Web服务之二:httpd安装配置
httpd相关介绍
代理:Web代理服务器工作在Web客户端与Web服务器之间,他负责接收来自客户端的http请求,并将其转发至对应的服务;而后接收来自于服务器的响应,并将响应报文回送至客户端。
Apache:Open Source,Web服务器的引导者,很多Web服务器的标准都是参照Apache制定的,因此这也是事实上互联网Web服务器的规范的指定者。
早先源自于NCSA,当时NCSA研发的一款软件其进程叫httpd,因此httpd一直也是作为Web服务器最早出现的代表而使用的。后来httpd这个软件已经很完善了,NCSA觉得这个项目已经没有完善下去的必要就解散了,因此NCSA的很多研发者到了其它公司工作,但它们又不想httpd没落下去,因此通过互联网协作起来继续为这个软件新增了很多功能,主要就是打上补丁、补漏洞、新增额外功能。因此有人把它们重新发行的,基于互联网协作发行的服务器httpd戏称为A Patchy Server(充满补丁的服务器),后来简写为Apache(Apache也是美国武装直升机的代称)。
FSF:GNU组织的,发布了GPL协定的软件基金会。
ASF:Apache Software Foundation,开源界最著名的基金会之一,与FSF齐名
到目前为止,Apache是著名的软件基金会,叫ASF
由ASF主导的著名项目有:
- httpd:提供web服务,很多时候就以Apache称呼httpd,因为早期httpd就被称为Apache Server,因此当听到Apache表示一个具体的项目时,就是表示httpd;
- Tomcat:JSP的应用程序服务器,能够提供JSP执行环境,是著名的实现JavaEE实现规范的参照程序;
- Hadoop:提供并行处理运行环境,提供高性能运算的非常重要的计算框架,可以实现将数千台电脑组织起来完成同一个任务;
Apache官网:www.apache.org
web服务器httpd官方站点:http://httpd.apache.org
httpd:
纯粹的Web Server,开源(Open Source),其开源协定不再是GPL,而是Apache的开源协定。
httpd传统风格特性:
- 在进程控制上通常是事先创建进程;Web服务器响应用户模型有多种,多进程/多线程是一个用户请求使用一个进程来响应,因此如果接收到多个用户请求后再进行创建进程速度会比较慢;所以Apache事先把进程启动作为空闲进程;
- 事先创建的进程是有数目要求的,有一种适应性叫按需维持适当的进程;如:启动500个进程响应500个请求,若500个请求中有400个请求都完成了,那么400个进程都空闲下来了,但不能让进程都空闲下来,因此当空闲太多时需要将空闲的进程一一销毁,直到满足我们所应该维持的最小或最大进程数为止;
- 模块化设计(即只具备核心功能),其核心比较小,各种功能都通过模块来进行添加,支持运行时配置,支持单独编译模块。这些模块可以在运行时启用,类似于Linux内核,平时只启用其核心功能,用到额外的功能时,只需要将额外的功能的模块装载进来即可,同时需要注意的是我们在用到哪个模块的功能时,可以单独编译对应的模块。甚至包括PHP都可以通过模块的方式装载进httpd,Apache与PHP结合有很多种方式,模块化就是比较常见的一种,也是RedHat系列服务器上默认的一种;
- 支持多种方式的虚拟主机配置。我们在此处简单引入一下虚拟主机的概念:如果需要提供Web服务,那就需要有一台物理服务器,并且在服务器上需要运行Web服务器进程,当客户端请求时,这个进程要能够予以响应。而若我们要在互联网上建一台Web服务器,能够提供个人或公司的站点,需要有一台物理服务器、需要IP地址、并且要保证实时能够在线、能够被互联网上的主机所访问,那这需要的资源会非常多,并且如果访问的用户非常少,会造成非常大的资源浪费。因此可以通过提供虚拟主机的方式提供站点。
- 支持https协议。通过mod_ssl模块支持。
