Protocol Buffer
Protocol buffers是google使用的一种结构化数据序列化编码解码方式,采用简单的二进制格式,他比XML、JSON格式体积更小,编码解码效率更高 下面是项目官方网站与XML对比的描述: # are 3 to 10 times smaller # are 20 to 100 times faster 这里有一个.NET环境下的对比测试:Results of Northwind database rows serialization benchmarks,用的是.NET下面的实现ProtoBuf.net protobuf项目(C++),.NET下的实现有:protobuf-net、protobuf-csharp-port。另外一个.NET的项目是Proto#,不过作者似乎没有维护了
使用方式简介
首先定义消息类型: message Person { required string name = 1; required int32 id = 2; optional string email = 3;
enum PhoneType { MOBILE = 0; HOME = 1; WORK = 2; }
message PhoneNumber { required string number = 1; optional PhoneType type = 2 [default = HOME]; }
repeated PhoneNumber phone = 4; } Field Rules: 属性规则,required: 必须的属性;optional: 可选属性;repeated: 可重复多个的属性 Field Type: 属性数据类型,标量值类型(scalar value types)支持double, float, int32, int64, uint32, uint64, sint32, sint64, fixed32, fixed64, bool, string, bytes等,另外支持枚举、嵌套/引用的消息类型等 Field Tags: 属性标签(例如name=1中的1),使用正整数表示,在序列化的二进制中使用这个标签来标记属性,比使用属性名称体积更小 详细的语法参考官方网站:Language Guide
消息类型定义在.proto文件中,使用protoc.exe根据.proto文件生成C++、Java、Python等类文件,这些类文件中定义了表示消息的对象,以及用于编码、解码的方法
体积方面,首先从上面消息类型的定义中可以看出,使用属性标签代替属性名称可以减小体积,另外在编码协议上对各种数据类型的处理,也尽量采用了压缩的表示方式以减小体积。速度方面,二进制协议比基于文本的解析更有优势
编码协议简介 - 2.3.0
详细的编码协议参考官方网站的Encoding Base 128 Varints 32位整数使用4字节存储,32位的整数值1同样要使用4个字节,比较浪费空间。Varint采用变长字节的方式存储整数,将高位为0的字节去掉,节约空间 高位为0的字节去掉以后,用来存储整数的每一个字节,其最高有效位(most significant bit)用作标识位,0表示这是整数的最后一个字节,1表示不是最后一个字节;其他7位用于存储整数的数值。字节序采用little-endian 示例: 整数1,Varint的二进制值为0000 0001。因为1个字节就足够,所以最高有效位为0,后7位则为1的原码形式 整数300,Varint需要2字节表示,二进制值为1010 1100 0000 0010。第一个字节最高有效位设为1,最后一个字节最高有效位设为0。解码过程如下: a). 首先每个字节去掉最高有效位,得到:010 1100 000 0010 b). 按照little-endian方式处理字节序,得到:000 0010 010 1100 c). 二进制值100101100即为300
ZigZag编码 Varint对于无符号整数有效,对负数无法进行压缩,protocol buffer对有符号整数采用ZigZag编码后,再以varint形式存储 对32位有符号数,ZigZag编码算法为 (n << 1) ^ (n >> 31),对64位有符号数的算法为(n << 1) ^ (n >> 63) 注意:32位有符号数右移31位后,对于正数所有位为0,对于负数所有位为1 编码后的效果是0=>0, -1=>1, 1=>2, -2=>3, 2=>4……,即将无符号数编码为有符号数表示,这样就能有效发挥varint的优势了
Protocol buffer用32位表示float和fixed32,用64位表示double和fixed64 String, bytes, 嵌入式消息等数据均采用定长数据类型(length-delimited)表示,这类数据在开始位置使用一个varint表示数据的字节长度,后面接着是数据值
消息结构 消息的所有属性都序列化为key-value pair(键-值对)的字节流形式,字节流中不包含属性的名称和声明的类型,这些信息必须从定义的消息类型中获取 key里面包含2个东西,一个是在消息类型里面为该属性指定的field tag,另一个是protocol buffer协议的封装类型(wire type)。这2个部分都是正整数,使用 (field_tag << 3) | wire_type 方式生成一个正整数,然后使用base 128 varint方式表示。key后面跟着是属性的值 wire type: <!--[endif]-->
