BeeGFS架构笔记
Metadata Distribution
Metadata is distributed across the metadata nodes on a per directory basis. The content of a directory is always stored on one metadata node. A metadata node is chosen at random for each directory.
-
Root Node: One of the metadata servers in BeeGFS will become a special root metadata node, which serves as an initial coordinator and as a guide to the system for clients. (
beegfs-ctlcan be used to find out which node has been chosen to be the root node). The management daemon saves the root node ID when a root node was chosen, so the election of the root node only happens during the very first startup of the system.
Capacity Pools
Storage targets are chosen depending on the free space available when new files are created, in order to balance the disk space usage. Targets are automatically placed in different capacity pools depending on their free space. There are three pools: Normal, Low, and Emergency. The target chooser algorithm prefers targets from the Normal pool, and falls back to the Low and Emergency pools only when the requested striping cannot be achieved otherwise. The disk space limits are the same for all targets and can be configured on the management daemon.
Storage Pools
Storage pools allow the cluster admin to group targets and mirror buddy groups together in different classes. For instance, there can be one pool consisting of fast, but small solid state drives, and another pool for bulk storage, using big but slower spinning disks. Pools can have descriptive names, making it easy to remember which pool to use without looking up the storage targets in the pool. The SSD pool could be named “fast” and the other “bulk”.
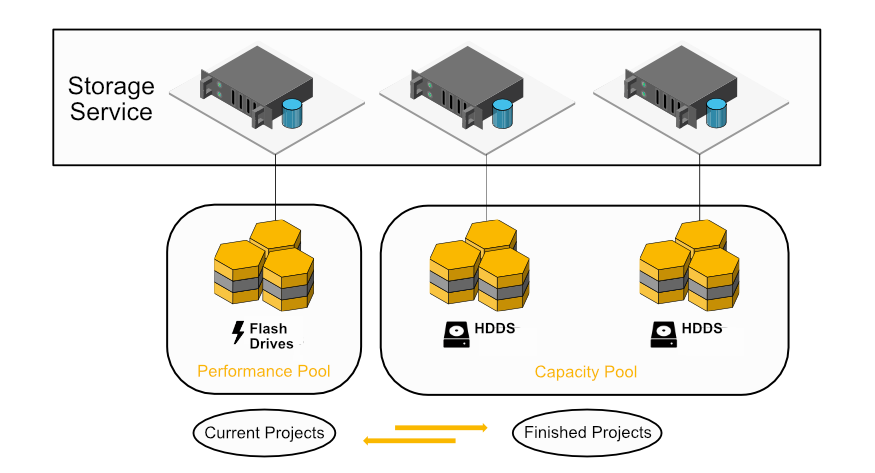
When a file is created by an application or user, they can choose which storage pool the file contents are stored in. Since the concept of storage pools is orthogonal to the file system’s directory structure, even files in the same directory can be in different storage pools.
The most intuitive way to expose the storage pools to the user, however, is using a single directory per pool, giving the user the opportunity to assign files to pools just by sorting them into different directories. More fine-grained control can be exerted using the command line tool beegfs-ctl, which allows data placement down to the file level. Usually, the user will want to move the current working project to the fast pool and keep it there until it is finished.
A storage pool consists of one or multiple storage targets. If storage mirroring is enabled, both targets of a mirror buddy group must be in the same pool, and the mirror buddy group itself must also be in the same storage pool.
Quota settings can be configured per Storage Pool.
See also
Mirroring
Warning
Mirroring is not a replacement for backups. If files are accidentally deleted or overwritten by a user or process, mirroring won’t help you to bring the old file back. You are still responsible for doing regular backups of your important bits.
BeeGFS provides support for metadata and file contents mirroring. Mirroring capabilities are integrated into the normal BeeGFS services, so that no separate services or third-party tools are needed. Both types of mirroring (metadata mirroring and file contents mirroring) can be used independently of each other. Mirroring also provides some high availability features.
Storage and metadata mirroring with high availability is based on so-called buddy groups. In general, a buddy group is a pair of two targets that internally manage data replication between each other. The buddy group approach allows one half of all servers in a system to fail while all data is still accessible. It can also be used to put buddies in different failure domains or different fire domains, e.g., different racks or different server rooms.
