DAOS存储
DAOS 分布式异步对象存储|架构设计
DAOS 分布式异步对象存储|事务模型
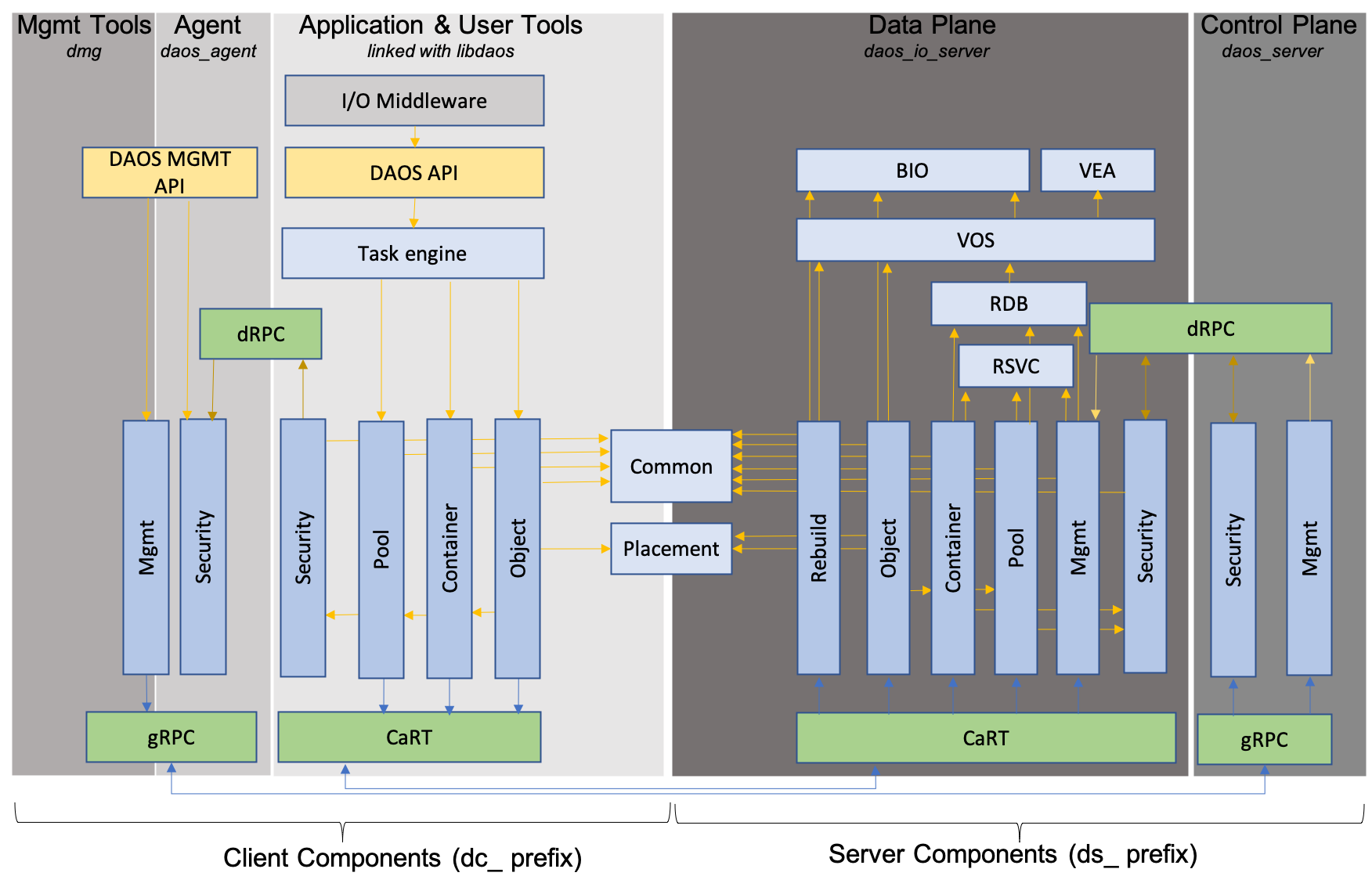
DAOS 分布式异步对象存储|相关组件
DAOS 分布式异步对象存储|控制平面
DAOS 分布式异步对象存储|数据平面
DAOS 分布式异步对象存储|网络传输和通信
DAOS 分布式异步对象存储|分层和服务
DAOS 分布式异步对象存储|Pool
DAOS 分布式异步对象存储|Container
Intel DAOS 存储解决方案简略梳理 - 知乎 (zhihu.com)
daos/README.md at master · daos-stack/daos · GitHub
##################################
/////////////////////////////////////////////////////////////////
Fault Detection & Isolation
DAOS servers are monitored within a DAOS system through a gossip-based protocol called SWIM1 that provides accurate, efficient, and scalable server fault detection.
Storage attached to each DAOS target is monitored through periodic local health assessment. Whenever a local storage I/O error is returned to the DAOS server, an internal health check procedure will be called automatically. This procedure makes an overall health assessment by analyzing the IO error code and device SMART/Health data. If the result is negative, the target will be marked as faulty, and further I/Os to this target will be rejected and re-routed.
