
mysql常用插入sql
insert into、insert ignore into、replace into区别
| 指令 | 不存在 | 已存在 | 举例 |
| insert | 插入 | 报错 | insert into stu(name, age) values('小明', 23); |
| insert ignore | 插入 | 忽略 | insert ignore into stu(name, age) values('小明', 23); |
| replace into | 插入 | 删除原记录后插入 | replace into stu(name, age) values('小明', 23); |
表要求:有PrimaryKey,或者unique索引
测试
建表语句:

create table if not exists stu ( id int auto_increment primary key, name varchar(32) not null, age int not null, address varchar(64) null, constraint stu_name_uindex unique (name) );
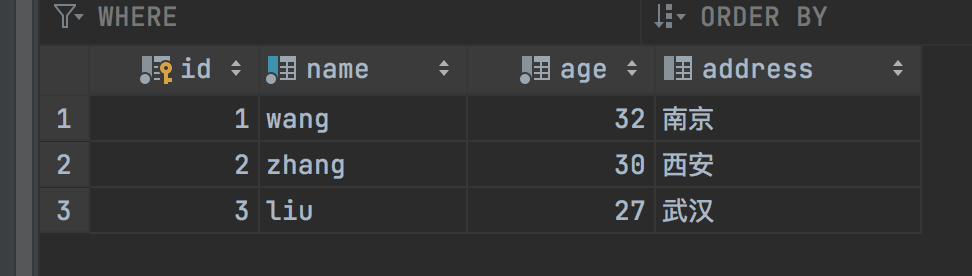
插入几条数据
insert into stu (name, age, address) values ('wang', 32, '南京'), ('zhang', 30, '西安'), ('liu', 27, '武汉');
查询后:
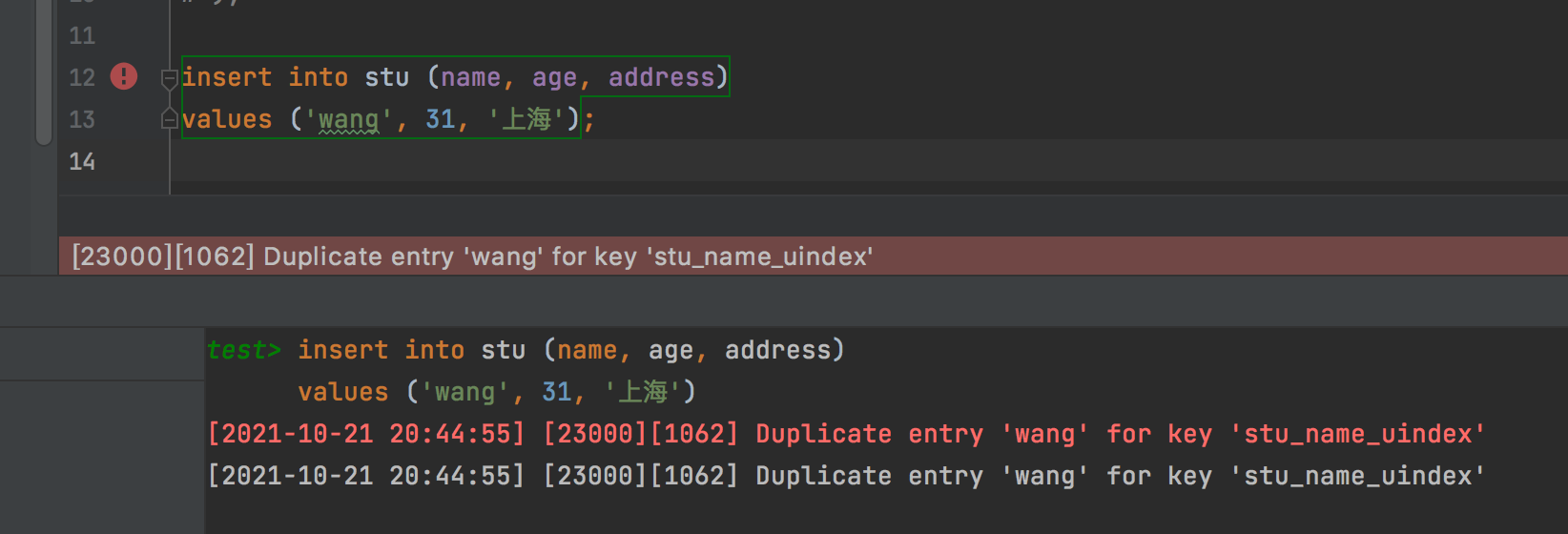
insert
因为name列为唯一索引,所以如果后面再插入的记录与数据库中已经存在的记录存在名称相同的则会报错,不存在执行插入。
replace
已存在替换,删除原来的记录,添加新的记录。
执行该语句后
replace into stu (name, age) values ('wang', 35);
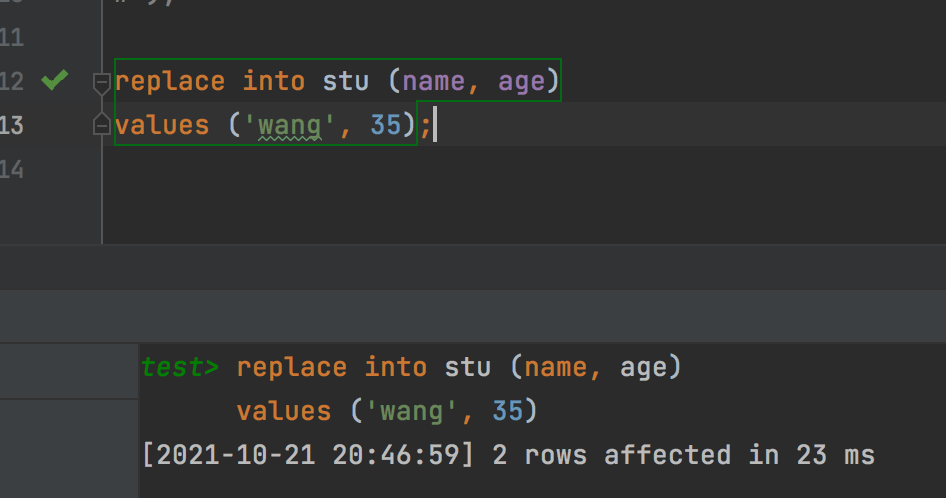
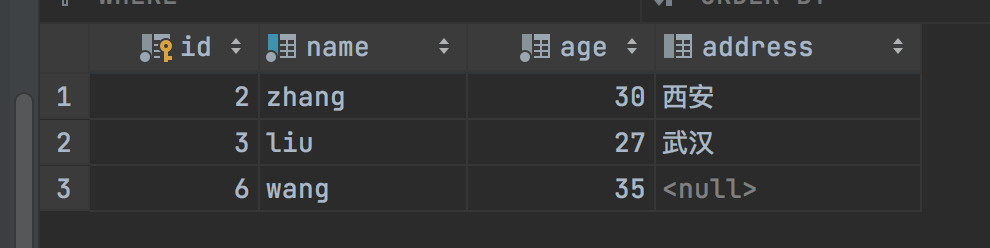
会发现name为wang的数据已经变更为新的数据了,也就是先将原来的name为wang的记录删除后,再插入新的记录。可以看到id=1的记录已经不在了,现在name为wang的是id=6的记录。注意replace并不是直接update原来记录。
