正则化、方差、偏差
1. 正则化
正则化是指,在损失函数的基础上加上了正则化项,即原来的loss function$ \frac{1}{m}\sum_{i=1}^n(y_i-\hat y)^2$ 变为$ \frac{1}{m}\sum_{i=1}^n(y_i-\hat y)^2+\frac{\lambda}{2m} \sum_{i=1}n||w||2$
**正则化的目的是为了防止过拟合 **
正则化可以防止过拟合的原因,从直观意义上讲,我们需要最小化损失函数,由于加了正则化项,所以在最小化损失函数的基础上参数值也越小越好,参数值 $ \theta $ 小的好处是:
1、因为参数值很小,接近于0,可以让减少多项式的项数。
2、参数值很小,可以让函数更平滑,比如带入两个样本点,由于参数值很小,所以预测值波动不大,因此函数更平滑。
1.1 过拟合
在谈正则化之前我们需要先看看为什么需要正则化,先看下面三张图。
第一张图可以看出欠拟合,因为拟合的分界线过于简单,有很多叉形和圆形无法分类正确。
第二张图拟合正常,基本分类正确
第三张图为过拟合,虽然每个点都分类正确,但是分界线过于复杂。过拟合会带来什么问题呢?假如下方代表我们的训练集,因为我们拟合的边界完美的区分了圆跟叉,所以在训练集上的误差是极小的。但是用在测试集上效果就会很差。对比第二张图处于圆形中的叉应该为异常点,所以应该归为圆。那又是什么带来了过拟合呢,我们知道根据泰勒公式,所有的函数多可以用多项式函数进行近似,所以如果我们假设的边界函数的项数过多,就会拟合出非常复杂的线,造成过拟合。比如第一张图片的假设函数(决策边界)为$ f(x_1,x_2) = \theta_0+\theta_1 x_1+\theta_2 x_2 $ ,而第三张图片的假设函数为\(f(x_1,x_2)=\theta_0 + \theta_1 x_1 +\theta_2 x^2_1+\theta_3 x^2_1 x_2+\theta_4 x^2_1 x^2_2+\theta_5 x^2_1 x^3_2+...\)
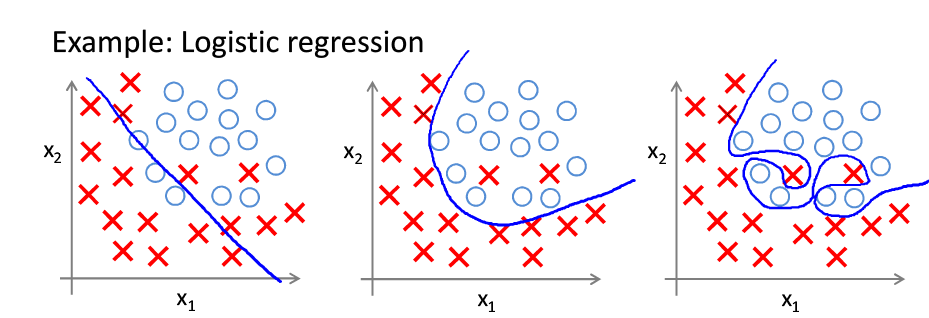
由于过拟合问题的存在我们提出了正则化的概念,正则化的目的就是为了防止过拟合。正则化有L1正则化与L2正则化两种。这里主要说L2正则化
1.2 范数
L1正则化即在损失函数上加上L1正则化项(L1范数),L2正则化即在损失函数上加上L2正则化项(L2范数)。那么什么是范数?
