
Linux网络
[译] Linux 网络栈监控和调优:接收数据(2016)
译者序
本文翻译自 2016 年的一篇英文博客 Monitoring and Tuning the Linux Networking Stack: Receiving Data。如果能看懂英文,建议阅读原文,或者和本文对照看。
这篇文章写的是 “Linux networking stack”,这里的 ”stack“ 指的不仅仅是内核协议 栈,而是包括内核协议栈在内的、从数据包到达物理网卡到最终被用户态程序收起的整个路 径。所以文章有三方面,交织在一起,看起来非常累(但是很过瘾):
- 原理及代码实现:网络各层,包括驱动、硬中断、软中断、内核协议栈、socket 等等
- 监控:对代码中的重要计数进行监控,一般在
/proc或/sys下面有对应输出 - 调优:修改网络配置参数
本文的另一个特色是,几乎所有讨论的内核代码,都在相应的地方给出了 github 上的链接 ,具体到行。
网络栈非常复杂,原文太长又没有任何章节号,看起来非常累。因此本文翻译时添加了适当 的章节号,以期按图索骥。
2020 更新:
基于 Prometheus+Grafana 监控网络栈:Monitoring Network Stack。
以下是翻译。
太长不读(TL; DR)
本文介绍了 Linux 内核是如何收包(receive packets)的,包是怎样从网络栈到达用 户空间程序的,以及如何监控(monitoring)和调优(tuning)这一路径上的各个 网络栈组件。
这篇文章的姊妹篇 Monitoring and Tuning the Linux Networking Stack: Sending Data。
这篇文章的图文注释版 the Illustrated Guide to Monitoring and Tuning the Linux Networking Stack: Receiving Data。
想对 Linux 网络栈进行监控或调优,必须对它的行为(what exactly is happening)和原 理有深入的理解,而这是离不开读内核源码的。希望本文可以给那些正准备投身于此的人提 供一份参考。
特别鸣谢
特别感谢 Private Internet Access 的各位同 僚。公司雇佣我们做一些包括本文主题在内的网络研究,并非常慷慨地允许我们将研究成果 以文章的形式发表。
本文基于在 Private Internet Access 时的研 究成果,最开始以 5 篇连载 的形式出现。
- 译者序
- 太长不读(TL; DR)
- 1 网络栈监控和调优:常规建议
- 2 收包过程俯瞰
- 3 网络设备驱动
- 4 软中断(SoftIRQ)
- 5 Linux 网络设备子系统
- 6 RPS (Receive Packet Steering)
- 7 RFS (Receive Flow Steering)
- 8 aRFS (Hardware accelerated RFS)
- 9 从
netif_receive_skb进入协议栈 - 10
netif_receive_skb - 11 协议层注册
- 12 其他
- 13 总结
- 14 额外讨论和帮助
- 15 相关文章
1 网络栈监控和调优:常规建议
网络栈很复杂,没有一种适用于所有场景的通用方式。如果网络的性能和健康状况对你来说 非常重要,那你别无选择,只能投入大量的时间、精力和资源去深入理解系统的各个部分是 如何工作的。
理想情况下,你应该考虑在网络栈的各个层级测量丢包状况,这样就可以缩小范围,确定哪 个组件需要调优。
然而,这也是一些网络管理员开始走偏的地方:他们想当然地认为通过一波 sysctl 或 /proc 操作就可以解决问题,并且认为这些配置适用于所有场景。在某些场景下,可能确实 如此;但是,考虑到整个系统是如此细微而精巧地交织在一起的,如果想做有意义的监控和调优 ,就必须得在更深层次搞清系统是如何工作的。否则,你虽然可以使用默认配置,并在 相当长的时间内运行良好,但终会到某个时间点,你不得不(投时间、精力和资源研究这些 配置,然后)做优化。
本文中的一些示例配置仅为了方便理解(效果),并不作为任何特定配置或默认配置的建议 。在做任何配置改动之前,你应该有一个能够对系统进行监控的框架,以查看变更是否带来 预期的效果。
对远程连接上的机器进行网络变更是相当危险的,机器很可能失联。另外,不要在生产环境 直接调整这些配置;如果可能的话,在新机器上改配置,然后将机器灰度上线到生产。
2 收包过程俯瞰
本文将拿 Intel I350 网卡的 igb 驱动作为参考,网卡的 data sheet 这里可以下 载 PDF (警告:文件很大)。
从比较高的层次看,一个数据包从被网卡接收到进入 socket 接收队列的整个过程如下:
- 加载网卡驱动,初始化
- 包从外部网络进入网卡
- 网卡(通过 DMA)将包 copy 到内核内存中的 ring buffer
- 产生硬件中断,通知系统收到了一个包
- 驱动调用 NAPI,如果轮询(poll)还没开始,就开始轮询
ksoftirqd进程调用 NAPI 的poll函数从 ring buffer 收包(poll函数是网卡 驱动在初始化阶段注册的;每个 CPU 上都运行着一个ksoftirqd进程,在系统启动期 间就注册了)- ring buffer 里包对应的内存区域解除映射(unmapped)
- (通过 DMA 进入)内存的数据包以
skb的形式被送至更上层处理 - 如果 packet steering 功能打开,或者网卡有多队列,网卡收到的包会被分发到多个 CPU
- 包从队列进入协议层
- 协议层处理包
- 包从协议层进入相应 socket 的接收队列
接下来会详细介绍这个过程。
协议层分析我们将会关注 IP 和 UDP 层,其他协议层可参考这个过程。
3 网络设备驱动
本文基于 Linux 3.13。
准确地理解 Linux 内核的收包过程是一件非常有挑战性的事情。我们需要仔细研究网卡驱 动的工作原理,才能对网络栈的相应部分有更加清晰的理解。
本文将拿 ibg 驱动作为例子,它是常见的 Intel I350 网卡的驱动。先来看网卡 驱动是如何工作的。
3.1 初始化
驱动会使用 module_init 向内核注册一个初始化函数,当驱动被加载时,内核会调用这个函数。
这个初始化函数(igb_init_module)的代码见 drivers/net/ethernet/intel/igb/igb_main.c.
过程非常简单直接:
/**
* igb_init_module - Driver Registration Routine
*
* igb_init_module is the first routine called when the driver is
* loaded. All it does is register with the PCI subsystem.
**/
static int __init igb_init_module(void)
{
int ret;
pr_info("%s - version %s\n", igb_driver_string, igb_driver_version);
pr_info("%s\n", igb_copyright);
/* ... */
ret = pci_register_driver(&igb_driver);
return ret;
}
module_init(igb_init_module);
初始化的大部分工作在 pci_register_driver 里面完成,下面来细看。
PCI 初始化
Intel I350 网卡是 PCI express 设备。 PCI 设备通过 PCI Configuration Space 里面的寄存器识别自己。
当设备驱动编译时,MODULE_DEVICE_TABLE 宏(定义在 include/module.h) 会导出一个 PCI 设备 ID 列表(a table of PCI device IDs),驱动据此识别它可以 控制的设备,内核也会依据这个列表对不同设备加载相应驱动。
igb 驱动的设备表和 PCI 设备 ID 分别见: drivers/net/ethernet/intel/igb/igb_main.c 和drivers/net/ethernet/intel/igb/e1000_hw.h。
static DEFINE_PCI_DEVICE_TABLE(igb_pci_tbl) = {
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I354_BACKPLANE_1GBPS) },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I354_SGMII) },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I354_BACKPLANE_2_5GBPS) },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I211_COPPER), board_82575 },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I210_COPPER), board_82575 },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I210_FIBER), board_82575 },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I210_SERDES), board_82575 },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I210_SGMII), board_82575 },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I210_COPPER_FLASHLESS), board_82575 },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I210_SERDES_FLASHLESS), board_82575 },
/* ... */
};
MODULE_DEVICE_TABLE(pci, igb_pci_tbl);
前面提到,驱动初始化的时候会调用 pci_register_driver,这个函数会将该驱动的各 种回调方法注册到一个 struct pci_driver 变量,drivers/net/ethernet/intel/igb/igb_main.c:
static struct pci_driver igb_driver = {
.name = igb_driver_name,
.id_table = igb_pci_tbl,
.probe = igb_probe,
.remove = igb_remove,
/* ... */
};
3.2 网络设备初始化
通过 PCI ID 识别设备后,内核就会为它选择合适的驱动。每个 PCI 驱动注册了一个 probe() 方法,内核会对每个设备依次调用其驱动的 probe 方法,一旦找到一个合适的 驱动,就不会再为这个设备尝试其他驱动。
很多驱动都需要大量代码来使得设备 ready,具体做的事情各有差异。典型的过程:
- 启用 PCI 设备
- 请求(requesting)内存范围和 IO 端口
- 设置 DMA 掩码
- 注册设备驱动支持的 ethtool 方法(后面介绍)
- 注册所需的 watchdog(例如,e1000e 有一个检测设备是否僵死的 watchdog)
- 其他和具体设备相关的事情,例如一些 workaround,或者特定硬件的非常规处理
- 创建、初始化和注册一个
struct net_device_ops类型变量,这个变量包含了用于设 备相关的回调函数,例如打开设备、发送数据到网络、设置 MAC 地址等 - 创建、初始化和注册一个更高层的
struct net_device类型变量(一个变量就代表了 一个设备)
我们来简单看下 igb 驱动的 igb_probe 包含哪些过程。下面的代码来自 igb_probe,drivers/net/ethernet/intel/igb/igb_main.c:
err = pci_enable_device_mem(pdev);
/* ... */
err = dma_set_mask_and_coherent(&pdev->dev, DMA_BIT_MASK(64));
/* ... */
err = pci_request_selected_regions(pdev, pci_select_bars(pdev,
IORESOURCE_MEM),
igb_driver_name);
pci_enable_pcie_error_reporting(pdev);
pci_set_master(pdev);
pci_save_state(pdev);
更多 PCI 驱动信息
详细的 PCI 驱动讨论不在本文范围,如果想进一步了解,推荐如下材料: 分享, wiki, Linux Kernel Documentation: PCI。
3.3 网络设备启动
igb_probe 做了很多重要的设备初始化工作。除了 PCI 相关的,还有如下一些通用网络 功能和网络设备相关的工作:
- 注册
struct net_device_ops变量 - 注册 ethtool 相关的方法
- 从网卡获取默认 MAC 地址
- 设置
net_device特性标记
我们逐一看下这些过程,后面会用到。
3.3.1 struct net_device_ops
网络设备相关的操作函数都注册到这个类型的变量中。igb_main.c:
static const struct net_device_ops igb_netdev_ops = {
.ndo_open = igb_open,
.ndo_stop = igb_close,
.ndo_start_xmit = igb_xmit_frame,
.ndo_get_stats64 = igb_get_stats64,
.ndo_set_rx_mode = igb_set_rx_mode,
.ndo_set_mac_address = igb_set_mac,
.ndo_change_mtu = igb_change_mtu,
.ndo_do_ioctl = igb_ioctl,
/* ... */
这个变量会在 igb_probe()中赋给 struct net_device 中的 netdev_ops 字段:
static int igb_probe(struct pci_dev *pdev, const struct pci_device_id *ent)
{
...
netdev->netdev_ops = &igb_netdev_ops;
}
3.3.2 ethtool 函数注册
ethtool 是一个命令行工 具,可以查看和修改网络设备的一些配置,常用于收集网卡统计数据。在 Ubuntu 上,可以 通过 apt-get install ethtool 安装。
ethtool 通过 ioctl 和设备驱 动通信。内核实现了一个通用 ethtool 接口,网卡驱动实现这些接口,就可以被 ethtool 调用。当 ethtool 发起一个系统调用之后,内核会找到对应操作的回调函数 。回调实现了各种简单或复杂的函数,简单的如改变一个 flag 值,复杂的包括调整网卡硬 件如何运行。
相关实现见:igb_ethtool.c。
3.3.3 软中断(IRQ)
当一个数据帧通过 DMA 写到 RAM(内存)后,网卡是如何通知其他系统这个包可以被处理 了呢?
传统的方式是,网卡会产生一个硬件中断(IRQ),通知数据包到了。有三种常见的硬中断类型:
- MSI-X
- MSI
- legacy IRQ
稍后详细介绍到。
先来思考这样一个问题:如果有大量的数据包到达,就会产生大量的硬件中断。CPU 忙于处 理硬件中断的时候,可用于处理其他任务的时间就会减少。
NAPI(New API)是一种新的机制,可以减少产生的硬件中断的数量(但不能完全消除硬中断 )。
3.3.4 NAPI
NAPI
NAPI 接收数据包的方式和传统方式不同,它允许设备驱动注册一个 poll 方法,然后调 用这个方法完成收包。
NAPI 的使用方式:
- 驱动打开 NAPI 功能,默认处于未工作状态(没有在收包)
- 数据包到达,网卡通过 DMA 写到内存
- 网卡触发一个硬中断,中断处理函数开始执行
- 软中断(softirq,稍后介绍),唤醒 NAPI 子系统。这会触发在一个单独的线程里,调用驱动注册的
poll方法收包 - 驱动禁止网卡产生新的硬件中断。这样做是为了 NAPI 能够在收包的时候不会被新的中 断打扰
- 一旦没有包需要收了,NAPI 关闭,网卡的硬中断重新开启
- 转步骤 2
和传统方式相比,NAPI 一次中断会接收多个包,因此可以减少硬件中断的数量。
poll 方法是通过调用 netif_napi_add 注册到 NAPI 的,同时还可以指定权重 weight,大部分驱动都 hardcode 为 64。后面会进一步解释这个 weight 以及 hardcode 64。
通常来说,驱动在初始化的时候注册 NAPI poll 方法。
3.3.5 igb 驱动的 NAPI 初始化
igb 驱动的初始化过程是一个很长的调用链:
igb_probe->igb_sw_initigb_sw_init->igb_init_interrupt_schemeigb_init_interrupt_scheme->igb_alloc_q_vectorsigb_alloc_q_vectors->igb_alloc_q_vectorigb_alloc_q_vector->netif_napi_add
从较高的层面来看,这个调用过程会做以下事情:
- 如果支持
MSI-X,调用pci_enable_msix打开它 - 计算和初始化一些配置,包括网卡收发队列的数量
- 调用
igb_alloc_q_vector创建每个发送和接收队列 igb_alloc_q_vector会进一步调用netif_napi_add注册 poll 方法到 NAPI 变量
我们来看下 igb_alloc_q_vector 是如何注册 poll 方法和私有数据的: drivers/net/ethernet/intel/igb/igb_main.c:
static int igb_alloc_q_vector(struct igb_adapter *adapter,
int v_count, int v_idx,
int txr_count, int txr_idx,
int rxr_count, int rxr_idx)
{
/* ... */
/* allocate q_vector and rings */
q_vector = kzalloc(size, GFP_KERNEL);
if (!q_vector)
return -ENOMEM;
/* initialize NAPI */
netif_napi_add(adapter->netdev, &q_vector->napi, igb_poll, 64);
/* ... */
q_vector 是新分配的队列,igb_poll 是 poll 方法,当它收包的时候,会通过 这个接收队列找到关联的 NAPI 变量(q_vector->napi)。
这里很重要,后面我们介绍从驱动到网络协议栈的 flow(根据 IP 头信息做哈希,哈希相 同的属于同一个 flow)时会看到。
3.4 启用网卡 (Bring A Network Device Up)
回忆前面我们提到的 structure net_device_ops 变量,它包含网卡启用、发包、设置 mac 地址等回调函数(函数指针)。
当启用一个网卡时(例如,通过 ifconfig eth0 up),net_device_ops 的 ndo_open 方法会被调用。它通常会做以下事情:
- 分配 RX、TX 队列内存
- 打开 NAPI 功能
- 注册中断处理函数
- 打开(enable)硬中断
- 其他
igb 驱动中,这个方法对应的是 igb_open 函数。
3.4.1 准备从网络接收数据
今天的大部分网卡都使用 DMA 将数据直接写到内存,接下来操作系统可以直接从里 面读取。实现这一目的所使用的数据结构是 ring buffer(环形缓冲区)。
要实现这一功能,设备驱动必须和操作系统合作,预留(reserve)出一段内存来给网卡 使用。预留成功后,网卡知道了这块内存的地址,接下来收到的包就会放到这里,进而被 操作系统取走。
由于这块内存区域是有限的,如果数据包的速率非常快,单个 CPU 来不及取走这些包,新 来的包就会被丢弃。这时候,Receive Side Scaling(RSS,接收端扩展)或者多队列( multiqueue)一类的技术可能就会排上用场。
一些网卡有能力将接收到的包写到多个不同的内存区域,每个区域都是独立的接收队列。这 样操作系统就可以利用多个 CPU(硬件层面)并行处理收到的包。只有部分网卡支持这个功 能。
Intel I350 网卡支持多队列,我们可以在 igb 的驱动里看出来。igb 驱动启用的时候 ,最开始做的事情之一就是调用 igb_setup_all_rx_resources 函数。这个函数会对每个 RX 队列调用 igb_setup_rx_resources, 里面会管理 DMA 的内存.
