python多线程学习三
本文希望达到的目标:
1、服务器端与线程池 (实例demo)
2、并发插入db与线程池(实例demo)
3、线程池使用说明
4、线程池源码解析
一、基于socket的服务器与线程池连接。
1、在i7内核,windows机器下,处理300笔客户端发的请求(客户端开启3个进程,每个进程串行发送数据100笔),为模拟服务器处理过程,服务器在返回数据前,服务器休眠0.5s(如果没有的话,线程池和单进程是一样的效果),使用基于线程池(同时存在10个线程)构建的服务器端,耗时为50s,随时创建随时销毁的服务器端,耗时为140s。
这个对比不能说明很多问题,因为不够真实,一方面客户端的并发量没上去;另一方面服务器端的应答时间比较随意,如果服务器端不sleep 0.5s,导致的结果是两种写法的耗用时间会是差不多的,因为创建单个线程的时间不是很长。但是结果差距的明显,说明了线程池在场景下还是有一定的性能优势的(开启10个进程,每个进程发送数据100笔,基于线程池的服务器也能在50s内处理完成)。
import thread
import time, threading
import socket
host =''
port =8888
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.bind((host,port))
s.listen(3)
class MyThread(threading.Thread):
def __init__(self,func,args,name=''):
threading.Thread.__init__(self)
self.name = name
self.func = func
self.args = args
def run(self):
self.func(*self.args)
def handle_request(conn_socket):
recv_data = conn_socket.recv(1024)
reply = 'HTTP/1.1 200 OK \r\n\r\n'
reply += 'hello world'
time.sleep(0.5)
conn_socket.send(reply)
conn_socket.close()
def main():
while True:
conn_socket, addr = s.accept()
t = MyThread(handle_request,(conn_socket,))
t.start()
t.join()
if __name__ == '__main__':
main()
还有网上重写的线程池,如果需要使用线程池做真正的项目,个人不建议参考网上这些不规范的脚本:
#!/usr/bin/env python #coding=gbk import socket from Queue import Queue from threading import Thread import threading """ 重写threadpool,自定义和实现线程池,实现web服务端多线程处理 """ host ='' port =8888 s = socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.bind((host,port)) s.listen(3) class ThreadPoolManger(): def __init__(self,thread_num): self.work_queue =Queue() self.thread_num = thread_num self._init_threading_pool(self.thread_num) def _init_threading_pool(self,thread_num): for i in range(thread_num): thread= ThreadManger(self.work_queue) thread.start() def add_job(self,func,*args): self.work_queue.put((func,args)) class ThreadManger(Thread): def __init__(self,work_queue): Thread.__init__(self) self.work_queue = work_queue self.daemon =True def run(self): while True: target,args = self.work_queue.get() target(*args) self.work_queue.task_done() def handle_request(conn_socket): recv_data = conn_socket.recv(1024) reply = 'HTTP/1.1 200 OK \r\n\r\n' reply += 'hello world' print 'thread %s is running ' % threading.current_thread().name conn_socket.send(reply) conn_socket.close() thread_pool = ThreadPoolManger(10) while True: conn_socket,addr =s.accept() thread_pool.add_job(handle_request,*(conn_socket,)) s.close()
二、向DB插入数据1w条
不考虑插入数据时的一些技巧(比如拼接sql批量插入;或者先写文件,再把调用mysql命令把文件导入db),单纯的基于多线程和线程池的差异对比,结果是同时开启10个线程插入1w笔数据耗时为32s,而使用线程池(size=10)耗时为9s,两者DB的连接
都是每个线程有自己的句柄,内部实现是一致的,这个结果充分的说明了线程池的优势。
#!/usr/bin/env python #coding=GBK from mytool.mysql import MySql import threading import time class MyThread(threading.Thread): def __init__(self,func,args,name=''): threading.Thread.__init__(self) self.name = name self.func = func self.args = args def run(self): self.func(*self.args) def make_t_tcpay_list(Flistid,Ftde_id,n): Fnum =0.5 Fabankid = 6222620710005743769 Fuid = 10000256025 wbdb_mysql = MySql("10.125.56.154", "root", "1234", "wd_db") for i in range(n): sql ="**" //自定义完成 wbdb_mysql.connect() wbdb_mysql.execute_insert_command(sql) Flistid = Flistid + 1 Ftde_id = Ftde_id + 1 if __name__ == "__main__": start = time.time() Threads=[] Flistid = 110180809100012153312110361120 Ftde_id = 1
for i in range(10): print i Flistid = Flistid+1000 Ftde_id = Ftde_id +1000 t = MyThread(make_t_tcpay_list, (Flistid,Ftde_id,1000)) Threads.append(t) for i in range(10): Threads[i].start() for i in range(10): Threads[i].join() end = time.time() print end - start
下面是线程池:
#!/usr/bin/env python #coding=GBK from mytool.mysql import MySql import threadpool import time def make_t_tcpay_list(n,Flistid,Ftde_id): Fnum =0.5 Fabankid = 6222620710005743769 Fuid = 10000256025 wbdb_mysql = MySql("10.125.56.154", "root", "root1234", "wd_db") wbdb_mysql.connect() for i in range(int(n)): sql ="" //自定义完成 wbdb_mysql.execute_insert_command(sql) Flistid =int(Flistid) + 1 Ftde_id =Ftde_id +1 if __name__ == "__main__": start = time.time() lst_vars_1 = ['1000','110180809100012153314210311120',1] lst_vars_2 = ['1000','110180809100012153314210321120',2000] lst_vars_3 = ['1000','110180809100012153314210331120', 4000] lst_vars_4 = ['1000','110180809100012153314210341120', 6000] lst_vars_5 = ['1000','110180809100012153314210351120', 8000] lst_vars_6 = ['1000','110180809100012153314210361120', 10000] lst_vars_7 = ['1000', '110180809100012153314210721120', 12000] lst_vars_8 = ['1000', '110180809100012153314210821120', 14000] lst_vars_9 = ['1000', '110180809100012153314210921120', 16000] lst_vars_10 = ['1000', '110180809100012123314210321120', 18000] func_var = [(lst_vars_1, None), (lst_vars_2, None), (lst_vars_3, None), (lst_vars_4, None), (lst_vars_5, None), (lst_vars_6, None), (lst_vars_7, None), (lst_vars_8, None), (lst_vars_9, None), (lst_vars_10, None)] pool = threadpool.ThreadPool(10) requests = threadpool.makeRequests(make_t_tcpay_list, func_var) for req in requests: pool.putRequest(req) pool.wait() end = time.time() print end - start