示例: 消息类型如下 message Test1 { required int32 attr = 1; } 创建一个Test1的对象,将其属性attr的值设置为150,则对该对象编码过程如下 属性数据类型为int32,其wire type为0,所以key值为 (1 << 3 ) | 0 => 0000 1000 属性值150采用Varint编码 150 => 10010110 //二进制 => 000 0001 001 0110 //7位一组分开 => 001 0110 000 0001 //little-endian字节序 => 1001 0110 0000 0001 //设置最高标识位 => 96 01 //16进制 所以这个Test1对象编码后的16进制值为:08 96 01
如果有嵌入式消息类型定义如下 message Test3 { required Test1 c = 3; } 编码后的16进制值形如:1A 03 08 96 01,其中08 96 01就是上面示例的Test1对象,在Test3的属性中他与字符串的处理方式一样,前面的03就是表示其长度的varint
protobuf-csharp-port的使用方式
protobuf-csharp-port跟protobuf的使用方式一样,即在开发过程中使用protoc.exe、ProtoGen.exe生成用于序列化、反序列化时的消息对象,在运行时通过这些对象进行编码解码 从GitHub下载项目源代码(目前还没有发布包),项目中带有示例AddressBook 生成消息通讯用的C#类分2个步骤 步骤1:使用lib目录下的protoc.exe生成二进制表示 protoc --descriptor_set_out=addressbook.protobin --proto_path=..\protos --include_imports ..\protos\tutorial\addressbook.proto 步骤2:使用编译生成的ProtoGen.exe从二进制表示生成C#类 ProtoGen.exe addressbook.protobin 会生成几个.cs文件,其中包括AddressBookProtos.cs,这个就是在addressbook.proto中定义的消息类型 运行时的项目需要引用编译生成的Google.ProtocolBuffers.dll,使用AddressBookProtos.cs完成编码解码操作,详细用法查看示例项目AddressBook 运行AddressBook.exe如下图: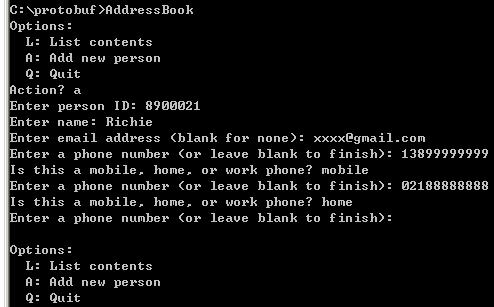 输入的对象序列化为二进制后,默认保存在addressbook.data文件中,可以使用ProtoDump.exe读取这个二进制文件:
输入的对象序列化为二进制后,默认保存在addressbook.data文件中,可以使用ProtoDump.exe读取这个二进制文件: 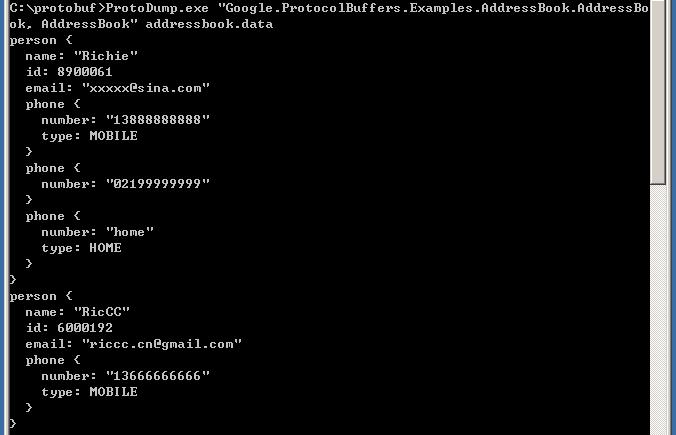
protobuf-net的使用方式 - r282
protobuf-net的使用与Google的protobuf完全不一样,他采用.NET的编程方式,可以非常方便的在.NET的序列化场景下使用,支持WCF的DataContact,WCF程序几乎不需要什么修改就能使用protobuf-net 下载protobuf-net,项目引用protobuf-net.dll,测试对象定义如下:
测试代码如下:
运行结果: 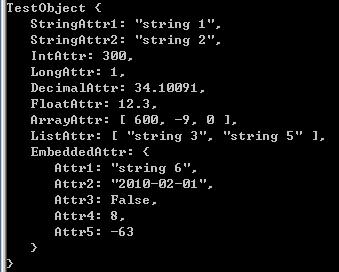
附录
原码、反码、补码 对有符号数,最高位是符号位。正数的原码反码和补码都是一样的,就是本身。负数的反码是原码求反,补码是反码加1。例如-1的原码是1000 0001,反码是1111 1110,补码是1111 1111。负数都是用补码表示,从正数的原码推负数的二进制表示(补码)时,只须将正数各个位(包括符合位)取反加1 补码有2种,即one's complement (1's complement,1的补码) 和 two's complement (2's complement,2的补码) 。按照定义,one's complement就是对各个位取反,two's complement是对各个位取反后加1。例如在8位处理器情况下,9的二进制是0000 1001,one's complement是1111 0110,two's complement是1111 0111 采用one's complement表示负数时存在正0 (0x00)和负0 (0xff),并且有符号数相加必须采用end-around carry(循环进位)处理,例如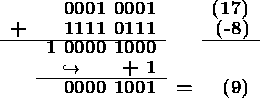 相加之后发生溢出,则必须将溢出位加到最低位上,这样导致有符号数相加和无符号数相加算法不一致,而采用two's complement表示时不存在这些问题 关于2的补码表示可以参考阮一峰的关于2的补码一文,更专业的说明可以参考wikipedia上的Method of complements:二进制的基数补码(radix complement)叫做2的补码,二进制的基数减一补码(diminished radix complement)叫做1的补码;十进制的基数补码叫做10的补码,基数减一补码叫做9的补码
相加之后发生溢出,则必须将溢出位加到最低位上,这样导致有符号数相加和无符号数相加算法不一致,而采用two's complement表示时不存在这些问题 关于2的补码表示可以参考阮一峰的关于2的补码一文,更专业的说明可以参考wikipedia上的Method of complements:二进制的基数补码(radix complement)叫做2的补码,二进制的基数减一补码(diminished radix complement)叫做1的补码;十进制的基数补码叫做10的补码,基数减一补码叫做9的补码
