
C语言字符函数与内存函数(让你的代码缩短一倍)

目录
1.size_t strlen( const char *string );
2.char *strcpy( char *strDestination, const char *strSource )
3.char *strcat( char *strDestination, const char *strSource )
4.int strcmp( const char *string1, const char *string2 )
2.char *strncpy( char *strDest, const char *strSource, size_t count )
3.char *strncat( char *strDest, const char *strSource, size_t count )
4.int strncmp( const char *string1, const char *string2, size_t count )
2.char *strstr( const char *string, const char *strCharSet )
3.char *strtok( char *strToken, const char *strDelimit )
1.void *memcpy( void *dest, const void *src, size_t count )
2.void *memmove( void *dest, const void *src, size_t count )
3.int memcmp( const void *buf1, const void *buf2, size_t count )
4.void *memset( void *dest, int c, size_t count )
1.char *strerror( int errnum )
零.前言
年少不知库函数好,错把硬钢当成宝。了解下面的库函数,学会代码的缩“码”入“库“。
1.求字符串的长度
1.size_t strlen( const char *string );
1.含义:
MSDN:get the length of strlen(得到字符串的长度)
2.参数:
const char *string
即传入一个字符串的地址,即字符串首元素的地址。
3.返回值:
返回一个无符号的整型size_t。
证明:
#include<stdio.h>
int main()
{
if (strlen("abcde") - strlen("abcdefg") > 0)
{
printf("haha\n");
}
else
{
printf("hehe\n");
}
return 0;
}打印的结果是:
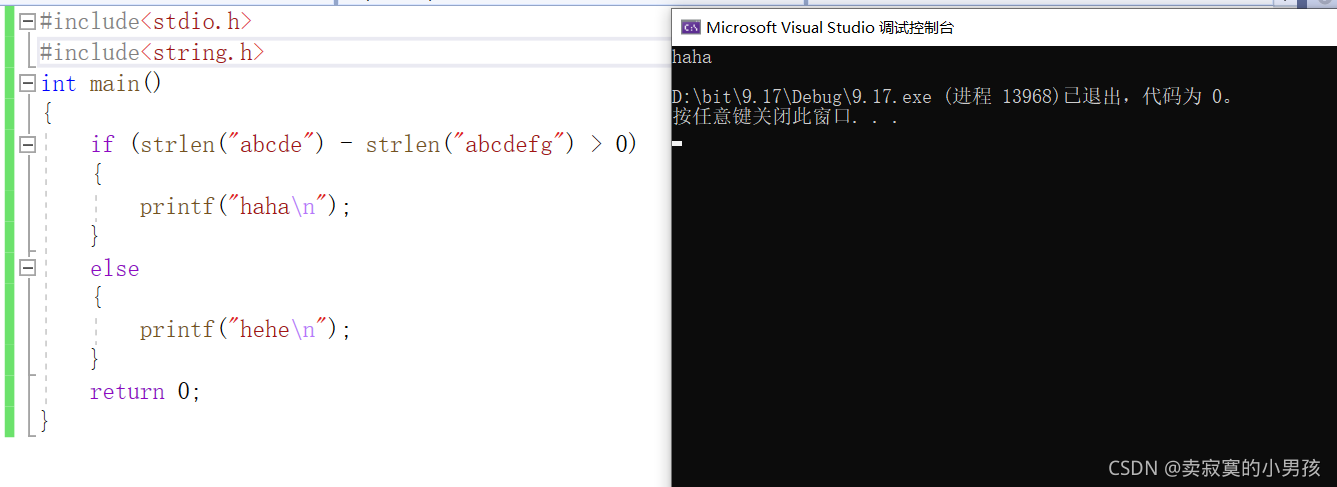
如果是一个有符号数的话就会是一个负数,就会打印hehe,但是这里打印的是haha所以返回的是一个无符号数 。
插一句,第一次打印的时候我没引用头文件,结果打印出来了hehe,这是因为没引用头文件的时候,会将返回值默认为int型的0,0-0=0,所以打印的是hehe。
原理:
strlen函数从传入的地址开始查找字符,每查找到一个字符返回值就加一,直到找到'\0',如果查找的字符串时{'a','b','c'}没有加入'\0',strlen会在内存中继续向下查找,直到找到'\0'为止,所以则返回的是一个随机值。
2.长度不受限的字符串函数
1.解释
所谓长度不受限制的字符串函数,就是字符串的引用是由'\0'控制的,而不是人为规定的。
2.char *strcpy( char *strDestination, const char *strSource )
1.含义
将后一个字符串从前往后依次拷贝到前一个字符串中,包括‘\0’。第一个字符串剩余的内容在内存中保留。
2.参数
参数为接收两个字符串的地址.