- 支持基于IP或主机名的ACL。
- 支持目录的访问控制。用户访问主站点的时候不用提供账号密码,但是访问某一特殊路径路径时,就需要提供账号密码。
- 支持URL重写。如:本来访问的是/image/a.jpg但却可以重写成/bbs/images/abc.jpeg,而这对于客户端来讲是透明的,可以在服务器上将这种内容统统转发到另外一个路径上重新访问。
Nginx:
Nginx是基于多进程响应n个用户请求的这样一种模型,所以它能够使用有限的资源响应比Apache更多的用户请求。但却代替不了httpd,因为Nginx目前来讲作为一个完整意义上的提供诸多丰富特性的Web服务器来讲,它没有办法与httpd相比较的。就其稳定性来讲也无法与httpd相比较,所以它们各有各的发挥场所,Nginx一般用来做反向代理,而httpd仍然是Web中当之无愧的老大。
虚拟主机的相关问题
虚拟主机:简单来讲,若我们只有一台物理服务器,而且安装的Web程序也只有一个,但这个Web服务器本身却可以根据用户请求的不同提供多个站点,即可以服务于多个不同的站点。如:若使用www.a.com与www.b.org发生在同一台主机,但是打开的网站确实是不同的,那这种我们就把它称为虚拟主机。
那么如何区别不同的虚拟主机呢?
我们刚才已经说了,对于多个虚拟主机来讲,Web服务器只有一个,而目标IP也可能只有一个,端口就是80端口。在这种前提之下,要想让用户访问的是不同的站点,那么靠什么区别呢?
在此之前我们需要明确的是,事实上服务器在特定的地址或套接字上提供服务的话,那么每一个服务必须要占据一个套接字(套接字即IP:Port的组合),而每一个套接字只能为一个服务器提供服务。所以若要实现多种不同方式的虚拟主机的话有多种不同的组合方式,如:一台服务器上配置多个IP地址,每一个IP地址提供一个网站。
所以实现虚拟主机的方式有这么几种变化方式:
- 基于IP的虚拟主机;
- 基于端口的虚拟主机;
- 基于域名的虚拟主机;若端口、IP都一样,但由于其站点访问的时候的DNS的主机名不同,却也可以打开不同的虚拟主机。
在互联网上,基于域名的虚拟主机的实现更现实一些。因为IPv4地址是紧缺的资源,因此基于IP的虚拟主机不现实;而Web服务器的端口默认为80端口,但基于端口的虚拟主机就需要使用其它端口,用户将无法得知具体端口号,也不现实。
我们再来回顾一下,客户端请求报文的格式为:
protocol://HOST:PORT/path/to/source
Method URL version header
body
GET /download/linux.tar.bz2 HTTP/1.0
HOST:www.test.com
Host与Method后的路径组织起来就是完整意义上的遵循规范的URL了,而Host指定的是域名,因此这个报文传到服务器后,服务器端完全可以根据Host区别到底访问的是哪个虚拟主机,这就是基于域名虚拟主机的实现的最基本的前提。这也是为什么请求报文中一定要有一个首部叫Host予以标识的原因。
但如果在实现基于域名的虚拟主机的前提之下用户访问的是IP地址呢?若请求的时候就是基于IP地址请求的话,此时可返回一个默认的虚拟主机,同时如果用户访问不存在的虚拟主机同样返回默认的虚拟主机。
httpd在CentOS上的安装配置:
httpd在CentOS上的安装配置方式:
- 通过系统自带的rpm包;
- 源码编译。rpm包有其局限性如:有些需要的功能未编译、有些不需要的功能编译了、版本落后、漏洞等等。
理论基础:
httpd安装包:
安装完成后执行进程在:/usr/sbin/httpd;