范数是具有“长度”概念的函数,每个向量都对应一个长度,不过不同的范数求出的向量的长度是不同的。比如我们平时求得向量的长度即欧式距离就是L2范数。
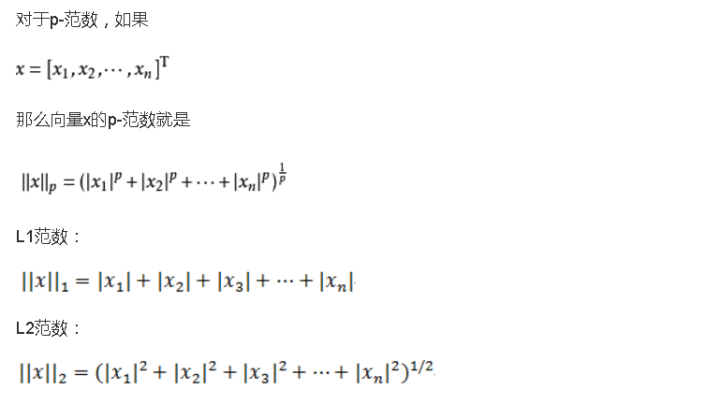
知道什么是范数后,我们可以探讨为什么L2范数可以防止过拟合。L2范数是指向量个元素的平方和然后求平方根, 我们让L2范数的规则项\(||w||^2\)最小,可以使\(w\)的每个元素都很小,都接近于0。但与L1范数不同,L2范数的每一项不会等于0。\(w\)越小,模型越简单,因此拟合的函数就不会太复杂,防止了过拟合。
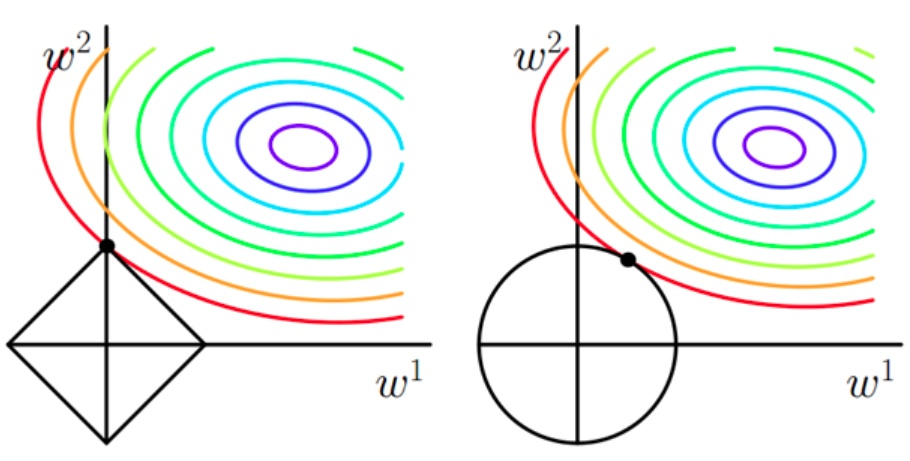
下图直观解释了为什么L1范数会使参数等于0而L2范数不会使参数等于0,图1为L1范数,图2为L2范数
$ L( \theta )=\frac{1}{m}\sum_{i=1}^n(y_i-\hat y)^2+\frac{\lambda}{2m} \sum_{i=1}n||w||2$
菱形或表示L1约束条件即损失函数后面那一项,等高线表示没有正则化的损失函数即损失函数前面那一项,等高线越接近中心,损失函数前面那一项值越小。
我们的目标是等高线很接近中心(损失函数前面那一项很小),同时菱形也很小。这样我们可以看出当菱形与等高线只有一个焦点的时候两个会同时比较小,而因为菱形的原因,交点一般在坐标上,因此\(||w^2||\)的值一般会等于0。
同理图二为L2范数,因为交点不会交在坐标轴上,而会交在附近,因此L2范数可以让解比较小,而不会等于0.
