

异地多活的数据一致性简单设计
概述
异地多活,往往意味着夸机房读写延迟的增加,也就增加了读写失败的可能性,最终导致数据的延迟更长,同时,这种场景下也会影响在线系统的性能和时延。本文从数据低延迟、开发复杂度上考虑,总结了两种处理方式,分别是双写和双读,从而保证数据的最终一致性。对于异地多活的业务场景,往往也不需要保证强一致性,允许短时间的不一致性。例如对于外卖软件,在南方点了外卖,然后到北方出差,常规上也不可能短时间内(分钟级别)从南方飞到北方。
再举个极端的例子,我们所看到星空中的行星的光,也很多是很多年前从很远的宇宙发射过来的,你不可能在同一时间看到光。
再者,实现真正的异地多活(强一致,多节点写入)是个极其复杂的工程,需要底层数据库、业务上的支持,对于一致性要求没那么高的业务场景,我们可以选择稍微简单的方案实现。
双写
写入本机房后,还需要写入异地机房,同步方式可以有:
-
数据库本身支持了同步:这种情况往往需要增加第三方组件,例如阿里的otter组件支持了mysql的同步。业务代码只需要写一次,底层数据同步交给数据库,会出现短时间的两个机房数据不一致的情况,业务上往往能够接受。但极端情况也会出现异地对同一份数据进行写,导致写写冲突,这时候需要业务介入做抉择(常见的方式如订单系统后期的对账补偿)。如果对于数据库的操作是数据库级别的原子性操作,例如redis的incr命令,就可以避免写写冲突。
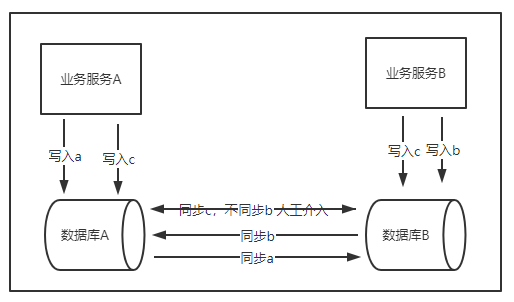
-
数据库本身不支持同步:这种情况需要业务代码双写,跨区写的失败率会变高,采取重试,但会加剧数据的延迟(如果延迟不高,也能接收)。同时,如果是在线系统,往往并发量比较大,所以还是得在业务层面加MQ,如加入第三方的MQ(如kafka),实现上就得实现producer和consumer逻辑,而且还需要额外对kafka进行维护,这也带来了系统的复杂性。简单做法是采用内存队列,直接写入内存队列,通过定时器定期消费内存队列数据。如果数据支持批量接口,采用批量写数据库,读的时候,只读本机房数据。这种方式,也会有问题:因为是内存队列,如果服务重启,还没来得及消费的数据会丢失;或者是多次写失败重试后依然失败,也会导致数据丢失(其实这种情况需要发出告警,人工介入了)。如果业务允许有一定的数据丢失的情况,但对时效性要求较高的,采用这种方式比较合理。
双读
跟双写的读本机房相反,改成只写本机房,读双机房。这种方式,首先对于高并发的读,非常不友好,跨区读的时延太高,同步读往往会导致超时或者影响在线时延。所以一般采用异步的方式,由一个异步线程把数据从另一个机房捞出来再写入本地机房数据库,读的时候只读本地机房数据库库。这种方式加大了延迟,好处是提高了并发度,尽量的减少对读的影响,而且如果本地支持幂等性,还能保证数据的最终一致。数据从异地同步到本地的机制可以两种:
-
全量同步:实现简单,但只适合于数据量少,但如果数据太多,同步也会很慢,加大了延迟,有可能打满网卡导致影响整体服务环境。
-
增量同步:实现复杂,需要设置个游标,类似kafka的offset,记录本次同步到的点,如何标准游标是准确的呢?需要保证不多也不少,例如如果游标粒度设置的太大,同一个游标可能对应多个数据,这样可能导致捞过来的数据比原有的多。所以这种情况对游标的选择就比较重要了。
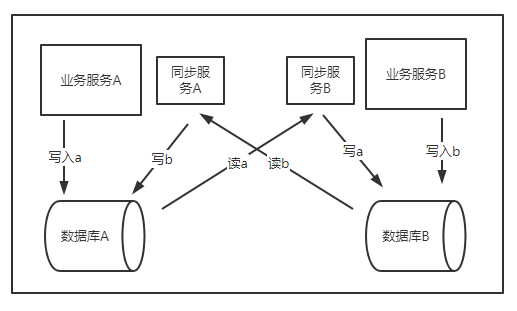
高并发下的优化方案
批量:无论是对于双读还是双写,都采用数据库的批量接口,减少网络io。
异步+双队列缓存
-
- 异步:对于双写方案,采用异步写;对于双读方案,采用异步读更新(这种情况除非是增量更新,否则如果全量更新,也会导致性能和延迟的增加;但全量更新就要求数据不能太多,而且如果数据库是redis或者其他kv,需要提前知道对应的key)。
- 双队列缓存:双buffer是为了提高并发度,对于双写,可以只需要对内存中的写进行互斥,但对于数据的更新不会互斥,因为两者个用不同队列;对于双读,数据结构可以参考我之前发的doublybufferdata数据结构。对于队列,其实是传统MQ的替代,只是如果引入MQ,则需要带来额外的维护成本,所以可以简单的实现,用set或者map都可以。
总结
双读和双写的本质区别其实是数据在哪一边同步的问题,类似kafka的producer和consumer,不可能放在同一个机房,要么producer端是夸机房,要么是consumer端是夸机房。无论是哪种方案,都会面临延迟和不一致问题,以及还有性能问题,要兼顾延迟性、一致性、性能等,实现起来极其复杂,需要根据业务需要选择一种折中的方案。
作者:bytesmover
出处: https://www.cnblogs.com/longbozhan/p/16011848.html
如果您觉得本文对您有帮助,请点击一下右下方的推荐按钮, 如果您对本文有任何疑问并想和作者探讨,请在本文下方评论,我看到后将第一时间回复!
版权声明:本文为博主原创或转载文章,欢迎转载,但转载文章之后必须在文章页面明显位置注明出处,否则保留追究法律责任的权利。
出处: https://www.cnblogs.com/longbozhan/p/16011848.html
如果您觉得本文对您有帮助,请点击一下右下方的推荐按钮, 如果您对本文有任何疑问并想和作者探讨,请在本文下方评论,我看到后将第一时间回复!
版权声明:本文为博主原创或转载文章,欢迎转载,但转载文章之后必须在文章页面明显位置注明出处,否则保留追究法律责任的权利。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~