在RedHat5.8系统上的httpd处理模式(多道处理模块MPM)是prefork的,需要事先启动空闲进程用来接收用户请求。因此启动后会发现系统上有很多个叫httpd的进程,而在众多进程当中,有一个进程运行的属主属组是root用户root组,其它进程的属主属组是apache用户apache组,这是因为在Linux系统上小于1024端口的要想启动只有管理员有权限,而这个root用户root组的进程本身并不响应用户请求,它专门用来创建空闲进程或销毁多余的空闲进程,所以这是一个主导进程(master process),其它进程称为work process。所以每一个用户请求都由主导进程创建一个工作进程响应用户请求。
服务脚本:/etc/rc.d/init.d/httpd;
占据端口及使用的协议:80/TCP;若基于ssl工作,则为443/TCP。
若基于rpm包编译安装,它会假设自己的工作根目录在/etc/httpd下,工作的根目录即进程运行的根目录相当于程序的安装目录。
配置文件目录:/etc/httpd/conf;
主配置文件为/etc/httpd/conf/httpd.conf,Apache的主配置文件非常大,里面有很多内容,因此RedHat将它们分段引用了,因此所有的位于/etd/httpd/conf.d/*.conf的文件都是主配置文件的组成部分;
Apache的各种模块目录:/etc/httpd/modules,这个模块是一个链接;
日志目录:/etc/httpd/logs(链接)指向/var/log/httpd;
Apache的日志文件分为两类,一类叫访问日志(access Log),指的是客户端每次发起访问请求以及服务器端响应的结果;一类叫错误日志(error_log),指的是错误的访问及服务器运行过程当中出现的问题,包括服务器启动过程当中出现问题了。
响应的文件:/var/www;
/var/www/html:静态页面所在的路径;
/var/www/cgi/bin:Apache提供动态内容时使用的路径;
CGI:
CGI是让Web服务器能够跟额外的应用程序通信的一种机制。它能够让Web服务器在必要的时候启动一个额外的程序来处理动态内容,因此,CGI称为Common Gateway Interface(通用网关接口),这种通用网关接口就是让Web服务器能够跟应用程序服务器打交道的一种协议(可以将其理解成一种协议)。
因此当客户端向服务器请求一个动态内容index.cgi时,对于这个cgi脚本,httpd可以判断出客户端请求这个脚本,需要一个应用程序来执行,于是它就发起一个进程,应用程序处理完成后,再重新响应给httpd,httpd将其组合起来响应给客户端。过程如:
Client --> httpd(index.cgi) --> Spawn Proccess(index.cgi) --> httpd --> Client
那么什么语言可以开发CGI或动态网站呢? 其实只要是程序语言都可以开发成动态网站,就连C也是。只不过C语言是编译型语言,开发成网站后需要编译成可执行程序。而既然所有语言都能开发动态网站,那因此就需要让Web服务器能够识别到底是哪一种语言开发的,只要Web服务器能够识别,它就能调用相应的程序执行。但无论哪一种语言开发的都叫CGI,那么Web服务器怎么去识别呢?其实,每一个可执行程序都可根据其前几个字节判断出来可执行程序的类型,也能够调用相应的执行程序工作,只不过通常都叫做CGI或者说它们都可以以CGI的方式跟Apache结合起来工作。
应用程序与Apache的其它结合方式以及LAMP概念的引入:
有些程序跟Apache不仅仅是CGI一种,为了降低Web服务器的工作压力,可以通过这样一种方式让动态服务器进程跟Web服务器结合:Web服务器无论用或不用,动态进程也像Web服务器一样事先生成好进程,有一个专门启动的服务叫动态服务启动进程,它也创建了很多空闲子进程。当有人向Web服务器发起内容请求时,而Web服务器发现这是一个动态内容时,它要发起一个新的进程来响应执行这个动态内容,而进程已经创建好了就不用发起了。于是Web服务器只需要将这个动态请求的页面交给一个空闲的服务器进程执行一次就可以了。于是这些动态进程的创建和回收不再由Web服务器维护了,而是由这些动态的专门的管理进程(Method Process)来管理。像这种Web服务器跟动态服务器通信的机制叫fastcgi,fastcgi是向PHP工作的一种机制,像Python还有别的工作机制。
