Python 基础语法七——模块
注意事项:
(1)、在IDLE交互环境中,当输入导入模块名和电号 "." 之后,系统会将模块的函数罗列出来供我们选择;
(2)、可以通用 help(模块名) 查看模块的帮助信息,其中FUNCTIONS介绍了模块内置函数的使用方法;
(3)、不管你执行了多少次 import , 一个模块只会被导入一次;
(4)、导入模块后,我们就可用模块名称这个变量访问模块的函数等所有功能。
定义:一般写的代码以.py结尾的Python文件就是一个独立的模块,模块包含了对象定义和语句。
1、命名空间
定义:是一个包含了一个或多个变量名称和它们各自对应的对象值的字典。
python可以调用局部命名空间和全局命名空间里的变量。如果一个局部变量和一个全局变量重名,则在函数内部调用时局部变量会屏蔽全局变量。
如果要修改函数内的全局变量的值,必须使用global语句,否则会出错。
2、模块导入的三种方法
2.1 方法一:最常用
import module1,module2
导入模块后,就可以引用模块内的函数,语法格式:模块名.函数名
2.2 方法二:慎用
from module import 函数名
函数名如果有多个,可用逗号 “,” 隔开
函数名可用通配符 “ * ” 导出所有的函数
这种方法,导出的函数名容易和其他函数名称冲突,失去了模块命名空间的优势。
2.3 方法三:方便在程序中调用
import module as 新名字
3、自定义模块和包
3.1 自定义模块
方法和步骤:
在安装Python的目录下,新建一个以 .py 为后缀名的文件,然后编辑该文件。
自定义模块要注意:
(1)为了是 IDLE 能找到我们自定义模块,该模块要和调用的程序在同一目录下,否则在导入模块是会提示找不到模块的错误;
(2) 模块名要遵循 Python 变量命名规范,不要使用中文、特殊字符等。
(3) 自定义的模块名不要和系统内置的模块名相同,可以先在 IDLE 交互环境里先用 “import modle_name ” 命令检查,若成功说明系统已存在此模块,然后考更改自定义模块名。
3.2 自定义包
在大型项目开发中,有多个程序员协作共同开发一个项目,为了避免模块名重名,Python 引入了按目录来组织模块的方法,称为包(Package)。 包是一个分层级的文件目录结构,它定义了有模块及子包,以及子包下的子包等组成的命名空间。
自定义包需注意:
(1)每个包目录下面都会有一个_init_.py的文件,这个文件是必须存在的,否则,系统就把这个目录作为普通目录,而不是一个包。
(2)_init_.py 可以是一个空文件,也可以有 Python 代码,因为_init_.py就是一个模块,而它的模块名就是 mymodle。
(3)在 Python 中可以有多及目录,组成多层次的包结构。
4、安装第三方模块
实现方法:通过包管理工具 pip 来实现。
如 Win10系统:在安装Python 3.6.5 时勾选了 pip 和 Add Python to environment variables 两个选项。
在 “ cmd ” 命令或直接选中“ 命令提示符 ”
| pip < command > [options] | |
| command 命令 | 说明 |
| install | install packages |
| download | Download packages |
| uninstall | Uninstall packages |
| freeze | Output installed packages in requirements format |
安装第三方模块前的注意事项:
(1) 确保可以从命令提示符中的命令行运行Python。可以通过命令来检查: ![]()
![]()

(2)确保可以从命令行运行 pip;

(3) 确保 pip 、setuptools 和 wheel 是最新版本;
虽然 pip 单独地从预构建的二进制文件中安装就可以了,但是最新的 setuptools 和 wheel 的版本对于确保你也可以从源文件中安装是有用的。 可以运行一下命令测试:(会因为网络原因下不了,多试几次,实在不行离线安装)
python -m pip install --upgrade pip setuptools wheel
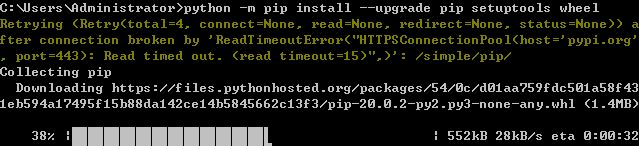
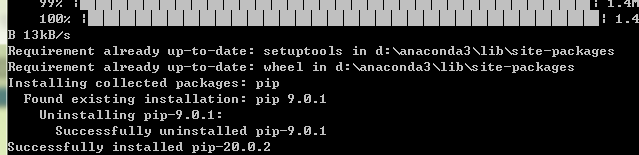
(4)创建一个虚拟环境,此项仅用与 Linux 系统,为可选项。运行以下命令:
python3 -m venv tutorial_env source tutorial_env/bin/activate
将在tutorial_env 子目录中创建一个新的虚拟环境,并配置当前 shell 以将其作默认的 Python 环境。
5、安装第三方模块实例
以从PyPI安装为例,使用 pip 从PyPI安装:pip 最常用的用法是从 Python 包中索引中使用需求说明符来安装。一般来说,需求说明符由项目名称和版本说明符组成。
Python 官网: https://www.pypi.org 可以查询、注册、发布的第三方库,包括包的历史版本号,支持的应用环境等包信息。
(1)在 Python 官网查询:web,得到包的名称(web3)和版本号 ( 4.3.0 ):
命令提示符: pip install web==4.3.0
( 2 ) 升级包:将已安装的项目升级到PyPIp的最新项目,
pip install --upgrade web3
