
缺陷的背后(四)---多进程之for循环下fork子进程引发bug
导语
业务模块为实现高并发时的更快的处理速度,经常会采用多进程的方式去处理业务。多进程模式下常见的三种bug:for循环下fork子进程导致产生无数孙子进程,僵尸进程,接口窜包。本章主要介绍第一种常见的bug:for循环下fork子进程导致产生无数孙子进程。通过分析开发线上出现的问题,理解问题出现的原因以及如何避免,如何有效的测试出这类缺陷。
目录
一:缺陷引入
二:多进程概念理解
2.0 fork基本概念理解
2.1 “写时复制”的fork
2.2 for循环下fork子进程问题分析
2.3 缺陷分析
三:测试方法
一: 缺陷引入
某日下午,测试组突然炸锅了,“为什么这台机器一下这么卡?”“为什么机器的cpu占用这么高?”“为啥这台机器的这个进程ps这么多?”“这么多进程未被主进程回收,这是僵尸进程啊”,后面该进程的相关测试人员一看,赶紧停了被测程序,机器恢复。
测试同学:主进程在wait释放子进程的“空壳”时,出现了大量的失败返回值为-1(日志有打印主进程调用wait的返回值),这就导致子进程的“空壳”未被释放,出现大量僵尸进程,直接占用耗尽用户资源,导致整个系统被拖垮。
开发同学:直接上多进程3件套看看能不能修复bug:
1: 创建进程前,查看子进程个数,超过最大进程数,不再fork
2: 子进程运行前,先sleep 1s
3: 子进程运行完或者发生异常时,不抛异常,直接exit退出
测试同学:修复了,现在正常运行子进程和子进程异常退出都不会产生僵尸进程了,问题解决。
------------------------------------------------------------------------------------------------------------------------------------------
那问题出现了:ps查看进程的时候,有看进程的状态吗?为什么确定就是僵尸进程? 也有可能是创建了大量的子进程且子进程一直未退出。用python还原下当时的代码,如下所示:
#!/usr/bin/python
# 模拟缺陷问题产生
import os,time,sys
def test(is_ok):
if is_ok == 0:
return 0
else:
return -1
def CreateVerifyTask():
try:
pid = os.fork()
if pid == 0:
print("子进程执行的代码,子进程的pid为{0},主进程pid为{1}".format(os.getpid(),os.getppid()))
ret = test(-1)
if ret<0:
print("创建任务失败")
# 改进方法1:子进程运行异常直接退出(推荐)
# os._exit(0)
raise RuntimeError('error1')
else:
pid= os.wait()
print(pid)
print("主进程执行的代码,当前pid为{0},我真实的pid为{1}".format(pid,os.getpid()))
except:
print('throw 1 CreateVerifyTask')
raise RuntimeError('error1')
def hand_test():
try:
CreateVerifyTask()
except:
print('throw 2 get_test')
# 改进方法2:将异常直接抛到for循环或者while循环
# raise RuntimeError('error1 hand_test')
# 不往外继续抛异常,子进程执行CreateVerifyTask产生异常在hand_test内被"消化",导致子进程在excute继续执行for循环,产生更多的孙子进程。
def excute():
try:
for i in range(10):
print(i)
hand_test()
except:
print('throw 2 get_test')
if __name__=='__main__':
excute()
为什么会产生大量的进程呢?如果认真看了这段代码仍然不明白为何产生问题,强烈建议从第二章节开始看,else谜底在2.3 缺陷分析揭晓。
二:多进程概念理解
2.0 fork基本概念
计算机程序设计中的分叉函数。返回值: 若成功调用一次则返回两个值,子进程返回0,父进程返回子进程标记;否则,出错返回-1。
一个现有进程可以调用fork函数创建一个新进程。由fork创建的新进程被称为子进程(child process)。子进程是父进程的副本,它将获得父进程数据空间、堆、栈等资源的副本,这意味着父子进程间不共享这些地址空间。UNIX将复制父进程的地址空间内容给子进程,因此,子进程有了独立的地址空间。在不同的UNIX (Like)系统下,我们无法确定fork之后是子进程先运行还是父进程先运行,这依赖于系统的实现。
如下所示的代码段:
Fork语句执行后:(第二步,第三步顺序不确定)
第一步: 父进程fork子进程成功,子进程获得父进程数据空间、堆、栈等资源的副本,拥有跟父进程一样的代码段,此时父子进程都从fork的下一句开始并发执行。
第二步: 父进程执行:内核向父进程1869返回子进程的进程号pid=1870,父进程执行else内代码段。
第三步: 子进程执行:内核向子进程返回0.子进程执行elif pid ==0 内代码段。

2.1 “写时复制”的fork
进程(Process)是计算机中已运行程序的实体,是系统的基本运作单位,是资源分配的最小单位,fork子进程后,子进程会复制父进程的状态(内存空间数据等)。fork 出来的进程和父进程拥有同样的上下文信息、内存数据、与进程关联的文件描述符。这句话是否理解,可以通过下面2个demo验证下:
问题1 :全局变量list1,fork子进程后,在子进程内:打印list1的虚拟地址,修改list1[0]的值,打印list1值,打印list1虚拟地址。 主进程内:打印list1的虚拟地址,待子进程修改后,打印list1值。
子进程和主进程打印的虚拟地址值是一样的吗?打印的list1的值是一样的吗?