如果对其原理感兴趣,可以进一步查看 Linux kernel’s DMA API HOWTO 。
RX 队列的数量和大小可以通过 ethtool 进行配置,调整这两个参数会对收包或者丢包产生可见影响。
网卡通过对 packet 头(例如源地址、目的地址、端口等)做哈希来决定将 packet 放到 哪个 RX 队列。只有很少的网卡支持调整哈希算法。如果支持的话,那你可以根据算法将特定 的 flow 发到特定的队列,甚至可以做到在硬件层面直接将某些包丢弃。
一些网卡支持调整 RX 队列的权重,你可以有意地将更多的流量发到指定的 queue。
后面会介绍如何对这些参数进行调优。
3.4.2 Enable NAPI
前面看到了驱动如何注册 NAPI poll 方法,但是,一般直到网卡被启用之后,NAPI 才被启用。
启用 NAPI 很简单,调用 napi_enable 函数就行,这个函数会设置 NAPI 变量(struct napi_struct)中一个表示是否启用的标志位。前面说到,NAPI 启用后并不是立即开始工 作(而是等硬中断触发)。
对于 igb,驱动初始化或者通过 ethtool 修改 queue 数量或大小的时候,会启用每个 q_vector 的 NAPI 变量。 drivers/net/ethernet/intel/igb/igb_main.c:
for (i = 0; i < adapter->num_q_vectors; i++)
napi_enable(&(adapter->q_vector[i]->napi));
3.4.3 注册中断处理函数
启用 NAPI 之后,下一步就是注册中断处理函数。设备有多种方式触发一个中断:
- MSI-X
- MSI
- legacy interrupts
设备驱动的实现也因此而异。
驱动必须判断出设备支持哪种中断方式,然后注册相应的中断处理函数,这些函数在中断发 生的时候会被执行。
一些驱动,例如 igb,会试图为每种中断类型注册一个中断处理函数,如果注册失败,就 尝试下一种(没测试过的)类型。
MSI-X 中断是比较推荐的方式,尤其是对于支持多队列的网卡。因为每个 RX 队列有独 立的MSI-X 中断,因此可以被不同的 CPU 处理(通过 irqbalance 方式,或者修改 /proc/irq/IRQ_NUMBER/smp_affinity)。我们后面会看到,处理中断的 CPU 也是随后处 理这个包的 CPU。这样的话,从网卡硬件中断的层面就可以设置让收到的包被不同的 CPU 处理。
如果不支持 MSI-X,那 MSI 相比于传统中断方式仍然有一些优势,驱动仍然会优先考虑它。 这个 wiki 介绍了更多 关于 MSI 和 MSI-X 的信息。
在 igb 驱动中,函数 igb_msix_ring, igb_intr_msi, igb_intr 分别是 MSI-X, MSI, 和传统中断方式的中断处理函数。
这段代码显式了驱动是如何尝试各种中断类型的, drivers/net/ethernet/intel/igb/igb_main.c:
static int igb_request_irq(struct igb_adapter *adapter)
{
struct net_device *netdev = adapter->netdev;
struct pci_dev *pdev = adapter->pdev;
int err = 0;
if (adapter->msix_entries) {
err = igb_request_msix(adapter);
if (!err)
goto request_done;
/* fall back to MSI */
/* ... */
}
/* ... */
if (adapter->flags & IGB_FLAG_HAS_MSI) {
err = request_irq(pdev->irq, igb_intr_msi, 0,
netdev->name, adapter);
if (!err)
goto request_done;
/* fall back to legacy interrupts */
/* ... */
}
err = request_irq(pdev->irq, igb_intr, IRQF_SHARED,
netdev->name, adapter);
if (err)
dev_err(&pdev->dev, "Error %d getting interrupt\n", err);
request_done:
return err;
}
这就是 igb 驱动注册中断处理函数的过程,这个函数在一个包到达网卡触发一个硬 件中断时就会被执行。
3.4.4 启用硬中断(enable interrupts),等待数据包进来
到这里,几乎所有的准备工作都就绪了,唯一剩下的就是打开硬中断, 等待数据包进来。
打开硬中断的方式因硬件而异,igb 驱动是在 __igb_open 里调用辅助函数 igb_irq_enable 完成的。
中断通过写寄存器的方式打开:
static void igb_irq_enable(struct igb_adapter *adapter)
{
/* ... */
wr32(E1000_IMS, IMS_ENABLE_MASK | E1000_IMS_DRSTA);
wr32(E1000_IAM, IMS_ENABLE_MASK | E1000_IMS_DRSTA);
/* ... */
}
现在,网卡已经启用了。驱动可能还会做一些额外的事情,例如启动定时器,工作队列( work queue),或者其他硬件相关的设置。这些工作做完后,网卡就可以收包了。
接下来看一下如何监控和调优网卡。
3.5 网卡监控
监控网络设备有几种不同的方式,每种方式的监控粒度(granularity)和复杂度不同。我 们先从最粗的粒度开始,逐步细化。
3.5.1 Using ethtool -S
ethtool -S 可以查看网卡统计信息(例如丢弃的包数量):
$ sudo ethtool -S eth0
NIC statistics:
rx_packets: 597028087
tx_packets: 5924278060
rx_bytes: 112643393747
tx_bytes: 990080156714
rx_broadcast: 96
tx_broadcast: 116
rx_multicast: 20294528
....
监控这些数据比较困难。因为用命令行获取很容易,但是以上字段并没有一个统一的标准。 不同的驱动,甚至同一驱动的不同版本可能字段都会有差异。
你可以先粗略的查看 “drop”, “buffer”, “miss” 等字样。然后,在驱动的源码里找到对应的 更新这些字段的地方,这可能是在软件层面更新的,也有可能是在硬件层面通过寄存器更新 的。如果是通过硬件寄存器的方式,你就得查看网卡的 data sheet(说明书),搞清楚这个 寄存器代表什么。ethtoool 给出的这些字段名,有一些是有误导性的(misleading)。
3.5.2 Using sysfs
sysfs 也提供了统计信息,但相比于网卡层的统计,要更上层一些。
例如,获取 eth0 的接收端 drop 的数量:
$ cat /sys/class/net/eth0/statistics/rx_dropped
2
不同类型的统计分别位于 /sys/class/net/<NIC>/statistics/ 下面的不同文件,包括 collisions, rx_dropped, rx_errors, rx_missed_errors 等等。
不幸的是,每种类型代表什么意思,是由驱动来决定的,因此也是由驱动决定何时以及在哪 里更新这些计数的。你可能会发现一些驱动将一些特定类型的错误归类为 drop,而另外 一些驱动可能将它们归类为 miss。
这些值至关重要,因此你需要查看对应的网卡驱动,搞清楚它们真正代表什么。
3.5.3 Using /proc/net/dev
/proc/net/dev 提供了更高一层的网卡统计。
$ cat /proc/net/dev
Inter-| Receive | Transmit
face |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressed
eth0: 110346752214 597737500 0 2 0 0 0 20963860 990024805984 6066582604 0 0 0 0 0 0
lo: 428349463836 1579868535 0 0 0 0 0 0 428349463836 1579868535 0 0 0 0 0 0
这个文件里显式的统计只是 sysfs 里面的一个子集,但适合作为一个常规的统计参考。
前面的警告(caveat)也适用于此:如果这些数据对你非常重要,那你必须得查看内核源码 、驱动源码和驱动手册,搞清楚每个字段真正代表什么意思,计数是如何以及何时被更新的。
3.6 网卡调优
3.6.1 查看 RX 队列数量
如果网卡及其驱动支持 RSS/多队列,那你可以会调整 RX queue(也叫 RX channel)的数量。 这可以用 ethtool 完成。
查看 RX queue 数量:
$ sudo ethtool -l eth0
Channel parameters for eth0:
Pre-set maximums:
RX: 0
TX: 0
Other: 0
Combined: 8
Current hardware settings:
RX: 0
TX: 0
Other: 0
Combined: 4
这里可以看到允许的最大值(网卡及驱动限制),以及当前设置的值。
注意:不是所有网卡驱动都支持这个操作。如果你的网卡不支持,会看到如下类似的错误:
$ sudo ethtool -l eth0
Channel parameters for eth0:
Cannot get device channel parameters
: Operation not supported
这意味着驱动没有实现 ethtool 的 get_channels 方法。可能的原因包括:该网卡不支 持调整 RX queue 数量,不支持 RSS/multiqueue,或者驱动没有更新来支持此功能。
3.6.2 调整 RX queues
ethtool -L 可以修改 RX queue 数量。
注意:一些网卡和驱动只支持 combined queue,这种模式下,RX queue 和 TX queue 是一 对一绑定的,上面的例子我们看到的就是这种。
设置 combined 类型网卡的收发队列为 8 个:
$ sudo ethtool -L eth0 combined 8
如果你的网卡支持独立的 RX 和 TX 队列数量,那你可以只修改 RX queue 数量:
$ sudo ethtool -L eth0 rx 8
注意:对于大部分驱动,修改以上配置会使网卡先 down 再 up,因此会造成丢包。请酌情 使用。
3.6.3 调整 RX queue 的大小
一些网卡和驱动也支持修改 RX queue 的大小。底层是如何工作的,随硬件而异,但幸运的是 ,ethtool 提供了一个通用的接口来做这件事情。增加 RX queue 的大小可以在流量很大的时 候缓解丢包问题,但是,只调整这个还不够,软件层面仍然可能会丢包,因此还需要其他的 一些调优才能彻底的缓解或解决丢包问题。
ethtool -g 可以查看 queue 的大小。
$ sudo ethtool -g eth0
Ring parameters for eth0:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 512
RX Mini: 0
RX Jumbo: 0
TX: 512
以上显式网卡支持最多 4096 个接收和发送 descriptor(描述符,简单理解,存放的是指 向包的指针),但是现在只用到了 512 个。
用 ethtool -G 修改 queue 大小:
$ sudo ethtool -G eth0 rx 4096
注意:对于大部分驱动,修改以上配置会使网卡先 down 再 up,因此会造成丢包。请酌情 使用。
3.6.4 调整 RX queue 的权重(weight)
一些网卡支持给不同的 queue 设置不同的权重,以此分发不同数量的网卡包到不同的队列。
如果你的网卡支持以下功能,那你可以使用:
- 网卡支持 flow indirection(flow 重定向,flow 是什么前面提到过)
- 网卡驱动实现了
get_rxfh_indir_size和get_rxfh_indir方法 - 使用的 ethtool 版本足够新,支持
-x和-X参数来设置 indirection table
ethtool -x 检查 flow indirection 设置:
$ sudo ethtool -x eth0
RX flow hash indirection table for eth3 with 2 RX ring(s):
0: 0 1 0 1 0 1 0 1
8: 0 1 0 1 0 1 0 1
16: 0 1 0 1 0 1 0 1
24: 0 1 0 1 0 1 0 1
第一列是哈希值索引,是该行的第一个哈希值;冒号后面的是每个哈希值对于的 queue,例 如,第一行分别是哈希值 0,1,2,3,4,5,6,7,对应的 packet 应该分别被放到 RX queue 0,1,0,1,0,1,0,1。
例子:在前两个 RX queue 之间均匀的分发(接收到的包):
$ sudo ethtool -X eth0 equal 2
例子:用 ethtool -X 设置自定义权重:
$ sudo ethtool -X eth0 weight 6 2
以上命令分别给 rx queue 0 和 rx queue 1 不同的权重:6 和 2,因此 queue 0 接收到的数量更 多。注意 queue 一般是和 CPU 绑定的,因此这也意味着相应的 CPU 也会花更多的时间片在收包 上。
一些网卡还支持修改计算 hash 时使用哪些字段。
3.6.5 调整 RX 哈希字段 for network flows
可以用 ethtool 调整 RSS 计算哈希时所使用的字段。
例子:查看 UDP RX flow 哈希所使用的字段:
$ sudo ethtool -n eth0 rx-flow-hash udp4
UDP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA
可以看到只用到了源 IP(SA:Source Address)和目的 IP。
我们接下来修改一下,加入源端口和目的端口:
$ sudo ethtool -N eth0 rx-flow-hash udp4 sdfn
sdfn 的具体含义解释起来有点麻烦,请查看 ethtool 的帮助(man page)。
调整 hash 所用字段是有用的,而 ntuple 过滤对于更加细粒度的 flow control 更加有用。
3.6.6 ntuple filtering for steering network flows
一些网卡支持 “ntuple filtering” 特性。该特性允许用户(通过 ethtool )指定一些参数来 在硬件上过滤收到的包,然后将其直接放到特定的 RX queue。例如,用户可以指定到特定目 端口的 TCP 包放到 RX queue 1。
Intel 的网卡上这个特性叫 Intel Ethernet Flow Director,其他厂商可能也有他们的名字 ,这些都是出于市场宣传原因,底层原理是类似的。
我们后面会看到,ntuple filtering 是一个叫 Accelerated Receive Flow Steering (aRFS) 功能的核心部分之一,后者使得 ntuple filtering 的使用更加方便。
这个特性适用的场景:最大化数据本地性(data locality),以增加 CPU 处理网络数据时的 缓存命中率。例如,考虑运行在 80 口的 web 服务器:
- webserver 进程运行在 80 口,并绑定到 CPU 2
- 和某个 RX queue 关联的硬中断绑定到 CPU 2
- 目的端口是 80 的 TCP 流量通过 ntuple filtering 绑定到 CPU 2
- 接下来所有到 80 口的流量,从数据包进来到数据到达用户程序的整个过程,都由 CPU 2 处理
- 仔细监控系统的缓存命中率、网络栈的延迟等信息,以验证以上配置是否生效
检查 ntuple filtering 特性是否打开:
$ sudo ethtool -k eth0
Offload parameters for eth0:
...