使用方式简介
首先定义消息类型: message Person { required string name = 1; required int32 id = 2; optional string email = 3;
enum PhoneType { MOBILE = 0; HOME = 1; WORK = 2; }
message PhoneNumber { required string number = 1; optional PhoneType type = 2 [default = HOME]; }
repeated PhoneNumber phone = 4; } Field Rules: 属性规则,required: 必须的属性;optional: 可选属性;repeated: 可重复多个的属性 Field Type: 属性数据类型,标量值类型(scalar value types)支持double, float, int32, int64, uint32, uint64, sint32, sint64, fixed32, fixed64, bool, string, bytes等,另外支持枚举、嵌套/引用的消息类型等 Field Tags: 属性标签(例如name=1中的1),使用正整数表示,在序列化的二进制中使用这个标签来标记属性,比使用属性名称体积更小 详细的语法参考官方网站:Language Guide
消息类型定义在.proto文件中,使用protoc.exe根据.proto文件生成C++、Java、Python等类文件,这些类文件中定义了表示消息的对象,以及用于编码、解码的方法
体积方面,首先从上面消息类型的定义中可以看出,使用属性标签代替属性名称可以减小体积,另外在编码协议上对各种数据类型的处理,也尽量采用了压缩的表示方式以减小体积。速度方面,二进制协议比基于文本的解析更有优势
编码协议简介 - 2.3.0
详细的编码协议参考官方网站的Encoding Base 128 Varints 32位整数使用4字节存储,32位的整数值1同样要使用4个字节,比较浪费空间。Varint采用变长字节的方式存储整数,将高位为0的字节去掉,节约空间 高位为0的字节去掉以后,用来存储整数的每一个字节,其最高有效位(most significant bit)用作标识位,0表示这是整数的最后一个字节,1表示不是最后一个字节;其他7位用于存储整数的数值。字节序采用little-endian 示例: 整数1,Varint的二进制值为0000 0001。因为1个字节就足够,所以最高有效位为0,后7位则为1的原码形式 整数300,Varint需要2字节表示,二进制值为1010 1100 0000 0010。第一个字节最高有效位设为1,最后一个字节最高有效位设为0。解码过程如下: a). 首先每个字节去掉最高有效位,得到:010 1100 000 0010 b). 按照little-endian方式处理字节序,得到:000 0010 010 1100 c). 二进制值100101100即为300
ZigZag编码 Varint对于无符号整数有效,对负数无法进行压缩,protocol buffer对有符号整数采用ZigZag编码后,再以varint形式存储 对32位有符号数,ZigZag编码算法为 (n << 1) ^ (n >> 31),对64位有符号数的算法为(n << 1) ^ (n >> 63) 注意:32位有符号数右移31位后,对于正数所有位为0,对于负数所有位为1 编码后的效果是0=>0, -1=>1, 1=>2, -2=>3, 2=>4……,即将无符号数编码为有符号数表示,这样就能有效发挥varint的优势了
Protocol buffer用32位表示float和fixed32,用64位表示double和fixed64 String, bytes, 嵌入式消息等数据均采用定长数据类型(length-delimited)表示,这类数据在开始位置使用一个varint表示数据的字节长度,后面接着是数据值
消息结构 消息的所有属性都序列化为key-value pair(键-值对)的字节流形式,字节流中不包含属性的名称和声明的类型,这些信息必须从定义的消息类型中获取 key里面包含2个东西,一个是在消息类型里面为该属性指定的field tag,另一个是protocol buffer协议的封装类型(wire type)。这2个部分都是正整数,使用 (field_tag << 3) | wire_type 方式生成一个正整数,然后使用base 128 varint方式表示。key后面跟着是属性的值 wire type: <!--[endif]-->
|
Type |
Meaning |
Used For |
|
0 |
Varint |
int32, int64, uint32, uint64, sint32, sint64, bool, enum |
|
1 |
64-bit |
fixed64, sfixed64, double |
|
2 |
Length-delimited |
string, bytes, embedded messages, packed repeated fields |
|
3 |
Start group |
groups (deprecated) |
|
4 |