import os
import time
list1 =[1,2,3,4]
print("list1的地址为{0}".format(id(list1)))
mainpid = os.getpid()
print(os.getpid())
pid = os.fork()
if pid<0:
print('创建进程失败')
elif pid == 0:
print("子进程执行的代码,子进程的pid为{0},主进程pid为{1}".format(os.getpid(),os.getppid()))
print("子进程修改前list1的地址为{0}".format(id(list1)))
list1[0]=10
print("子进程修改后list1的地址为{0}".format(id(list1)))
print("子进程list1为{0}".format(list1))
else:
print("主进程执行的代码,当前pid为{0},我真实的pid为{1}".format(pid,os.getpid()))
print("主进程list1的地址为{0}".format(id(list1)))
time.sleep(1)
print("主进程list1为{0}".format(list1))
print("主进程最后打印list1的地址为{0}".format(id(list1)))
print(list1)
print('end')
运行结果:
list1的地址为4349698528 10157 主进程执行的代码,当前pid为10158,我真实的pid为10157 主进程list1的地址为4349698528 子进程执行的代码,子进程的pid为10158,主进程pid为10157 子进程修改前list1的地址为4349698528 子进程修改后list1的地址为4349698528 子进程list1为[10, 2, 3, 4] [10, 2, 3, 4] end 主进程list1为[1, 2, 3, 4] 主进程最后打印list1的地址为4349698528 [1, 2, 3, 4] end Process finished with exit code 0
结果:
全局变量在子进程的虚拟地址值 = 主进程的虚拟地址值;子进程内的list1的值 不等于主进程list1的值。
分析:
fork创建一个新进程。系统调用复制当前进程,在进程表中新建一个新的表项,新表项中的许多属性与当前进程是相同的。新进程几乎与主进程一模一样,执行的代码也完全相同,但是新进程有自己的数据空间、环境和文件描述符。但是新的进程只是拥有自己的虚拟内存空间,而没有自己的物理内存空间。新进程共享源进程的物理内存空间。而且新内存的虚拟内存空间几乎就是源进程虚拟内存空间的一个复制。所以父子进程都打印list1的虚拟地址时,都是同一个地址值。
进程空间可以简单地分为程序段(正文段)、数据段、堆和栈四部分(简单这样理解)。fork函数,当执行完fork后的一定时间内,新的进程(p2)和主进程(p1)的进程空间关系如下图:

fork执行时,Linux内核会为新的进程P2创建一个虚拟内存空间,而新的虚拟空间中的内容是对P1虚拟内存空间中的内容的一个拷贝。而P2和P1共享原来P1的物理内存空间。但是当父子两个进程中任意一个进程对数据段、栈区、堆区进行写操作时,上图中的状态就会被打破,这个时候就会发生物理内存的复制,这也就是叫“写时复制”的原因。发生的状态转变如下:
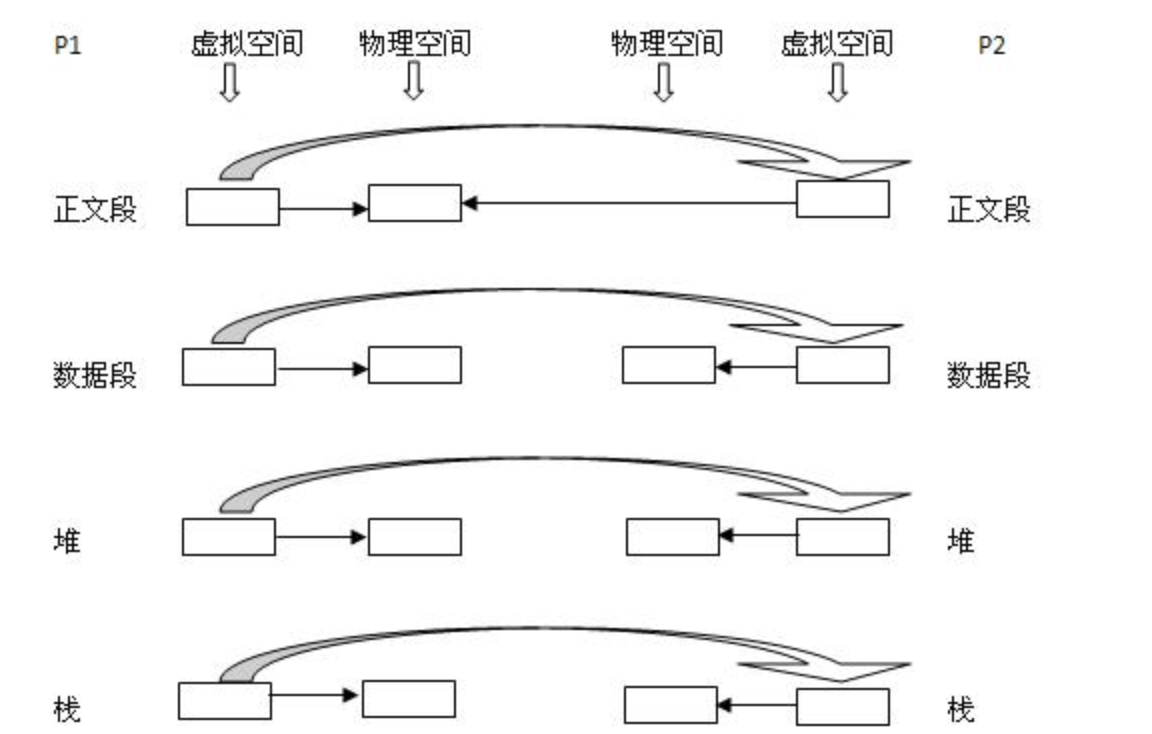
P2有了属于自己的物理内存空间。如果只有数据段发生了写操作那么就只有数据段进行写时复制,而堆、栈区域依然是父子进程共享。这就解释了为啥修改子进程的全局变量,不影响父进程list1值的情况。还有一个需要注意的是,正文段(程序段)不会发生写时复制,这是因为通常情况下程序段是只读的。子进程和父进程从fork之后,基本上就是独立运行,互不影响了。
此外需要特别注意的是,父子进程的文件描述符表也会发生写时复制。
