

iptables之三扩展及其应用
回顾
iptables/netfilter
netfilter:kernel framework,位于内核中的框架,提供了5个钩子行数分别对应iptables中的5个内置的规则链。
四表:filter、nat、mangle、raw
五链:PREROUTING、INPUT、FORWORD、OUTPUT、POSTROUTING(前三个面向于入栈,后两个用于出栈)
iptables:
常用的子命令:
链管理:-F、-X、-N、-E、-Z、-P、-L、
规则:-A、-I、-D、-R
-j TAEGET:
ACCEPT、DROP、REJECT、RETURN、LOG、MARK、DNAT、SNAT、MASQUEARDE、…
匹配标准:
通用匹配:-s、-d、-p、-i、-o
扩展匹配:
隐含扩展:
-p tcp:--dport,--sport,--tcp-flags,--syn(--tcp-flags SYN、ACK、FIN、RST SYN)
-p udp:--dport,--sport
-p icmp:--icmp-type
显示扩展:-m
显示扩展
必须显示指明使用的扩展模块(模块使用rpm –ql iptables | grep “\.so”查看)
需要注意的是,在CentOS7上防火墙使用的是firewalls来管理的,firewalls是用Python研发的前端模块。
查看扩展:
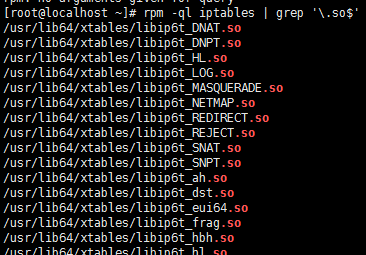
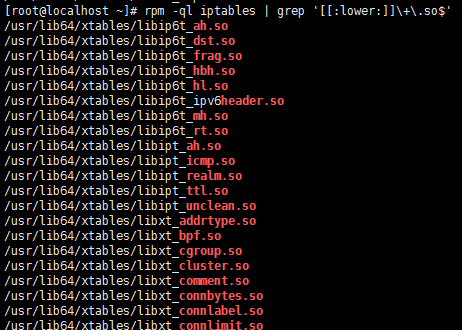
注意:每一个扩展都有自己的专用选项
此外,CentOS6和CentOS7去获取每一个扩展使用帮助文档的方式是不一样的:
- CentOS6:man iptables
- CentOS7:man iptables-extensions
常用显示扩展说明
1、multiport扩展
多端口匹配。
我们直接使用—sport或—dport时,端口要么指明单个的要么指明连续的一片,如果想把22端口TCP协议与80端口的服务同时开启,如何做呢?此时就要使用multiport实现扩展了。所以这是以离散方式定义端口匹配,最多指定15个端口。
- [!] --source-ports,--sports port[,port|,port:port]... #指明多个源端口;
- [!] --destination-ports,--dports port[,port|,port:port]... #指明多个离散的目标端口;
- [!] --ports port[,port|,port:port]... #既能匹配源又能匹配目标端口;
示例:同时放行22和80端口
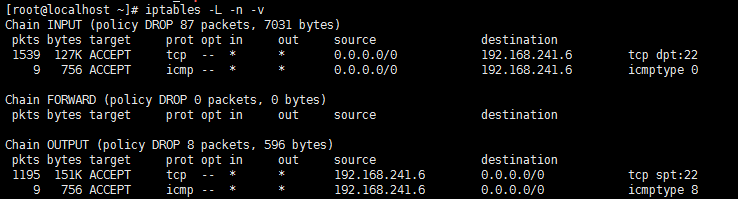

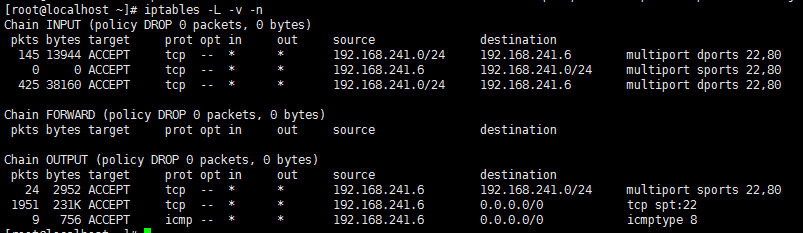

2、iprange扩展
指明连续的(但一般不能扩展为整个网络)IP地址范围时使用;
- [!] --src-range from[-to] #指明连续的源IP地址范围;
- [!] --dst-range from[-to] #指明连续的目标地址范围;
例:仅放行192.168.241.1-192.168.241.120访问SSH、Web、Telnet:
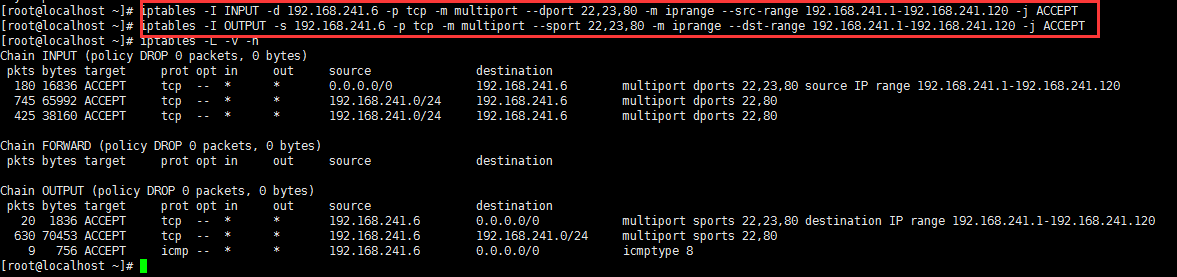

3、string扩展
此前讲网络通信时说过,任何能够被网络传输的数据必定都是那些能够被流式化的数据。数据通过网络传输时,有一个特性,数据报文从一个主机传到另外一个主机时,这个报文必须要封装各种首部,而只要没加密,这个数据是可以被看见的,但问题是我们怎么编码的呢?怎么把这个文本字符或其它信息编码成在互联网上能够发送的01编码呢?