End group |
groups (deprecated) |
|
5 |
32-bit |
fixed32, sfixed32, float |
如果有嵌入式消息类型定义如下 message Test3 { required Test1 c = 3; } 编码后的16进制值形如:1A 03 08 96 01,其中08 96 01就是上面示例的Test1对象,在Test3的属性中他与字符串的处理方式一样,前面的03就是表示其长度的varint
protobuf-csharp-port的使用方式
protobuf-csharp-port跟protobuf的使用方式一样,即在开发过程中使用protoc.exe、ProtoGen.exe生成用于序列化、反序列化时的消息对象,在运行时通过这些对象进行编码解码 从GitHub下载项目源代码(目前还没有发布包),项目中带有示例AddressBook 生成消息通讯用的C#类分2个步骤 步骤1:使用lib目录下的protoc.exe生成二进制表示 protoc --descriptor_set_out=addressbook.protobin --proto_path=..\protos --include_imports ..\protos\tutorial\addressbook.proto 步骤2:使用编译生成的ProtoGen.exe从二进制表示生成C#类 ProtoGen.exe addressbook.protobin 会生成几个.cs文件,其中包括AddressBookProtos.cs,这个就是在addressbook.proto中定义的消息类型 运行时的项目需要引用编译生成的Google.ProtocolBuffers.dll,使用AddressBookProtos.cs完成编码解码操作,详细用法查看示例项目AddressBook 运行AddressBook.exe如下图:
输入的对象序列化为二进制后,默认保存在addressbook.data文件中,可以使用ProtoDump.exe读取这个二进制文件: protobuf-net的使用方式 - r282
protobuf-net的使用与Google的protobuf完全不一样,他采用.NET的编程方式,可以非常方便的在.NET的序列化场景下使用,支持WCF的DataContact,WCF程序几乎不需要什么修改就能使用protobuf-net 下载protobuf-net,项目引用protobuf-net.dll,测试对象定义如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
[ProtoContract]public class TestObject{ [ProtoMember(1)] public string StringAttr1 { get; set; } [ProtoMember(2)] public string StringAttr2 { get; set; } [ProtoMember(3)] public int IntAttr { get; set; } [ProtoMember(4)] public long LongAttr { get; set; } [ProtoMember(5)] public decimal DecimalAttr { get; set; } [ProtoMember(6)] public float FloatAttr { get; set; } [ProtoMember(7)] public int[] ArrayAttr { get; set; } [ProtoMember(8)] public IList<string> ListAttr { get; set; } [ProtoMember(9)] public InnerObject EmbeddedAttr { get; set; } public override string ToString() { StringBuilder sb = new StringBuilder() .Append("TestObject {\r\n") .Append(" StringAttr1: \"").Append(this.StringAttr1).Append("\",\r\n") .Append(" StringAttr2: \"").Append(this.StringAttr2).Append("\",\r\n") .Append(" IntAttr: ").Append(this.IntAttr).Append(",\r\n") .Append(" LongAttr: ").Append(this.LongAttr).Append(",\r\n") .Append(" DecimalAttr: ").Append(this.DecimalAttr).Append(",\r\n") .Append(" FloatAttr: ").Append(this.FloatAttr).Append(",\r\n"); if (this.ArrayAttr != null) { sb.Append(" ArrayAttr: [ "); foreach (int i in this.ArrayAttr) sb.Append(i).Append(", "); sb.Remove(sb.Length - 2, 2); sb.Append(" ],\r\n"); } if (this.ListAttr != null) { sb.Append(" ListAttr: [ "); foreach (string s in this.ListAttr) sb.Append('"').Append(s).Append("\", "); sb.Remove(sb.Length - 2, 2); sb.Append(" ],\r\n"); } if (this.EmbeddedAttr != null) sb.Append(" EmbeddedAttr: ").Append(this.EmbeddedAttr.ToString()).Append("\r\n"); return sb.Append("}").ToString(); }}[ProtoContract]public class InnerObject{ [ProtoMember(1)] public string Attr1 { get; set; } [ProtoMember(2)] public DateTime Attr2 { get; set; } [ProtoMember(3)] public bool Attr3 { get; set; } [ProtoMember(6)] public byte Attr4 { get; set; } [ProtoMember(9)] public sbyte Attr5 { get; set; } public override string ToString() { return new StringBuilder() .Append("{\r\n") .Append(" Attr1: \"").Append(this.Attr1).Append("\",\r\n") .Append(" Attr2: \"").Append(this.Attr2.ToString("yyyy-MM-dd")).Append("\",\r\n") .Append(" Attr3: ").Append(this.Attr3).Append(",\r\n") .Append(" Attr4: ").Append(this.Attr4).Append(",\r\n") .Append(" Attr5: ").Append(this.Attr5).Append("\r\n") .Append(" }").ToString(); }} |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
using (MemoryStream ms = new MemoryStream()){ TestObject obj = new TestObject() { StringAttr1 = "string 1", StringAttr2 = "string 2", IntAttr = 300, LongAttr = 1, DecimalAttr = 34.10091M, FloatAttr = 12.3f, ArrayAttr = new int[] { 600, -9, 0 }, ListAttr = new List<string> { "string 3", "string 5" }, EmbeddedAttr = new InnerObject() { Attr1 = "string 6", Attr2 = new DateTime(2010, 2, 1), Attr3 = false, Attr4 = 8, Attr5 = -63 } }; Serializer.Serialize<TestObject>(ms, obj); ms.Flush(); ms.Position = 0; TestObject obj2 = Serializer.Deserialize<TestObject>(ms); Console.WriteLine(obj2); Console.ReadKey();} |
附录
原码、反码、补码 对有符号数,最高位是符号位。正数的原码反码和补码都是一样的,就是本身。负数的反码是原码求反,补码是反码加1。例如-1的原码是1000 0001,反码是1111 1110,补码是1111 1111。负数都是用补码表示,从正数的原码推负数的二进制表示(补码)时,只须将正数各个位(包括符合位)取反加1 补码有2种,即one's complement (1's complement,1的补码) 和 two's complement (2's complement,2的补码) 。按照定义,one's complement就是对各个位取反,two's complement是对各个位取反后加1。例如在8位处理器情况下,9的二进制是0000 1001,one's complement是1111 0110,two's complement是1111 0111 采用one's complement表示负数时存在正0 (0x00)和负0 (0xff),并且有符号数相加必须采用end-around carry(循环进位)处理,例如
相加之后发生溢出,则必须将溢出位加到最低位上,这样导致有符号数相加和无符号数相加算法不一致,而采用two's complement表示时不存在这些问题 关于2的补码表示可以参考阮一峰的关于2的补码一文,更专业的说明可以参考wikipedia上的Method of complements:二进制的基数补码(radix complement)叫做2的补码,二进制的基数减一补码(diminished radix complement)叫做1的补码;十进制的基数补码叫做10的补码,基数减一补码叫做9的补码
 浙公网安备 33010602011771号
浙公网安备 33010602011771号