
java之xml字符串转map、object转xml字符串
最近由于进行微信公众号开发,了解了一下java的一些xml操作。
所以本篇文章简单介绍xml字符串转map和object转xml字符串。
由于与微信交互的过程中一些数据微信是以xml字符串形式发送到我们服务器,然后将处理好的对象转成xml字符串发送到微信服务器。
所以需要封装个专门的工具类来处理,我建了一个类XmlUtil,用来实现上述功能。
jar包准备:
<!-- 解析xml --> <dependency> <groupId>dom4j</groupId> <artifactId>dom4j</artifactId> <version>1.6.1</version> </dependency> <dependency> <groupId>com.thoughtworks.xstream</groupId> <artifactId>xstream</artifactId> <version>1.4.9</version> </dependency>
xml字符串转map:
xml字符串的获取:从请求request的输入流中读取Document文档对象。
用SAXReader获取List<Element>,遍历,将当前迭代元素的name和text作为键值对存入map。
具体代码如下:
/** * xml转map * * @param request * @return * @throws IOException */ public static Map<String, String> xml2Map(HttpServletRequest request) throws IOException { Map<String, String> map = new HashMap<String, String>(); SAXReader reader = new SAXReader(); InputStream is = null; Document doc = null; try { is = request.getInputStream(); doc = reader.read(is); Element root = doc.getRootElement(); List<Element> list = root.elements(); for (Element e : list) { map.put(e.getName(), e.getText()); } } catch (IOException e) { e.printStackTrace(); } catch (DocumentException e) { e.printStackTrace(); } finally { is.close(); } return map; }
接下来是XStream部分(比较重要):
private static String cdata_prefix = "<![CDATA[";
private static String cdata_suffix = "]]>";
/**
* 文本消息对象转Xml
*
* @param 对象
* @param 对象的类型
* @return
*/
public static String textMessage2Xml(Object object,Class<?> objectTargetClass) {
XStream xStream = new XStream(new XppDriver() {
/**
* 对xml标签里面值含有CDATA会被转义,比如<会被转义成<
* 以下代码为了能加入不被转义的CDATA
*/
@Override
public HierarchicalStreamWriter createWriter(Writer out) {
PrettyPrintWriter ppw = new PrettyPrintWriter(out) {
Boolean isCdata = false;
Class<?> targetClazz = null;
Class<?> superClass = null;
List<String> super_class_field_names = new ArrayList<String>();
List<String> target_class_field_names = new ArrayList<String>();
@Override
public void startNode(String name, @SuppressWarnings("rawtypes") Class clazz) {
super.startNode(name, clazz);
/**
* System.out.println(textMessage.getCreateTime()+",name:"+name+",clazz:"+clazz);
* 输出结果
* 173413984,name:xml,clazz:class com.entity.TextMessage
* 173413984,name:ToUserName,clazz:class java.lang.String
* 173413984,name:FromUserName,clazz:class java.lang.String
* 173413984,name:CreateTime,clazz:class java.lang.String
* 173413984,name:MsgType,clazz:class java.lang.String
* 173413984,name:Content,clazz:class java.lang.String
*
* name为xml时,clazz为xStream.alias("xml", textMessage.getClass())声明的类
*/
try {
if ("xml".equals(name)) {
initParam(clazz);
} else {
if (super_class_field_names.contains(name)) {
isCdata=superClass.getDeclaredField(StringUtil.firstLowerCase(name)).isAnnotationPresent(CDATA_Annotaion.class);
} else if (target_class_field_names.contains(name)) {
isCdata=targetClazz.getDeclaredField(StringUtil.firstLowerCase(name)).isAnnotationPresent(CDATA_Annotaion.class);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
private void initParam(@SuppressWarnings("rawtypes") Class clazz) {
targetClazz = clazz;
// 目标类属性名保存
Field[] targetFields = targetClazz.getDeclaredFields();
for (Field f : targetFields) {
target_class_field_names.add(StringUtil.firstUpCase(f.getName()));
}
// 父类属性名保存到list中
superClass = targetClazz.getSuperclass();
if (!superClass.equals(Object.class)) {
Field[] superFields = superClass.getDeclaredFields();
for (Field f : superFields) {
super_class_field_names.add(StringUtil.firstUpCase(f.getName()));
}
}
}
@Override
protected void writeText(QuickWriter writer, String text) {
if (isCdata) {
writer.write(cdata_prefix + text + cdata_suffix);
} else {
writer.write(text);
}
}
};
return ppw;
}
});
xStream.alias("xml", objectTargetClass);
//开启注解转换(别名转换)
xStream.processAnnotations(objectTargetClass);
return xStream.toXML(object);
}
解释下上面代码:
XStream xStream = new XStream(new XppDriver() {...})
这一步中间new了个XppDriver,关于XppDriver的介绍,我查找资料后,理解为一种解析输入输出的驱动。