此前说过,数据在发送或存储都有两种格式,一种是二进制格式,一种是文本编码格式,而文本编码格式通过互联网来发送的通常是Base64或MIME的编码机制。虽然这些数据都是01代码,但是我们可以把它们进行反向叫Decode,协议报文在本地先编码成可传输格式,到对方以后还需要还原成对应的协议报文或对应的可见的内容格式。
而string能够检查网络上每一个发送的报文内容当中,虽然编码了却可以去匹配这个编码中是否出现了此处指定的字符串的。
以Web服务为例,假设客户机从对方的网站上打开一个网页,这个网页内容服务器发送给客户机时它应该有IP首部、TCP首部、HTTP首部,但后面一定是网页内容,这个网页内容如果明文发送没有使用https,无非就是编码成01代码,而若想检查这里面是否出现指定的字符串,如法论功、传销等时,对于中文字符的检查是有限的,但对于英文字符的检查匹配是很好的,像这种虽然说iptables是工作在网络层和传输层的协议,但它却能够基于string去检查所传输的内容中是否有我们要匹配到的字符串的。
所以string扩展就是实现这种功能的:基于字符串匹配去检查协议传输单元中的内容,即检查报文中出现的字符串。
This modules matches a given string by using some pattern matching strategy. It requires a linux kernel >= 2.6.14.
即根据某个模式匹配来检查给定的字符串,要求内核版本大于2.6.14。其次,必须要根据某个模式匹配策略,所谓模式匹配策略指的就是字符串检查比对算法(比对检查算法如:传递一个字符串是abcdefg,那么传输时是先传a还是先传g呢?这都是有可能的,假如说先传的a,按照正常的字符串流,现在要去检查这里边有没有出现cd,如何检查?这就需要高效率的字符串比对算法):
--algo {bm|kmp}:指定所要使用的字符串比对算法;
bm = Boyer-Moore, kmp = Knuth-Pratt-Morris
必须给定算法才能够做字符串比对的,所以在string扩展中,algo是必须指定的选项;
- [!] --string pattern:从头到尾检查
- [!] --hex-string pattern:十六进制格式编码后的string,基于十六进制比直接给定一个字符串速率要高得多,因为给定字符串还需要转换成二进制或特定格式进行比对,而直接写成16进制格式的话,得到的结果就已经是直接编码后的结果了。
举例:
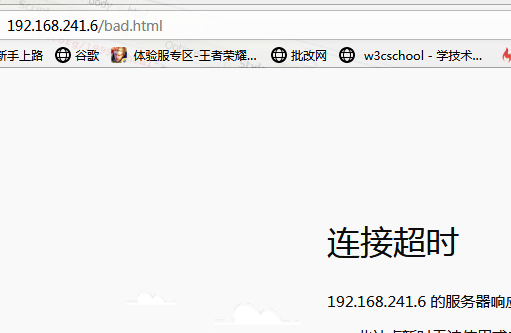
创建一个网页,用户访问这个网站时,其网页中包括movie这样的字符串,就不允许访问:


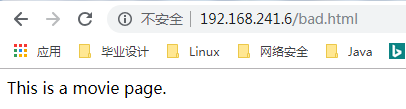
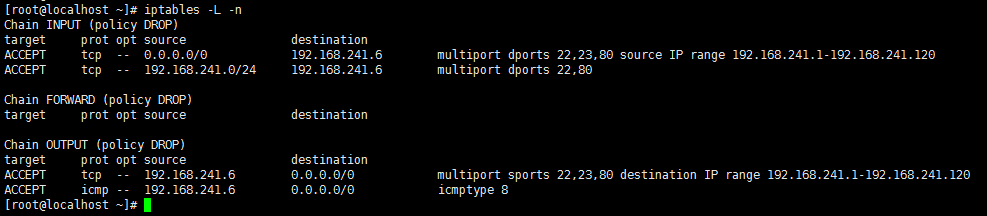
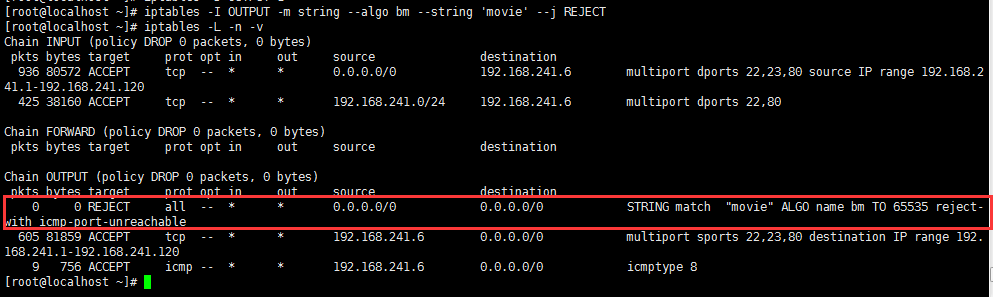