#!/usr/bin/python # -*- coding: UTF-8 -*- import pymysql import os import time def init_db(): # 打开数据库连接 db_conn = pymysql.connect("localhost","root","root1234","mysql" ) # 使用 cursor() 方法创建一个游标对象 cursor cursor = db_conn.cursor() return db_conn,cursor db_conn,db_curdsor = init_db() pid = os.fork() if pid<0: print('创建进程失败') elif pid == 0: print('子进程db_curdsor的地址是:{0}'.format(id(db_curdsor))) for i in range(1000): time.sleep(1) db_curdsor.execute("SELECT VERSION()") version_data = db_curdsor.fetchone() print(version_data) else: print("主进程执行的代码,当前pid为{0},我真实的pid为{1}".format(pid,os.getpid())) print('主进程db_curdsor的地址是:{0}'.format(id(db_curdsor))) time.sleep(2) db_conn.close()
运行结果:
主进程执行的代码,当前pid为13237,我真实的pid为13224 主进程db_curdsor的地址是:4672554320 子进程db_curdsor的地址是:4672554320 ('8.0.18',) Traceback (most recent call last): File "/Users/leiliao/Downloads/loleina_excise/process/test2.py", line 30, in <module> db_curdsor.execute("SELECT VERSION()") File "/opt/anaconda3/lib/python3.7/site-packages/pymysql/cursors.py", line 170, in execute result = self._query(query) File "/opt/anaconda3/lib/python3.7/site-packages/pymysql/cursors.py", line 328, in _query conn.query(q) File "/opt/anaconda3/lib/python3.7/site-packages/pymysql/connections.py", line 517, in query self._affected_rows = self._read_query_result(unbuffered=unbuffered) File "/opt/anaconda3/lib/python3.7/site-packages/pymysql/connections.py", line 732, in _read_query_result result.read() File "/opt/anaconda3/lib/python3.7/site-packages/pymysql/connections.py", line 1075, in read first_packet = self.connection._read_packet() File "/opt/anaconda3/lib/python3.7/site-packages/pymysql/connections.py", line 657, in _read_packet packet_header = self._read_bytes(4) File "/opt/anaconda3/lib/python3.7/site-packages/pymysql/connections.py", line 707, in _read_bytes CR.CR_SERVER_LOST, "Lost connection to MySQL server during query") pymysql.err.OperationalError: (2013, 'Lost connection to MySQL server during query') Process finished with exit code 0
此时如果子进程运行中,发现断连执行重连操作,则重连后的句柄属于子进程独有资源。
2.2 for循环下fork子进程问题分析
下面代码会创建几个子进程呢?