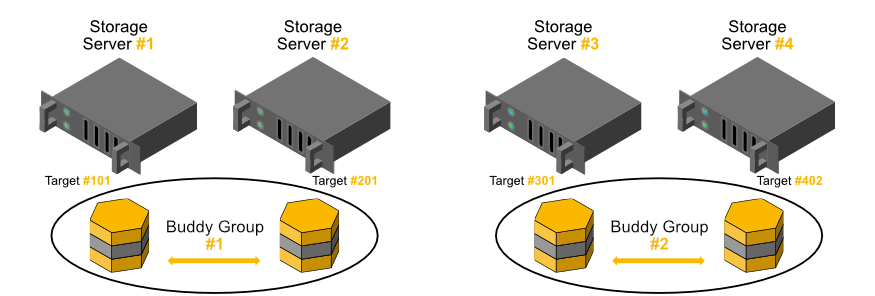
Storage Buddy Mirroring: 4 Servers with 1 Target per Server
Storage server buddy mirroring can also be used with an odd number of storage servers. This works, because BeeGFS buddy groups are composed of individual storage targets, independent of their assignment to servers, as shown in the following example graphic with three servers and two storage targets per server. (In general, a storage buddy group could even be composed of two targets that are attached to the same server.)
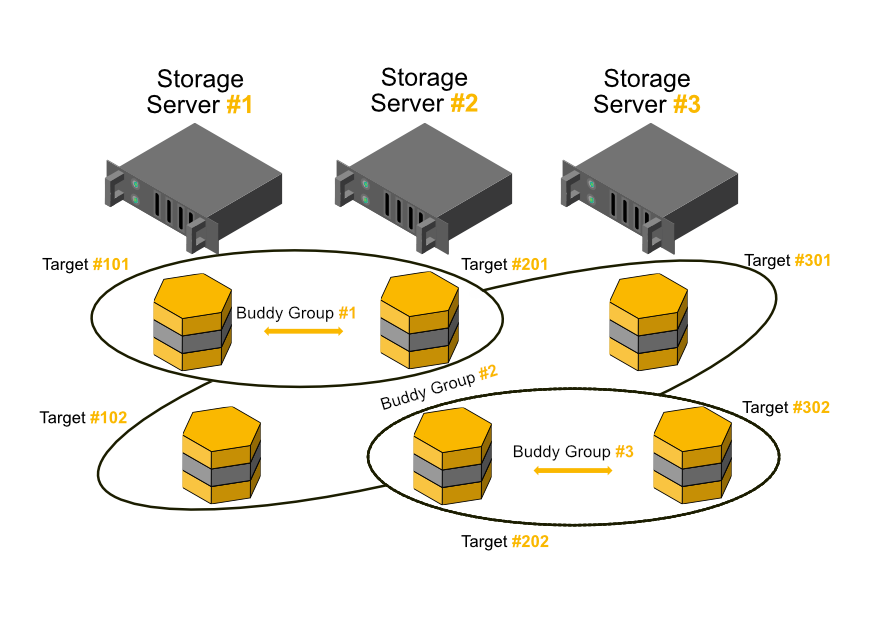
Storage Buddy Mirroring: 3 Servers with 2 Targets per Server
Note that this is not possible with metadata servers since there are no metadata targets in BeeGFS. An even number of metadata servers is needed so that every metadata server can belong to a buddy group.
In normal operation, one of the storage targets (or metadata servers) in a buddy group is considered to be the primary, whereas the other is the secondary. Modifying operations will always be sent to the primary first, which takes care of the mirroring process. File contents and metadata are mirrored synchronously, i.e. the client operation completes after both copies of the data were transferred to the servers.
If the primary storage target or metadata server of a buddy group is unreachable, it will get marked as offline, and a failover to the secondary will be issued. In this case, the former secondary will become the new primary. Such a failover is transparent and happens without any loss of data for running applications. The failover will happen after a short delay, to guarantee consistency of the system while the change information is propagated to all nodes. This short delay also avoids unnecessary resynchronizations if a service is simply restarted, e.g., in case of a rolling update. For more information on possible target states see here: Target States
Please note that targets and servers that belong to a buddy group are also still available to store unmirrored data, so it is easily possible to have a filesystem which only mirrors a certain subset of the data.
A failover of a buddy group can only happen if the BeeGFS Management service is running. That means that no failover will occur if the node with the beegfs-mgmtd service crashes. Therefore, it is recommended to have the beegfs-mgmtd service running on a different machine. However, it is not necessary to have a dedicated server for the beegfs-mgmtd service, as explained here.
Setup of mirroring is described in Mirroring.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号