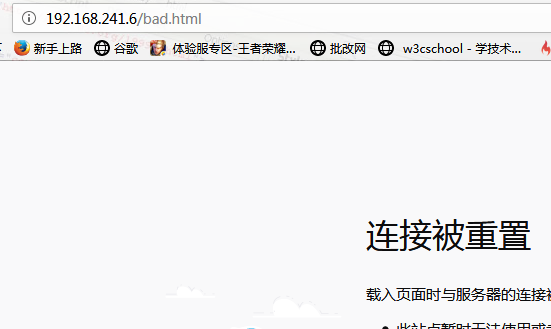
此时用户请求可以访问,但是由于响应报文中的内容被匹配到,因此响应被拒绝了。
4、time扩展
(基于时间做检查的)
根据报文到达的时间与指定的时间范围进行匹配;(若报文到达的时间刚好在指定的时间范围内表示匹配到了)
如:到特定时间网络自动断开、网络自动开启就是基于time扩展实现的。
This matches if the packet arrival time/date is within a given range.
即只要报文到达的时间在我们给定的时间范围内,就表示能匹配。
常用选项:
- --datestart YYYY[-MM[-DD[Thh[:mm[:ss]]]]] #起始日期
- --datestop YYYY[-MM[-DD[Thh[:mm[:ss]]]]] #停止日期
Only match during the given time, which must be in ISO 8601 "T" notation. The possible time range is 1970-01-01T00:00:00 to 2038-01-19T04:17:07. 中间要加个T这个特殊字符,也可以只给定年,表示那年的1月1号0点0分0秒。
If --datestart or --datestop are not specified, it will default to 1970-01-01 and 2038-01-19, respectively.
- --timestart hh:mm[:ss]
- --timestop hh:mm[:ss]
只匹配之间不匹配日期,这样就表示每一天都要检查了
Only match during the given daytime. The possible time range is 00:00:00 to 23:59:59. Leading zeroes are allowed (e.g. "06:03") and correctly interpreted as base-10.
- [!] --monthdays day[,day...]:每月在哪一号到哪一号进行检查;有效范围是1-31;
- [!] --weekdays day[,day...]:只在周几进行检查。有效范围是1-7
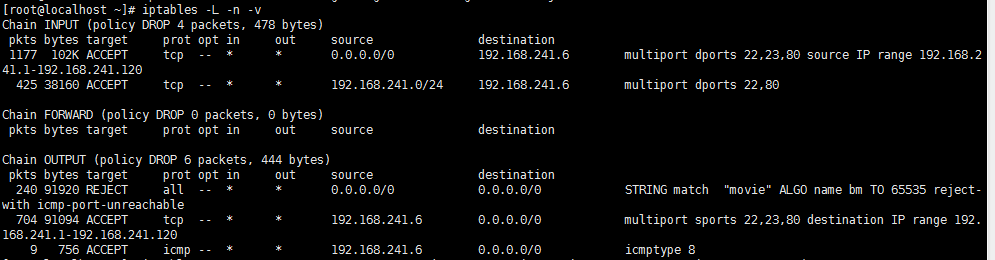
示例:Web服务器全天不允许访问:
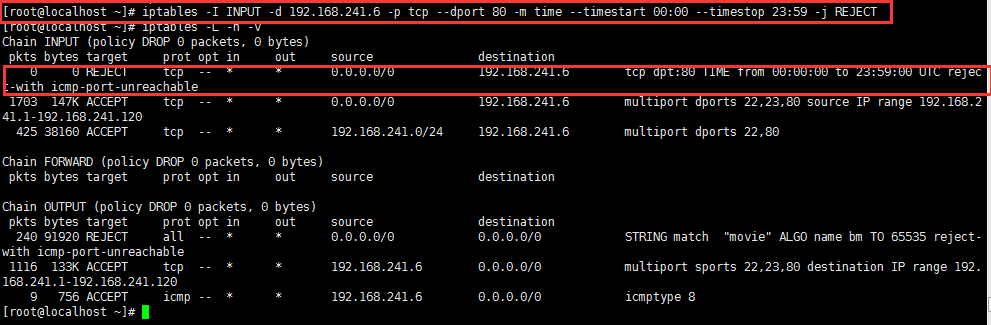
5、connlimit扩展
Allows you to restrict the number of parallel connections to a server per client IP address (or client address block).