3.返回值
返回第一个字符串。
4.用法
#include<stdio.h>
#include<string.h>
int main()
{
char arr1[] = "abcdef";
char arr2[] = "efgh";
strcpy(arr1, arr2);
printf("%s", arr1);
return 0;
}将字符串arr2拷贝到arr1中,打印的结果是:
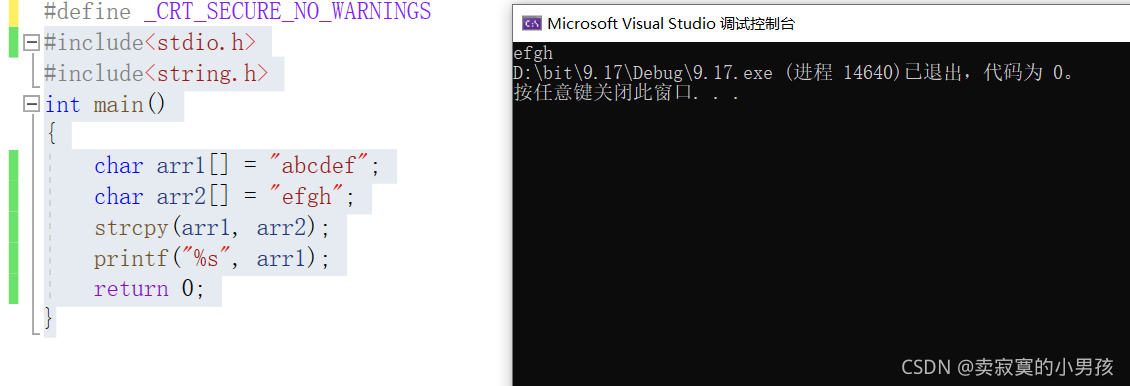
5.两种报错原因
后一个字符串中没有‘\0’。比如这样定义字符串
char a[]={'a','b','c'}2.第一个字符串的长度小于第二个字符串的长度。
3.char *strcat( char *strDestination, const char *strSource )
1.含义
字符串连接。将字符串strSource连接到strDestination上。
2.参数
第一个参数为被连接的字符串的首元素地址,第二个参数用const修饰,表示不可改变的字符串,为连接的字符串的首元素的地址。
3.返回值
返回的是被连接的字符串的首元素地址。
4.用法
char arr1[20] = "abcd";
char arr2[] = "efgh";
strcat(arr1, arr2);
printf("%s", arr1);将字符串arr2连接到arr1的后面,打印的结果是:

5.注意事项
1.数组arr1要留足空间,如果定义的数组arr1是char arr1[]="abcd"的话,将数组arr2拷贝过来的时候,开辟的空间是不够的,会出现报错,所以才开辟了一个较大的空间arr1[20]。
2.数组arr2是需要有末尾的'\0'的,找到'\0'之后将arr2中的内容链接到arr1中,如果arr2这样定义arr[]={'e','f','g','h'}的话,编译器会出现报错。
6.模拟实现
char* my_strcat(char* dest, char* src)
{
char* flag = dest;
while (*dest)
{
dest++;
}
while (*dest++ = *src++)
{
;
}
return flag;
}4.int strcmp( const char *string1, const char *string2 )
1.含义
字符串比较函数,比较字符串string1和string,从首地址开始逐个比较。
2.参数
const修饰无法改变的变量,string1和string2分别接收需要比较的两个字符串的首元素的地址。
3.返回值
返回值是int,如果两字符串相同则返回0,如果string1的字符的ascii值小于string2的字符的ascii值则返回一个负数,反之则返回一个正数。