Once detected, the faulty target or servers (effectively a set of targets) must be excluded from each pool membership. This process is triggered either manually by the administrator or automatically (see the next section for more information). Upon exclusion from the pool map, each target starts the collective rebuild process automatically to restore data redundancy. The rebuild process is designed to operate online while servers continue to process incoming I/O operations from applications.
Tools to monitor and manage rebuild are still under development.
//////////////////////////////////////////////////////////////////
Management Service
The Control Plane implements a management service as part of the DAOS Server, responsible for handling distributed operations across the DAOS System.
Some dmg commands will trigger MS requests to be issued to a daos_server process on a storage node running as the MS leader, this happens under the hood and the logic for the request steering is handled in the control API which is utilized by the dmg tool.
When necessary, requests will be forwarded to the data plane engine over dRPC channel and handled by the mgmt module.
MS RPC related code is contained in /src/control/server/mgmt_*.go files.
######################################
System Command Handling
System commands use fan-out and send unary RPCs to selected ranks across the system for actions stop, start and reformat.
Storage Command Handling
Storage related RPCs, whose handlers are defined in ctl_storage*.go delegate operations to backend providers encapsulated in the bdev and scm storage subsystem packages.
##################################
Single redundancy group based DTX Leader Election
In single redundancy group based DTX model, the leader selection is done for each object or dkey following these general guidelines:
// 在基于单冗余组的DTX模型中,按照以下一般准则为每个对象或dkey选择leader:
R1: When different replicated objects share the same redundancy group, the same leader should not be used for each object. 当不同的复制对象共享同一冗余组时,不应为每个对象使用相同的leader。
R2: When a replicated object with multiple DKEYs span multiple redundancy groups, the leaders in different redundancy groups should be on different servers. //当具有多个DKEY的复制对象跨越多个冗余组时,不同冗余组中的leader应位于不同的服务器上。
R3: Servers that fail frequently should be avoided in leader selection to avoid frequent leader migration.
//在leader选择中应避免频繁失败的服务器,以避免频繁的leader迁移。
R4: For EC object, the leader will be one of the parity nodes within current redundancy group.
//对于EC对象,leader将是当前冗余组中的奇偶校验节点之一。
##################################
Bootstrapping and DAOS System Membership
When starting a data-plane instance, we look at the superblock to determine whether the instance should be started as a MS (management service) replica. The daos_server.yml's access_points parameter is used (only during format) to determine whether an instance is to be a MS replica or not.
When the starting instance is identified as an MS replica, it performs bootstrap and starts. If the DAOS system has only one replica (as specified by access_points parameter), the host of the bootstrapped instance is now the MS leader. Whereas if there are multiple replicas, elections will happen in the background and eventually a leader will be elected.
When the starting instance is not identified as an MS replica, the instance's host calls Join on the control API client which triggers a gRPC request to the MS leader. The joining instance's control address is populated in the request.
The gRPC server running on the MS leader handles the Join request and allocates a DAOS system rank which is recorded in the MS membership (which is backed by the distributed system database). The rank is returned in the Join response and communicated to the data-plane (engine) over dRPC.
##################################
NVMe Threading Model
- Device Owner Xstream: In the case there is no direct 1:1 mapping of VOS XStream to NVMe SSD, the VOS xstream that first opens the SPDK blobstore will be named the 'Device Owner'. The Device Owner Xstream is responsible for maintaining and updating the blobstore health data, handling device state transitions, and also media error events. All non-owner xstreams will forward events to the device owner.
- Init Xstream: The first started VOS xstream is termed the 'Init Xstream'. The init xstream is responsible for initializing and finalizing the SPDK bdev, registering the SPDK hotplug poller, handling and periodically checking for new NVMe SSD hot remove and hotplug events, and handling all VMD LED device events.

Above is a diagram of the current NVMe threading model. The 'Device Owner' xstream is responsible for all faulty device and device reintegration callbacks, as well as updating device health data. The 'Init' xstream is responsible for registering the SPDK hotplug poller and maintaining the current device list of SPDK bdevs as well as evicted and unplugged devices. Any device metadata operations or media error events that do not occur on either of these two xstreams will be forwarded to the appropriate xstream using the SPDK event framework for lockless inter-thread communication. All xstreams will periodically poll for I/O statistics (if enabled in server config), but only the device owner xstream will poll for device events, making necessary state transitions, and update device health stats, and the init xstream will poll for any device removal or device hot plug events.
#######################################
Device Health Monitoring
The device owner xstream is responsible for maintaining anf updating all device health data and all media error events as apart of the device health monitoring feature. Device health data consists of raw SSD health stats queried via SPDK admin APIs and in-memory health data. The raw SSD health stats returned include useful and critical data to determine the current health of the device, such as temperature, power on duration, unsafe shutdowns, critical warnings, etc. The in-memory health data contains a subset of the raw SSD health stats, in addition to I/O error (read/write/unmap) and checksum error counters that are updated when a media error event occurs on a device and stored in-memory.