根据每客户端IP(也可以是地址块,好像只能在CentOS7上才能指定地址块)做并发连接数数量匹配。
如:单个IP同时对主机发起了10个IP请求,我们服务器如果最多能并发响应100个,它自己一个人就占用了10个,对我们的资源消耗量太大,为了能做到公平,限制每一个客户端最多只能访问并发2个,这就是所谓的每IP并发连接数访问数量限制。
- [!] --connlimit-above n #连接的数量大于n,表示超过的,指明多个的,一般来讲,超过的都给它拒绝的。(CentOS6只支持这一个专用选项)
- --connlimit-upto n #连接数量小于等于n,表示小于等于的,一般允许
- --connlimit-mask prefix_length #指明地址网段掩码,说白了就是指明前缀长度。对IPv4来讲,一般这就是所谓可以用来做掩码的数量,1的个数。
例:对本机的SSH服务最多只允许来自于一个客户端的并发连接3个:
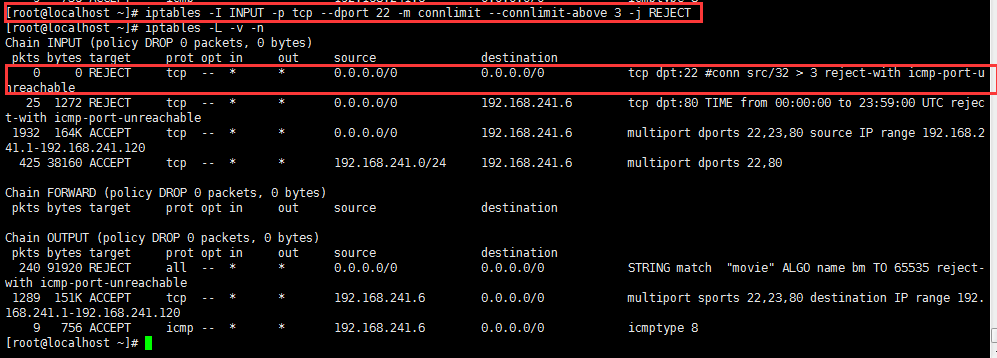
自己测试效果!
6、limit扩展
基于收发报文的速率做检查;
limit和connlimit不一样,connlimit指的是并发连接数量而limit则是发送报文的速度,比如向对方发送一个ping包,一秒钟发一个也可以一秒钟发100个。
例如:可以基于收发报文的速率做检查,即一秒钟只匹配一个,但你1秒钟发送10个我最多放开一个。
使用令牌桶过滤器来实现速率匹配,基于令牌桶算法实现。
令牌桶过滤器:
如:假设摩天轮是基于一定速率旋转的,假如每两分钟能够转下来一个轿厢,假设一个轿厢只能座两个人,现在有一大堆人排队,需要座摩天轮,我们处理方法是什么呢?先一次上两个人,一次匹配两个,但它两分钟转了一个,接下来两分钟之内有人在等也没用,等下一个轿厢转过来再上两个,人来的再快也没用,排队的人需要发的报文再多也没用,它一定要受限于已有的令牌桶。而这每一个轿厢可以理解为是一个令牌,而整个摩天轮上的轿厢加起来是我们所能够容纳的最多的令牌数量,所以称为令牌桶。
再举个例子:有一个博物馆,某一天免费开放,但是为了保证博物馆的参观效率,我们这个博物馆最多允许同时在馆人员数量 不能超过100人,但是一说免费一下子涌进来1000个市民在排队,这1000个在此等待排队访问的市民们,假设每一个人参观完后在里面呆的时间是10分钟左右,10分钟后就会出来,每一分钟放一个人进去。那么先放100个人进去,假如过了10分钟了,一个一个往外放行,而第一批一下子放进去了这么多这叫峰值。