import os import time n = 3 # 期望设置3个进程 for i in range(n): pid = os.fork() if pid<0: print('创建进程失败') elif pid == 0: print("子进程执行的代码,子进程的pid为{0},主进程pid为{1}".format(os.getpid(),os.getppid()))
# break
# 增加break,创建的线程数就是n
else: pass #主进程什么都不做
运行结果:
子进程执行的代码,子进程的pid为14787,主进程pid为14786
子进程执行的代码,子进程的pid为14788,主进程pid为14786
子进程执行的代码,子进程的pid为14789,主进程pid为14786
子进程执行的代码,子进程的pid为14790,主进程pid为14787
子进程执行的代码,子进程的pid为14791,主进程pid为14788
子进程执行的代码,子进程的pid为14792,主进程pid为14787
子进程执行的代码,子进程的pid为14793,主进程pid为14790
结果:7个
分析:
fork是UNIX或类UNIX中的分叉函数,fork函数将运行着的程序分成2个(几乎)完全一样的进程,每个进程都启动一个从代码的同一位置开始执行的线程。这两个进程中的线程继续执行,就像是两个用户同时启动了该应用程序的两个副本。如果把n设置成3,则实际会产生7个子进程。
1.i=0时,父进程进入for循环,此时由于fork的作用,产生父子两个进程(分别记为F0/S0),分别输出father和child,然后,二者分别执行后续的代码,子进程由于for循环的存在,没有退出当前循环,因此,父子进程都将进入i=1的情况;
2.i=1时,父进程继续分成父子两个进程(分别记为F1/S1),而i=0时fork出的子进程也将分成两个进程(分别记为FS01/SS01),然后所有这些进程进入i=2;
3.....过程于上面类似,已经不用多说了,相信一切都已经明了了,依照上面的标记方法,i=2时将产生
如下图所示:
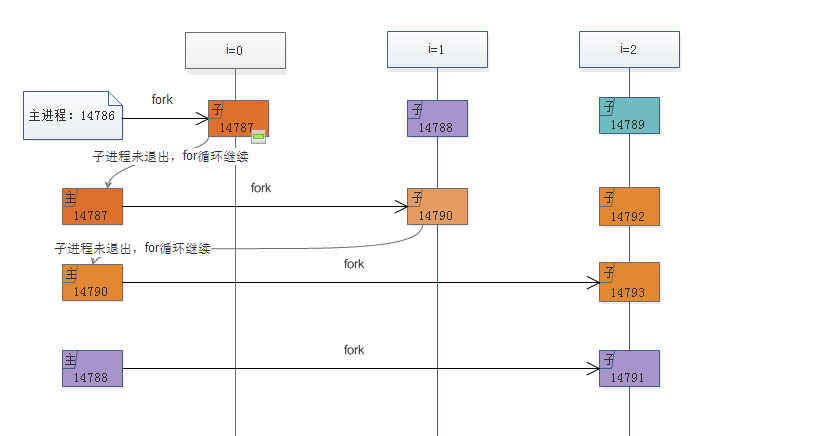
对应的数学公式如下:1 + 2 + 4 + ... + 2^(n - 1) = 2^n - 1
2.3 缺陷分析
缺陷产生的根本原因就在于:在创建子进程时异常,raise抛异常之后被外层函数hand_test捕获到之后没有继续往外抛,导致子进程在excute函数种的for循环未结束,子进程继续执行excute函数,创建孙子进程,导致创建n多进程。
三件套还是有点用,虽然那会开发不知道是啥原因。。。。。
这个问题的解决,应该有2种方法:
1. 子进程运行的代码段,子进程执行的函数正常运行完,尤其是异常的时候,使用exit退出当前子进程,从根本上解决子进程fork孙子进程的问题。(最推荐方法)
2. 子进程运行异常抛异常,异常需要一直抛直到for循环处理的函数去处理。
三:测试方法
测试点:for循环内fork子进程,是否产生孙子进程
测试方法:子进程代码执行区正常执行,子进程能正常退出。
子进程代码执行区异常执行,子进程直接exit退出。(抛异常关注处理异常函数)