ntuple-filters: off
receive-hashing: on
可以看到,上面的 ntuple 是关闭的。
打开:
$ sudo ethtool -K eth0 ntuple on
打开 ntuple filtering 功能,并确认打开之后,可以用 ethtool -u 查看当前的 ntuple rules:
$ sudo ethtool -u eth0
40 RX rings available
Total 0 rules
可以看到当前没有 rules。
我们来加一条:目的端口是 80 的放到 RX queue 2:
$ sudo ethtool -U eth0 flow-type tcp4 dst-port 80 action 2
也可以用 ntuple filtering 在硬件层面直接 drop 某些 flow 的包。当特定 IP 过来的流 量太大时,这种功能可能会派上用场。更多关于 ntuple 的信息,参考 ethtool man page。
ethtool -S <DEVICE> 的输出统计里,Intel 的网卡有 fdir_match 和 fdir_miss 两项, 是和 ntuple filtering 相关的。关于具体的、详细的统计计数,需要查看相应网卡的设备驱 动和 data sheet。
4 软中断(SoftIRQ)
在进一步深入网络栈之前,我们先开个小差,看下内核里一个叫 SoftIRQ 的东西。
4.1 软中断是什么
内核的软中断系统是一种在硬中断处理上下文(驱动中)之外执行代码的机制。 硬中断处理函数(handler)执行时,会屏蔽部分或全部(新的)硬中断。中断被屏蔽的时间 越长,丢失事件的可能性也就越大。所以,所有耗时的操作都应该从硬中断处理逻辑中剥 离出来,硬中断因此能尽可能快地执行,然后再重新打开硬中断。
内核中也有其他机制将耗时操作转移出去,不过对于网络栈,我们接下来只看软中断这种方式。
可以把软中断系统想象成一系列内核线程(每个 CPU 一个),这些线程执行针对不同 事件注册的处理函数(handler)。如果用过 top 命令,可能会注意到 ksoftirqd/0 这个内核线程,其表示这个软中断线程跑在 CPU 0 上。
内核子系统(比如网络)能通过 open_softirq() 注册软中断处理函数。接下来会看到 网络系统是如何注册它的处理函数的。
现在先来看一下软中断是如何工作的。
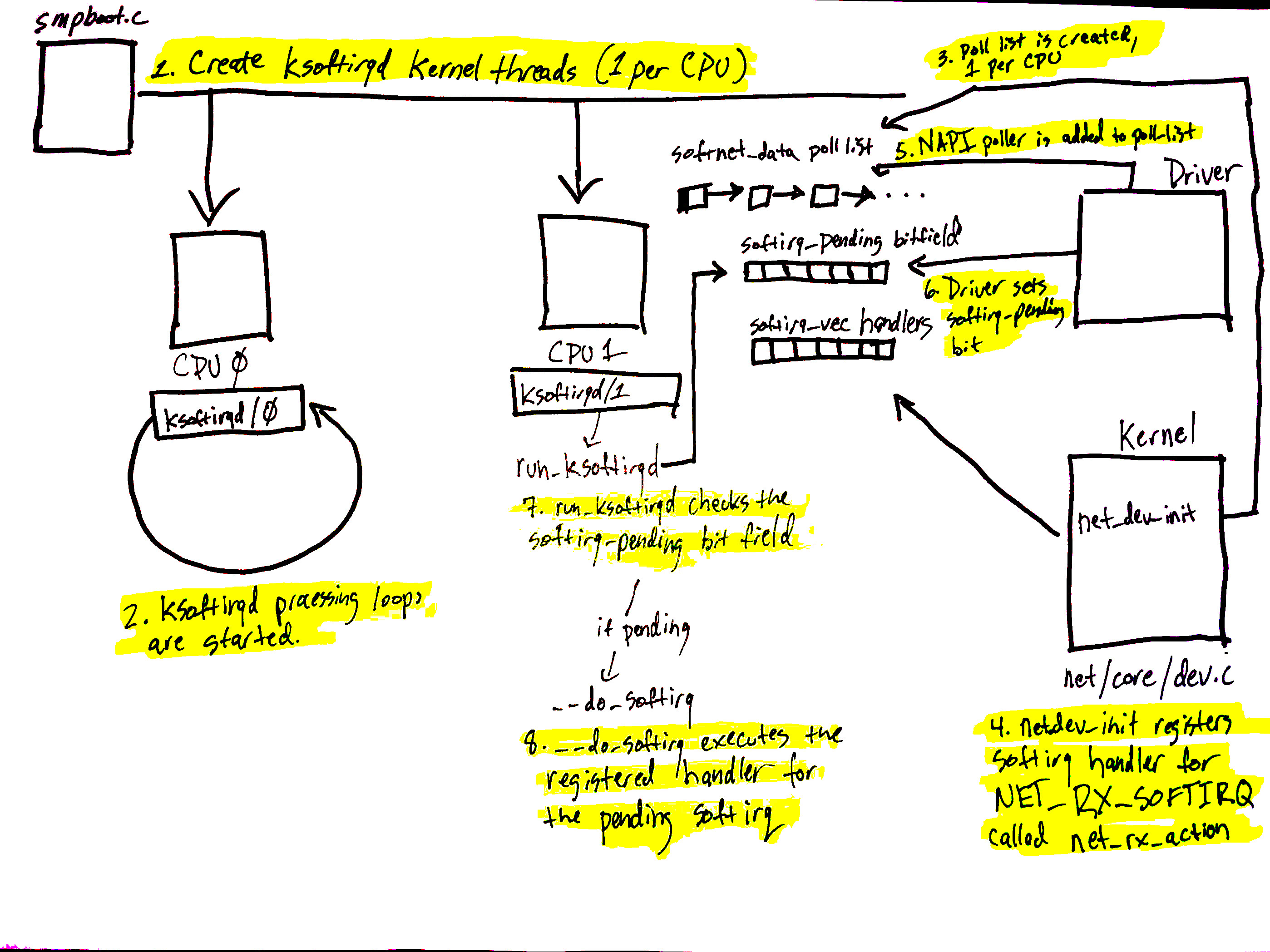
4.2 ksoftirqd
软中断对分担硬中断的工作量至关重要,因此软中断线程在内核启动的很早阶段就 spawn 出来了。
kernel/softirq.c 展示了 ksoftirqd 系统是如何初始化的:
static struct smp_hotplug_thread softirq_threads = {
.store = &ksoftirqd,
.thread_should_run = ksoftirqd_should_run,
.thread_fn = run_ksoftirqd,
.thread_comm = "ksoftirqd/%u",
};
static __init int spawn_ksoftirqd(void)
{
register_cpu_notifier(&cpu_nfb);
BUG_ON(smpboot_register_percpu_thread(&softirq_threads));
return 0;
}
early_initcall(spawn_ksoftirqd);
看到注册了两个回调函数: ksoftirqd_should_run 和 run_ksoftirqd。这两个函数都会从 kernel/smpboot.c 里调用,作为事件处理循环的一部分。
kernel/smpboot.c 里面的代码首先调用 ksoftirqd_should_run 判断是否有 pending 的软 中断,如果有,就执行 run_ksoftirqd,后者做一些 bookeeping 工作,然后调用 __do_softirq。
4.3 __do_softirq
__do_softirq 做的几件事情:
- 判断哪个 softirq 被 pending
- 计算 softirq 时间,用于统计
- 更新 softirq 执行相关的统计数据
- 执行 pending softirq 的处理函数
查看 CPU 利用率时,si 字段对应的就是 softirq,度量(从硬中断转移过来的)软 中断的 CPU 使用量。
4.4 监控
软中断的信息可以从 /proc/softirqs 读取:
$ cat /proc/softirqs
CPU0 CPU1 CPU2 CPU3
HI: 0 0 0 0
TIMER: 2831512516 1337085411 1103326083 1423923272
NET_TX: 15774435 779806 733217 749512
NET_RX: 1671622615 1257853535 2088429526 2674732223
BLOCK: 1800253852 1466177 1791366 634534
BLOCK_IOPOLL: 0 0 0 0
TASKLET: 25 0 0 0
SCHED: 2642378225 1711756029 629040543 682215771
HRTIMER: 2547911 2046898 1558136 1521176
RCU: 2056528783 4231862865 3545088730 844379888
监控这些数据可以得到软中断的执行频率信息。
例如,NET_RX 一行显示的是软中断在 CPU 间的分布。如果分布非常不均匀,那某一列的 值就会远大于其他列,这预示着下面要介绍的 Receive Packet Steering / Receive Flow Steering 可能会派上用场。但也要注意:不要太相信这个数值,NET_RX 太高并不一定都 是网卡触发的,下面会看到其他地方也有可能触发之。
调整其他网络配置时,可以留意下这个指标的变动。
现在,让我们进入网络栈部分,跟踪一个包是如何被接收的。
5 Linux 网络设备子系统
我们已经知道了网络驱动和软中断是如何工作的,接下来看 Linux 网络设备子系统是如何 初始化的。然后我们就可以从一个包到达网卡开始跟踪它的整个路径。
5.1 网络设备子系统的初始化
网络设备(netdev)的初始化在 net_dev_init,里面有些东西很有意思。
struct softnet_data 变量初始化
net_dev_init 为每个 CPU 创建一个 struct softnet_data 变量。这些变量包含一些 指向重要信息的指针:
- 需要注册到这个 CPU 的 NAPI 变量列表
- 数据处理 backlog
- 处理权重
- receive offload 变量列表
- receive packet steering 设置
接下来随着逐步进入网络栈,我们会一一查看这些功能。
SoftIRQ Handler 初始化
net_dev_init 分别为接收和发送数据注册了一个软中断处理函数。
static int __init net_dev_init(void)
{
/* ... */
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
/* ... */
}
后面会看到驱动的中断处理函数是如何触发 net_rx_action 这个为 NET_RX_SOFTIRQ 软中断注册的处理函数的。
5.2 数据来了
终于,网络数据来了!
如果 RX 队列有足够的描述符(descriptors),包会通过 DMA 写到 RAM。设备然后发 起对应于它的中断(或者在 MSI-X 的场景,中断和包达到的 RX 队列绑定)。
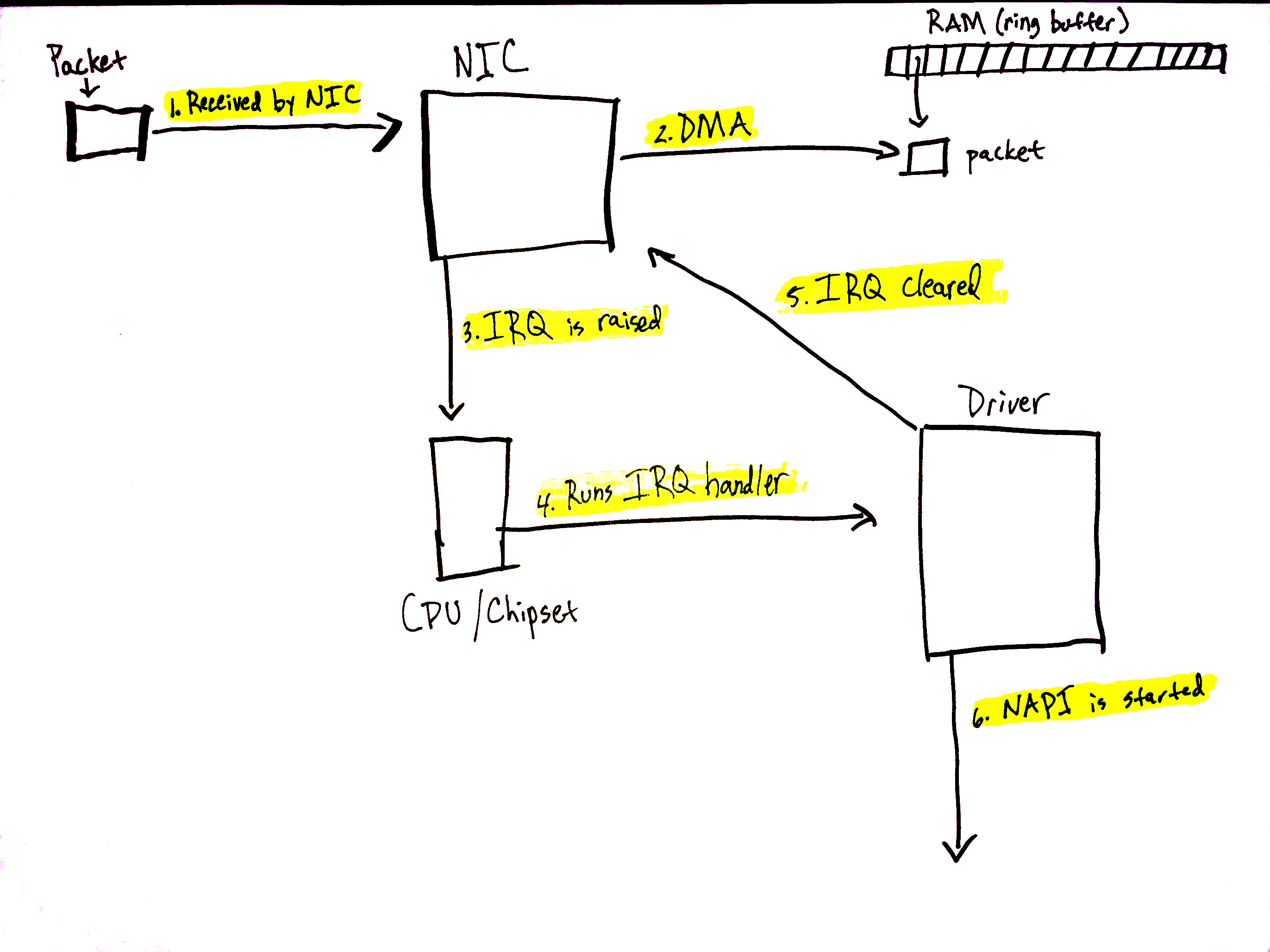
5.2.1 中断处理函数
一般来说,中断处理函数应该将尽可能多的处理逻辑移出(到软中断),这至关重要,因为 发起一个中断后,其他的中断就会被屏蔽。
我们来看一下 MSI-X 中断处理函数的代码,它展示了中断处理函数是如何尽量简单的。
static irqreturn_t igb_msix_ring(int irq, void *data)
{
struct igb_q_vector *q_vector = data;
/* Write the ITR value calculated from the previous interrupt. */
igb_write_itr(q_vector);
napi_schedule(&q_vector->napi);
return IRQ_HANDLED;
}
这个中断处理函数非常简短,只做了 2 个很快的操作就返回了。
首先,它调用 igb_write_itr 更新一个硬件寄存器。对这个例子,这个寄存器是记录硬件 中断频率的。
这个寄存器和一个叫 “Interrupt Throttling”(也叫 “Interrupt Coalescing”)的硬件 特性相关,这个特性可以平滑传送到 CPU 的中断数量。我们接下来会看到,ethtool 是 怎么样提供了一个机制用于调整 IRQ 触发频率的。
第二,触发 napi_schedule,如果 NAPI 的处理循环还没开始的话,这会唤醒它。注意, 这个处理循环是在软中断中执行的,而不是硬中断。
这段代码展示了硬中断尽量简短为何如此重要;为我们接下来理解多核 CPU 的接收逻辑很有 帮助。
5.2.2 NAPI 和 napi_schedule
接下来看从硬件中断中调用的 napi_schedule 是如何工作的。
注意,NAPI 存在的意义是无需硬件中断通知就可以接收网络数据。前面提到, NAPI 的轮询循环(poll loop)是受硬件中断触发而跑起来的。换句话说,NAPI 功能启用了 ,但是默认是没有工作的,直到第一个包到达的时候,网卡触发的一个硬件将它唤醒。后面 会看到,也还有其他的情况,NAPI 功能也会被关闭,直到下一个硬中断再次将它唤起。
napi_schedule 只是一个简单的封装,内层调用 __napi_schedule。 net/core/dev.c:
/**
* __napi_schedule - schedule for receive
* @n: entry to schedule
*
* The entry's receive function will be scheduled to run
*/
void __napi_schedule(struct napi_struct *n)
{
unsigned long flags;
local_irq_save(flags);
____napi_schedule(&__get_cpu_var(softnet_data), n);
local_irq_restore(flags);
}
EXPORT_SYMBOL(__napi_schedule);
__get_cpu_var 用于获取属于这个 CPU 的 structure softnet_data 变量。
____napi_schedule, net/core/dev.c:
/* Called with irq disabled */
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
这段代码了做了两个重要的事情:
- 将(从驱动的中断函数中传来的)
napi_struct变量,添加到 poll list,后者 attach 到这个 CPU 上的softnet_data __raise_softirq_irqoff触发一个NET_RX_SOFTIRQ类型软中断。这会触发执行net_rx_action(如果没有正在执行),后者是网络设备初始化的时候注册的
接下来会看到,软中断处理函数 net_rx_action 会调用 NAPI 的 poll 函数来收包。
5.2.3 关于 CPU 和网络数据处理的一点笔记
注意到目前为止,我们从硬中断处理函数中转移到软中断处理函数的逻辑,都是使用的本 CPU 变量。
驱动的硬中断处理函数做的事情很少,但软中断将会在和硬中断相同的 CPU 上执行。这就 是为什么给每个 CPU 一个特定的硬中断非常重要:这个 CPU 不仅处理这个硬中断,而且通 过 NAPI 处理接下来的软中断来收包。
后面我们会看到,Receive Packet Steering 可以将软中断分给其他 CPU。
5.2.4 监控网络数据到达
硬中断请求
注意:由于某些驱动在 NAPI 运行时会关闭硬中断,因此只监控硬中断无法得到网络处理健 康状况的全景试图,硬中断监控只是整个监控方案的重要组成部分。
读取硬中断统计:
$ cat /proc/interrupts
CPU0 CPU1 CPU2 CPU3
0: 46 0 0 0 IR-IO-APIC-edge timer
1: 3 0 0 0 IR-IO-APIC-edge i8042