可以想象令牌桶是这么一种做法,假如说每一分钟有一个空闲令牌到达,于是可以放一个人进去,但是在过去的一段时间内,第一分钟过去了,没人来,将这个令牌收集起来,想象成是一个桶,来一个空闲令牌给它扔进去一个,再来一个空闲令牌还没人用再扔到桶里,但这个桶的容量是有限的,假如说每一分钟能空闲下来一个,但是600分钟过去了,这个时候就空闲了600块令牌,这个时候来了1000个人,一下子放600个这个速率对我们来讲太大了,因此峰值我们通常不会给它放的太大。假如说这个桶的容量只是50个,那过去600分钟内一直没有人来访问,我最多也只放50个空闲令牌地51个空闲令牌如果还没有人访问,就把它扔了,所以多余的空闲令牌将不会被收集。
我们仍然回到令牌桶上,可以想象成发包速率,别人ping我们的主机,发一个ping报文,我们的服务器会很忙,但是任何一个ping报文来了我们都应该给它做响应,正常情况下一个主机也应该是这么做的,因为这是我们在协议上做的要求。但是任何一个报文来了,我们得对当前系统发生中断,中断后让内核接受这个报文并放在内存中,需要理解这个报文是什么,如果发现是一个ping请求还要给它封装一个报文,通过网卡在发一个响应给它。如果对方闲着没事,一直在ping而且ping的速度非常快,一秒钟还发了10个报文过来,怎么办呢?可以控制响应速率,每2秒钟响应一个,第一次来的时候,也不知道有恶意没有,第一次来1秒钟发来10个,峰值速率定义为5个,意味着一批来10个先响应5个,不控制速度,这叫峰值速率。接着,再来的话,最多两秒钟一个的这样放行。而这种控制机制其实就是令牌桶算法所实现的控制机制。
由此,若当前这台主机允许别人ping请求进来但是这个ping请求最多在实现访问速度上每秒钟0.5个,而峰值速率可以1次多达5个。该如何做?
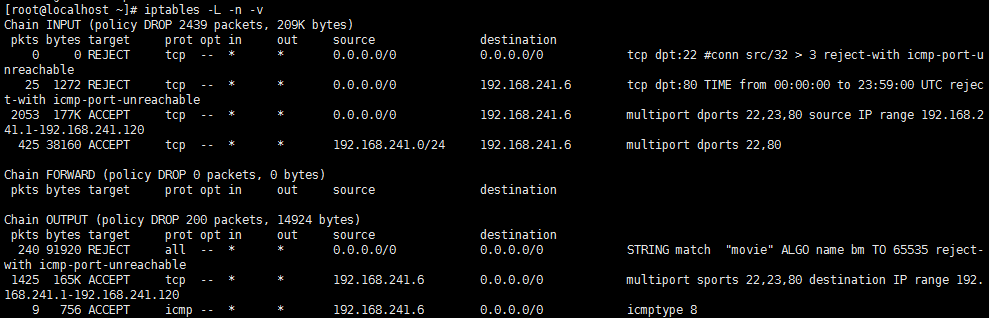

测试:
选项:
--limit rate[/second|/minute|/hour|/day] 发包速率,此选项为必须的
--limit-burst number 指明该开始不做限制使得空闲时峰值可以达到多少,此选项非必须
7、state扩展(对我们来讲至关重要的扩展)
根据连接追踪机制来检查连接间的状态
连接与连接间的状态有这么几种:
注意:这种连接追踪无关使用的是TCP、UDP、ICMP协议,这种连接追踪机制与TCP自己的状态没有任何关系,这里的状态是iptables自己所附加的一种去追踪连接、记录连接此前曾经是否访问过的一种机制;
此前举过例子:作为一个店员,来过一个顾客,此前将它记录下来了,那下一次再来就知道了,这就是所谓的连接追踪机制;
这种连接追踪机制是怎么工作的呢?或者说我们能够追踪到的状态有哪些?