1.3 权重衰减
$ L( \theta )=\frac{1}{m}\sum_{i=1}^n(y_i-\hat y)^2+\frac{\lambda}{2m} \sum_{i=1}n||w||2$
我们对上述公式\(w\)的偏导即梯度
\(\frac {\partial L}{\partial w_i} = (未加正则化的损失函数对w的偏导)+\frac{\lambda}{2m}w_i\)
所以进行梯度下降更新参数时
\(w_i = w_i-\alpha[(未加正则化的损失函数对w的偏导)+\frac{\lambda}{2m}w_i]\)
\(w_i = w_i(1-\alpha\frac{\lambda}{2m})-\alpha(未加正则化的损失函数对w的偏导)\)
发现跟没有加正则化项的梯度下降\(w_i = w_i-\alpha(未加正则化的损失函数对w的偏导)\)相比,因为\((1-\alpha\frac{\lambda}{2m})<1\),\(w_i\)会强制变小,因为乘了一个比1小的数,所以权重在不停的衰减。
1.4 总结
我们平时的正则化是指加了L2范数,由于L2范数的性质,会使参数\(w\)(\(\theta\))的值接近0,因此使假设函数(决策边界)或者说模型变得简单,防止过拟合,在预测的时候就不会波动特别大。因此在测试集上就会表现的比表好。这就是正则。
2. 方差偏差
方差跟偏差也是在谈论模型拟合程度的时候经常说到的问题。
偏差:模型整体的预测值与真实值的偏离程度
方差:模型的预测值之间的离散程度
可以看到偏差是模型与真实值之间的比较,方差是模型自身的比较。下图形象展示了偏差跟方差。
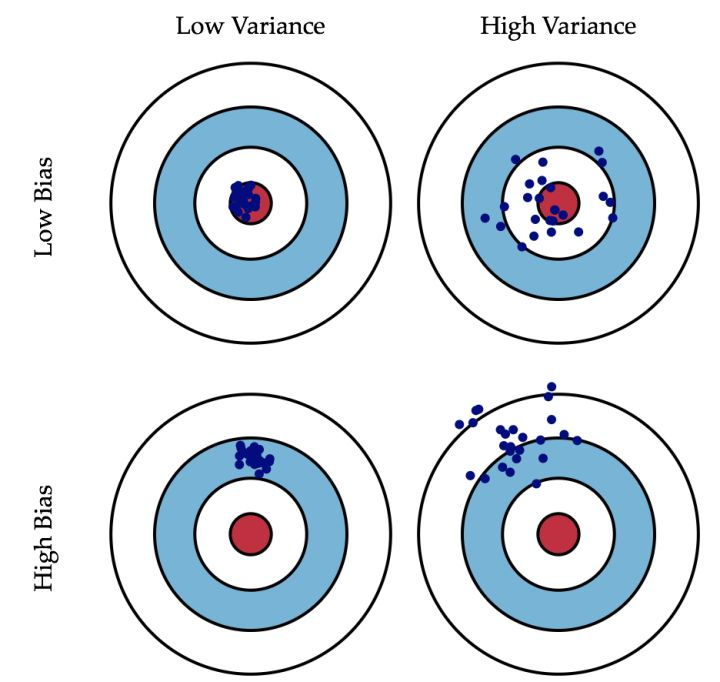
可以看到偏差是指里数据的平均值离靶心的程度,而方差是指数据间的离散程度。
我们平时说模型过于简单欠拟合,是高偏差,低方差。因为预测总是偏离真实值,造成高偏差,但又因为函数简单,预测的值波动不大,聚到一起。因此是低方差。
过拟合相反是高方差,低偏差。因为函数复杂虽然预测也偏离真实值但是是在真实值上下波动,因此低偏差,函数复杂度高,预测值离散程度高,所以高方差
3. 交叉验证
我们在对数据集进行测试的时候要保证,完全不能通过测试集来调整参数跟超参数。因此我们对数据集进行划分的时候可以将数据集划分为训练集,验证集跟测试集。训练集来训练模型参数,验证集来寻找模型超参数,比如正则化参数\(\lambda\)。最后在测试集上进行测试。切记不能通过测试集来调整任何参数。
4.参考
- L1正则化与L2正则化 - bingo酱的文章 - 知乎
https://zhuanlan.zhihu.com/p/35356992 - 偏差和方差有什么区别? - Jason Gu的回答 - 知乎
https://www.zhihu.com/question/20448464/answer/20039077 - L1范数与L2范数的区别 - 鱼涛之欢的文章 - 知乎
https://zhuanlan.zhihu.com/p/28023308

 浙公网安备 33010602011771号
浙公网安备 33010602011771号