30: 3361234770 0 0 0 IR-IO-APIC-fasteoi aacraid
64: 0 0 0 0 DMAR_MSI-edge dmar0
65: 1 0 0 0 IR-PCI-MSI-edge eth0
66: 863649703 0 0 0 IR-PCI-MSI-edge eth0-TxRx-0
67: 986285573 0 0 0 IR-PCI-MSI-edge eth0-TxRx-1
68: 45 0 0 0 IR-PCI-MSI-edge eth0-TxRx-2
69: 394 0 0 0 IR-PCI-MSI-edge eth0-TxRx-3
NMI: 9729927 4008190 3068645 3375402 Non-maskable interrupts
LOC: 2913290785 1585321306 1495872829 1803524526 Local timer interrupts
可以看到有多少包进来、硬件中断频率,RX 队列被哪个 CPU 处理等信息。这里只能看到硬中 断数量,不能看出实际多少数据被接收或处理,因为一些驱动在 NAPI 收包时会关闭硬中断。 进一步,使用 Interrupt Coalescing 时也会影响这个统计。监控这个指标能帮你判断出你设 置的 Interrupt Coalescing 是不是在工作。
为了使监控更加完整,需要同时监控 /proc/softirqs (前面提到)和 /proc。
5.2.5 数据接收调优
中断合并(Interrupt coalescing)
中断合并会将多个中断事件放到一起,累积到一定阈值后才向 CPU 发起中断请求。
这可以防止中断风暴,提升吞吐,降低 CPU 使用量,但延迟也变大;中断数量过多则相反。
历史上,早期的 igb、e1000 版本,以及其他的都包含一个叫 InterruptThrottleRate 参数, 最近的版本已经被 ethtool 可配置的参数取代。
$ sudo ethtool -c eth0
Coalesce parameters for eth0:
Adaptive RX: off TX: off
stats-block-usecs: 0
sample-interval: 0
pkt-rate-low: 0
pkt-rate-high: 0
...
ethtool 提供了用于中断合并相关的通用接口。但切记,不是所有的设备都支持完整的配 置。你需要查看驱动文档或代码来确定哪些支持,哪些不支持。ethtool 的文档说:“ 驱动没有实现的接口将会被静默忽略”。
某些驱动支持一个有趣的特性:“自适应 RX/TX 硬中断合并”。这个特性一般是在硬件实现的 。驱动通常需要做一些额外的工作来告诉网卡需要打开这个特性(前面的 igb 驱动代码里有 涉及)。
自适应 RX/TX 硬中断合并带来的效果是:带宽比较低时降低延迟,带宽比较高时提升吞吐。
用 ethtool -C 打开自适应 RX IRQ 合并:
$ sudo ethtool -C eth0 adaptive-rx on
还可以用 ethtool -C 更改其他配置。常用的包括:
rx-usecs: How many usecs to delay an RX interrupt after a packet arrives.rx-frames: Maximum number of data frames to receive before an RX interrupt.rx-usecs-irq: How many usecs to delay an RX interrupt while an interrupt is being serviced by the host.rx-frames-irq: Maximum number of data frames to receive before an RX interrupt is generated while the system is servicing an interrupt.
请注意你的硬件可能只支持以上列表的一个子集,具体请参考相应的驱动说明或源码。
不幸的是,通常并没有一个很好的文档来说明这些选项,最全的文档很可能是头文件。每个选项的解释见 include/uapi/linux/ethtool.h 。
注意:虽然硬中断合并看起来是个不错的优化项,但需要网络栈的其他一些 部分做针对性调整。只合并硬中断很可能并不会带来多少收益。
调整硬中断亲和性(IRQ affinities)
If your NIC supports RSS / multiqueue or if you are attempting to optimize for data locality, you may wish to use a specific set of CPUs for handling interrupts generated by your NIC.
Setting specific CPUs allows you to segment which CPUs will be used for processing which IRQs. These changes may affect how upper layers operate, as we’ve seen for the networking stack.
If you do decide to adjust your IRQ affinities, you should first check if you running the irqbalance daemon. This daemon tries to automatically balance IRQs to CPUs and it may overwrite your settings. If you are running irqbalance, you should either disable irqbalance or use the –banirq in conjunction with IRQBALANCE_BANNED_CPUS to let irqbalance know that it shouldn’t touch a set of IRQs and CPUs that you want to assign yourself.
Next, you should check the file /proc/interrupts for a list of the IRQ numbers for each network RX queue for your NIC.
Finally, you can adjust the which CPUs each of those IRQs will be handled by modifying /proc/irq/IRQ_NUMBER/smp_affinity for each IRQ number.
You simply write a hexadecimal bitmask to this file to instruct the kernel which CPUs it should use for handling the IRQ.
Example: Set the IRQ affinity for IRQ 8 to CPU 0
$ sudo bash -c 'echo 1 > /proc/irq/8/smp_affinity'
5.3 网络数据处理:开始
一旦软中断代码判断出有 softirq 处于 pending 状态,就会开始处理,执行 net_rx_action,网络数据处理就此开始。
我们来看一下 net_rx_action 的循环部分,理解它是如何工作的。哪个部分可以调优, 哪个可以监控。
5.3.1 net_rx_action 处理循环
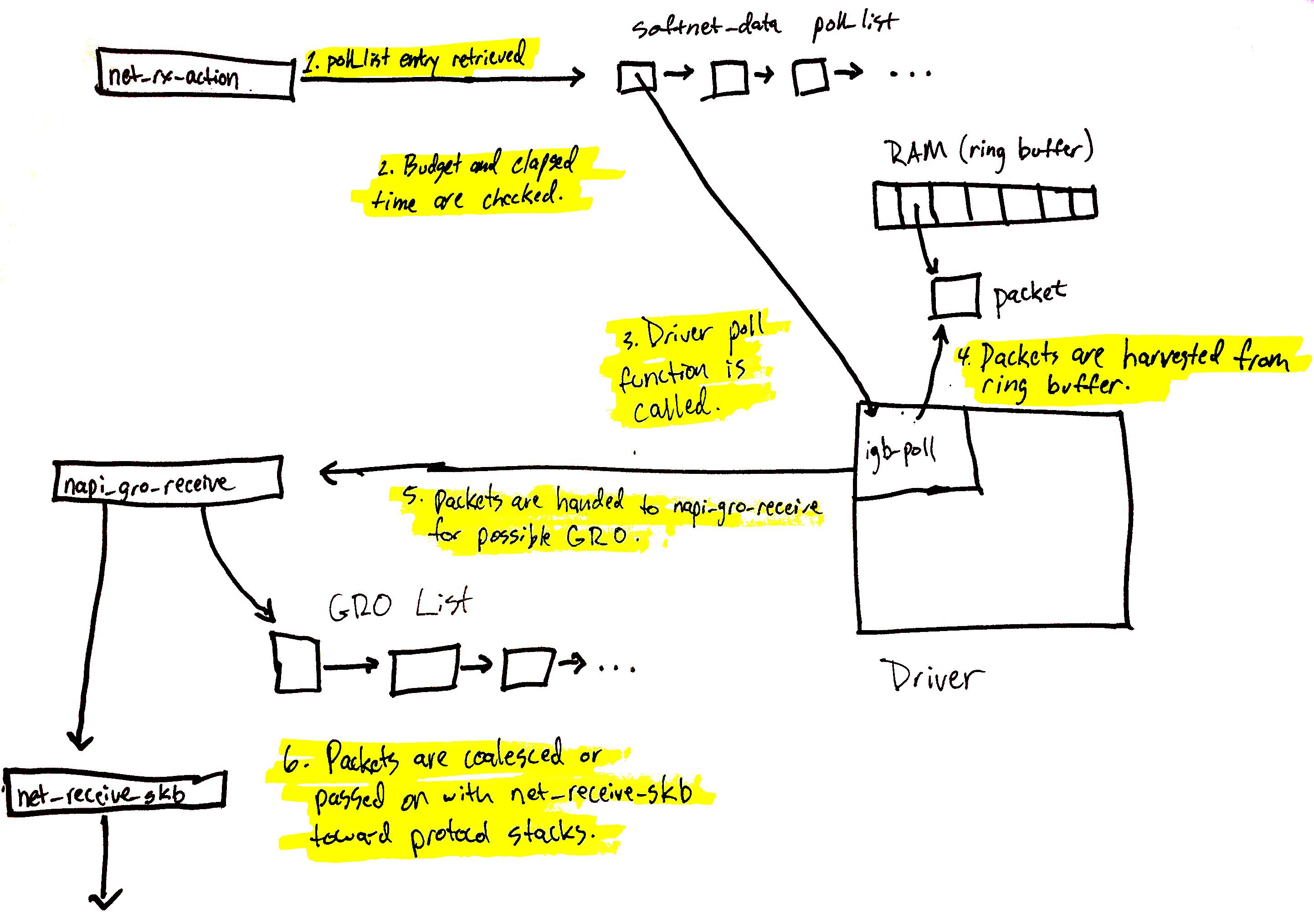
net_rx_action 从包所在的内存开始处理,包是被设备通过 DMA 直接送到内存的。 函数遍历本 CPU 队列的 NAPI 变量列表,依次出队并操作之。处理逻辑考虑任务量(work )和执行时间两个因素:
- 跟踪记录工作量预算(work budget),预算可以调整
- 记录消耗的时间
while (!list_empty(&sd->poll_list)) {
struct napi_struct *n;
int work, weight;
/* If softirq window is exhausted then punt.
* Allow this to run for 2 jiffies since which will allow
* an average latency of 1.5/HZ.
*/
if (unlikely(budget <= 0 || time_after_eq(jiffies, time_limit)))
goto softnet_break;
这里可以看到内核是如何防止处理数据包过程霸占整个 CPU 的,其中 budget 是该 CPU 的 所有 NAPI 变量的总预算。这也是多队列网卡应该精心调整 IRQ Affinity 的原因。回忆前 面讲的,处理硬中断的 CPU接下来会处理相应的软中断,进而执行上面包含 budget 的 这段逻辑。
多网卡多队列可能会出现这样的情况:多个 NAPI 变量注册到同一个 CPU 上。每个 CPU 上 的所有 NAPI 变量共享一份 budget。
如果没有足够的 CPU 来分散网卡硬中断,可以考虑增加 net_rx_action 允许每个 CPU 处理更多包。增加 budget 可以增加 CPU 使用量(top 等命令看到的 sitime 或 si 部分),但可以减少延迟,因为数据处理更加及时。
Note: the CPU will still be bounded by a time limit of 2 jiffies, regardless of the assigned budget.
5.3.2 NAPI poll 函数及权重
回忆前面,网络设备驱动使用 netif_napi_add 注册 poll 方法,igb 驱动有如下代码:
/* initialize NAPI */
netif_napi_add(adapter->netdev, &q_vector->napi, igb_poll, 64);
这注册了一个 NAPI 变量,hardcode 64 的权重。我们来看在 net_rx_action 处理循环 中这个值是如何使用的。 net/core/dev.c:
weight = n->weight;
work = 0;
if (test_bit(NAPI_STATE_SCHED, &n->state)) {
work = n->poll(n, weight);
trace_napi_poll(n);
}
WARN_ON_ONCE(work > weight);
budget -= work;
其中的 n 是 struct napi 的变量。其中的 poll 指向 igb_poll。poll() 返回 处理的数据帧数量,budget 会减去这个值。
所以,假设驱动使用 weight 值 64(Linux 3.13.0 的所有驱动都是 hardcode 这个值) ,设置 budget 默认值 300,那系统将在如下条件之一停止数据处理:
igb_poll函数被调用了最多 5 次(如果没有数据需要处理,那次数就会很少)- 时间经过了至少 2 个 jiffies
5.3.3 NAPI 和设备驱动的合约(contract)
NAPI 子系统和设备驱动之间的合约,最重要的一点是关闭 NAPI 的条件。具体如下:
- 如果驱动的
poll方法用完了它的全部 weight(默认 hardcode 64),那 它不要更改 NAPI 状态。接下来net_rx_actionloop 会做的 - 如果驱动的
poll方法没有用完全部 weight,那它必须关闭 NAPI。下次有硬件 中断触发,驱动的硬件处理函数调用napi_schedule时,NAPI 会被重新打开
接下来先看 net_rx_action 如何处理合约的第一部分,然后看 poll 方法如何处理第 二部分。
5.3.4 Finishing the net_rx_action loop
net_rx_action 循环的最后一部分代码处理前面提到的 NAPI 合约的第一部分。 net/core/dev.c:
/* Drivers must not modify the NAPI state if they
* consume the entire weight. In such cases this code
* still "owns" the NAPI instance and therefore can
* move the instance around on the list at-will.