有这么几个,举例说明一下:
首先第一个,在TCP也好,UPD也好,ICMP也好,通常对于一个报文来讲,一次请求,它就由所谓的请求报文和响应报文共同组成。所以当请求发来,我们给予响应这个过程,一旦我们收到对方请求,并开始做响应这之后,它们的执行状态叫ESTABLISHED,并且更重要的是,在有限时间内,比如说我们定义此前只要来过,我们会每个人,如鱼一样,只有六秒钟记忆,我们每一个连接只记录六秒钟,在六秒钟之内,只要再来访问我都认为你是此前来过的,都是ESTABLISHED状态,而如果说你访问过一次,我帮你记录六秒,但你六秒钟内再也没有来过,那这个连接就会清空,就会忘记了,再来就会认为是一个新顾客了。
所以它的连接追踪是靠内部,是iptables在内核内部找到这个内存空间,在这段内存空间当中会记录下来此前每一个源地址,访问的目标地址(目标地址一般是本机),而后给每一个源地址和目标地址记录下来了,并且记录完以后,后面给它一个倒计时的计时器,如30秒钟,然后就倒计时29、28…一直到0,这个条目被清除,在这个条目被清除之前,如果有同一个IP地址又来访问了,可以知道这是此前我们曾经访问过的。当然它的连接追踪可以追踪包含到对应的协议,如:使用的源地址、目标地址、源端口、目标端口、TCP协议还是UDP协议的,它都能记录下来,可以记录的非常详细,因此每一个连接都会占据一定的内存空间的。
那么对于在互联网上的一个非常繁忙的服务器来讲,如果有1万个,甚至有10万个不同的地址来访问过这台服务器,那就要记录10万条信息,要追踪10万条,所以他需要很大的内存空间了,而这个内存空间是在内核当中的,而内核一旦把内存耗尽了,就非常麻烦。所以默认来讲这个内存空间给的是比较小的,因此我们启用连接追踪机制以后对于非常繁忙的服务器这就很容易把这个连接撑爆了,而爆了以后,新的连接请求都会被自动拒绝。
所以对于所谓的状态的这种方式的做扩展,而检查状态这种方式去检查扩展,通常来讲,我们要求其状态连接上的这个数量尽可能给它开放的大一些。怎么开放呢?
调整连接追踪功能所能容纳的最大连接数量:
查看最大连接数量,使用的这个在内核中:/proc/sys/net/nf_conntrack_max,叫连接最终最大值,而这个值默认是:

所以说对于并发数量非常大的,像GLVS,做并发调度时,31512这个数量可能是相当大的;
第二个,我们当前已经追踪了哪些连接,使用如下方式查看:

这里边记录的是我已经追踪到的所有的连接。
所以,已经追踪到并记录的连接:/proc/net/nf_conntrack
再次说明,第一个数值在非常繁忙的服务器上如果不得不启用连接追踪功能的话,一定要将它调大一些。
那么我们常用的状态有哪些?
可追踪的连接状态:
- NEW
新发出的请求;连接追踪模板(/proc/net/nf_conntrack)中不存在此连接相关的信息条目,这种就叫做新情求,因此,将其识别为第一次发出的请求;