( 3 ) 安装到用户站点
若要安装与当前用户隔离的包,请使用用户标志,通过运行以下命令:
pip install --user SomeProject
(4)安装需求文件
安装需求文件中指定的需求列表,如果没有则忽略。通过运行以下命令:
pip install -r requirements.txt
(5)在Python shell 环境中验证安装的第三方模块:
在IDLE shell 交互环境下使用 import 命令。
import web3
dir(web3)
6、模块应用实例
6.1 日期时间相关: datetime模块
datetime 是 Python处理日期和时间的标准模块。
(1)获取当前日期和时间:
from datetime import datetime
now = datetime.now()
print(now)4
1
from datetime import datetime2
3
now = datetime.now()4
print(now) (2)获取指定定日期和时间:
from datetime import datetime
now = datetime.now()
dt = datetime(2018,6,6,12,12) # 用指定日期时间创建datetime
print(now)
print(dt)6
1
from datetime import datetime2
3
now = datetime.now()4
dt = datetime(2018,6,6,12,12) # 用指定日期时间创建datetime5
print(now)6
print(dt) (3)datetime 转换为 timestamp 模块
在计算机中,时间实际上是用数字表示的。我们把1970年1月1日 00:00:00 UTC + 00:00 时区的时刻称为 epoch time , 记为 0 (1970年以前的时间为复数),当前时间就是相对 epoch time 的秒数,称为 timestamp 。
即:
timestamp = 0 = 1970-1-1 00:00:00 UTC+0:00
对应北京时间为:
timestamp = 0 = 1970-1-1 00:00:00 UTC+8:00
可见 timestamp 的值与时区毫无关系,因为 timestamp 一旦确定,其 UTC 时间就确定了,转换到任意时区的时间也是完全确定的,这就是为什么计算机存储的当前时间是以 timestamp 表示的,因为全球各地的计算机在任意时刻的 timestamp 都是完全相同的。
把一个datetime 类型转换为 timestamp 只需要简单调用 timestamp() 方法,如下所示代码:
from datetime import datetime
now = datetime.now()
dt = datetime(2018,6,6,12,12) # 用指定日期时间创建datetime
print(now)
print(dt)
print(dt.timestamp())8
1
from datetime import datetime2
3
now = datetime.now()4
dt = datetime(2018,6,6,12,12) # 用指定日期时间创建datetime5
6
print(now)7
print(dt)8
print(dt.timestamp()) Python 的 timestamp 是一个浮点数。如果有小数位,小数位表示毫秒数。某些编程语言(如Java 和 JavaScript)的 timestamp 使用整数表示毫秒,这种情况下只需要把timestamp 除以 1000 就得到 Python 的浮点表示方法。
(4) timestamp 转换为 datetime
要把 timestamp 转换 为 datetime,使用 datetime 提供的 fromtimestamp()
from datetime import datetime
now = datetime.now()
dt = datetime(2018,6,6,12,12) # 用指定日期时间创建datetime
print(now)
print(dt)
print(dt.timestamp())8
1
from datetime import datetime2
3
now = datetime.now()4
dt = datetime(2018,6,6,12,12) # 用指定日期时间创建datetime5
6
print(now)7
print(dt)8
print(dt.timestamp()) timestamp 是一个浮点数,它没有时区的概念,而 datetime 是有时区的,timsestamp 可以直接被转换到 UTC 标准时区的时间,使用 datetime 提供的 utcfromtimestamp() 方法。
(5)str 转换为 datetime:
用户输入的日期和时间是字符串,要处理日期和时间,首先必须把 str 转换为datetime 。转换方法通过 datetime 提供的 strptime() 方法来实现,如下列所示代码:
datee_test = datetime.strptime('2018-06-19 13:15:00', '%Y-%m-%d %H:%M:%S')
print(datee_test)2
1
datee_test = datetime.strptime('2018-06-19 13:15:00', '%Y-%m-%d %H:%M:%S')2
