Node 节点执行 sed -i 's/masqueradeAll: false/masqueradeAll: true/' /var/lib/kube-proxy/config.yaml systemctl restart kube-proxy
在 mars1 及 nginx-app-57679cfb75-6z8nq 上面重新抓包,mars1 上面使用自身的 IP为条件,nginx-app-57679cfb75-6z8nq 上面使用 80 端口为条件,然后在 mars1 上面访问 nginx 这个 Service 的 8080 端口,结果如下:
mars1 的抓包结果
tcpdump -vnn -i eth0 host 10.244.0.18
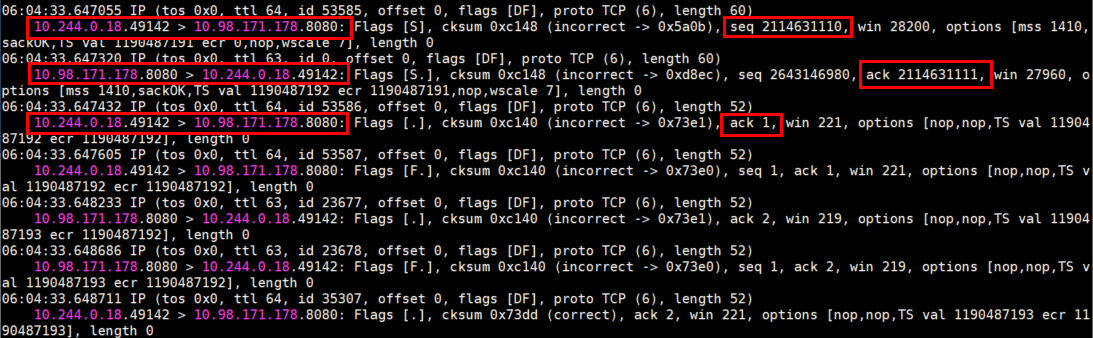
nginx-app-57679cfb75-6z8nq 的抓包结果
tcpdump -vnn -i eth0 port 80
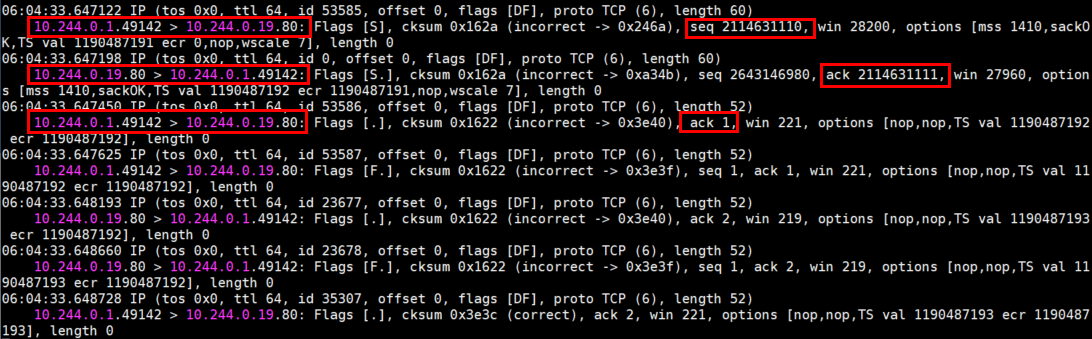
根据以上截图,可以看到,这次 mars1 正常建立了 TCP 三次握手,因为收到了 Service 的回包。另外,nginx-app-57679cfb75-6z8nq 上面看到访问的源 IP 变成了 mars1 的网关(10.244.0.1),所以 Service 针对访问它的流量做了 SNAT+DNAT,准确来说是做了 MASQUERADE ,nginx-app-57679cfb75-6z8nq 回包的时候就不会产生之前的 IP+端口不对应的问题了。同时测试了 mars2、mars3 都可以正常访问 Service。
总结
这种故障主要出现在 Kubernetes 集群里面应用间需要通过 Service 的 IP 或者域名互访的场景,如果集群里面的应用只提供给外部访问,是不会有这种问题存在的。如果 nginx 是多个 Pod 的话,可能不容易发现,只会出现偶尔访问不通的情况,排查的时候最好只保留一个 Pod 。
这个故障排查了好几天,主要耗费时间的地方在于一直想在网上找到现成的解决办法,而一直找不到。其实抓包分析是很基础的排查方法,但由于是容器环境,镜像里面难免会缺少一些必要的工具/命令,这时候我们就需要一个方便用于排查问题的镜像。其实自己制作一个适合自己使用的镜像并非难事,对于日常问题的排查还是非常有用的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号