所以如果客户端与服务器此前从来没有基于某种协议进行过通信,现在客户端发送过来一个请求,那这个服务器端会识别第一个连接,这个请求叫NEW。此时开始响应,如果它再发来一个连接,如果我们这个时候模板中的条目是有效的,那就意味着表示是ESTABLISHED,直到这个条目失效之前的这段时间都叫做ESTABLISHED。
- ESTABLISHED
表示NEW状态之后,连接追踪模板中为其建立的条目失效之前这段期间内所进行的通信的状态。
- RELATED
相关的连接;如ftp协议中的命令连接与数据连接之间的关系;
ftp在实现数据传输的时候有两个连接:命令连接、数据连接,对于命令连接来讲,它只是用于实现收发命令的,一旦需要获取数据,它会为每一次的数据获取打开一个新的数据连接。但如果没有控制连接是否应该会出现数据连接?没有发命令就不可能传输数据,那么是不是可以认为只要在传输数据的过程当中那个命令就是存在的。所以像数据连接跟命令连接这样的关系叫RELATED。命令连接是一个有来有往的独立的连接,有请求有响应,但数据连接确实也是另外一个有请求有响应的连接。所谓两个连接就是每一个连接都是由请求报文和响应报文组成的,所以数据连接它有自己的单独专用的请求报文和响应报文,而命令连接也有自己的请求报文和响应报文,它是两个互相独立的连接,但这两个连接之间应该是有关系的,因为所有的数据连接应该是由命令连接建立起来的,这种就叫做相关的连接。
- INVALIED
无法识别的连接;
既不是NEW、也不是ESTABLISHED、又不是RELATED,称为INVALIED;
而state就是能够让我们能够根据连接追踪状态中的状态进而实现对于连接实现控制功能或匹配检查的。
还需要注意的是,如果要使用连接追踪状态实现对报文的状态做状态追踪或状态检测的话,需要去装载专用的模块才行,即需要让内核装载上内核专用的模块才行,不过这些模块的装载一般来讲都是自动完成的。
如:以Web服务器为例:
思考一下,可以这么理解吗?当用户请求发出来时,第一次请求时这是一个NEW状态的连接,我们对NEW放行以后,那后续的所有的通信过程,只要连接追踪模板中的条目失效之前的所有通信过程都可以认为这是ESTABLISHED状态,注意不要考虑TCP的连接状态只考虑连接追踪。所以只要第一次请求我允许放行了,而后在连接追踪模板中就开始给它记录这样一条连接,随后的所有请求和响应,在这个条目失效之前,它们都是叫做已建立的连接,是可以这么理解的。
事实上,只有第一次发出请求时是NEW的,而后哪怕是对你第一个请求的响应也叫ESTABLISHED,后续在请求响应都是ESTABLESHED,连请求都是,更不用说响应了。
因此将来为了使得防火墙更安全,状态追踪就能帮我们在一定程度上实现这个效果了。如:像现在很多木马是反弹式的,有些木马程序,如在你主机上植入一个木马,假设你很有安全意识,所以把本机上的所有无用的端口(也不会拿来访问别人)统统关掉了,只开放了80端口,因为本地是Web服务器,不开放80端口,别人连Web服务也没办法访问了。