因为我们要在写的时候做点处理,所以重写了public HierarchicalStreamWriter createWriter(Writer out){...}方法:
PrettyPrintWriter ppw = new PrettyPrintWriter(out) {...}中重写了
@Override
public void startNode(String name, @SuppressWarnings("rawtypes") Class clazz) {...}方法
和
@Override
protected void writeText(QuickWriter writer, String text) {...}方法
writeText是最后写处理,比如我要根据isCdata判断是否添加<![CDATA[]]>,isCdata为true就添加,false不添加
startNode是在节点开始的时候加入自己的代码逻辑,比如我在这边判断实体类的属性上面是否有@CDATA_Annotation,如果有我就将isCdata赋值为true,反之false。
每条实体类属性都是先startNode->writeText,比如实体类有3条属性,在startNode时候添加一条system.out.printlin语句看情况,就会发现输出3次。
/**
* System.out.println(textMessage.getCreateTime()+",name:"+name+",clazz:"+clazz);
* 输出结果
* 173413984,name:xml,clazz:class com.entity.TextMessage
* 173413984,name:ToUserName,clazz:class java.lang.String
* 173413984,name:FromUserName,clazz:class java.lang.String
* 173413984,name:CreateTime,clazz:class java.lang.String
* 173413984,name:MsgType,clazz:class java.lang.String
* 173413984,name:Content,clazz:class java.lang.String
*
* name为xml时,clazz为xStream.alias("xml", textMessage.getClass())声明的类
*/
我例子中的输出结果,类是TextMessage,里面有条属性content,剩下4条属于继承来的,做了一些处理把父类的也取到了,173413984是TextMessage类的createTime属性的值。
可以看出后面6条都是属于同一个对象,至于第一条name为xml是因为下面

生声明了类的别名为xml
解释完了上面代码,现在说下注意事项:
可能有细心的人注意到了,我用了首字母大小写转换,而且控制台输出的时候name是大写,因为我在实体类上加了XStream别名
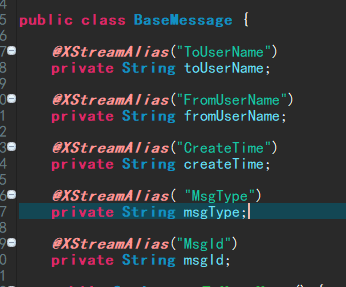
所以startNode传进来的name会是首字母大写的形式,所以在反射的时候将其转换成了小写,为什么用别名是因为不想将实体类属性名变成首字母大写,那样不规范(普通类的类名就是大写的,会混乱),所以在不改变实体类的情况下用了别名。
如果用了别名,一定要记住在toXML方法之前一定要开启注解转换

StringUtil(首字母大写和首字母小写的方法):
public class StringUtil {
public static String firstUpCase(String str) {
String result=str.substring(0,1).toUpperCase()+str.substring(1,str.length());
return result;
}
public static String firstLowerCase(String str){
String result=str.substring(0,1).toLowerCase()+str.substring(1,str.length());
return result;
}
}
注解CDATA_Annotaion:
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Inherited;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Documented
@Retention(value = RetentionPolicy.RUNTIME)
@Target(value = { ElementType.FIELD })
@Inherited
public @interface CDATA_Annotaion {
}
有不同的欢迎提问,有错欢迎指出!谢谢大家浏览!
ps:每天记录一点,就算写的很差,以后自己找起来也方便,也能记得更牢。
附上github:https://github.com/617355557/code_pianduan/blob/master/XmlUtil.java
欢迎大家下载,转载~~~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号