4.用法
char arr1[] = "abcdefg";
char arr2[] = "abcdefh";
int ret;
ret = strcmp(arr1, arr2);
printf("%d", ret);
打印的结果是:
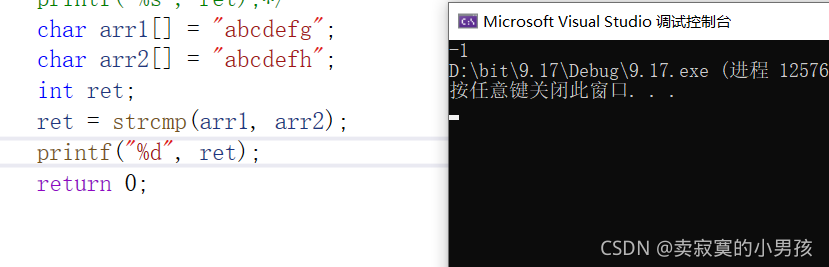
当比较到最后一个字符的时候,由于g的ascii值小于h的ascii值,所以打印的是一个负数值。
5.注意事项
如果两个字符串的长度不相等时,在短的字符串比较完之后,使用长字符串的字符与'\0'比较。
6.模拟实现
int my_strcmp(const char* str1, const char* str2)
{
while (*str1 == *str2)
{
if (*str1 == 0)
{
return 0;
}
str1++;
str2++;
}
return *str1 - *str2;
}3.长度受限制的字符串函数
1.解释
所谓长度受限制的字符串函数,就是字符串的引用不是由'\0'控制的,而是人为规定的。
2.char *strncpy( char *strDest, const char *strSource, size_t count )
1.含义
以规定的个数拷贝字符串。
2.参数
strDest是被拷贝函数的首元素的地址,strSource是拷贝函数的首元素的地址,无符号数count指从strSource中字符串首元素开始,拷贝元素的个数。
3.返回值
返回的是被拷贝函数的地址。
4.用法
char arr1[] = "abcdefghi";
char arr2[] = "xxxx";
char* ret = strncpy(arr1, arr2, 4);
printf("%s", ret);打印的结果是:

注意与strcpy的区别,strcpy是将整个字符串替换,这里规定的是替换了多少个字符。
5.注意事项
如果这段代码中的4改成6,但是此时arr2中只有5个元素,那么也会覆盖arr1中的六个元素,并且在abcd被x覆盖之后,e和f都是被'\0'覆盖的。我们可以调试起来看一下arr1中的值:
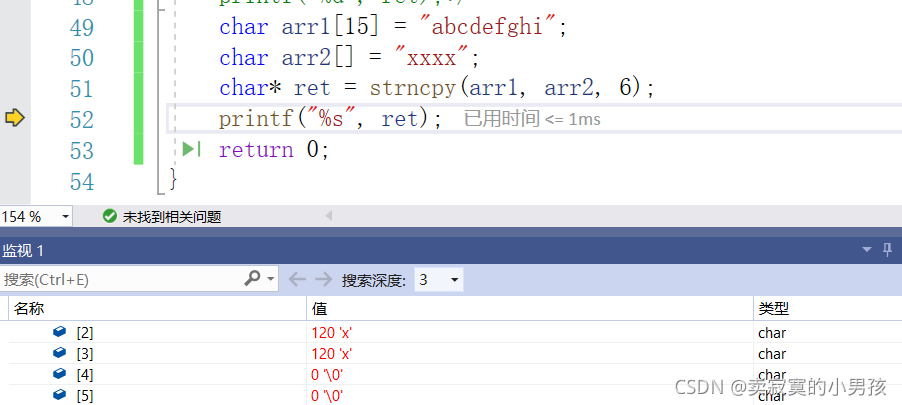 这说明如果想要覆盖的元素多于arr2中的元素个数的时候,不够的用'\0'来覆盖。
这说明如果想要覆盖的元素多于arr2中的元素个数的时候,不够的用'\0'来覆盖。
3.char *strncat( char *strDest, const char *strSource, size_t count )
1.含义
链接两个字符串strDest与strSource,并且人为限定链接字符个数。