print(datee_test) (6) datetime 转换为 str :
如:已经有了datetime 对象,要把它格式为字符串显示给用户,就需要转换为str,通过datetime 提供的 strtime() 方法实现的;
now.strftime('%a, %b %d %H:%M')1
1
now.strftime('%a, %b %d %H:%M') (7) datetime 加减:对日期和时间进行加减,时间上就是把 datetime 往后或前计算,得到新的 datetime 。需要导入 timedelta 类,使用 timedelta 可以很容易地算出前几天后几天的时刻。
now = datetime.now()
datetime.datetime(2018, 6, 19, 14, 42, 36, 664596)
now + timedelta(hours=10)
now - timedelta(days=10)
now + timedelta(days=12, hours=23)5
1
now = datetime.now()2
datetime.datetime(2018, 6, 19, 14, 42, 36, 664596)3
now + timedelta(hours=10)4
now - timedelta(days=10)5
now + timedelta(days=12, hours=23) (8)本地时间转换为 UTC 时间:
本地时间是指系统设定时区的时间,例如北京时间是 UTC+8:00 时区的时间,而 UTC 时间值 UTC +0:00 时区的时间。
datetime 类型有时区属性 tzinfo,默认值为 None,所以无法区分这个datetime 到底是哪个时区,除非强行给 datetime 设置一个时区,如下例所示代码。
(9) 时区转换
先通过 datetime 提供的 utcnow() 方法拿到当前的 UTC 时间,再用 astimezone() 方法转换为任意时区的时间;
7、读写 JSON 数据: json 模块
JSON(JavaScript Object Notation)是一种轻量捷的数据交换格式。JSON数据格式等同于 Python 里面的字典格式,里面可以包含方括号括起来的数组,即 python 中的列表。
在 python 中,json 模块专门处理 json 格式的数据,提供了四中方法: dumps \ dump 、loads、load。
7.1 dumps、dump:
dumps、dump 实现序列化功能,但在使用功能上有差别。其中,dumps 实现的是将数据序列化为字符串(str),而在使用 dump 时,必须传文件描述符,将序列化的字符串(str) 保存到文件中。
dumps 方法的使用:
import json
dict_test = { "01":"张三","02":"李四"}
# 将 字符串、数字、字典等数据序列化为标准的字符串( str )格式
json.dumps("Python") # 字符串
json.dumps(15.78) # 数字
json.dumps(dict_test) # 字典8
1
import json2
3
dict_test = { "01":"张三","02":"李四"}4
5
# 将 字符串、数字、字典等数据序列化为标准的字符串( str )格式6
json.dumps("Python") # 字符串7
json.dumps(15.78) # 数字8
json.dumps(dict_test) # 字典 dump 方法的使用:将字典数据保存到某个目录下
import json
dict_test = { "01":"张三","02":"李四"}
# 将 字符串、数字、字典等数据序列化为标准的字符串( str )格式
json.dumps("Python") # 字符串
json.dumps(15.78) # 数字
json.dumps(dict_test) # 字典
# 使用 dump 方法将字典数据 dict_test 保存到 F 盘根目录下的 json_test.json文件中。
with open("F:\\json_test.json","w", encoding='utf-8') as file_test:
json.dump(dict_test,file_test,indent=5)12
1
import json2
3
dict_test = { "01":"张三","02":"李四"}4
5
# 将 字符串、数字、字典等数据序列化为标准的字符串( str )格式6
json.dumps("Python") # 字符串7
json.dumps(15.78) # 数字8
json.dumps(dict_test) # 字典9
10
# 使用 dump 方法将字典数据 dict_test 保存到 F 盘根目录下的 json_test.json文件中。11
with open("F:\\json_test.json","w", encoding='utf-8') as file_test:12
json.dump(dict_test,file_test,indent=5) 7.2、loads 、load
loads、load 是反序列化方法。loads 只完成了反序列化,load 只接收文件描述符,完成了读取文件和反序列化。
import json
# 使用 loads 和 load
teacher_info = json.loads('{"teacher_name":"Mr.Liu","teacher_age":24}')
print(teacher_info)
