python --- 字符编码学习小结(二)
距离上一篇的python --- 字符编码学习小结(一)已经过去2年了,2年的时间里,确实也遇到了各种各样的字符编码问题,也能解决,但是每次都是把所有的方法都试一遍,然后终于正常。这种方法显然是不科学的,本质上不理解问题产生的原因,所以遇到问题,只能先用万能钥匙,不行的话再逐个换。2年的时间积累和学习目前对此的了解又深刻了一点。
一、常见的编解码问题:
先来说几个常见的问题吧。
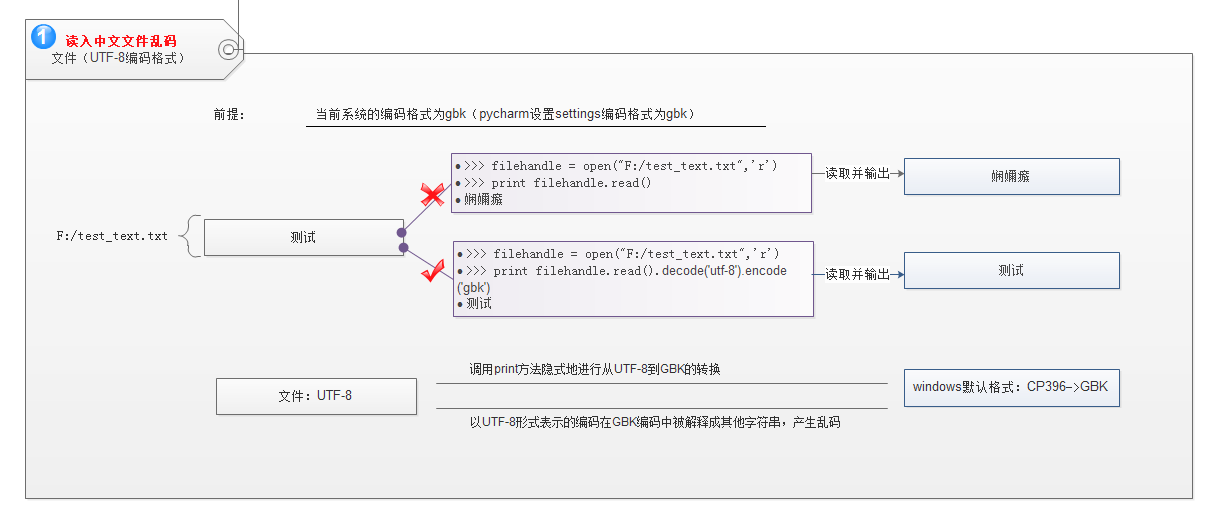
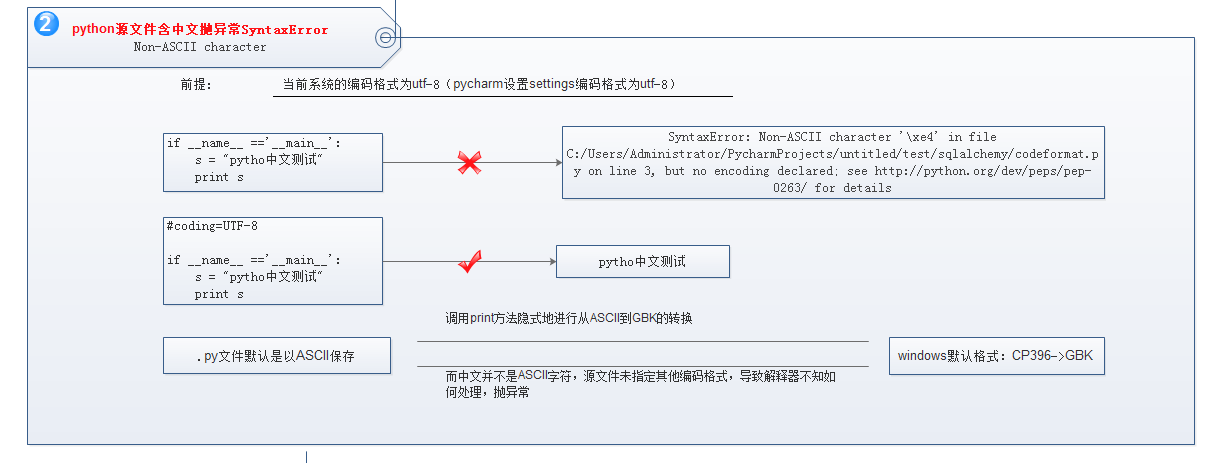
这2个问题,都是最最常见,又最基本典型的问题,又最基本的2个问题,从这2个问题出发,弄清楚问题产生的原因,后面很多问题基本都是组合场景,能比较轻松解决。
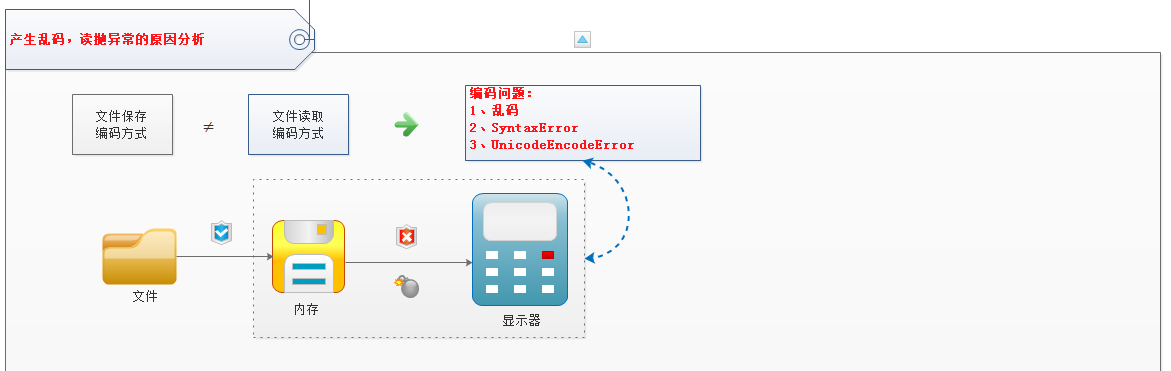
二:问题产生原因分析
1、根本原因:
2、分析问题1产生原因和解决方法:
第一步: ***格式的txt文件被读取到内存中 第二步:显示器按&&&方式来读取? 当&&& 与 ***不一致就会乱码,分析如下: A: 正常默认情况下,python解析器尝试使用 &&& = GBK格式(windows默认格式:CP396->GBK)来解析这块内存数据来显示: a : 如果读取的文件是*** = GBK格式,ok,不乱码 b : 如果读取的文件是*** = UTF-8格式就会产生乱码。因为以UTF-8形式表示的编码在GBK编码中被解释成其他字符串导致产生乱码 B: 而如果此时在在pycharm里可以通过设置settings的encoding格式=UTF-8来解析这块内存数据: a: 如果读取的文件是GBK格式会产生乱码。因为以GBK形式表示的编码在utf-8编码中被解释成其他字符串导致产生乱码 b : 如果读取的文件是UTF-8格式就不会乱码。 