2.参数
strDest表示被链接的函数的首元素地址,strSource表示的是链接函数的首元素地址,无符号数count表示的是链接的字符的个数。
3.返回值
返回的是被连接函数的首元素地址。
4.用法
char arr1[10] = "abcd";
char arr2[] = "efg";
char* ret = strncat(arr1, arr2, 2);
printf("%s", ret);打印的结果是:

最终arr1字符串变成了abcdef
5.注意事项
如果将最后一个参数2改成6,由于arr2中只有4个元素,差的两个会用'\0'补位,调试观察到的结果是这样的。
4.int strncmp( const char *string1, const char *string2, size_t count )
1.含义
表示比较两个字符串string1与string2的前count个元素。
2.参数
string1和string2表示的是两个字符串的首元素地址,count表示的是要比较两个字符串的前count个元素。
3.返回值
如果前count个元素相等返回0,如果比较的字符,第一个字符串的ascii值小于第二个字符串的ascii值则返回一个小于0的数(注意不一定返回的就是-1),反之则返回一个大于0的数。
4.用法
char arr1[] = "abcdef";
char arr2[] = "abcfrg";
int ret;
ret = strncmp(arr1, arr2, 3);
printf("%d", ret);打印的结果是:
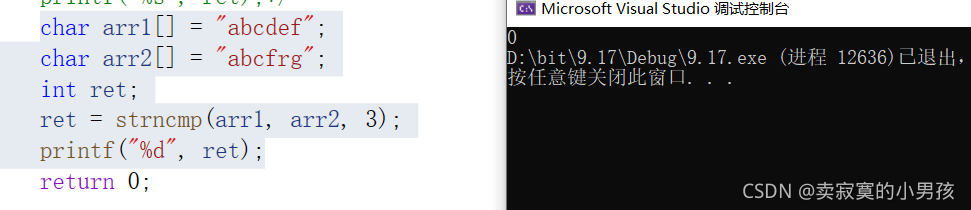
注意这里只比较了前三个字符,所以返回值是0。
4.字符串查找函数
1.解释
即使用函数过程中对字符串进行了查找。
2.char *strstr( const char *string, const char *strCharSet )
1.含义
在字符串查找字符串。
2.参数
string为被查找字符串的首元素地址,strCharSet为所需要查找的字符串的首元素地址。
3.返回值
返回的是strCharSet这个字符串在string中第一次出现时的首元素的地址。
如果没找到则返回空指针。
4.用法
char arr1[] = "I am the king of Asgard";
char arr2[] = "king";
char* ret = strstr(arr1, arr2);
printf("%s", ret);打印的结果是:

由于查找的是king这个字符串,找到了,所以返回arr1中第一次出现king的地址,从这个地址向后打印的结果就是king of Asgard.
