
python学习笔记系列----(八)python常用的标准库
终于学到了python手册的最后一部分:常用标准库。这部分内容主要就是介绍了一些基础的常用的基础库,可以大概了解下,在以后真正使用的时候也能想起来再拿出来用。
8.1 操作系统接口模块:OS
OS模块提供了很多与操作系统进行交互的函数,比如常见的使用函数有获取当前工作目录:os.getcwd();修改当前工作目录:os.chdir(),在系统执行command命令:os.system()。既然是对操作系统的交互,操作系统常见的就有多种,比如unix和windows的。OS模块里有些函数就是只有unix能使用,比如返回父进程的进程id:getppid();有些是unix和windows的都能使用,比如:获取当前进程id:getpid()。这些在官方文档都有说明,如下:
os.getpid()
Return the current process id.
Availability: Unix, Windows.
os.getppid()
Return the parent’s process id.
Availability: Unix.
OS模块确实实用性比较强,在编写自动化测试脚本的时候,有时候也能使用到。就简答说下我使用过的应用场景吧。有时候跑自动化的时候,一些配置文件可能需要重新修改,这时工具远程连接到服务器后,需要让服务器自动替换文件,再重启服务,so~~ os模块应用上场了。OS模块主要实现了以下三大功能:进程的管理,操作系统的管理,文件和目录的管理。基于文件的操作,实际python的bulit-in模块也有个open函数,os也有open函数,但是两者之间是有区别的,os的open打开文档后,没有拿到当前文件的对象,返回的是一个整型数值,不便于后面对文档的各种操作。而内置库提供的open函数,返回的是文件的对象。
如果每天要对文件和目录进行管理,推荐使用shutil模块,这个模块提供了更多方便的接口对文件,目录进行管理(复制文件或者目录,删除文件或者目录)。比如如果要删除文件,如果继续使用os,则os.system('rf -rm /build/executables/installdir'),使用shutil模块,就简单了:shutil.move('/build/executables', 'installdir')。
8.2 文件通配符:glob模块
glob 模块提供了一个函数用于从目录通配符搜索中生成文件列表。如果,从当前目录中,搜素所有的.PY文件。之前在我不知道glob模块时,我用的是os.path模块实现的。
os.path.splitext(file)[1] == '.py'
现在使用glob模块,可以更灵活的进行处理:
>>> import glob >>> glob.glob('*.py') ['primes.py', 'random.py', 'quote.py']
8.3 字符串的正则匹配:re模块
正则表达式在匹配负责字符串的时候,确实很有用:
>>> import re >>> re.findall(r'\bf[a-z]*', 'which foot or hand fell fastest') ['foot', 'fell', 'fastest'] >>> re.sub(r'(\b[a-z]+) \1', r'\1', 'cat in the the hat') 'cat in the hat'
但是,如果是简单的对字符串进行操作,官网推荐的还是使用string模块的函数,因为这些函数看起来更易读更简洁,更容易调试:
>>> 'tea for too'.replace('too', 'two') 'tea for two'
8.4 互联网访问:urllib2模块
用于访问互联网以及处理网络通信协议中,最简单的两个是用于处理从 urls 接收的数据的 urllib2 以及用于发送电子邮件的 smtplib。
最简单的例子:
import urllib2 response = rllib2.urlopen('http://python.org/') html = response.read()
8.5 日期和时间:datetime 模块
datetime 模块为日期和时间处理同时提供了简单和复杂的方法。支持日期和时间算法的同时,实现的重点放在更有效的处理和格式化输出。该模块还支持时区处理,函数方法比较简单,就直接从官网截取例子:
>>> # dates are easily constructed and formatted >>> from datetime import date >>> now = date.today() >>> now datetime.date(2003, 12, 2) >>> now.strftime("%m-%d-%y. %d %b %Y is a %A on the %d day of %B.") '12-02-03. 02 Dec 2003 is a Tuesday on the 02 day of December.' >>> # dates support calendar arithmetic >>> birthday = date(1964, 7, 31) >>> age = now - birthday >>> age.days 14368
8.6 数据压缩:zlib
以下模块直接支持通用的数据打包和压缩格式: zlib, gzip, bz2, zipfile 以及 tarfile(实际测试过程中也暂时未用到该类函数):
>>> import zlib >>> s = b'witch which has which witches wrist watch' >>> len(s) 41 >>> t = zlib.compress(s) >>> len(t) 37 >>> zlib.decompress(t) b'witch which has which witches wrist watch' >>> zlib.crc32(s) 226805979
8.7 性能度量:timeit 模块
解决同一问题有时候可能有不同方法之间,不然的方法之间是存在的性能差异的。Python 提供了一个度量工具,例如,使用元组封装和拆封来交换元素看起来要比使用传统的方法要诱人的多。 timeit 证明了后者更快一些:
>>> from timeit import Timer >>> Timer('t=a; a=b; b=t', 'a=1; b=2').timeit() 0.57535828626024577 >>> Timer('a,b = b,a', 'a=1; b=2').timeit() 0.54962537085770791
相对于 timeit 的细粒度,profile 和 pstats 模块提供了针对更大代码块的时间度量工具。
8.8 质量控制:doctest 模块,unittest模块
在开发过程中经常进行测试,一般可以使用到2个模块:doctest 模块,unittest模块。doctest 模块,扫描模块并根据程序中内嵌的文档字符串执行测试。测试构造如同简单的将它的输出结果剪切并粘贴到文档字符串中。unittest 模块不像 doctest 模块那么容易使用,不过它可以在一个独立的文件里提供一个更全面的测试集。个人觉得unittest模块更像开发使用的单元测试模块。
import doctest def average(values): """Computes the arithmetic mean of a list of numbers. >>> print average([10, 30, 70]) 40.0 """ return sum(values, 0.0) / len(values) if __name__=="__main__": print doctest.testmod()
上面的测试,是对一个求平均值函数的测试,程序运行后就会执行average([10, 30, 70])求这三个数的平均值,并设置预期值为40,实际上实际值和这个值不相等。测试结果如下:

而使用unittest模块如下:
import unittest
def average(values):
"""Computes the arithmetic mean of a list of numbers.