A.b 解决办法:.decode('utf-8').encode('gbk')或者decode('utf-8') B.a 解决办法:decode('gbk').encode('utf-8')或者decode('gbk')
其中,windows默认的解析格式是GBK,在pycharm里可以通过设置settings的encoding格式来设置;而文件保存格式,在notepad++可以选择
读取文件推荐使用方法:
推荐使用codecs模块,使用codecs/io.open()显示指定文件编码格式。python 2 open(filename,mode),不支持encoding参数,但python 3支持
3、分析问题2产生原因和解决方法:
第一步: 以***编码格式保存py文件。 第二步:显示器按&&&方式来读取? 在解析过程中,当字符在***无法找到时程序会抛异常,分析如下: A: 正常默认情况下,python的默认编码是 *** = ASCII编码: a : 默认情况下,python解析器尝试使用 &&& = GBK 来解析数据,但是中文并不是ASCII字符,导致解释器不知如何处理,抛异常. b : 设置pycharm的settings的encoding格式 = UTF-8, 来解析数据,但是中文并不是ASCII字符,导致解释器不知如何处理,抛异常. 解决方法:声明源文件的编码方式。 推荐方法:#coding=utf-8
三、其他常见不同类型问题
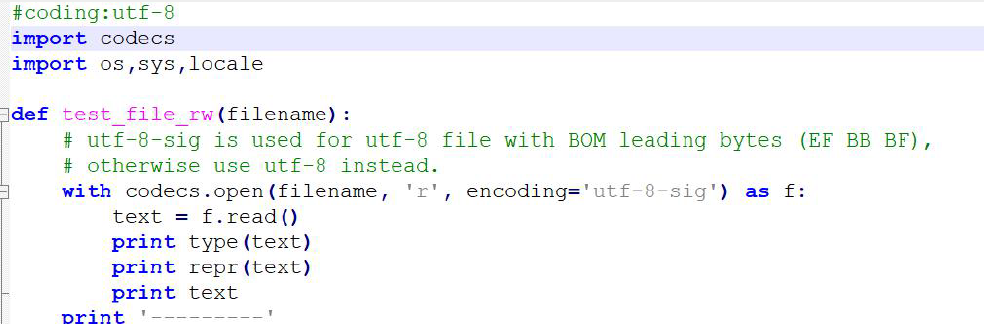
1、不可见字符BOM导致解析异常

2、chardet检测字节流编码格式,是基于概率,存在不准确的问题。字节编码无法准确猜对,必须明确告知
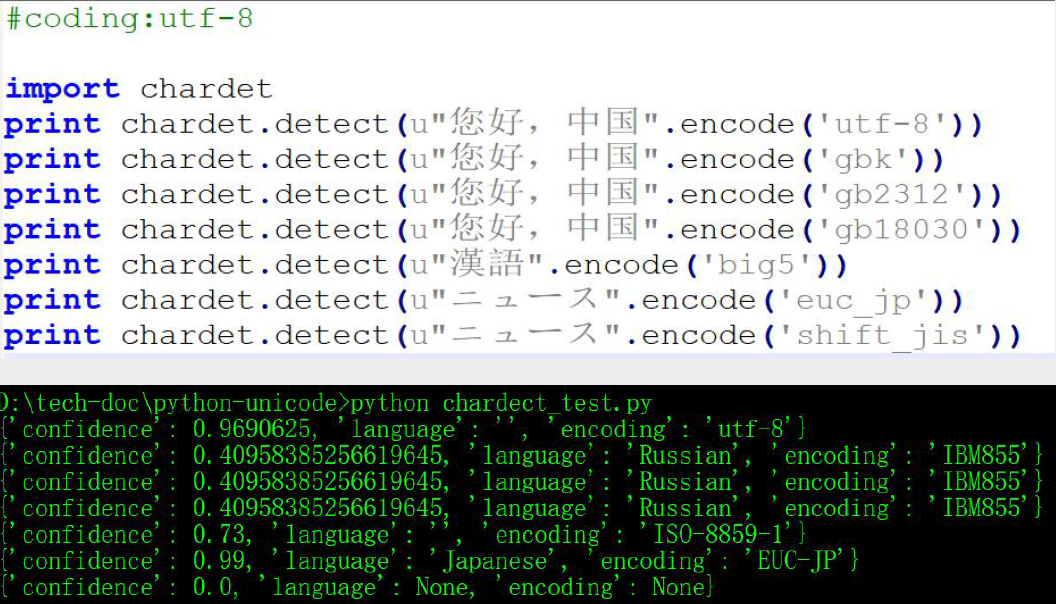