*/
if (unlikely(work == weight)) {
if (unlikely(napi_disable_pending(n))) {
local_irq_enable();
napi_complete(n);
local_irq_disable();
} else {
if (n->gro_list) {
/* flush too old packets
* If HZ < 1000, flush all packets.
*/
local_irq_enable();
napi_gro_flush(n, HZ >= 1000);
local_irq_disable();
}
list_move_tail(&n->poll_list, &sd->poll_list);
}
}
如果全部 work 都用完了,net_rx_action 会面临两种情况:
- 网络设备需要关闭(例如,用户敲了
ifconfig eth0 down命令) - 如果设备不需要关闭,那检查是否有 GRO(后面会介绍)列表。如果时钟 tick rate
>= 1000,所有最近被更新的 GRO network flow 都会被 flush。将这个 NAPI 变量移 到 list 末尾,这个循环下次再进入时,处理的就是下一个 NAPI 变量
这就是包处理循环如何唤醒驱动注册的 poll 方法进行包处理的过程。接下来会看到, poll 方法会收割网络数据,发送到上层栈进行处理。
5.3.5 到达 limit 时退出循环
net_rx_action 下列条件之一退出循环:
- 这个 CPU 上注册的 poll 列表已经没有 NAPI 变量需要处理(
!list_empty(&sd->poll_list)) - 剩余的
budget <= 0 - 已经满足 2 个 jiffies 的时间限制
代码:
/* If softirq window is exhausted then punt.
* Allow this to run for 2 jiffies since which will allow
* an average latency of 1.5/HZ.
*/
if (unlikely(budget <= 0 || time_after_eq(jiffies, time_limit)))
goto softnet_break;
如果跟踪 softnet_break,会发现很有意思的东西:
From net/core/dev.c:
softnet_break:
sd->time_squeeze++;
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
goto out;
softnet_data 变量更新统计信息,软中断的 NET_RX_SOFTIRQ 被关闭。
time_squeeze 字段记录的是满足如下条件的次数:net_rx_action 有很多 work 要做但 是 budget 用完了,或者 work 还没做完但时间限制到了。这对理解网络处理的瓶颈至关重要 。我们后面会看到如何监控这个值。关闭 NET_RX_SOFTIRQ 是为了释放 CPU 时间给其他任务 用。这行代码是有意义的,因为只有我们有更多工作要做(还没做完)的时候才会执行到这里, 我们主动让出 CPU,不想独占太久。
然后执行到了 out 标签所在的代码。另外还有一种条件也会跳转到 out 标签:所有 NAPI 变量都处理完了,换言之,budget 数量大于网络包数量,所有驱动都已经关闭 NAPI ,没有什么事情需要 net_rx_action 做了。
out 代码段在从 net_rx_action 返回之前做了一件重要的事情:调用 net_rps_action_and_irq_enable。Receive Packet Steering 功能打开时这个函数 有重要作用:唤醒其他 CPU 处理网络包。
我们后面会看到 RPS 是如何工作的。现在先看看怎样监控 net_rx_action 处理循环的 健康状态,以及进入 NAPI poll 的内部,这样才能更好的理解网络栈。
5.3.6 NAPI poll
回忆前文,驱动程序会分配一段内存用于 DMA,将数据包写到内存。就像这段内存是由驱动 程序分配的一样,驱动程序也负责解绑(unmap)这些内存,读取数据,将数据送到网络栈 。
我们看下 igb 驱动如何实现这一过程的。
igb_poll
可以看到 igb_poll 代码其实相当简单。 drivers/net/ethernet/intel/igb/igb_main.c:
/**
* igb_poll - NAPI Rx polling callback
* @napi: napi polling structure
* @budget: count of how many packets we should handle
**/
static int igb_poll(struct napi_struct *napi, int budget)
{
struct igb_q_vector *q_vector = container_of(napi,
struct igb_q_vector,
napi);
bool clean_complete = true;
#ifdef CONFIG_IGB_DCA
if (q_vector->adapter->flags & IGB_FLAG_DCA_ENABLED)
igb_update_dca(q_vector);
#endif
/* ... */
if (q_vector->rx.ring)
clean_complete &= igb_clean_rx_irq(q_vector, budget);
/* If all work not completed, return budget and keep polling */
if (!clean_complete)
return budget;
/* If not enough Rx work done, exit the polling mode */
napi_complete(napi);
igb_ring_irq_enable(q_vector);
return 0;
}
几件有意思的事情:
- 如果内核 DCA(Direct Cache Access)功能打 开了,CPU 缓存是热的,对 RX ring 的访问会命中 CPU cache。更多 DCA 信息见本文 “ Extra” 部分
- 然后执行
igb_clean_rx_irq,这里做的事情非常多,我们后面看 - 然后执行
clean_complete,判断是否仍然有 work 可以做。如果有,就返回 budget( 回忆,这里是 hardcode 64)。在之前我们已经看到,net_rx_action会将这个 NAPI 变量移动到 poll 列表的末尾 - 如果所有
work都已经完成,驱动通过调用napi_complete关闭 NAPI,并通过调用igb_ring_irq_enable重新进入可中断状态。下次中断到来的时候回重新打开 NAPI
我们来看 igb_clean_rx_irq 如何将网络数据送到网络栈。
igb_clean_rx_irq
igb_clean_rx_irq 方法是一个循环,每次处理一个包,直到 budget 用完,或者没有数 据需要处理了。
做的几件重要事情:
- 分配额外的 buffer 用于接收数据,因为已经用过的 buffer 被 clean out 了。一次分配
IGB_RX_BUFFER_WRITE (16)个。 - 从 RX 队列取一个 buffer,保存到一个
skb类型的变量中 - 判断这个 buffer 是不是一个包的最后一个 buffer。如果是,继续处理;如果不是,继续 从 buffer 列表中拿出下一个 buffer,加到 skb。当数据帧的大小比一个 buffer 大的时候, 会出现这种情况
- 验证数据的 layout 和头信息是正确的
- 更新
skb->len,表示这个包已经处理的字节数 - 设置
skb的 hash, checksum, timestamp, VLAN id, protocol 字段。hash, checksum,timestamp,VLAN ID 信息是硬件提供的,如果硬件报告 checksum error,csum_error统计就会增加。如果 checksum 通过了,数据是 UDP 或者 TCP 数据,skb就会 被标记成CHECKSUM_UNNECESSARY - 构建的 skb 经
napi_gro_receive()进入协议栈 - 更新处理过的包的统计信息
- 循环直至处理的包数量达到 budget
循环结束的时候,这个函数设置收包的数量和字节数统计信息。
接下来在进入协议栈之前,我们先开两个小差:首先是看一些如何监控和调优软中断,其次 是介绍 GRO。有了这个两个背景,后面(通过 napi_gro_receive 进入)协议栈部分会更容易理解。
5.3.7 监控网络数据处理
/proc/net/softnet_stat
前面看到,如果 budget 或者 time limit 到了而仍有包需要处理,那 net_rx_action 在退出 循环之前会更新统计信息。这个信息存储在该 CPU 的 struct softnet_data 变量中。
这些统计信息打到了/proc/net/softnet_stat,但不幸的是,关于这个的文档很少。每一 列代表什么并没有标题,而且列的内容会随着内核版本可能发生变化。
在内核 3.13.0 中,你可以阅读内核源码,查看每一列分别对应什么。 net/core/net-procfs.c:
seq_printf(seq,
"%08x %08x %08x %08x %08x %08x %08x %08x %08x %08x %08x\n",
sd->processed, sd->dropped, sd->time_squeeze, 0,
0, 0, 0, 0, /* was fastroute */
sd->cpu_collision, sd->received_rps, flow_limit_count);
其中一些的名字让人很困惑,而且在你意想不到的地方更新。在接下来的网络栈分析说,我 们会举例说明其中一些字段是何时、在哪里被更新的。前面我们已经看到了 squeeze_time 是在 net_rx_action 在被更新的,到此时,如下数据你应该能看懂了:
$ cat /proc/net/softnet_stat
6dcad223 00000000 00000001 00000000 00000000 00000000 00000000 00000000 00000000 00000000
6f0e1565 00000000 00000002 00000000 00000000 00000000 00000000 00000000 00000000 00000000
660774ec 00000000 00000003 00000000 00000000 00000000 00000000 00000000 00000000 00000000
61c99331 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
6794b1b3 00000000 00000005 00000000 00000000 00000000 00000000 00000000 00000000 00000000
6488cb92 00000000 00000001 00000000 00000000 00000000 00000000 00000000 00000000 00000000
关于/proc/net/softnet_stat 的重要细节:
- 每一行代表一个
struct softnet_data变量。因为每个 CPU 只有一个该变量,所以每行 其实代表一个 CPU - 每列用空格隔开,数值用 16 进制表示
- 第一列
sd->processed,是处理的网络帧的数量。如果你使用了 ethernet bonding, 那这个值会大于总的网络帧的数量,因为 ethernet bonding 驱动有时会触发网络数据被 重新处理(re-processed) - 第二列,
sd->dropped,是因为处理不过来而 drop 的网络帧数量。后面会展开这一话题 - 第三列,
sd->time_squeeze,前面介绍过了,由于 budget 或 time limit 用完而退出net_rx_action循环的次数 - 接下来的 5 列全是 0
- 第九列,
sd->cpu_collision,是为了发送包而获取锁的时候有冲突的次数 - 第十列,
sd->received_rps,是这个 CPU 被其他 CPU 唤醒去收包的次数 - 最后一列,
flow_limit_count,是达到 flow limit 的次数。flow limit 是 RPS 的特性, 后面会稍微介绍一下
如果你要画图监控这些数据,确保你的列和相应的字段是对的上的,最保险的方式是阅读相 应版本的内核代码。
5.3.8 网络数据处理调优
调整 net_rx_action budget
net_rx_action budget 表示一个 CPU 单次轮询(poll)所允许的最大收包数量。单次 poll 收包时,所有注册到这个 CPU 的 NAPI 变量收包数量之和不能大于这个阈值。 调整:
$ sudo sysctl -w net.core.netdev_budget=600
如果要保证重启仍然生效,需要将这个配置写到/etc/sysctl.conf。
Linux 3.13.0 的默认配置是 300。
5.4 GRO(Generic Receive Offloading)
Large Receive Offloading (LRO) 是一个硬件优化,GRO 是 LRO 的一种软件实现。
两种方案的主要思想都是:通过合并“足够类似”的包来减少传送给网络栈的包数,这有 助于减少 CPU 的使用量。例如,考虑大文件传输的场景,包的数量非常多,大部分包都是一 段文件数据。相比于每次都将小包送到网络栈,可以将收到的小包合并成一个很大的包再送 到网络栈。GRO 使协议层只需处理一个 header,而将包含大量数据的整个大包送到用 户程序。
这类优化方式的缺点是 信息丢失:包的 option 或者 flag 信息在合并时会丢 失。这也是为什么大部分人不使用或不推荐使用LRO 的原因。
LRO 的实现,一般来说,对合并包的规则非常宽松。GRO 是 LRO 的软件实现,但是对于包合并 的规则更严苛。
顺便说一下,如果用 tcpdump 抓包,有时会看到机器收到了看起来不现实的、非常大的包, 这很可能是你的系统开启了 GRO。接下来会看到,tcpdump 的抓包点(捕获包的 tap )在整个栈的更后面一些,在GRO 之后。
使用 ethtool 修改 GRO 配置
-k 查看 GRO 配置:
$ ethtool -k eth0 | grep generic-receive-offload
generic-receive-offload: on
-K 修改 GRO 配置:
$ sudo ethtool -K eth0 gro on
注意:对于大部分驱动,修改 GRO 配置会涉及先 down 再 up 这个网卡,因此这个网卡上的连接 都会中断。
5.5 napi_gro_receive
如果开启了 GRO,napi_gro_receive 将负责处理网络数据,并将数据送到协议栈,大部分 相关的逻辑在函数 dev_gro_receive 里实现。
dev_gro_receive
这个函数首先检查 GRO 是否开启了,如果是,就准备做 GRO。GRO 首先遍历一个 offload filter 列表,如果高层协议认为其中一些数据属于 GRO 处理的范围,就会允许其对数据进行 操作。
协议层以此方式让网络设备层知道,这个 packet 是不是当前正在处理的一个需要做 GRO 的 network flow 的一部分,而且也可以通过这种方式传递一些协议相关的信息。例如,TCP 协 议需要判断是否以及合适应该将一个 ACK 包合并到其他包里。
list_for_each_entry_rcu(ptype, head, list) {
if (ptype->type != type || !ptype->callbacks.gro_receive)
continue;
skb_set_network_header(skb, skb_gro_offset(skb));
skb_reset_mac_len(skb);
NAPI_GRO_CB(skb)->same_flow = 0;
NAPI_GRO_CB(skb)->flush = 0;
NAPI_GRO_CB(skb)->free = 0;
pp = ptype->callbacks.gro_receive(&napi->gro_list, skb);
break;
}