5.模拟实现
1.正常实现
char* my_strstr(const char* str1, const char* str2)
{
char* p1;
char* p2;
char* cp=str1;
if (*str2 == '\0');
{
return str1;
}
while (*cp)
{
p1 = cp;
p2 = str2;
while (*p1 == *p2 && *p1 && *p2)
{
p1++;
p2++;
}
if (*p2 == '\0')
{
return cp;
}
cp++;
}
return NULL;
}2.KMP算法实现
我还是专门开一篇博客讲KMP算法的实现吧,在这里可能讲不完,我们今天的主题是字符串函数与内存函数。
3.char *strtok( char *strToken, const char *strDelimit )
1.含义
字符串切割函。
2.参数
strToken表示被切割字符串的首元素地址,strDelimit表示的是以哪些分隔符为标准进行切割,把这些标准放入一个字符数组中,strDelimit表示的就是这个字符数组的首元素的地址。
3.返回值
返回的是一个被切的字符串的首元素的地址,通过这个地址分别打印被分割的字符串。
4.注意事项
1.strDelimit作为定义分隔符字符的集合。
2.被分割的字符串包含了0个或者多个分隔符串中的1个或多个分隔符。
3.strtok函数找到被分割函数的下一个标记,并将之用'\0'结尾,并返回'\0'标记前的首元素的地址。
4.strtok每标记一个子字符串会记录标记的'\0'的下一个地址。
5.strtok会改变被操作的字符串,所以在使用strtok进行字符串的切分的时候,要先临时拷贝字符串的内容然后再进行切分。
6.若一个字符串中有多个切割符,每使用一次strtok函数只能打印出一个子字符串,下一次再使用strtok将第一个变量置为NULL,那么默认strtok函数从第一次标记之后的位置开始执行,即标记完'\0'的位置的下一个位置元素的地址开始。因此只有第一次使用时需要的是被分割函数的首元素的地址,之后的几次都要用NULL代替。
5.用法
char arr1[] = "you nearly caught Jack Sparrow.";
char arr2[] = " ";
char* ret = NULL;
for (ret = strtok(arr1, arr2); ret != NULL; ret=strtok(NULL, arr2))
{
printf("%s\n", ret);
}打印的结果是:

这里给大家看一下内存:
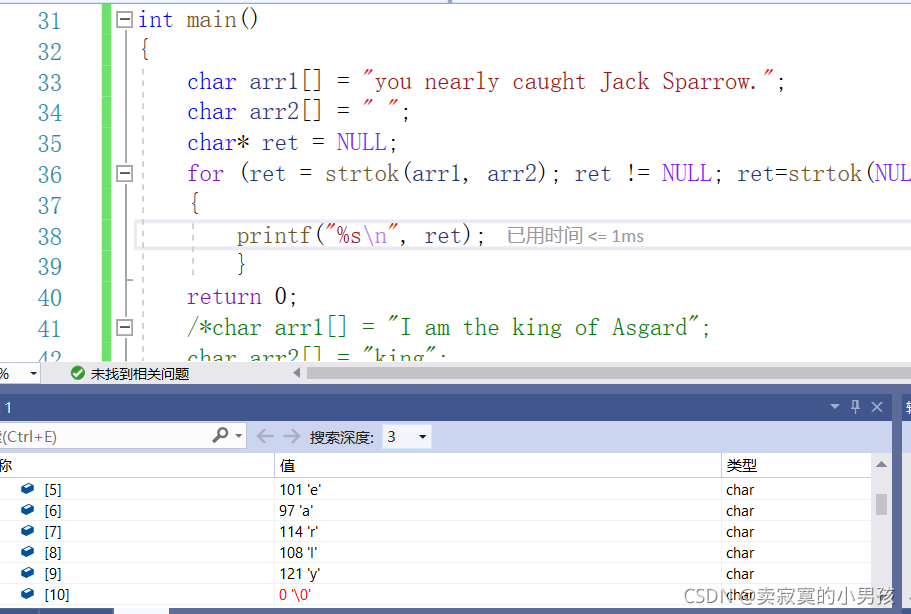
这是循环第二次进行,我们看到这个函数将nearly后面的' '砍掉补上了一个'\0',每一次执行都改变了字符串的内容。
5.内存操作函数
