Linux源码笔记-网络栈-接收流程
(1)硬中断(中断处理的前半部)
XXX_rx_interrupt
napi_schedule
_napi_schedule
_raise_softirq_irqoff(NET_RX_SOFTIRQ)
(2)软中断(中断处理的后半部)
// 通过这种共享的 <伪napi_struct> 方式使得non-napi设备很好的融入了NAPI框架,
// 使得non-napi和NAPI设备对下半部 net_rx_action() 是透明的。
// 软中断
// NET_RX_SOFTIRQ
net_rx_action
// 开始轮询
napi_poll
//////////////////////////////////////////
// 在这里调用驱动的 napi_struct->poll 函数,
// 如果驱动有支持NAPI,会定义并初始化这个poll函数,
// 对于非NAPI驱动,它默认的poll函数是process_backlog
// 对于支持NAPI的驱动,由netif_napi_add给中断注册napi_poll回调
napi_struct->poll
(2.2)软中断:对于不支持NAPI的驱动,
操作系统默认的poll函数是process_backlog
process_backlog
_netif_receive_skb
_netif_receive_skb_core
deliver_skb
packet_type->func
arp_rcv
ip_rcv
(2.3)软中断:对于支持NAPI的驱动:
(2.3.1)NAPI的Poll函数:
(a)通过netif_napi_add向操作系统注册本驱动的poll函数:
//支持NAPI
// netif_napi_add(dev, &cell->napi, gro_cell_poll, 64);
gro_cell_poll
napi_gro_receive
napi_complete
(b)BCM网卡注册的NAPI的Poll函数:
// (B) 对于支持NAPI的驱动,
// netif_napi_add(dev, &priv->napi, bcm_sysport_poll, 64)
bcm_sysport_poll
bcm_sysport_desc_rx
napi_gro_receive
napi_complete
(c)i40e网卡注册的NAPI的Poll函数:
// netif_napi_add(vsi->netdev, &q_vector->napi,i40e_napi_poll, NAPI_POLL_WEIGHT);
i40e_napi_poll
i40e_clean_rx_irq
i40e_receive_skb
napi_gro_receive
napi_complete
(d)tg3网卡注册的NAPI的Poll函数:
// (B) 对于支持NAPI的驱动,
// netif_napi_add(tp->dev, &tp->napi[0].napi, tg3_poll, 64)
tg3_poll
tg3_poll_work
tg3_rx
napi_gro_receive
napi_complete
(2.3.2)NAPI的组装函数:
它主要是将分片的skb进行组装,然后形成一个新的skb
如果没有gro,则小的段会被一个个送到协议栈,
有了gro之后,就会在接收端将tso切好的数据包组合成大包再传递给协议栈。
然后GRO什么时候会将数据feed进协议栈呢,这里会有两个退出点,
一个是在napi_skb_finish里,他会通过判断__napi_gro_receive的返回值,来决定是需要将数据包立即feed进协议栈还是保存起来,
一个是当napi的循环执行完毕时,也就是执行napi_complete的时候,
napi_gro_receive
dev_gro_receive
packet_offload->callbacks.gro_receive
inet_gro_receive
net_offload->callbacks.gro_receive
//如果本次NAPI已经完毕,是时候执行flush GRO packet 了,
//那么napi_gro_complete 调用netif_receive_skb_internal
napi_gro_complete
netif_receive_skb_internal
//一旦 dev_gro_receive 完成,napi_skb_finish 就会被调用,
// (2)如果当dev_gro_receive 返回 GRO_NORMAL的时候
// 那么 napi_skb_finish 会调用 netif_receive_skb_internal
napi_skb_finish
netif_receive_skb_internal
(3)网络栈
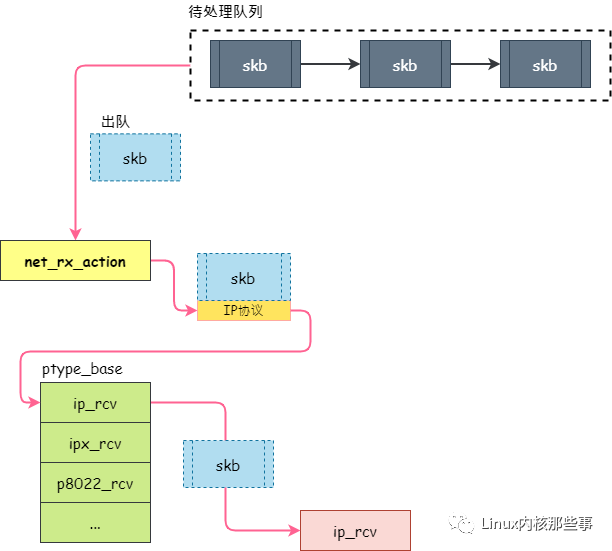

(2.3.2)skb组装完毕入队列:
// (A) 如果 RPS 被启用,那么会调用enqueue_to_backlog
enqueue_to_backlog
softnet_data->input_pkt_queue
// (B) 如果 RPS 没启用,那么会调用__netif_receive_skb,
_netif_receive_skb
_netif_receive_skb_core
deliver_skb
packet_type->func
ip_rcv
net_device->rx_handler
br_handle_frame
bond_handle_frame
(2.3.3)skb组装完毕入队列:5.10内核
netif_receive_skb
netif_receive_skb_internal
__netif_receive_skb
__netif_receive_skb_one_core
__netif_receive_skb_core
deliver_skb
# 本地协议栈处理
packet_type->func
ip_rcv
sk_buff->dev->rx_handler
# 桥处理
br_handle_frame
////////////////////////////////////////////////
__netif_receive_skb_core函数主要有几个处理:
(1) vlan报文的处理,主要是循环把vlan头剥掉;
(2) 交给 net_device->rx_handler 处理,例如OVS、linux bridge等;
(3) ptype_all处理,例如抓包程序、raw socket等;
(4) ptype_base处理,交给协议栈处理,例如ip、arp、rarp等;
(2.3.4)桥处理:5.10内核
br_handle_frame
br_handle_frame_finish
br_forward
br_forward_finish
br_dev_queue_push_xmit

 浙公网安备 33010602011771号
浙公网安备 33010602011771号