如果协议层提示是时候 flush GRO packet 了,那就到下一步处理了。这发生在 napi_gro_complete,会进一步调用相应协议的 gro_complete 回调方法,然后调用 netif_receive_skb 将包送到协议栈。 这个过程见net/core/dev.c:
if (pp) {
struct sk_buff *nskb = *pp;
*pp = nskb->next;
nskb->next = NULL;
napi_gro_complete(nskb);
napi->gro_count--;
}
接下来,如果协议层将这个包合并到一个已经存在的 flow,napi_gro_receive 就没什么事 情需要做,因此就返回了。如果 packet 没有被合并,而且 GRO 的数量小于 MAX_GRO_SKBS( 默认是 8),就会创建一个新的 entry 加到本 CPU 的 NAPI 变量的 gro_list。 net/core/dev.c:
if (NAPI_GRO_CB(skb)->flush || napi->gro_count >= MAX_GRO_SKBS)
goto normal;
napi->gro_count++;
NAPI_GRO_CB(skb)->count = 1;
NAPI_GRO_CB(skb)->age = jiffies;
skb_shinfo(skb)->gso_size = skb_gro_len(skb);
skb->next = napi->gro_list;
napi->gro_list = skb;
ret = GRO_HELD;
这就是 Linux 网络栈中 GRO 的工作原理。
5.6 napi_skb_finish
一旦 dev_gro_receive 完成,napi_skb_finish 就会被调用,其如果一个 packet 被合并了 ,就释放不用的变量;或者调用 netif_receive_skb 将数据发送到网络协议栈(因为已经 有 MAX_GRO_SKBS 个 flow 了,够 GRO 了)。
接下来,是看 netif_receive_skb 如何将数据交给协议层。但在此之前,我们先看一下 RPS。
6 RPS (Receive Packet Steering)
回忆前面我们讨论了网络设备驱动是如何注册 NAPI poll 方法的。每个 NAPI 变量都会运 行在相应 CPU 的软中断的上下文中。而且,触发硬中断的这个 CPU 接下来会负责执行相应的软 中断处理函数来收包。
换言之,同一个 CPU 既处理硬中断,又处理相应的软中断。
一些网卡(例如 Intel I350)在硬件层支持多队列。这意味着收进来的包会被通过 DMA 放到 位于不同内存的队列上,而不同的队列有相应的 NAPI 变量管理软中断 poll()过程。因此, 多个 CPU 同时处理从网卡来的中断,处理收包过程。
这个特性被称作 RSS(Receive Side Scaling,接收端扩展)。
RPS (Receive Packet Steering,接收包控制,接收包引导)是 RSS 的一种软件实现。因为是软 件实现的,意味着任何网卡都可以使用这个功能,即便是那些只有一个接收队列的网卡。但 是,因为它是软件实现的,这意味着 RPS 只能在 packet 通过 DMA 进入内存后,RPS 才能开始工 作。
这意味着,RPS 并不会减少 CPU 处理硬件中断和 NAPI poll(软中断最重要的一部分)的时 间,但是可以在 packet 到达内存后,将 packet 分到其他 CPU,从其他 CPU 进入协议栈。
RPS 的工作原理是对个 packet 做 hash,以此决定分到哪个 CPU 处理。然后 packet 放到每个 CPU 独占的接收后备队列(backlog)等待处理。这个 CPU 会触发一个进程间中断( IPI,Inter-processor Interrupt)向对端 CPU。如果当时对端 CPU 没有在处理 backlog 队列收包,这个进程间中断会 触发它开始从 backlog 收包。/proc/net/softnet_stat 其中有一列是记录 softnet_data 变量(也即这个 CPU)收到了多少 IPI(received_rps 列)。
因此,netif_receive_skb 或者继续将包送到协议栈,或者交给 RPS,后者会转交给其他 CPU 处理。
RPS 调优
使用 RPS 需要在内核做配置(Ubuntu + Kernel 3.13.0 支持),而且需要一个掩码( bitmask)指定哪些 CPU 可以处理那些 RX 队列。相关的一些信息可以在内核文档 里找到。
bitmask 配置位于:/sys/class/net/DEVICE_NAME/queues/QUEUE/rps_cpus。
例如,对于 eth0 的 queue 0,你需要更改/sys/class/net/eth0/queues/rx-0/rps_cpus。 内核文档 里说,对一些特定的配置下,RPS 没必要了。
注意:打开 RPS 之后,原来不需要处理软中断(softirq)的 CPU 这时也会参与处理。因此相 应 CPU 的 NET_RX 数量,以及 si 或 sitime 占比都会相应增加。你可以对比启用 RPS 前后的 数据,以此来确定你的配置是否生效,以及是否符合预期(哪个 CPU 处理哪个网卡的哪个中 断)。
7 RFS (Receive Flow Steering)
RFS(Receive flow steering)和 RPS 配合使用。RPS 试图在 CPU 之间平衡收包,但是没考虑 数据的本地性问题,如何最大化 CPU 缓存的命中率。RFS 将属于相同 flow 的包送到相同的 CPU 进行处理,可以提高缓存命中率。
调优:打开 RFS
RPS 记录一个全局的 hash table,包含所有 flow 的信息。这个 hash table 的大小可以在 net.core.rps_sock_flow_entries:
$ sudo sysctl -w net.core.rps_sock_flow_entries=32768
其次,你可以设置每个 RX queue 的 flow 数量,对应着 rps_flow_cnt:
例如,eth0 的 RX queue0 的 flow 数量调整到 2048:
$ sudo bash -c 'echo 2048 > /sys/class/net/eth0/queues/rx-0/rps_flow_cnt'
8 aRFS (Hardware accelerated RFS)
RFS 可以用硬件加速,网卡和内核协同工作,判断哪个 flow 应该在哪个 CPU 上处理。这需要网 卡和网卡驱动的支持。
如果你的网卡驱动里对外提供一个 ndo_rx_flow_steer 函数,那就是支持 RFS。
调优: 启用 aRFS
假如你的网卡支持 aRFS,你可以开启它并做如下配置:
- 打开并配置 RPS
- 打开并配置 RFS
- 内核中编译期间指定了
CONFIG_RFS_ACCEL选项。Ubuntu kernel 3.13.0 是有的 - 打开网卡的 ntuple 支持。可以用 ethtool 查看当前的 ntuple 设置
- 配置 IRQ(硬中断)中每个 RX 和 CPU 的对应关系
以上配置完成后,aRFS 就会自动将 RX queue 数据移动到指定 CPU 的内存,每个 flow 的包都会 到达同一个 CPU,不需要你再通过 ntuple 手动指定每个 flow 的配置了。
9 从 netif_receive_skb 进入协议栈
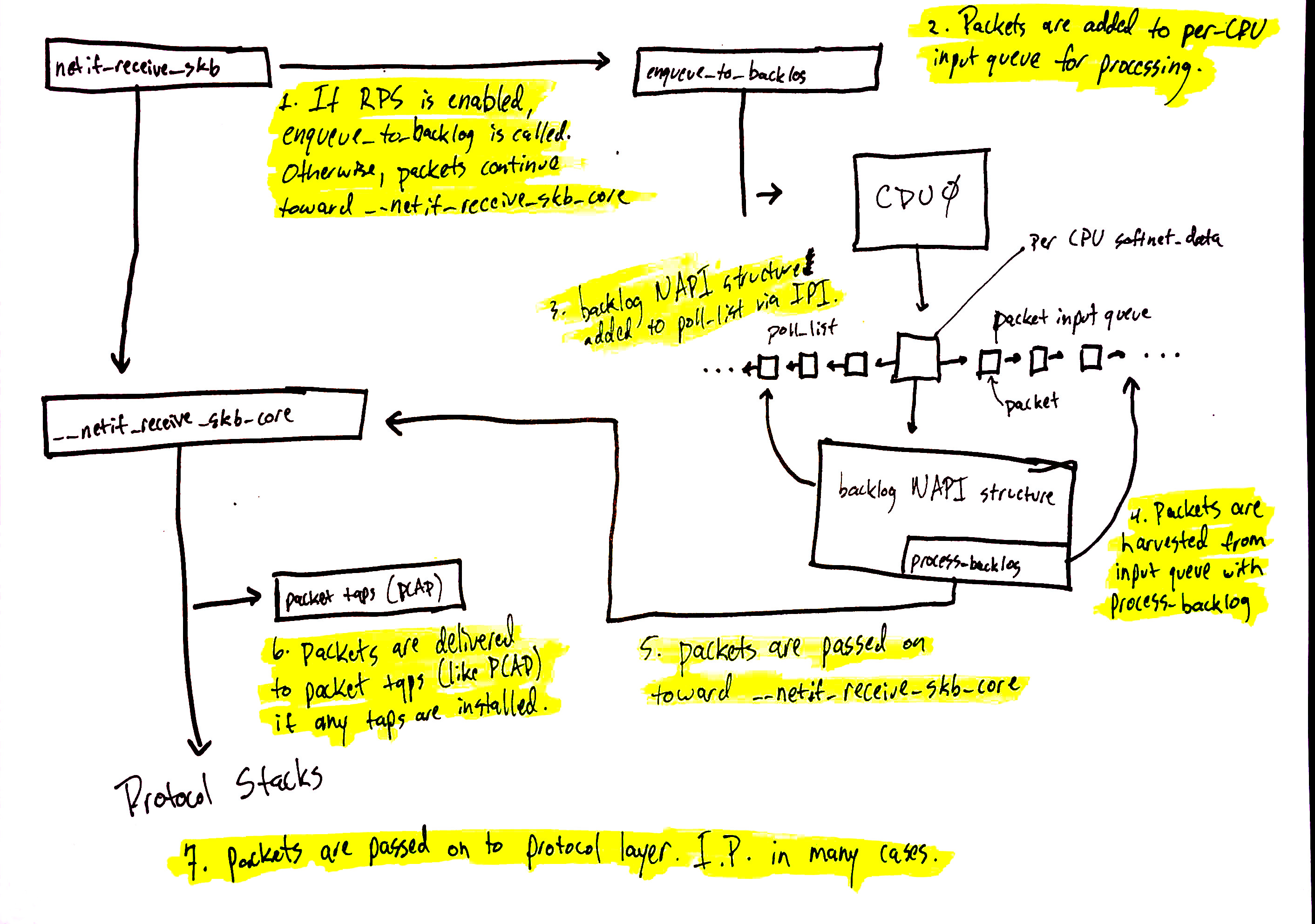
重新捡起我们前面已经几次提到过的 netif_receive_skb,这个函数在好几个地方被调用 。两个最重要的地方(前面都看到过了):
napi_skb_finish:当 packet 不需要被合并到已经存在的某个 GRO flow 的时候napi_gro_complete:协议层提示需要 flush 当前的 flow 的时候
提示:netif_receive_skb 和它调用的函数都运行在软中断处理循环(softirq processing loop)的上下文中,因此这里的时间会记录到 top 命令看到的 si 或者 sitime 字段。
netif_receive_skb 首先会检查用户有没有设置一个接收时间戳选项(sysctl),这个选 项决定在 packet 在到达 backlog queue 之前还是之后打时间戳。如果启用,那立即打时间戳 ,在 RPS 之前(CPU 和 backlog queue 绑定);如果没有启用,那只有在它进入到 backlog queue 之后才会打时间戳。如果 RPS 开启了,那这个选项可以将打时间戳的任务分散个其他 CPU,但会带来一些延迟。
9.1 调优: 收包打时间戳(RX packet timestamping)
你可以调整包被收到后,何时给它打时间戳。
关闭收包打时间戳:
$ sudo sysctl -w net.core.netdev_tstamp_prequeue=0
默认是 1。
10 netif_receive_skb
处理完时间戳后,netif_receive_skb 会根据 RPS 是否启用来做不同的事情。我们先来看简 单情况,RPS 未启用。
10.1 不使用 RPS(默认)
如果 RPS 没启用,会调用__netif_receive_skb,它做一些 bookkeeping 工作,进而调用 __netif_receive_skb_core,将数据移动到离协议栈更近一步。
__netif_receive_skb_core 工作的具体细节我们稍后再看,先看一下 RPS 启用的情况下的 代码调用关系,它也会调到这个函数的。
10.2 使用 RPS
如果 RPS 启用了,它会做一些计算,判断使用哪个 CPU 的 backlog queue,这个过程由 get_rps_cpu 函数完成。 net/core/dev.c:
cpu = get_rps_cpu(skb->dev, skb, &rflow);
if (cpu >= 0) {
ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail);
rcu_read_unlock();
return ret;
}
get_rps_cpu 会考虑前面提到的 RFS 和 aRFS 设置,以此选出一个合适的 CPU,通过调用 enqueue_to_backlog 将数据放到它的 backlog queue。
10.3 enqueue_to_backlog
首先从远端 CPU 的 struct softnet_data 变量获取 backlog queue 长度。如果 backlog 大于 netdev_max_backlog,或者超过了 flow limit,直接 drop,并更新 softnet_data 的 drop 统计。注意这是远端 CPU 的统计。
qlen = skb_queue_len(&sd->input_pkt_queue);
if (qlen <= netdev_max_backlog && !skb_flow_limit(skb, qlen)) {
if (skb_queue_len(&sd->input_pkt_queue)) {
enqueue:
__skb_queue_tail(&sd->input_pkt_queue, skb);
input_queue_tail_incr_save(sd, qtail);
return NET_RX_SUCCESS;
}
/* Schedule NAPI for backlog device */
if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) {
if (!rps_ipi_queued(sd))
____napi_schedule(sd, &sd->backlog);
}
goto enqueue;
}
sd->dropped++;
kfree_skb(skb);
return NET_RX_DROP;
enqueue_to_backlog 被调用的地方很少。在基于 RPS 处理包的地方,以及 netif_rx,会 调用到它。大部分驱动都不应该使用 netif_rx,而应该是用 netif_receive_skb。如果 你没用到 RPS,你的驱动也没有使用 netif_rx,那增大 backlog 并不会带来益处,因为它 根本没被用到。
注意:检查你的驱动,如果它调用了 netif_receive_skb,而且你没用 RPS,那增大 netdev_max_backlog 并不会带来任何性能提升,因为没有数据包会被送到 input_pkt_queue。
如果 input_pkt_queue 足够小,而 flow limit(后面会介绍)也还没达到(或者被禁掉了 ),那数据包将会被放到队列。这里的逻辑有点 funny,但大致可以归为为:
- 如果 backlog 是空的:如果远端 CPU NAPI 变量没有运行,并且 IPI 没有被加到队列,那就 触发一个 IPI 加到队列,然后调用
____napi_schedule进一步处理 - 如果 backlog 非空,或者远端 CPU NAPI 变量正在运行,那就 enqueue 包
这里使用了 goto,所以代码看起来有点 tricky。
if (skb_queue_len(&sd->input_pkt_queue)) {
enqueue:
__skb_queue_tail(&sd->input_pkt_queue, skb);
input_queue_tail_incr_save(sd, qtail);
rps_unlock(sd);
local_irq_restore(flags);
return NET_RX_SUCCESS;
}
/* Schedule NAPI for backlog device
* We can use non atomic operation since we own the queue lock
*/
if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) {
if (!rps_ipi_queued(sd))
____napi_schedule(sd, &sd->backlog);
}
goto enqueue;
Flow limits
RPS 在不同 CPU 之间分发 packet,但是,如果一个 flow 特别大,会出现单个 CPU 被打爆,而 其他 CPU 无事可做(饥饿)的状态。因此引入了 flow limit 特性,放到一个 backlog 队列的属 于同一个 flow 的包的数量不能超过一个阈值。这可以保证即使有一个很大的 flow 在大量收包 ,小 flow 也能得到及时的处理。
检查 flow limit 的代码,net/core/dev.c:
if (qlen <= netdev_max_backlog && !skb_flow_limit(skb, qlen)) {
默认,flow limit 功能是关掉的。要打开 flow limit,你需要指定一个 bitmap(类似于 RPS 的 bitmap)。
监控:由于 input_pkt_queue 打满或 flow limit 导致的丢包
在/proc/net/softnet_stat 里面的 dropped 列计数,包含本节提到的原因导致的 drop。
调优
Tuning: Adjusting netdev_max_backlog to prevent drops
在调整这个值之前,请先阅读前面的“注意”。
如果你使用了 RPS,或者你的驱动调用了 netif_rx,那增加 netdev_max_backlog 可以改 善在 enqueue_to_backlog 里的丢包:
例如:increase backlog to 3000 with sysctl.
$ sudo sysctl -w net.core.netdev_max_backlog=3000
默认值是 1000。
Tuning: Adjust the NAPI weight of the backlog poll loop
net.core.dev_weight 决定了 backlog poll loop 可以消耗的整体 budget(参考前面更改 net.core.netdev_budget 的章节):
$ sudo sysctl -w net.core.dev_weight=600
默认值是 64。
记住,backlog 处理逻辑和设备驱动的 poll 函数类似,都是在软中断(softirq)的上下文 中执行,因此受整体 budget 和处理时间的限制,前面已经分析过了。
Tuning: Enabling flow limits and tuning flow limit hash table size
$ sudo sysctl -w net.core.flow_limit_table_len=8192
默认值是 4096.