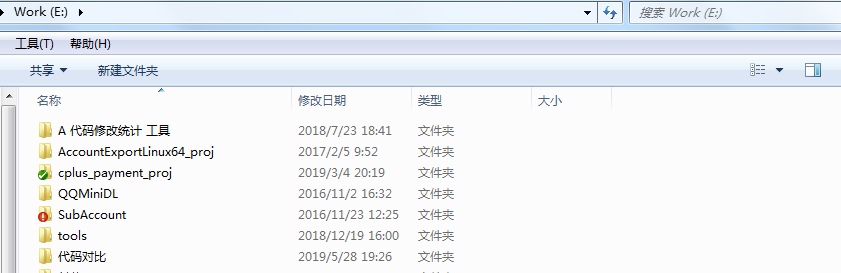
3、os.walk() 遍历含中文的路径时中文乱码报错
现在需要遍历E:/ 下的路径,部分如下所示,存在中文文件名
A: 报错代码段如下:读取的
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
for root, dirs, files in os.walk("E:/", topdown=False):
for name in files:
print(os.path.join(root, name))
读取结果如下:
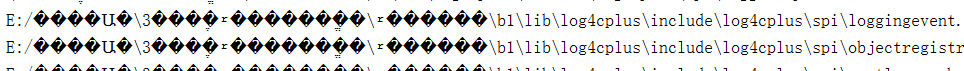
B: 导致取读错误的原因如下:
os.walk(folder_name) 返回的文件路径编码和入参folder_name编码有关:
• 当folder_name是unicode时,os.walk返回的root,directories, filenames也是unicode
• 否则按照sys.getfilesystemencoding()编码返回str.中文windows 系统sys.getfilesystemencoding()返回“mbcs”(即:“gbk”)英文ubuntu系统sys.getfilesystemencoding()返回“utf-8”
如果根路径中有中文,路径需要使用unicode编码作为os.walk的入参
C : 修改代码如下,能正常读取中文路径
for root, dirs, files in os.walk(u"E:/", topdown=False): 或者 for root, dirs, files in os.walk("E:/".decode('utf-8'), topdown=False):


 浙公网安备 33010602011771号
浙公网安备 33010602011771号