在这种机制之下,动态服务器进程就不用再由Web服务器控制启动或销毁了,而是由一个专门的进程负责,而这个专门的进程是工作在某个端口或套接字上个Web服务器通信,因此此时Web服务器与应用程序服务器可以放在不同的主机上了。如可以分为两台物理服务器,一个物理服务器专门用于接收用户请求的静态内容,如果请求的是静态内容直接从本地返回即可。当用户请求的是动态内容时,此服务器会通过本地的TCP/IP协议由本地网络将请求发送给另外一台主机,另一台主机上运行的有一个动态服务进程,同时它还创建了很多子进程随时等待响应发送过来的请求。请求处理完成后,通过网络将结果返回给Web服务子进程,子进程再响应给客户端。子进程在响应给客户端。这样静态内容和动态内容就可以使用不同的主机分别进行处理了。这就是处理动态内容的服务器被称为应用进程服务器的原因,所以它是专门用来处理应用程序或动态内容的。
这样一来,前端就可以放置两个Web服务器了,无论哪一台服务器用到动态内容时,都可以向应用程序服务器发起执行内容的请求。这正如我们曾经说过的一个域名可以有有两个A记录,因此有一个域名叫www.test.com,用户请求时,来自不同用户的请求解析到不同的Web服务器上,这台Web服务器如果静态内容都是一样的,当它请求一些动态内容需要执行的话,只需要将内容交给同一台服务器一执行将结果返回即可,这就是Web服务器站点,这也是动态内容跟静态内容怎么进行分层次的(程序分层)。这样就实现了各司其职,一个人只完成特定的工作。
我们在继续讨论这个话题,程序还有一种特性,我们都知道程序是由指令和数据组成的,如果我们要处理的数据非常大,而早期数据都是放在文件当中的,如:用户账号密码在/etc/passwd和/etc/shadow中,passwd和shadow就是一个数据库文件,但是条目如果多达数十万种,我们从中挑选一个数据会非常慢,而且管理起来会非常不方便。因此必须要有一种行之有效的数据管理机制,专门用来管理数据的服务器就叫数据库服务器,存储数据的地方叫数据库,而能够帮助管理数据的,运行数据库软件的这种服务器就叫数据库服务器。
当数据量非常大时再用简单的文本文件管理数据就变得非常低效了,于是就需要数据库服务器。因此需要有服务能够帮我们存储这种数据而且能够专门用某种接口将这种数据服务提供给提供给额外的其它应用程序或直接提供给用户,这种接口可以理解为数据库的API。因此若将数据库服务器建立好了,用户一旦需要处理程序执行,那个动态脚本就需要在应用程序服务器上执行,而应用程序服务器要执行一个脚本,这个脚本中涉及到数据处理,那这个数据处理的请求就需要提交给数据服务进程了。实际上无论是应用程序服务器还是数据库服务器都是CPU密集型的(CPU-bound,对CPU的占用率非常大),因此前端的用户越来越多导致后端的应用程序服务器忙不过来了,响应的速度回非常慢,此时可以考虑分层,将数据库服务器独立出来,再找一台物理机专门用来提供数据库服务。因此当程序需要访问数据时,应用程序服务器再次向后端的数据库服务器发起请求,由数据库服务器将数据返回给应用程序服务器,应用程序服务器再格式化成HTML文档返回给Web服务器进程,由Web服务器进程响应给客户端。
此时分出类三层,静态内容层、应用程序层、数据层。而每一个对应的层上需要一个专门的服务器提供,前端使用httpd,也叫Apache。中间使用PHP,数据层使用MySQL。它们都运行在Linux上,于是简称为LAMP。
安装配置使用httpd:
httpd本身是受SELinux控制的,但是事先应让SELinux处于permission或disabled的状态,不然很多配置都可能无法正常运行。
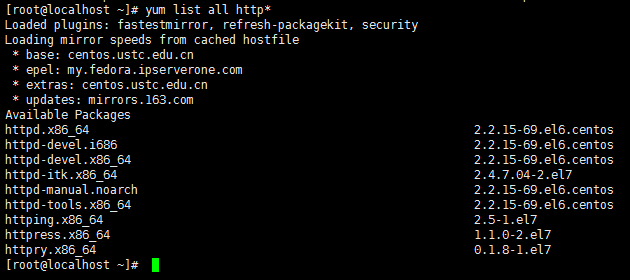
关闭SELinux:

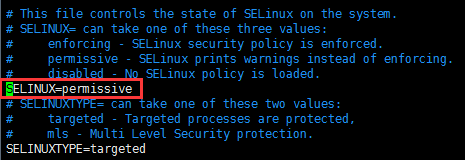

httpd的rpm包组成:
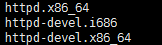
httpd.i386:服务器端包;
httpd-devel:开发包,包括一些开发库和头文件;
httpd-manual:手册,httpd官方文档;
安装httpd:



/etc/httpd/conf/magic:用于定义本地如何识别通过MIME编码而来的其它多媒体(非纯文本文档);
/etc/rc.d/init.d/httpd:服务脚本,其配置文件在/etc/sysconfig/httpd,为服务脚本提供配置文件,可以把配置文件中的某些参数一改服务脚本就能够工作在不同模式下了;
/usr/bin/ab:Apache服务器的压力测试工具,可用来评估Apache服务器的工作性能;
/usr/bin/{htdbm,htdigest,htpasswd}:创建Apache用户认证账号密码的几个命令;
启动服务:

查看80端口:

查看系统进程:

测试访问:

欢迎页面位置:

欢迎页面重命名后将不会被访问:
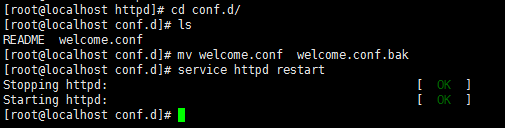

新建欢迎页面:



其实Web服务器的默认配置页面是需要在Web服务器的配置文件中指定是哪个页面的,而不是简单的随意给定一个页面。
Web服务器本身的配置文件定义:


配置文件分为三个字段:

注意:第二字段和第三字段不能同时生效,默认使用主服务器段,即第二字段。
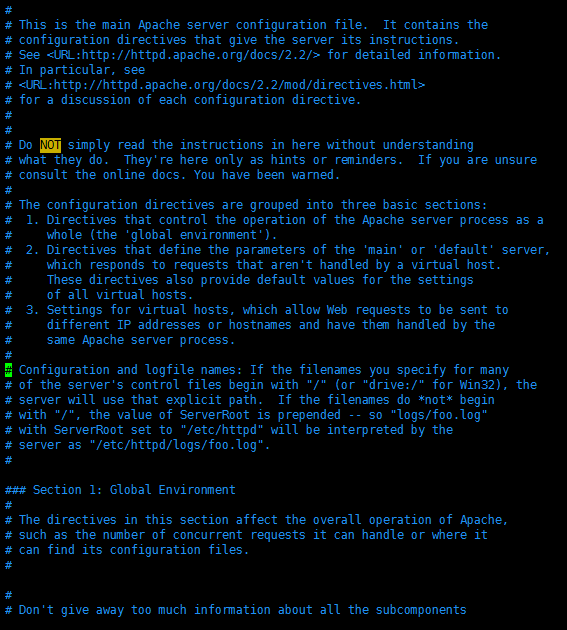
#后有空格为注释,#后无空格为可启用的选项,在Apache中叫指令,因为Apache的配置文件由directive(指令,不区分大小写)和其value(根据需要有哦可能区分大小写)组成;
Apache配置文件的每一个指令的值在Apache官方文档中有指定的参考。
安装参考文档的rpm包:



再看配置文件/etc/httpd/conf/httpd.conf:
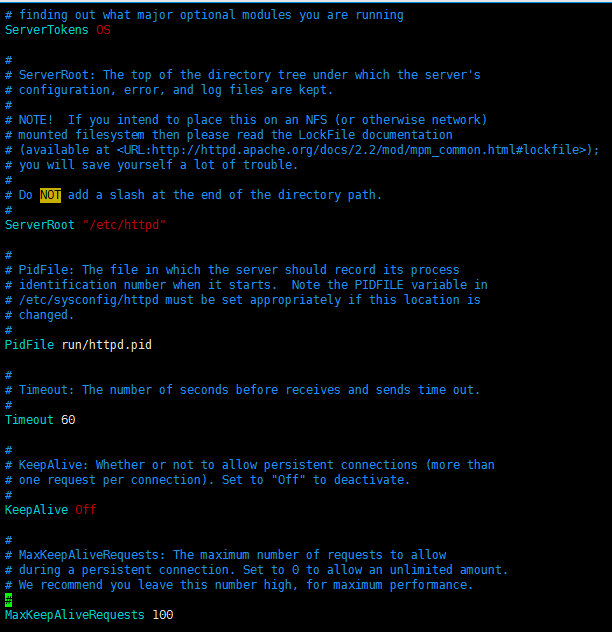

ServerRoot:服务器的根目录或工作目录,不到万不得已不要改,很多其它路径都是相对于这个路劲而言的;
PidFile:保存pid号的文件的路径(相对路径,相对于ServerRoot而言),每一个进程都有一个pid号,尤其是服务类的软件运行起来后这个pid号会保存在以这个进程命名的文件中;
Timeout:超时时间,TCP协议三次握手建立连接发起请求,若出现TCP的第一次握手发起后等它第二次就无响应了的情况,此处Timeout指的就是处于等待状态的时间,单位为秒;
KeepAlive:是否使用长连接,一般情况下,服务器的访问量不是特别大,应该打开长连接,会显著提高性能,因为若不打开长连接每一次请求都会三次握手,此处将其改为On;
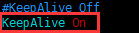
MaxKeepAliveRequests:不能让用户一直处于长连接,因此开启长连接后需要设定最多一次请求多少个。设定为0表示无限制,只要用户自己不断开就永远不断开了;
KeepAliveTimeOut:长连接的断开时长,单位为秒;若只请求了一个资源,不能让请求一直占用这个资源不断开,对于繁忙的服务器来讲,应尽可能将这个时间降低一些,既能够帮助一个用户的多次请求,又能够尽可能降低由于空闲连接空闲而导致的资源浪费。对于不同的服务器来讲这个值需要自己测试才能得出,如使用ab命令或LoaderRunner(HP公司专业级的测试工具);
LoaderRunner:HP公司专业级的测试工具,可以模拟应用程序的真实场景而对服务器做接近于真实的测试。(尝试自学)
MPM:Multi Path Modules,多道处理模块
当多个用户同时请求时,有多进程响应多个请求、一个进程响应多个请求等方式,而MPM就是定义在一个Web服务响应多个请求时所工作的模型的。
常用方式:(面试中可能是问到最多的话题,作为运维工程师是否了解Web服务器?请讲述这几种模型它们彼此之间的联系和区别(用专业的语言通俗易懂的讲给别人听))
- mpm_winnt:
是Windows NT上专用的,因为Windows是原生支持多线程的,所以是Windows上使用的一种特殊处理机制;
- prefork:
预先生成进程,一个请求用一个进程响应。
好处在于稳定可靠,任何一个进程崩溃了都不会影响其它请求,但性能比较差,尤其是多个用户请求并发量很大的时候性能很差,因为它对资源的消耗量非常多,而且会涉及到大量的进程切换。
- worker:
基于线程工作的,一个进程响应多个用户请求,但一个进程下使用多个线程来响应用户请求,一个请求用一个线程响应。
首先,它会生成两个工作进程,而我们都知道线程是进程的子单位,因此线程一定是处于进程当中的,所以在worker模型下,Web服务器会生成多个进程(一般而言,默认可能启动两个)。但启动的进程不是用来响应用户请求的,而是每一个进程会生成多个线程,用一个线程响应一个用户请求。这样的好处在于对于Thread而言,由于多个线程共享同一个进程的资源,所以如果某一个进程曾经访问过某一个文件而且已经打开了的话,那么第二个线程访问同一个文件就不用再打开直接访问即可,这样效率比较高;
但是多个线程在共享资源时,如果要写一个资源的话会导致资源争用的,所以为了避免资源竞争,必须要实现加锁,因此如果不能良好的避免锁竞争的话,事实上线程是否比进程效率更高,这个很难说的清楚,尤其是Linux不是原生态支持线程的。所以worker模型经过测试发现在Linux上还不如prefork模型性能好,这也是为什么默认使用prefork而不是worker模型的原因。
- event
基于事件驱动,一个进程处理多个用户请求,但是是同时处理多个,而不是使用线程响应的,使用一个进程处理多个请求。
在Apache2.4后才原生态支持event,并且默认就使用event,只要系统库(I/O)支持;因为event才是最强大的,Nginx就是使用event机制,但在Apache2.2中默认使用的是prefork的模型
prefork和worker模型在配置文件/etc/httpd/conf/httpd.conf中有各自不同的属性的定义:
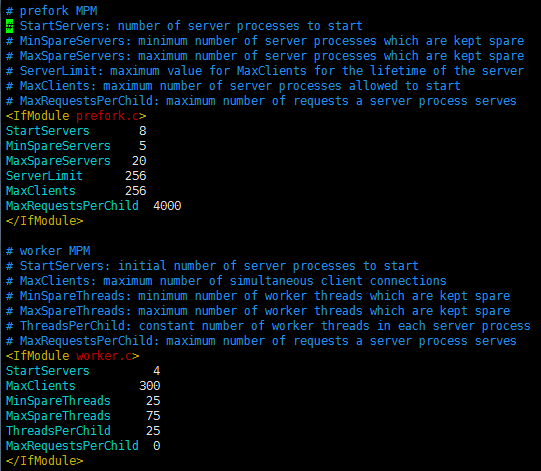
prefork:
<IfModule...>:意为如果某个模块配置(启用)了的话,是Apache中的一种重要的指令使用机制,其中的指令只对这一个片段有效;可以理解为容器,这个容器装有所有的配置属性,只对这个容器对应的那个对象生效;
StartServers:服务器刚启动时启动的空闲进程数;
MinSpareServers:最小空闲进程数;
MaxSpareServers:最大空闲进程数;
MaxClients:最多允许多少个请求数同时连接;
ServerLimit:指定MaxClients的上限值,需要先关掉服务器,kill掉进程再重启服务器才可生效;
MaxRequestsPerChild:Web服务会生成很多个服务器进程,这些进程接收用户请求,用户请求结束了,那这个进程就空闲了,空闲后可能没办法kill了,因为又有新的用户请求需要予以响应,此处定义每一个进程最多响应多少次;
worker:
StartServers:刚开始启动的进程数;
ThreadPerChild:每一个进程可以生成多少个线程;
MinSpareThreads、MaxSpareThreads定义的是总体线程数,而不是单个进程的线程数;
查看当前服务器支持的模型:(不包括worker模型):
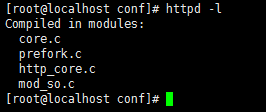
httpd -l #列出当前服务器进程编译的时候所支持的模块
httpd_core.c、core:不仅包括httpd还包括反向代理等各种额外的功能,还包括缓存等;
mod_so:支持动态模块加载;