这只会影响新分配的 flow hash table。所以,如果你想增加 table size 的话,应该在打开 flow limit 功能之前设置这个值。
打开 flow limit 功能的方式是,在/proc/sys/net/core/flow_limit_cpu_bitmap 中指定一 个 bitmask,和通过 bitmask 打开 RPS 的操作类似。
10.4 处理 backlog 队列:NAPI poller
每个 CPU 都有一个 backlog queue,其加入到 NAPI 变量的方式和驱动差不多,都是注册一个 poll 方法,在软中断的上下文中处理包。此外,还提供了一个 weight,这也和驱动类似 。
注册发生在网络系统初始化的时候。
net/core/dev.c的 net_dev_init 函数:
sd->backlog.poll = process_backlog;
sd->backlog.weight = weight_p;
sd->backlog.gro_list = NULL;
sd->backlog.gro_count = 0;
backlog NAPI 变量和设备驱动 NAPI 变量的不同之处在于,它的 weight 是可以调节的,而设备 驱动是 hardcode 64。在下面的调优部分,我们会看到如何用 sysctl 调整这个设置。
10.5 process_backlog
process_backlog 是一个循环,它会一直运行直至 weight(前面介绍了)用完,或者 backlog 里没有数据了。
backlog queue 里的数据取出来,传递给__netif_receive_skb。这个函数做的事情和 RPS 关闭的情况下做的事情一样。即,__netif_receive_skb 做一些 bookkeeping 工作,然后调 用__netif_receive_skb_core 将数据发送给更上面的协议层。
process_backlog 和 NAPI 之间遵循的合约,和驱动和 NAPI 之间的合约相同:NAPI is disabled if the total weight will not be used. The poller is restarted with the call to ____napi_schedule from enqueue_to_backlog as described above.
函数返回接收完成的数据帧数量(在代码中是变量 work),net_rx_action(前面介绍了 )将会从 budget(通过 net.core.netdev_budget 可以调整,前面介绍了)里减去这个值。
10.6 __netif_receive_skb_core:将数据送到抓包点(tap)或协议层
__netif_receive_skb_core 完成将数据送到协议栈这一繁重工作(the heavy lifting of delivering the data)。在此之前,它会先检查是否插入了 packet tap(探 测点),这些 tap 是抓包用的。例如,AF_PACKET 地址族就可以插入这些抓包指令, 一般通过 libpcap 库。
如果存在抓包点(tap),数据就会先到抓包点,然后才到协议层。
10.7 送到抓包点(tap)
如果有 packet tap(通常通过 libpcap),packet 会送到那里。 net/core/dev.c:
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (!ptype->dev || ptype->dev == skb->dev) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
}
如果对 packet 如何经过 pcap 有兴趣,可以阅读 net/packet/af_packet.c。
10.8 送到协议层
处理完 taps 之后,__netif_receive_skb_core 将数据发送到协议层。它会从数据包中取出 协议信息,然后遍历注册在这个协议上的回调函数列表。
可以看__netif_receive_skb_core 函数,net/core/dev.c:
type = skb->protocol;
list_for_each_entry_rcu(ptype,
&ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) {
if (ptype->type == type &&
(ptype->dev == null_or_dev || ptype->dev == skb->dev ||
ptype->dev == orig_dev)) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
}
上面的 ptype_base 是一个 hash table,定义在net/core/dev.c中:
struct list_head ptype_base[PTYPE_HASH_SIZE] __read_mostly;
每种协议在上面的 hash table 的一个 slot 里,添加一个过滤器到列表里。这个列表的头用如 下函数获取:
static inline struct list_head *ptype_head(const struct packet_type *pt)
{
if (pt->type == htons(ETH_P_ALL))
return &ptype_all;
else
return &ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK];
}
添加的时候用 dev_add_pack 这个函数。这就是协议层如何注册自身,用于处理相应协议的 网络数据的。
现在,你已经知道了数据是如何从卡进入到协议层的了。
11 协议层注册
接下来我们看协议层注册自身的实现。
本文会拿 IP 层作为例子,因为它最常用,大部分读者都很熟悉。
11.1 IP 协议层
IP 层在函数 inet_init 中将自身注册到 ptype_base 哈希表。 net/ipv4/af_inet.c:
dev_add_pack(&ip_packet_type);
struct packet_type 的变量 ip_packet_type 定义在 net/ipv4/af_inet.c:
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
};
__netif_receive_skb_core 会调用 deliver_skb (前面介绍过了), 后者会调用.func 方法(这个例子中就是 ip_rcv)。
11.1.1 ip_rcv
ip_rcv 方法的核心逻辑非常简单直接,此外就是一些数据合法性验证,统计计数器更新等 等。它在最后会以 netfilter 的方式调用 ip_rcv_finish 方法。这样做的目的是,任何 iptables 规则都能在 packet 刚进入 IP 层协议的时候被应用,在其他处理之前。
我们可以在 ip_rcv 结束的时候看到交给 netfilter 的代码: net/ipv4/ip_input.c
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, skb, dev, NULL, ip_rcv_finish);
netfilter and iptables
这里简单介绍下 netfilter, iptables 和 conntrack。
NF_HOOK_THRESH 会检查是否有 filter 被安装,并会适时地返回到 IP 协议层,避免过深的进 入 netfilter 处理,以及在 netfilter 下面再做 hook 的 iptables 和 conntrack。
注意:netfilter 或 iptables 规则都是在软中断上下文中执行的,数量很多或规则很 复杂时会导致网络延迟。但如果你就是需要一些规则的话,那这个性能损失看起来是无 法避免的。
11.1.2 ip_rcv_finish
netfilter 完成对数据的处理之后,就会调用 ip_rcv_finish —— 当然,前提是 netfilter 没有丢掉这个包。
ip_rcv_finish 开始的地方做了一个优化。为了能将包送到合适的目的地,需要一个路由 子系统的 dst_entry 变量。为了获取这个变量,早期的代码调用了 early_demux 函数,从 这个数据的目的端的高层协议中。
early_demux 是一个优化项,通过检查相应的变量是否缓存在 socket 变量上,来路由 这个包所需要的 dst_entry 变量。 net/ipv4/ip_input.c:
if (sysctl_ip_early_demux && !skb_dst(skb) && skb->sk == NULL) {
const struct net_protocol *ipprot;
int protocol = iph->protocol;
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot && ipprot->early_demux) {
ipprot->early_demux(skb);
/* must reload iph, skb->head might have changed */
iph = ip_hdr(skb);
}
}
可以看到,这个函数只有在 sysctl_ip_early_demux 为 true 的时候才有可能被执行。默 认 early_demux 是打开的。下一节会介绍如何关闭它,以及为什么你可能会需要关闭它。
如果这个优化打开了,但是并没有命中缓存(例如,这是第一个包),这个包就会被送到内 核的路由子系统,在那里将会计算出一个 dst_entry 并赋给相应的字段。
路由子系统完成工作后,会更新计数器,然后调用 dst_input(skb),后者会进一步调用 dst_entry 变量中的 input 方法,这个方法是一个函数指针,有路由子系统初始化。例如 ,如果 packet 的最终目的地是本机(local system),路由子系统会将 ip_local_deliver 赋 给 input。
调优: 打开或关闭 IP 协议的 early demux 选项
关闭 early_demux 优化:
$ sudo sysctl -w net.ipv4.ip_early_demux=0
默认是 1,即该功能默认是打开的。
添加这个 sysctl 开关的原因是,一些用户报告说,在某些场景下 early_demux 优化会导 致 ~5% 左右的吞吐量下降。
11.1.3 ip_local_deliver
回忆我们看到的 IP 协议层过程:
- 调用
ip_rcv做一些初始的 bookkeeping - 将包交给 netfilter 处理,同时还有一个回调函数,netfilter 处理完毕后会调用这个函 数
- 处理结束的时候,调用
ip_rcv_finish,将数据包送到协议栈的更上层
ip_local_deliver 的逻辑与此类似: net/ipv4/ip_input.c:
/*
* Deliver IP Packets to the higher protocol layers.
*/
int ip_local_deliver(struct sk_buff *skb)
{
/*
* Reassemble IP fragments.
*/
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, skb, skb->dev, NULL,
ip_local_deliver_finish);
}
只要 packet 没有在 netfilter 被 drop,就会调用 ip_local_deliver_finish 函数。
11.1.4 ip_local_deliver_finish
ip_local_deliver_finish 从数据包中读取协议,寻找注册在这个协议上的 struct net_protocol 变量,并调用该变量中的回调方法。这样将包送到协议栈的更上层。
Monitoring: IP protocol layer statistics
读取/proc/net/snmp 获取详细的 IP 协议统计:
$ cat /proc/net/snmp
Ip: Forwarding DefaultTTL InReceives InHdrErrors InAddrErrors ForwDatagrams InUnknownProtos InDiscards InDelivers OutRequests OutDiscards OutNoRoutes ReasmTimeout ReasmReqds ReasmOKs ReasmFails FragOKs FragFails FragCreates
Ip: 1 64 25922988125 0 0 15771700 0 0 25898327616 22789396404 12987882 51 1 10129840 2196520 1 0 0 0
...
这个文件包含几个协议层的统计信息。先是 IP 层。
与这些列相关的,IP 层的统计类型都定义在include/uapi/linux/snmp.h:
enum
{
IPSTATS_MIB_NUM = 0,
/* frequently written fields in fast path, kept in same cache line */
IPSTATS_MIB_INPKTS, /* InReceives */
IPSTATS_MIB_INOCTETS, /* InOctets */
IPSTATS_MIB_INDELIVERS, /* InDelivers */
IPSTATS_MIB_OUTFORWDATAGRAMS, /* OutForwDatagrams */
IPSTATS_MIB_OUTPKTS, /* OutRequests */
IPSTATS_MIB_OUTOCTETS, /* OutOctets */
/* ... */
读取/proc/net/netstat 获取更详细的 IP 层统计:
$ cat /proc/net/netstat | grep IpExt
IpExt: InNoRoutes InTruncatedPkts InMcastPkts OutMcastPkts InBcastPkts OutBcastPkts InOctets OutOctets InMcastOctets OutMcastOctets InBcastOctets OutBcastOctets InCsumErrors InNoECTPkts InECT0Pktsu InCEPkts
IpExt: 0 0 0 0 277959 0 14568040307695 32991309088496 0 0 58649349 0 0 0 0 0
格式和/proc/net/snmp 类似,除了每列的命字都一 IpExt 开头之外。
一些有趣的统计:
InReceives: The total number of IP packets that reached ip_rcv before any data integrity checks.InHdrErrors: Total number of IP packets with corrupted headers. The header was too short, too long, non-existent, had the wrong IP protocol version number, etc.InAddrErrors: Total number of IP packets where the host was unreachable.ForwDatagrams: Total number of IP packets that have been forwarded.InUnknownProtos: Total number of IP packets with unknown or unsupported protocol specified in the header.InDiscards: Total number of IP packets discarded due to memory allocation failure or checksum failure when packets are trimmed.InDelivers: Total number of IP packets successfully delivered to higher protocol layers. Keep in mind that those protocol layers may drop data even if the IP layer does not.- InCsumErrors: Total number of IP Packets with checksum errors.
注意这些计数分别在 IP 层的不同地方被更新。由于代码一直在更新,重复计数或者计数错 误的 bug 可能会引入。如果这些计数对你非常重要,强烈建议阅读内核的相应源码,确定 它们是在哪里更新的,以及更新的对不对,是不是有 bug 等等。
11.2 高层协议注册
本文介绍 UDP 处理函数的注册过程,TCP 的注册过程与此一样,并且是在相同的时间注册的。
在 net/ipv4/af_inet.c 中定义了 UDP、TCP 和 ICMP 协议的回调函数相关的数据结构,IP 层处 理完毕之后会调用相应的回调. From net/ipv4/af_inet.c:
static const struct net_protocol tcp_protocol = {
.early_demux = tcp_v4_early_demux,
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
.netns_ok = 1,
};
static const struct net_protocol udp_protocol = {
.early_demux = udp_v4_early_demux,
.handler = udp_rcv,
.err_handler = udp_err,
.no_policy = 1,
.netns_ok = 1,
};
static const struct net_protocol icmp_protocol = {
.handler = icmp_rcv,
.err_handler = icmp_err,
.no_policy = 1,
.netns_ok = 1,
};
这些变量在 inet 地址族初始化的时候被注册。 net/ipv4/af_inet.c:
/*
* Add all the base protocols.
*/
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
pr_crit("%s: Cannot add ICMP protocol\n", __func__);
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)
pr_crit("%s: Cannot add UDP protocol\n", __func__);
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
pr_crit("%s: Cannot add TCP protocol\n", __func__);
接下来我们详细查看 UDP 协议。上面可以看到,UDP 的回调函数是 udp_rcv。这是从 IP 层进 入 UDP 层的入口。我们就从这里开始探索。
11.3 UDP 协议层
UDP 协议层的实现见net/ipv4/udp.c。
11.3.1 udp_rcv
这个函数只要一行,调用__udp4_lib_rcv 接收 UDP 报文。
11.3.2 __udp4_lib_rcv
__udp4_lib_rcv 首先对包数据进行合法性检查,获取 UDP 头、UDP 数据报长度、源地址、目 标地址等信息。然后进行其他一些完整性检测和 checksum 验证。
回忆前面的 IP 层内容,在送到更上面一层协议(这里是 UDP)之前,会将一个 dst_entry 会关联到 skb。
如果对应的 dst_entry 找到了,并且有对应的 socket,__udp4_lib_rcv 会将 packet 放到 socket 的接收队列:
sk = skb_steal_sock(skb);
if (sk) {
struct dst_entry *dst = skb_dst(skb);
int ret;
if (unlikely(sk->sk_rx_dst != dst))
udp_sk_rx_dst_set(sk, dst);
ret = udp_queue_rcv_skb(sk, skb);
sock_put(sk);
/* a return value > 0 means to resubmit the input, but
* it wants the return to be -protocol, or 0
*/
if (ret > 0)
return -ret;
return 0;
} else {
如果 early_demux 中没有关联 socket 信息,那此时会调用__udp4_lib_lookup_skb 查找对应的 socket。
以上两种情况,最后都会将 packet 放到 socket 的接收队列:
ret = udp_queue_rcv_skb(sk, skb);
sock_put(sk);
如果 socket 没有找到,数据报(datagram)会被丢弃:
/* No socket. Drop packet silently, if checksum is wrong */
if (udp_lib_checksum_complete(skb))
goto csum_error;
UDP_INC_STATS_BH(net, UDP_MIB_NOPORTS, proto == IPPROTO_UDPLITE);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PORT_UNREACH, 0);
/*
* Hmm. We got an UDP packet to a port to which we
* don't wanna listen. Ignore it.
*/
kfree_skb(skb);
return 0;
11.3.3 udp_queue_rcv_skb
这个函数的前面部分所做的工作:
- 判断和这个数据报关联的 socket 是不是 encapsulation socket。如果是,将 packet 送到该层的处理函数
- 判断这个数据报是不是 UDP-Lite 数据报,做一些完整性检测
- 验证 UDP 数据报的校验和,如果校验失败,就丢弃
最后,我们来到了 socket 的接收队列逻辑,判断队列是不是满了: net/ipv4/udp.c:
if (sk_rcvqueues_full(sk, skb, sk->sk_rcvbuf))
goto drop;
13.3.4 sk_rcvqueues_full
定义如下:
/*
* Take into account size of receive queue and backlog queue
* Do not take into account this skb truesize,
* to allow even a single big packet to come.