insert igonre
使用insert ignore into执行插入时,如果该记录已经存在则会忽略,不存在则执行插入。
insert ignore into stu (name, age, address) values ('wang', 23, '北京');
该语句执行后,再次查询发现数据集并没有发生变化
如果插入库中不存在的记录,则会执行插入操作
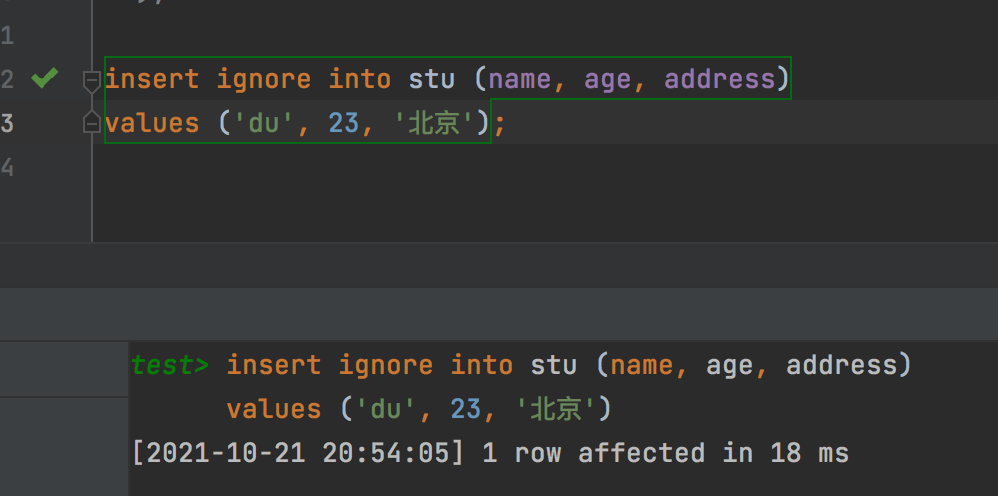
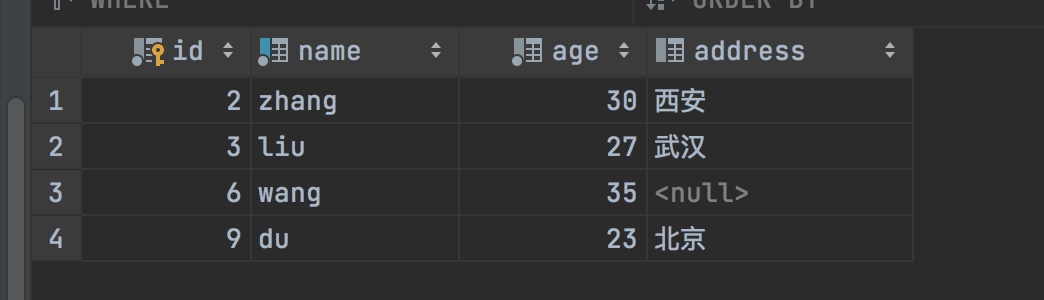
可以看到name='du'的记录已经插入到库中了。
ON DUPLICATE KEY UPDATE
该语法的用法是针对如果插入的记录,数据库中唯一约束列的该值不存在则执行插入操作,如果数据库中已经存在该记录,则修改该记录。
还以上面的数据集举例:
现在使用该语法插入几条记录:
insert into stu (name, age, address) values ('wang', 50, '乌鲁木齐'), ('liu', 66, '重庆'), ('zhao', 44, '拉萨') on duplicate key update age = VALUES(age), address = VALUES(address);
按照上面讲解的意思,执行该语句后,因为name为唯一约束,所以name='wang'的记录,id=6的age和address将会分别修改为50和乌鲁木齐,name='liu'的记录,id=3的age和address将会修改为66和重庆,而name='zhao'的因为数据集中不存在该记录,所以该记录将会插入。现在执行下看下效果
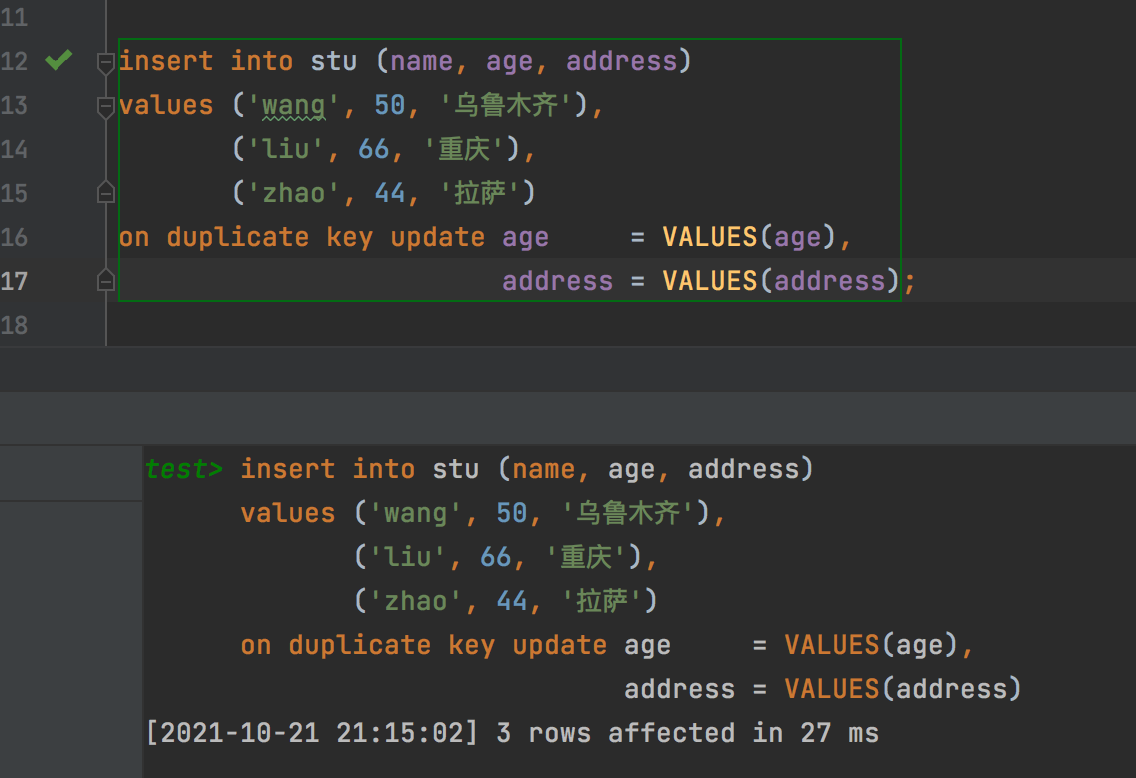
执行后的结果集:
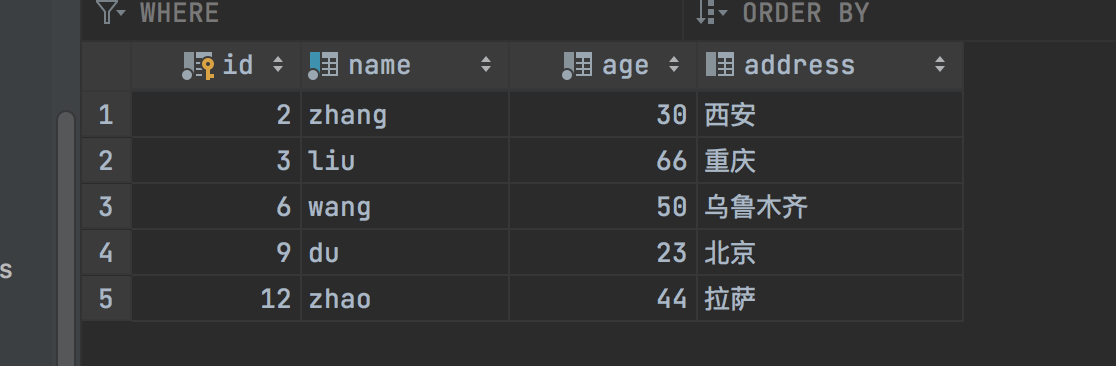
可以看到,已经成功了,实现了想要的效果,不存在的记录插入,已经存在的记录执行修改。
本文作者:wang_longan
本文链接:https://www.cnblogs.com/longan-wang/p/15384286.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步