
@
目录
Pandas具有全功能的,高性能内存中连接操作,与SQL等关系数据库非常相似
- pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,left_index=False, right_index=False, sort=True,suffixes=('_x', '_y'), copy=True, indicator=False)
- pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,keys=None, levels=None, names=None, verify_integrity=False,copy=True)
- .replace()
- .duplicated()
一、merge合并 → 类似excel的vlookup
1.1 参数on → 参考键
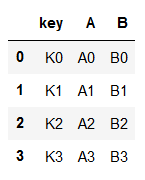
df1 = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
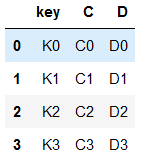
df2 = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
df1
df2
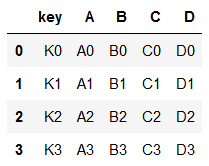
# left:第一个df
# right:第二个df
# on:参考键,参考键相同的行会合并
df = pd.merge(df1, df2, on='key')
df3 = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
df4 = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
# 多个链接键,必须key1和key2都相同才合并
print(pd.merge(df3, df4, on=['key1','key2']))
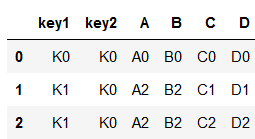
注意这里触发了对齐
1.2 参数how → 合并方式
# inner:默认,取交集
pd.merge(df3, df4,on=['key1','key2'], how = 'inner')
# outer:取并集,数据缺失范围NaN
print(pd.merge(df3, df4, on=['key1','key2'], how = 'outer'))
# left:按照df3的on参数为参考合并,数据缺失范围NaN
print(pd.merge(df3, df4, on=['key1','key2'], how = 'left'))
# right:按照df4的on参数为参考合并,数据缺失范围NaN
print(pd.merge(df3, df4, on=['key1','key2'], how = 'right'))
1.3 参数 left_on, right_on, left_index, right_index → 当键不为一个列时,可以单独设置左键与右键
df1 = pd.DataFrame({'lkey':list('bbacaab'),
'data1':range(7)})
df2 = pd.DataFrame({'rkey':list('abd'),
'date2':range(3)})
print(pd.merge(df1, df2, left_on='lkey', right_on='rkey'))
print('------')
# df1以‘lkey’为键,df2以‘rkey’为键
df1 = pd.DataFrame({'key':list('abcdfeg'),
'data1':range(7)})
df2 = pd.DataFrame({'date2':range(100,105)},
index = list('abcde'))
print(pd.merge(df1, df2, left_on='key', right_index=True))
# df1以‘key’为键,df2以index为键
# left_index:为True时,第一个df以index为键,默认False
# right_index:为True时,第二个df以index为键,默认False
# 所以left_on, right_on, left_index, right_index可以相互组合:
# left_on + right_on, left_on + right_index, left_index + right_on, left_index + right_index
二、concat连接
s1 = pd.Series([1,2,3])
s2 = pd.Series([2,3,4])
print(pd.concat([s1,s2]))
print('-----')
# 默认axis=0,行+行
s3 = pd.Series([1,2,3],index = ['a','c','h'])
s4 = pd.Series([2,3,4],index = ['b','e','d'])
print(pd.concat([s3,s4]).sort_index())
print(pd.concat([s3,s4], axis=1))
print('-----')
# axis=1,列+列,成为一个Dataframe
# 重设index为默认的0~n
s_new = pd.concat([s3,s4], axis=1)
s_new.reset_index(inplace=True, drop=False)# drop 是否把index列丢弃
s_new
三、duplicated去重
方法1
s = pd.Series([1,1,1,1,2,2,2,3,4,5,5,5,5])
print(s.duplicated())# 判断是否重复
print(s[s.duplicated() == False])# 通过布尔判断,得到不重复的值
方法2
# drop.duplicates移除重复
# inplace参数:是否替换原值,默认False
s_re = s.drop_duplicates()
方法3
sq = s.unique()
四、replace替换
s = pd.Series(list('ascaazsd'))
print(s.replace('a', np.nan))
print(s.replace(['a','s'] ,np.nan))
print(s.replace({'a':'hello world!','s':123}))
# 可一次性替换一个值或多个值
# 可传入列表或字典
打赏
码字不易,如果对您有帮助,就打赏一下吧O(∩_∩)O



 浙公网安备 33010602011771号
浙公网安备 33010602011771号