*/
static inline bool sk_rcvqueues_full(const struct sock *sk, const struct sk_buff *skb,
unsigned int limit)
{
unsigned int qsize = sk->sk_backlog.len + atomic_read(&sk->sk_rmem_alloc);
return qsize > limit;
}
Tuning these values is a bit tricky as there are many things that can be adjusted.
调优: Socket receive queue memory
上面看到,判断 socket 接收队列是否满了是和 sk->sk_rcvbuf 做比较。 这个值可以被两个 sysctl 参数控制:最大值和默认值:
$ sudo sysctl -w net.core.rmem_max=8388608
$ sudo sysctl -w net.core.rmem_default=8388608
你也可以在你的应用里调用 setsockopt 带上 SO_RCVBUF 来修改这个值(sk->sk_rcvbuf) ,能设置的最大值不能超过 net.core.rmem_max。
但是,你也可以 setsockopt 带上 SO_RCVBUFFORCE 来覆盖 net.core.rmem_max,但是执 行应用的用户要有 CAP_NET_ADMIN 权限。
skb_set_owner_r 函数设置 UDP 数据包的 owner,并会更新计数器 sk->sk_rmem_alloc。 我们接下来会看到。
sk_add_backlog 函数会更新 sk->sk_backlog.len 计数,后面看。
11.3.5 udp_queue_rcv_skb
判断 queue 未满之后,就会将数据报放到里面: net/ipv4/udp.c:
bh_lock_sock(sk);
if (!sock_owned_by_user(sk))
rc = __udp_queue_rcv_skb(sk, skb);
else if (sk_add_backlog(sk, skb, sk->sk_rcvbuf)) {
bh_unlock_sock(sk);
goto drop;
}
bh_unlock_sock(sk);
return rc;
第一步先判断有没有用户空间的程序正在这个 socket 上进行系统调用。如果没有,就可以调用__udp_queue_rcv_skb 将数据报放到接收队列;如果有,就调用 sk_add_backlog 将它放到 backlog 队列。
当用户空间程序释放在这个 socket 上的系统调用时(通过向内核调用 release_sock),这 个数据报就从 backlog 移动到了接收队列。
11.3.7 __udp_queue_rcv_skb
这个函数调用 sock_queue_rcv_skb 将数据报送到 socket 接收队列;如果失败,更新统计计数并释放 skb。
rc = sock_queue_rcv_skb(sk, skb);
if (rc < 0) {
int is_udplite = IS_UDPLITE(sk);
/* Note that an ENOMEM error is charged twice */
if (rc == -ENOMEM)
UDP_INC_STATS_BH(sock_net(sk), UDP_MIB_RCVBUFERRORS,is_udplite);
UDP_INC_STATS_BH(sock_net(sk), UDP_MIB_INERRORS, is_udplite);
kfree_skb(skb);
trace_udp_fail_queue_rcv_skb(rc, sk);
return -1;
}
11.3.8 Monitoring: UDP protocol layer statistics
以下文件可以获取非常有用的 UDP 统计:
/proc/net/snmp
/proc/net/udp
/proc/net/snmp
监控 UDP 协议统计:/proc/net/snmp
$ cat /proc/net/snmp | grep Udp\:
Udp: InDatagrams NoPorts InErrors OutDatagrams RcvbufErrors SndbufErrors
Udp: 16314 0 0 17161 0 0
Much like the detailed statistics found in this file for the IP protocol, you will need to read the protocol layer source to determine exactly when and where these values are incremented.
InDatagrams: Incremented when recvmsg was used by a userland program to read datagram. Also incremented when a UDP packet is encapsulated and sent back for processing.
NoPorts: Incremented when UDP packets arrive destined for a port where no program is listening.
InErrors: Incremented in several cases: no memory in the receive queue, when a bad checksum is seen, and if sk_add_backlog fails to add the datagram.
OutDatagrams: Incremented when a UDP packet is handed down without error to the IP protocol layer to be sent.
RcvbufErrors: Incremented when sock_queue_rcv_skb reports that no memory is available; this happens if sk->sk_rmem_alloc is greater than or equal to sk->sk_rcvbuf.
SndbufErrors: Incremented if the IP protocol layer reported an error when trying to send the packet and no error queue has been setup. Also incremented if no send queue space or kernel memory are available.
InCsumErrors: Incremented when a UDP checksum failure is detected. Note that in all cases I could find, InCsumErrors is incrememnted at the same time as InErrors. Thus, InErrors - InCsumErros should yield the count of memory related errors on the receive side.
监控 UDP socket 统计:/proc/net/udp
$ cat /proc/net/udp
sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode ref pointer drops
515: 00000000:B346 00000000:0000 07 00000000:00000000 00:00000000 00000000 104 0 7518 2 0000000000000000 0
558: 00000000:0371 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 7408 2 0000000000000000 0
588: 0100007F:038F 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 7511 2 0000000000000000 0
769: 00000000:0044 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 7673 2 0000000000000000 0
812: 00000000:006F 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 7407 2 0000000000000000 0
The first line describes each of the fields in the lines following:
sl: Kernel hash slot for the socketlocal_address: Hexadecimal local address of the socket and port number, separated by :.rem_address: Hexadecimal remote address of the socket and port number, separated by :.st: The state of the socket. Oddly enough, the UDP protocol layer seems to use some TCP socket states. In the example above, 7 is TCP_CLOSE.tx_queue: The amount of memory allocated in the kernel for outgoing UDP datagrams.rx_queue: The amount of memory allocated in the kernel for incoming UDP datagrams.tr, tm->when, retrnsmt: These fields are unused by the UDP protocol layer.uid: The effective user id of the user who created this socket.timeout: Unused by the UDP protocol layer.inode: The inode number corresponding to this socket. You can use this to help you determine which user process has this socket open. Check /proc/[pid]/fd, which will contain symlinks to socket[:inode].ref: The current reference count for the socket.pointer: The memory address in the kernel of the struct sock.drops: The number of datagram drops associated with this socket. Note that this does not include any drops related to sending datagrams (on corked UDP sockets or otherwise); this is only incremented in receive paths as of the kernel version examined by this blog post.
打印这些信息的代码见net/ipv4/udp.c.
11.4 将数据放到 socket 队列
网络数据通过 sock_queue_rcv 进入 socket 的接收队列。这个函数在将数据报最终送到接收 队列之前,会做几件事情:
- 检查 socket 已分配的内存,如果超过了 receive buffer 的大小,丢弃这个包并更新计数
- 应用
sk_filter,这允许 BPF(Berkeley Packet Filter)过滤器在 socket 上被应用 - 执行
sk_rmem_scedule,确保有足够大的 receive buffer 接收这个数据报 - 执行
skb_set_owner_r,这会计算数据报的长度并更新sk->sk_rmem_alloc计数 - 调用
__skb_queue_tail将数据加到队列尾端
最后,所有在这个 socket 上等待数据的进程都收到一个通知通过 sk_data_ready 通知处理 函数。
这就是一个数据包从到达机器开始,依次穿过协议栈,到达 socket,最终被用户程序读取 的过程。
12 其他
还有一些值得讨论的地方,放在前面哪里都不太合适,故统一放到这里。
12.1 打时间戳 (timestamping)
前面提到,网络栈可以收集包的时间戳信息。如果使用了 RPS 功能,有相应的 sysctl 参数 可以控制何时以及如何收集时间戳;更多关于 RPS、时间戳,以及网络栈在哪里完成这些工 作的内容,请查看前面的章节。一些网卡甚至支持在硬件上打时间戳。
如果你想看内核网络栈给收包增加了多少延迟,那这个特性非常有用。
内核关于时间戳的文档 非常优秀,甚至还包括一个示例程序和相应的 Makefile,有兴趣的话可以上手试试。
使用 ethtool -T 可以查看网卡和驱动支持哪种打时间戳方式:
$ sudo ethtool -T eth0
Time stamping parameters for eth0:
Capabilities:
software-transmit (SOF_TIMESTAMPING_TX_SOFTWARE)
software-receive (SOF_TIMESTAMPING_RX_SOFTWARE)
software-system-clock (SOF_TIMESTAMPING_SOFTWARE)
PTP Hardware Clock: none
Hardware Transmit Timestamp Modes: none
Hardware Receive Filter Modes: none
从上面这个信息看,该网卡不支持硬件打时间戳。但这个系统上的软件打时间戳,仍然可以 帮助我判断内核在接收路径上到底带来多少延迟。
12.2 socket 低延迟选项:busy polling
socket 有个 SO_BUSY_POLL 选项,可以让内核在阻塞式接收(blocking receive) 的时候做 busy poll。这个选项会减少延迟,但会增加 CPU 使用量和耗电量。
重要提示:要使用此功能,首先要检查你的设备驱动是否支持。Linux 内核 3.13.0 的 igb 驱动不支持,但 ixgbe 驱动支持。如果你的驱动实现(并注册)了 struct net_device_ops(前面介绍过了)的 ndo_busy_poll 方法,那它就是支持 SO_BUSY_POLL。
Intel 有一篇非常好的文章介绍其原理。
对单个 socket 设置此选项,需要传一个以微秒(microsecond)为单位的时间,内核会 在这个时间内对设备驱动的接收队列做 busy poll。当在这个 socket 上触发一个阻塞式读请 求时,内核会 busy poll 来收数据。
全局设置此选项,可以修改 net.core.busy_poll 配置(毫秒,microsecond),当 poll 或 select 方 法以阻塞方式调用时,busy poll 的时长就是这个值。
12.3 Netpoll:特殊网络场景支持
Linux 内核提供了一种方式,在内核挂掉(crash)的时候,设备驱动仍然可以接收和发送数 据,相应的 API 被称作 Netpoll。这个功能在一些特殊的网络场景有用途,比如最著名的两个例子: kgdb和 netconsole。
大部分驱动都支持 Netpoll 功能。支持此功能的驱动需要实现 struct net_device_ops 的 ndo_poll_controller 方法(回调函数,探测驱动模块的时候注册的,前面介绍过)。
当网络设备子系统收包或发包的时候,会首先检查这个包的目的端是不是 netpoll。
例如,我们来看下__netif_receive_skb_core,net/dev/core.c:
static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc)
{
/* ... */
/* if we've gotten here through NAPI, check netpoll */
if (netpoll_receive_skb(skb))
goto out;
/* ... */
}
设备驱动收发包相关代码里,关于 netpoll 的判断逻辑在很前面。
Netpoll API 的消费者可以通过 netpoll_setup 函数注册 struct netpoll 变量,后者有收 包和发包的 hook 方法(函数指针)。
如果你对使用 Netpoll API 感兴趣,可以看看 netconsole 的驱动 ,Netpoll API 的头文件 include/linux/netpoll.h ,以及这个精 彩的分享。
12.4 SO_INCOMING_CPU
SO_INCOMING_CPU 直到 Linux 3.19 才添加, 但它非常有用,所以这里讨论一下。
使用 getsockopt 带 SO_INCOMING_CPU 选项,可以判断当前哪个 CPU 在处理这个 socket 的网 络包。你的应用程序可以据此将 socket 交给在期望的 CPU 上运行的线程,增加数据本地性( data locality)和 CPU 缓存命中率。
在提出 SO_INCOMING_CPU 的邮件列表 里有一个简单示例框架,展示在什么场景下使用这个功能。
12.5 DMA 引擎
DMA engine (直接内存访问引擎)是一个硬件,允许 CPU 将很大的复制操作(large copy operations)offload(下放)给它。这样 CPU 就从数据拷贝中解放出来,去做其他工作,而 拷贝就交由硬件完成。合理的使用 DMA 引擎(代码要利用到 DMA 特性)可以减少 CPU 的使用量 。
Linux 内核有一个通用的 DMA 引擎接口,DMA engine 驱动实现这个接口即可。更多关于这个接 口的信息可以查看内核源码的文档 。
内核支持的 DMA 引擎很多,这里我们拿 Intel 的IOAT DMA engine为例来看一下。
Intel’s I/O Acceleration Technology (IOAT)
很多服务器都安装了Intel I/O AT bundle ,其中包含了一系列性能优化相关的东西,包括一个硬件 DMA 引擎。可以查看 dmesg 里面有 没有 ioatdma,判断这个模块是否被加载,以及它是否找到了支持的硬件。
DMA 引擎在很多地方有用到,例如 TCP 协议栈。
Intel IOAT DMA engine 最早出现在 Linux 2.6.18,但随后 3.13.11.10 就禁用掉了,因为有一些 bug,会导致数据损坏。
3.13.11.10 版本之前的内核默认是开启的,将来这些版本的内核如果有更新,可能也会禁用掉。
直接缓存访问 (DCA, Direct cache access)
Intel I/O AT bundle 中的另一个有趣特性是直接缓存访问(DCA)。
该特性允许网络设备(通过各自的驱动)直接将网络数据放到 CPU 缓存上。至于是如何实现 的,随各家驱动而异。对于 igb 的驱动,你可以查看 igb_update_dca 和 igb_update_rx_dca 这两个函数的实现。igb 驱动使用 DCA,直接写硬件网卡的一个 寄存器。
要使用 DCA 功能,首先检查你的 BIOS 里是否打开了此功能,然后确保 dca 模块加载了, 还要确保你的网卡和驱动支持 DCA。
Monitoring IOAT DMA engine
如上所说,如果你不怕数据损坏的风险,那你可以使用 ioatdma 模块。监控上,可以看几 个 sysfs 参数。
例如,监控一个 DMA 通道(channel)总共 offload 的 memcpy 操作次数:
$ cat /sys/class/dma/dma0chan0/memcpy_count
123205655
类似的,一个 DMA 通道总共 offload 的字节数:
$ cat /sys/class/dma/dma0chan0/bytes_transferred
131791916307
Tuning IOAT DMA engine
IOAT DMA engine 只有在包大小超过一定的阈值之后才会使用,这个阈值叫 copybreak。 之所以要设置阈值是因为,对于小包,设置和使用 DMA 的开销要大于其收益。
调整 DMA engine copybreak 参数:
$ sudo sysctl -w net.ipv4.tcp_dma_copybreak=2048
默认值是 4096。
13 总结
Linux 网络栈很复杂。
对于这样复杂的系统(以及类似的其他系统), 如果不能在更深的层次理解它正在做什么,就不可能做监控和调优。 当遇到网络问题时,你可能会在网上搜到一些 sysctl.conf 最优实践一类的东西,然后应 用在自己的系统上,但这并不是网络栈调优的最佳方式。
监控网络栈需要从驱动开始,逐步往上,仔细地在每一层统计网络数据。 这样你才能清楚地看出哪里有丢包(drop),哪里有收包错误(errors),然后根据导致错 误的原因做相应的配置调整。
不幸的是,这项工作并没有捷径。
14 额外讨论和帮助
需要一些额外的关于网络栈的指导(navigating the network stack)?对本文有疑问,或有 相关内容本文没有提到?以上问题,都可以发邮件给我们, 以便我们知道如何提供帮助。
15 相关文章
如果你喜欢本文,你可能对下面这些底层技术文章也感兴趣:
- Monitoring and Tuning the Linux Networking Stack: Sending Data
- The Definitive Guide to Linux System Calls
- How does strace work?
- How does ltrace work?
- APT Hash sum mismatch
- HOWTO: GPG sign and verify deb packages and APT repositories
- HOWTO: GPG sign and verify RPM packages and yum repositories


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类