1.void *memcpy( void *dest, const void *src, size_t count )
1.含义
内存拷贝函数。
2.参数
void* dest表示了一个空类型的指针dest,空类型的指针可以指向任意形式的地址,dest表示被拷贝的内容的首元素地址,src表示的是拷贝内容的首元素地址,无符号整型count表示的是一共拷贝的字节个数。
3.返回值
返回的是被拷贝内容的首元素的地址。
4.用法
int arr1[] = { 1,2,3,4,5,6,7,8,9,10 };
int arr2[10] = { 0 };
memcpy(arr2, arr1, 10 * sizeof(arr1[0]));
int i;
for (i = 0; i < 10; i++)
{
printf("%d", arr2[i]);
}打印的结果是:
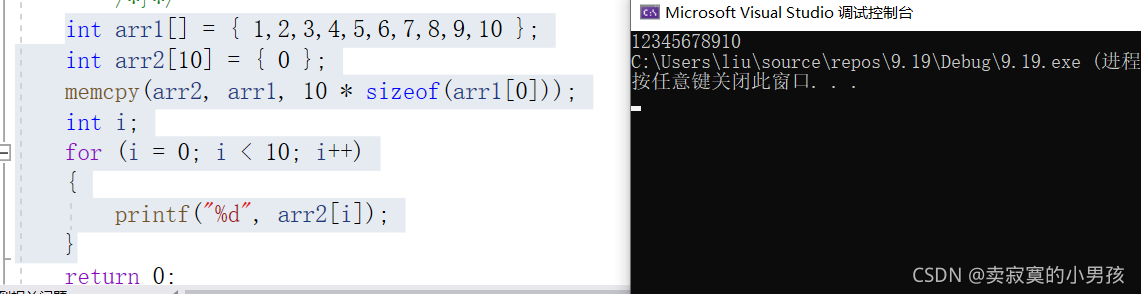
5.模拟实现
void* my_memcpy(void* str1, void* str2, size_t num)
{
void* ret = str1;
int i;
for(i=0;i<num;i++)
{
*(char*)str1 = *(char*)str2;
str1 = (char*)str1 + 1;
str2 = (char*)str2 + 1;
}
return ret;
}2.void *memmove( void *dest, const void *src, size_t count )
1.含义
这也是一个字符串拷贝函数,与上一个不同的是我们经常使用这个函数拷贝自己本身。
2.参数
dest表示的是被拷贝内容的首元素地址,src表示的是拷贝内容的首元素地址,无符号整型count表示的是拷贝内容所占字节数。
3.返回值
返回的是被拷贝内容的首元素地址。
4.用法
int arr[] = { 1,2,3,4,5,6,7,8,9 };
memmove(arr + 2, arr, 2 * sizeof(arr[0]));
int i;
for (i = 0; i < 9; i++)
{
printf("%d", arr[i]);
}打印的结果是:
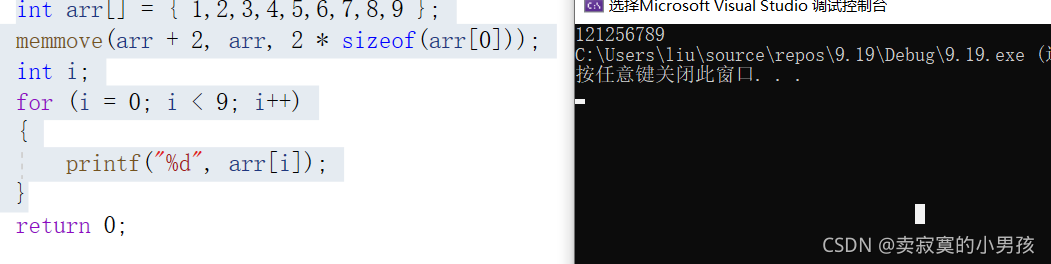
这里拷贝了从第三个元素开始拷贝了字符串本身的两个元素。
5.模拟实现
void* my_memmove(void* dest, void* src, size_t count)
{
void* ret = dest;
if (dest < src)
{
while (count--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
}
else
while (count--)
{
*((char*)dest + count) = *((char*)src + count);