The DAOS data plane will monitor NVMe SSDs every 60 seconds, including updating the health stats with current values, checking current device states, and making any necessary blobstore/device state transitions. Once a FAULTY state transition has occurred, the monitoring period will be reduced to 10 seconds to allow for quicker transitions and finer-grained monitoring until the device is fully evicted.
Useful admin commands to query device health:
- dmg storage query (device-health | target-health) [used to query SSD health stats]
While monitoring this health data, an admin can now make the determination to manually evict a faulty device. This data will also be used to set the faulty device criteria for automatic SSD eviction (available in a future release).
Faulty Device Detection (SSD Eviction)
Faulty device detection and reaction can be referred to as NVMe SSD eviction. This involves all affected pool targets being marked as down and the rebuild of all affected pool targets being automatically triggered. A persistent device state is maintained in SMD and the device state is updated from NORMAL to FAULTY upon SSD eviction. The faulty device reaction will involve various SPDK cleanup, including all I/O channels released, SPDK allocations (termed 'blobs') closed, and the SPDK blobstore created on the NVMe SSD unloaded. Currently only manual SSD eviction is supported, and a future release will support automatic SSD eviction.
Useful admin commands to manually evict an NVMe SSD:
- dmg storage set nvme-faulty [used to manually set an NVMe SSD to FAULTY (ie evict the device)]
########################################
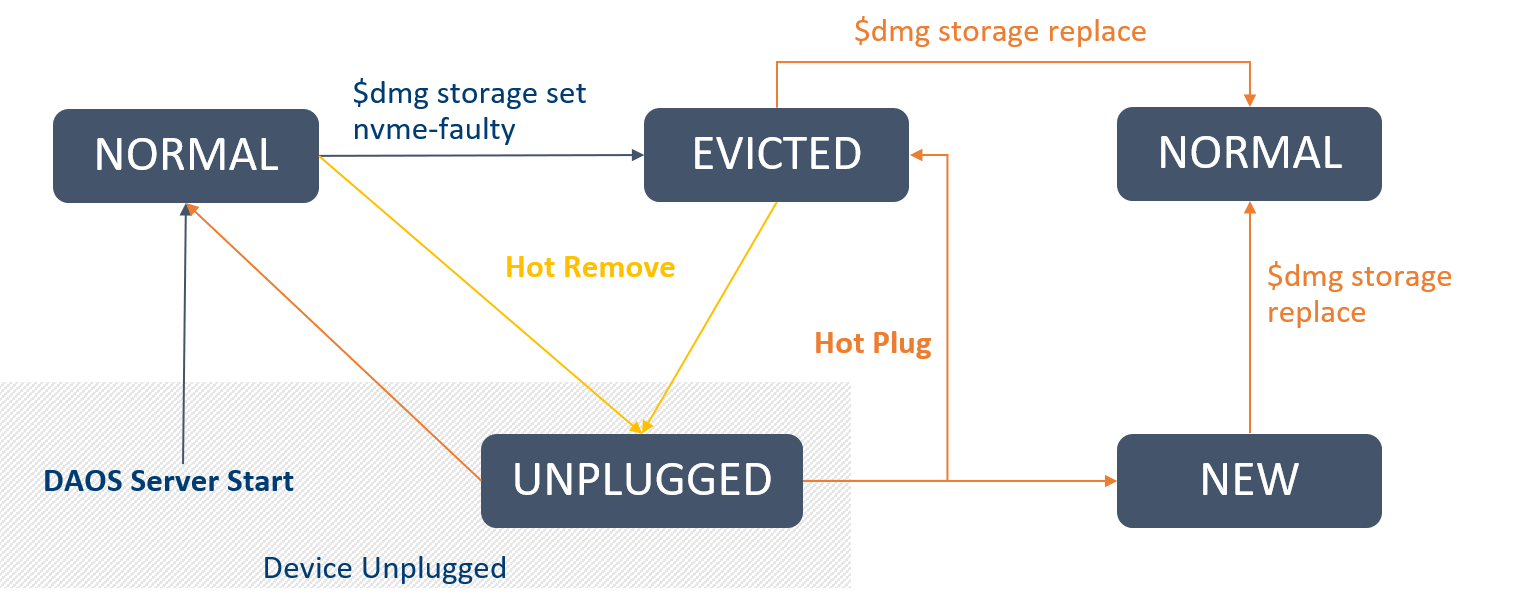
Device States
The device states that are returned from a device query by the admin are dependent on both the persistently stored device state in SMD, and the in-memory BIO device list.
- NORMAL: A fully functional device in use by DAOS (or in setup).
- EVICTED: A device has been manually evicted and is no longer in use by DAOS.
- UNPLUGGED: A device previously used by DAOS is unplugged.
- NEW: A new device is available for use by DAOS.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号