若将来想使用worker模型的服务的话,使用httpd.worker即可,httpd默认使用的是prefork。
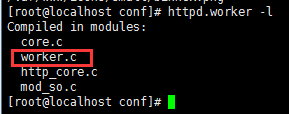
演示使用worker模型的Web服务器:
修改服务器的启动脚本配置文件即可:

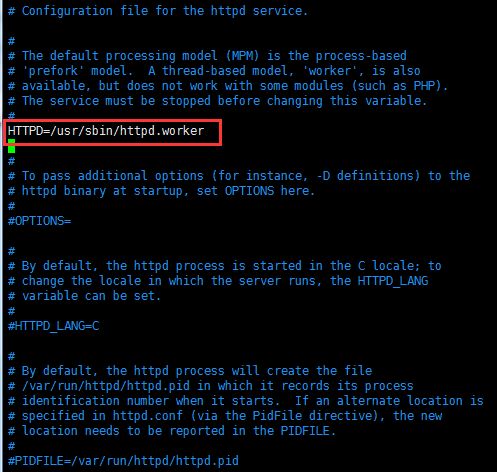
若使用event模型,改成event即可:
在httpd2.2中,event是测试模型,不建议使用,2.4以后event才真正成熟起来并成为独立的rpm。
继续来看我们httpd的配置文件:

Listen:指定监听的地址和端口,地址可省略,若不带IP地址,说明监听当前主机上的所有地址的80端口。Listen指令可出现多次,因此可以指定不同的端口;
LoadModule:指定Apache启动时装载的模块,格式:LoadModule 模块名称 模块路径;

include conf.d/*.conf:包含其它配置文件;
User、Group:Apache的work进程都要使用普通用户运行,故此处指定这个普通用户与组

 浙公网安备 33010602011771号
浙公网安备 33010602011771号