但是有些反弹式木马就有一个功能,它设计的非常精巧,他通过扫描本机哪个端口能访问,它于是发现80端口能够访问,于是自己通过80端口去主动发起一个新的连接,连接客户端,并且给你木马的那个人它有个控制端,然后这个程序会通过80连接控制端,于是他进而能够远程控制你的主机,这种实现的功能就非常精巧了。但是,我们的80端口是用来让别人访问我们给予响应的,也就是说本机服务器通过80端口发出去的所有报文都是用来响应给别人而不是请求别人的。因此对于反弹式木马,开放80端口是无效的,因为默认情况下开放80端口它做的操作至于是请求还是响应你是做不到检查的。那一旦我们能有做连接追踪这就容易了,因为80端口进来的请求时新连接还是已建立连接我都允许,但是出去的只允许已建立的,我们不应该允许新连接出去,因为80端口Web服务只可能通过80去响应而不可能通过80连接别人。因此这样就限制了所有通过80端口的出去的连接必须是对某个请求作出响应,说白了就必须只能是ESTABLISHED状态,那么这种反弹式木马就出不去了,因为它发起的是新连接。
因此我们说这种状态追踪的检测的防火墙机制能够在一定程度上增强防火墙的安全性,不过这种安全性增强的前提是你得打开连接追踪功能,而连接追踪是消耗资源并降低效率的,这是必然的。
选项:
--state STATE1,STATE2…
使用连接追踪机制添加规则示例:
对于22号端口和80端口做状态检测:
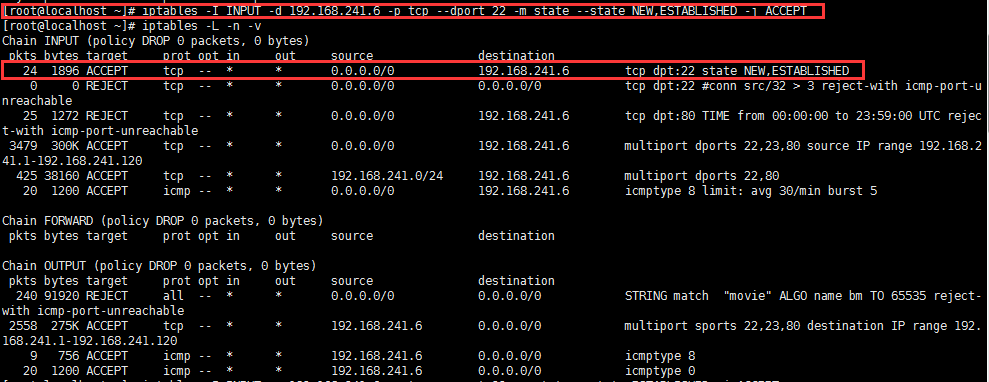
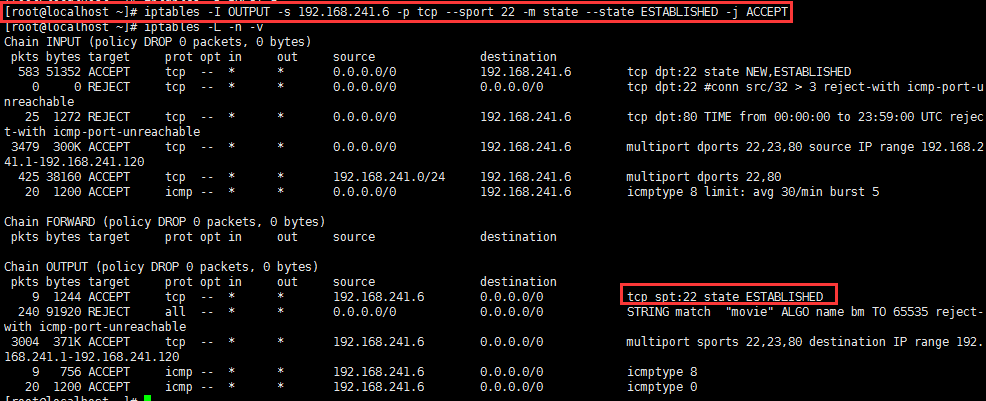
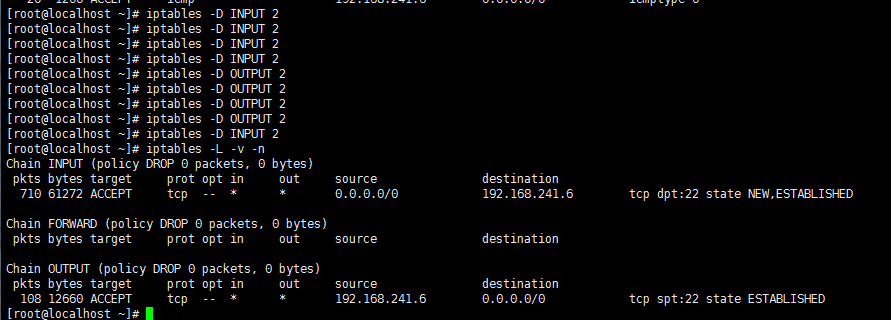
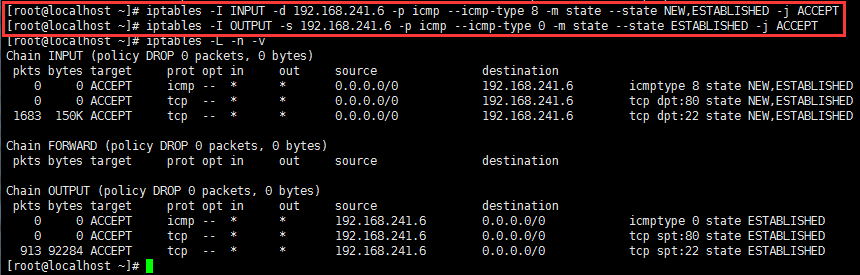
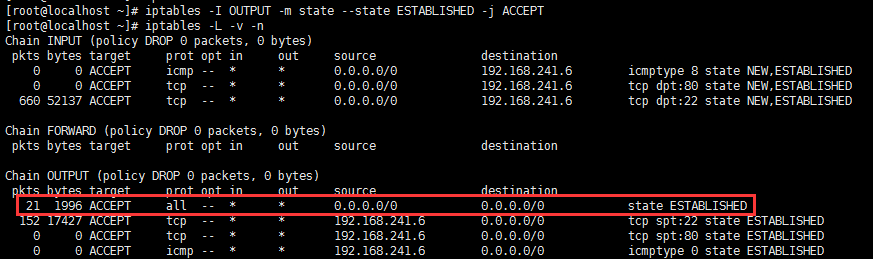
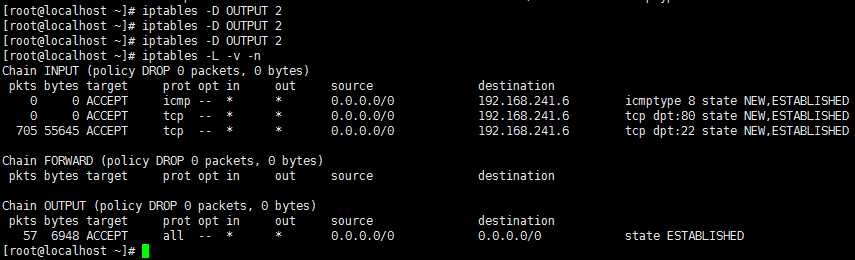


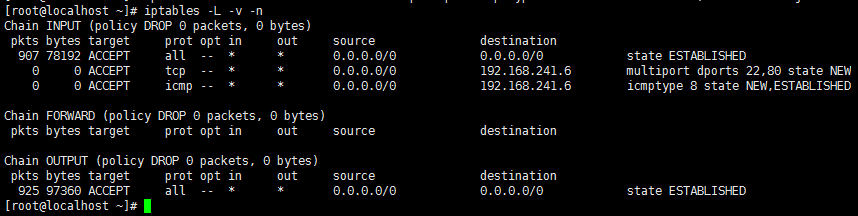
有了连接追踪机制,我们可以在较为安全的前提下实现对n条规则的同时放行。
自行测试SSH服务与Web服务!
有些连接追踪的时间很长,有些很短,像TCP的会话时间是2个小时(TCP会话超时时间计时器是两个小时),所以要想修改每一种协议的连接追踪的时长也可以自己定义,于是:
不同协议或连接类型追踪的时长可在/proc/sys/net/netfilter/调整。
问题:
如何基于连接追踪的功能开放被动模式的ftp服务?(被动模式下服务器端的数据连接端口是随机的,但如果所有端口都开放,防火墙还有什么安全性可言?)