}
return ret;
}注意当两个指针位置不同的时候操作是不同的,当dest指针在前面时,应该从后向前拷贝,当dest指针在后面时要从前向后拷贝。否则拷贝的内容会出现覆盖。
3.int memcmp( const void *buf1, const void *buf2, size_t count )
1.含义
内存对比函数。
2.参数
void* buf1与void* buf2只两个被比较内存的首地址,无符号整型count表示的是比较内存的字节个数。
3.返回值
如果两者相等则返回0,如果第一个比第二个大,返回小于0的数,如果第二个比第一个大则返回大于0的数。
4.用法
int arr1[] = { 1,2,3,4,5 };
int arr2[] = { 1,2,3,6,6 };
int ret;
ret = memcmp(arr1, arr2, 3 * sizeof(arr1[0]));
printf("%d", ret);打印的结果是:
4.void *memset( void *dest, int c, size_t count )
1.含义
内存置为函数。
2.参数
void* dest表示被置为内存的首地址,c表示将这段内存置为的内容,count表示一共选择多少个字节的内存。
3.返回值
返回的是被置内存的地址。
4.用法
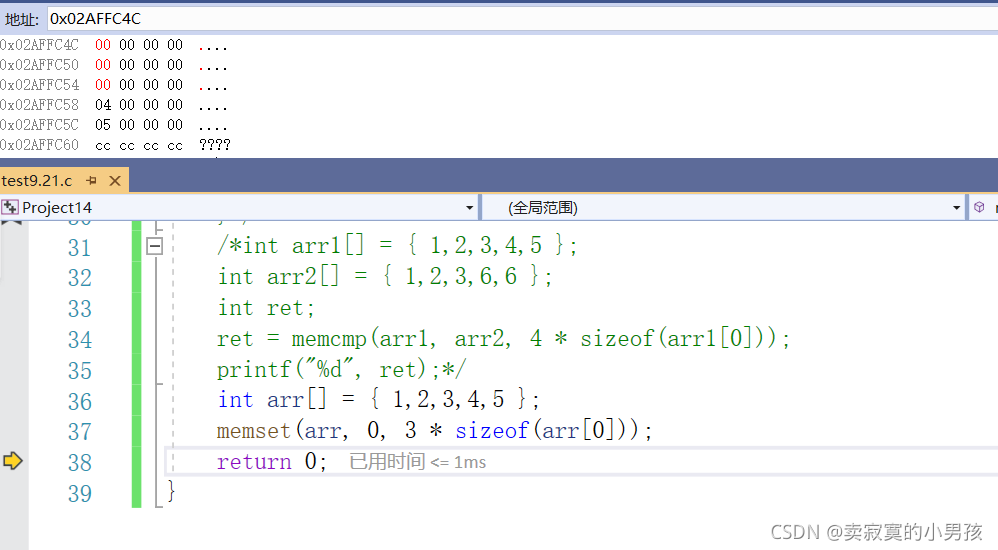
int arr[] = { 1,2,3,4,5 };
memset(arr, 0, 3 * sizeof(arr[0]));我们通过内存来观察结果:
6.错误信息报告函数
1.char *strerror( int errnum )
1.含义
找到错误码传递的错误信息的首地址。需要看着例子理解。
2.参数
errnum为错误码。
3.返回值
返回错误信息的首地址。
4.用法
假设我们要打开一个不存在的文件test.txt
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
printf("%s", strerror(errno));
}打印的结果是:

在strerror函数中传的是errno这一数组,该数组为C语言错误码存放数组。此时存放的是没打开文件的错误码。
7.总结
虽然有这么库函数可以帮助我们实现功能,但我还是建议大家多多了解一下函数的模拟实现,写完这篇文章突然悟到了一个道理,既然好多大型企业都要C++那种面向对象编程,为什么我们还要学习C语言,这是因为C++的库实在是太多了,我们想实现一个功能,一调用就可以实现了。但C语言不同,它更在于探索本质,了解原码,只有了解了本质我们才可以进行创新,从而变成了一个创造性的人才,我们要去成为一个设计师,而非只会用前人的图纸进行搬砖的打工人。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律