

redis
Redis
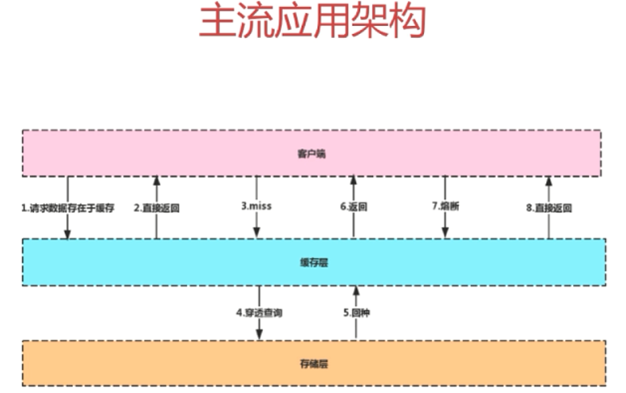
缓存中间件 — Memcache和Redis的区别
Memcache:代码层次类似Hash
→ 支持简单数据类型
→ 不支持数据持久化存储
→ 不支持主从同步(类似mysql的数据主从同步)
→ 不支持分片
Redis
→ 数据类型丰富(set、list)
→ 支持数据磁盘持久化存储
→ 支持主从同步
→ 支持分片
为什么redis能这么快?
100000+QPS(QPS即query per second,每秒内查询次数)
1、完全基于内存,绝大部分请求是纯粹的内存操作,执行效率高
2、数据结构简单,对数据操作也简单
3、采用单线程,单线程也能处理高并发请求,想多核也可启动多实例
4、使用多路I/O复用模型,非阻塞IO
5、
Redis的数据类型
1、String :最基本的数据类型,二进制安全
set键值(set name “zhangsan”) get 键(get name)
2、Hash :String元素组成的字典,适用于存储对象。
hmset 对象 属性1 “1” 属性2 “2”(存对象)
hget 对象 属性(获取对象属性值)
hset 对象 属性 值(修改对象的属性值)
3、List :列表,按照String元素插入顺序排序。
lpush list1 aaa (向list1中插入aaa)
lrange list1 0 10 (取出list1中的10条数据,后进先出)
4、Set : String 元素组成的无序集合,通过哈希表实现,不许重复。
sadd set1 111 (向set1中添加111,成功返回1,已存在返回0)
smembers set1 (遍历set1,是无序的)
5、Sorted Set :通过分数来为集合中的成员进行从小到大的排序
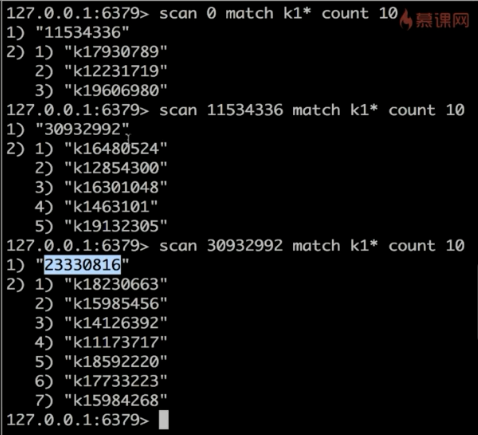
从海量key中查询某一固定前缀的key
使用keys对线上的业务的影响
Keys pattern :查找所有符合给定模式pattern的key
1、keys 指令一次性返回所有匹配的key
2、键的数量过大会使服务卡顿(keys 值)
SCAN cursor [MATCH pattern] [COUNT count]
1、基于游标的迭代器,需要基于上一次的游标延续之前的迭代过程
2、以0作为游标开始一次新的迭代,直到命令返回游标0完成一次遍历
3、不保证每次执行都返回某个给定数量的元素,支持模糊查询
4、一次性返回的数量不可控制,只能是大概率符合count参数
scan 0 match 键 count 10
如何通过redis实现分布式锁
分布式锁需要解决的问题
1、互斥性(任意时刻只能有一个客户端获取锁,不能同时获取)
2、安全性(锁只能被持有的客户端删除,不能被其他客户端删除)
3、死锁(获取锁的客户端因为某些原因宕机而未能释放锁,其他客户端无法获取到该锁)
4、容错(当一些客户端宕机时其他客户端可通过相关版获取锁和释放锁)
SETNX key value :如果key不存在,则创建并赋值
1、时间复杂度 :O(1)
2、返回值 : 设置成功,返回1;设置失败,返回0。
如何解决setnx长期有效的问题
Expire key seconds
1、设置key的生存时间,当key过期时(生存时间为0),会被自动删除
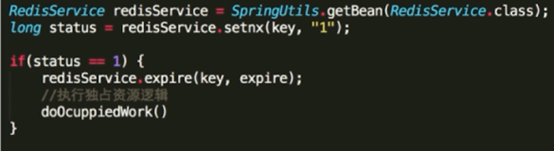
2、缺点 :原子性得不到满足
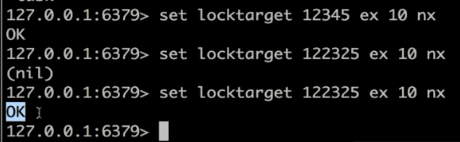
Set key value [EX seconds] [PX milliseconds] [NX|XX]
1、EX second :设置键的过期时间为second秒
2、PX milliseconds :设置键的过期时间为milliseconds毫秒
3、NX :只在键不存在时,才对键进行设置操作
4、XX :只在键已近存在时,才对键进行设置操作
5、Set操作成功完成时,返回OK,否则返回null
Java代码

大量的key’同时过期的注意事项
集中过期,由于清除大量的key很耗时,会出现短暂的卡顿现象
1、解放方案:在设置key过期时间的时候,给每个key加上随机值