三、线程池使用说明
线程池基本原理: 我们把任务放进队列中去,然后开N个线程,每个线程都去队列中取一个任务,执行完了之后告诉系统说我执行完了,然后接着去队列中取下一个任务,直至队列中所有任务取空,退出线程。
通过上面2个demo,对单线程,多线程,线程池实际处理的差异性有了一定的了解。但是实际因为Cpython的GIL全局排他锁的存在,导致任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁。多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
对于IO密集型的任务,多线程还是起到很大效率提升(之前的两个demo都属于IO密集型),因为进行耗时的IO操作的时候,会能释放GIL,从而其他线程就可以获取GIL,提供了任务的并发处理能力。比如,计算时间占20%, IO等待时间80%,假设任务完成需要5s,可以想象成完成任务过程:CPU占用1秒,等待时间4秒,CPU在线程等待时,可以切换另外一个线程进程,这个线程的CPU运行完了,还能允许再激活3个线程,这个是第一个线程等待时间结束了,CPU切换回去,第一个线程任务就处理完成了,完成5个任务,只需要10s。这里还有一个公式: 线程数= N*(x+y)/x;N核服务器,通过执行业务的单线程分析出本地计算时间为x,等待时间为y,这样能让CPU的利用率最大化。 由于有GIL的影响,python只能使用到1个核,所以这里设置N=1
而对于计算密集型的任务,先看一个简单的demo,计算100次(1+2+...+10000),单进程耗时0.44s,而多进程和线程池耗时呢?比单进程还差,耗时1.2s。
单进程:
import time, threading def change_it(n): for j in range(n): sum =0 for i in range(100000): sum = sum + i if __name__ == "__main__": start = time.time() change_it(100) end = time.time() print end - start
耗时: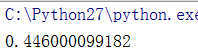
线程池(多进程):
#coding=GBK from mytool.mysql import MySql import threadpool import time def change_it(n): for j in range(n): sum =0 for i in range(100000): sum = sum + i if __name__ == "__main__": start = time.time() func_var = [10,10,10,10,10,10,10,10,10,10] pool = threadpool.ThreadPool(10) requests = threadpool.makeRequests(change_it, func_var) for req in requests: pool.putRequest(req) pool.wait() end = time.time() print end - start
耗时:
看到python在多线程的情况下居然比单线程整整慢了61%。对于由于一个CPU密集型的任务,使用多线程编程,会因为CPU一直处于运行状态,而线程又要等待获取GIL锁,从而进行线程处于循环等待状态,导致性能反而下降。
四、线程池源码解析
1、核心类:ThreadPool
类成员变量:
class ThreadPool: def __init__(self, num_workers, q_size=0): self.requestsQueue = Queue.Queue(q_size) self.resultsQueue = Queue.Queue() self.workers = [] self.workRequests = {} self.createWorkers(num_workers)
用户自定义的类似,不同的地方多了一个结果队列,把创建的运行线程全都放入了workers 内,且把所有的任务对象化workRequests
关键函数:
def createWorkers(self, num_workers): """Add num_workers worker threads to the pool.""" for i in range(num_workers): self.workers.append(WorkerThread(self.requestsQueue, self.resultsQueue))
def putRequest(self, request, block=True, timeout=0): """Put work request into work queue and save its id for later.""" assert isinstance(request, WorkRequest) self.requestsQueue.put(request, block, timeout) self.workRequests[request.requestID] = request
2、工作线程类 :WorkerThread
成员变量:
class WorkerThread(threading.Thread): def __init__(self, requestsQueue, resultsQueue, **kwds): threading.Thread.__init__(self, **kwds) self.setDaemon(1) self.workRequestQueue = requestsQueue self.resultQueue = resultsQueue self._dismissed = threading.Event() self.start()
关键函数:
def run(self): while not self._dismissed.isSet(): # thread blocks here, if queue empty request = self.workRequestQueue.get() if self._dismissed.isSet(): # if told to exit, return the work request we just picked up self.workRequestQueue.put(request) break # and exit try: self.resultQueue.put( (request, request.callable(*request.args, **request.kwds)) ) except: request.exception = True self.resultQueue.put((request, sys.exc_info()))
3、生成任务对象
def makeRequests(callable, args_list, callback=None, exc_callback=None): requests = [] for item in args_list: if isinstance(item, tuple): requests.append( WorkRequest(callable, item[0], item[1], callback=callback, exc_callback=exc_callback) ) else: requests.append( WorkRequest(callable, [item], None, callback=callback, exc_callback=exc_callback) ) return requests
其中任务对象类定义为:
class WorkRequest: if requestID is None: self.requestID = id(self) else: try: hash(requestID) except TypeError: raise TypeError("requestID must be hashable.") self.requestID = requestID self.exception = False self.callback = callback self.exc_callback = exc_callback self.callable = callable self.args = args or [] self.kwds = kwds or {}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号