
Python爬虫之数据存储(无数据库版)
Python对HTML正文抽取后存储为两种格式:JSON和CSV
一、存储为JSON:
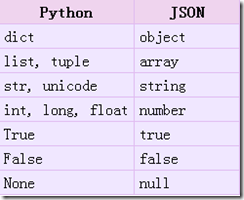
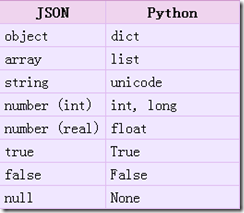
Python对JSON文件的操作分为编码和解码,通过JSON模块来实现。编码过程是把Python对象转换成JSON对象的一个过程,常用的两个函数是dumps和dump函数。两个函数的唯一区别就是dump把Python对象转换成JSON对象,并将JSON对象通过fp文件流写入文件中,而dumps则是生成了一个字符串。
dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True,allow_nan=True, cls=None, indent=None, separators=None,default=None, sort_keys=False, **kw)
dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True,allow_nan=True, cls=None, indent=None, separators=None,default=None, sort_keys=False, **kw)
常用参数分析:
Skipkeys:默认值是False,如果dict的keys内的数据不是python的基本类型(str,unicode,int,long,float,bool,None),设置为False时,就会报TypeError的错误。此时设置成True,则会跳过这类key
ensure_ascii:,当它为True的时候,所有非ASCII码字符显示为\uXXXX序列,只需在dump时将ensure_ascii设置为False即可,此时存入json的中文即可正常显示。)
indent:应该是一个非负的整型,如果是0就是顶格分行显示,如果为空就是一行最紧凑显示,否则会换行且按照indent的数值显示前面的空白分行显示,这样打印出来的json数据也叫pretty-printed json
separators:分隔符,实际上是(item_separator,dict_separator)的一个元组,默认的就是(',',':');这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。
encoding:默认是UTF-8,设置json数据的编码方式。
sort_keys:将数据根据keys的值进行排序。
例如:抽取盗墓笔记(http://seputu.com/)的标题,存放在/home/demo.json文件中
from bs4 import BeautifulSoup
import requests
import json
user_agent = 'Mozilla/4.0 (compatible;MSIE 5.5;Window NT)'
headers = {'User-Agent':user_agent}
r = requests.get('http://seputu.com/',headers=headers)
#print(r.text)
soup = BeautifulSoup(r.text,'html.parser')
content = []
for mulu in soup.find_all(class_="mulu"):
h2 = mulu.find('h2')
if h2 != None:
h2_title = h2.string #获取标题
list = []
for a in mulu.find(class_='box').find_all('a'): #获取所有的a标签中url和章节内容
href = a.get('href')
box_title = a.get('title')
list.append({'href':href,'box_title':box_title})
content.append({'title':h2_title,'content':list})
with open('/home/demo.json,'w') as fp:
json.dump(content,fp=fp,ensure_ascii=False,indent=4)
二、存储为CSV:
CSV(Comma-Separated Values,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。
CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列。
特点
-
读取出的数据一般为字符类型,如果是数字需要人为转换为数字
-
以行为单位读取数据
-
列之间以半角逗号或制表符为分隔,一般为半角逗号
-
一般为每行开头不空格,第一行是属性列,数据列之间以间隔符为间隔无空格,行之间无空行。
1、Python使用csv库来读写CSV文件,需要用到Writer对象:
(1)写入CSV文件:
import csv
headers = ['ID','UserName','Password','Age','Country']
rows = [(1001,'aa','123',24,'中国'),
(1002,'bb','111',25,'美国'),
(1003,'cc','222',26,'德国'),
]
with open('/home/demo.csv','w') as f:
f_csv = csv.writer(f)
f_csv.writerow(headers)
f_csv.writerow(rows)
(2)读取CSV文件:
with open('/home/demo.csv') as f:
f_csv = csv.reader(f)
headers = next(f_csv)
print(headers)
for row in f_csv:
print(row)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号