with open("F:\\json_test.json","r",encoding="utf-8") as file_test:
test_loads = json.loads(file_test.read())
file_test.seek(0)
test_load = json.load(file_test) # json.loads( file_test.read())
print(test_loads)
print(test_load)1
import json2
3
# 使用 loads 和 load4
teacher_info = json.loads('{"teacher_name":"Mr.Liu","teacher_age":24}')5
print(teacher_info)6
with open("F:\\json_test.json","r",encoding="utf-8") as file_test:7
test_loads = json.loads(file_test.read())8
file_test.seek(0)9
test_load = json.load(file_test) # json.loads( file_test.read())10
print(test_loads)11
print(test_load)8、系统相关: sys 模块
sys 模块是 python 自带模块,包含了和系统相关的信息。通过运行以下命令。
导入该模块:import sys
通过 help(sys) 或者 dir(sys) 命令查看 sys 模块可用的方法跟成员变量:help(sys),dir(sys)
8.1 sys.path : 包含输入模块的目录名列表 (即 你的 path 设置)
sys.path.append(" 自定义模块路径 ") 添加模块路径。
8.2 sys.argv:在外部向程序内部传递参数;即path 列表中的第一个参数
9、数学: math 模块
python 自带模块,包含了和数学运算公式相关的信息。通过运行以下命令,导入该模块:
import math
dir(math)
10、随机数: random 模块
random 模块是 python 自带模块,功能是:生成随机数。可以通过 dir( random )查看 random 模块可用的方法和成员变量。
10.1、生成随机整数: randint()
10.2、随机浮点数: random() # 不带参数
random.uniform(12,30) # 带参数
10.3、随机字符: choice()
10.4、洗牌: shuffle()
11、在 Python 中调用 R 语言
注意:在 Python 中调用 R 语言的前提条件是,要在本机安装 rpy2 模块和 R 语言工具。
11.1 安装 rpy
rpy2 的版本 和 python 的版本要对应,也要和 R 的版本对应。
(1)下载 rpy2;
现在相应版本的 *****.whl 文件
(2)安装;
在命令提示符下,输入
pip install ****.whl
安装成功提示如下:
Successfully built MarkupSafe
Installing collected packages: MarkupSafe, jinja2, rpy2
Successfully installed MarkupSafe-1.0 jinja2-2.10 rpy2-2.9.43
1
Successfully built MarkupSafe2
Installing collected packages: MarkupSafe, jinja2, rpy23
Successfully installed MarkupSafe-1.0 jinja2-2.10 rpy2-2.9.4 11.2 安装 R 语言工具
( 1 ) 下载 R 语言工具
下载地址: https://www.r-project.org/ --> 点击 “ download R ” --> 选择中国的镜像。
(2) 安装:双击可执行文件。
11.3 测试安装是否成功
(1) 在 Python shell 里面输入一下命令:
import rpy2.robjects as rob # 无错误说明 rpy2 模块安装成功
rob.r['pi']
运行结果如下:
R object with classes: ('numeric',) mapped to:
<FloatVector - Python:0x06ADCE68 / R:0x08BBE9D8>
[3.141593]
4
1
R object with classes: ('numeric',) mapped to:2
<FloatVector - Python:0x06ADCE68 / R:0x08BBE9D8>3
[3.141593]4
(2)载入和使用 R 包
from rpy2.robjects.packgages import importr
base = importr("base")
stats = importr("stats")
stats.rnorm(12)4
1
from rpy2.robjects.packgages import importr2
base = importr("base")3
stats = importr("stats")4
stats.rnorm(12)
学习,生活要不停的提高提高,哪怕一点点,也不要停。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号