>>> print average([10, 30, 70])
40.0
"""
return sum(values, 0.0) / len(values)
class TestStatisticalFunctions(unittest.TestCase):
def test_average(self):
self.assertEqual(average([20, 30, 70]), 40.0)
self.assertEqual(round(average([1, 5, 7]), 1), 4.3)
with self.assertRaises(ZeroDivisionError):
average([])
with self.assertRaises(TypeError):
average(20, 30, 70)
if __name__=="__main__":
print unittest.main()
运行后结果如下:
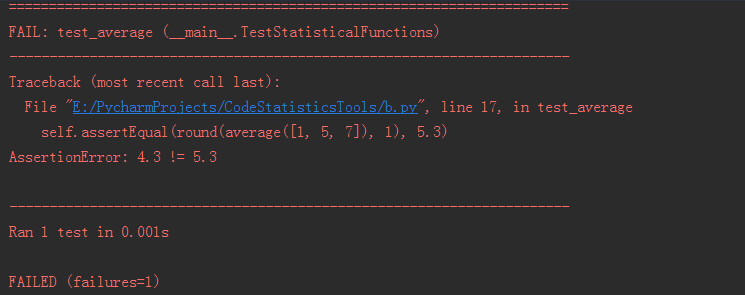
一运行,一比较,确实觉得unittest模块更符合常规的单元测试框架~~~
8.9 模板:Template 模块
string 提供了一个灵活多变的模版类 Template ,使用它最终用户可以简单地进行编辑。这使用户可以在不进行改变的情况下定制他们的应用程序。格式使用 $ 为开头的 Python 合法标识(数字、字母和下划线)作为占位符。占位符外面的大括号使它可以和其它的字符不加空格混在一起。
>>> from string import Template >>> t = Template('${village}folk send $$10 to $cause.') >>> t.substitute(village='Nottingham', cause='the ditch fund') 'Nottinghamfolk send $10 to the ditch fund.'
当一个占位符在字典或关键字参数中没有被提供时, substitute() 方法就会抛出一个 KeyError 异常。 对于邮件合并风格的应用程序,用户提供的数据可能并不完整,这时使用 safe_substitute() 方法可能更适合 — 如果数据不完整,它就不会改变占位符:
>>> t = Template('Return the $item to $owner.') >>> d = dict(item='unladen swallow') >>> t.substitute(d) Traceback (most recent call last): ... KeyError: 'owner' >>> t.safe_substitute(d) 'Return the unladen swallow to $owner.'
可以用这个类来做一个简单的应用,比如需要批量修改一批照片的后缀名,原来照片文件的后缀名都是img_1074.jpg,现在希望修改成人名+时间这种格式的,可以用以下方法实现:
# -*- coding: utf-8 -*-
from string import Template
import time,os.path
class BatchReName(Template):
delimiter = '%'
photofiles = ['img_1074.jpg','img_1075.jpg','img_1076.jpg'] fmt = raw_input('Enter rename style ') t = BatchReName(fmt) date = time.strftime('%d%b%y') for i,filename in enumerate(photofiles): base,ext = os.path.splitext(filename) newname = t.substitute(d=date,n=i,f=ext) print '{0} --> {1}'.format(filename,newname)
运行结果如下:

8.10 列表工具:array 模块
很多数据结构可能会用到内置列表类型。然而,有时可能需要不同性能代价的实现。array 模块提供了一个类似列表的 array() 对象,它仅仅是存储数据,更为紧凑。以下的示例演示了一个存储双字节无符号整数的数组(类型编码 "H" )而非存储 16 字节 Python 整数对象的普通正规列表;collections 模块提供了类似列表的 deque() 对象,它从左边添加(append)和弹出(pop)更快,但是在内部查询更慢。这些对象更适用于队列实现和广度优先的树搜索;heapq 提供了基于正规链表的堆实现。最小的值总是保持在 0 点。这在希望循环访问最小元素但是不想执行完整堆排序的时候非常有用。
这些模块好像我并没有使用过~~~(平常注重更多的在自动化功能的实现上了)。以上就是常见模块的介绍,官网还介绍了其他常用的模块,比如输出格式模块,多线程模版,日志系统的模版等。花了近一个月的时间才把python2.7.11的英文手册看完,收获最大并不是语言基础或者语言语法,感觉更多的是让自己面对一大堆英文文档,不再是排斥状态,敢看下去,能看下去。当然同时还对python语言的整体有了更深刻的印象。嘿嘿,接下来python学习之路又何处何从呢,我想应该是先写些测试小工具吧~~

