
缺陷的背后(一)---MYQL之LIMIT M,N 分页查找
一、问题发现篇
最近组内做了一次典型缺陷分享时,翻阅2018年的缺陷,找到了一个让我觉得“有料”的bug(别的同事测试发现的),先大致简单的描述下这个问题:
- 需要实现的功能:从一个DB库同步某一段时间的数据到另一个DB库(简化后的需求)。
- 问题描述:一次同步20w条符合记录的数据,程序同步完成后,丢数据5条。
- 问题定位:加载数据的sql,考虑到数据量大,使用了limit M,N的方法来分页加载数据,大致如下:
select * from test where Fmodify_time >= '2018-12-12 05:00:00'and Fmodify_time <= '2018-12-12 05:01:00' limit 0,2;
开发哥哥定位问题产生的原因是因为20w的数据里,存在大量的Fmodify_time 值相同的记录,由于未排序,导致这类数据服务器返回时会随机选择,从而导致分页取出来的数据存在重复或者丢失的问题。然后解决的办法就是,加上order by Fmodify_time 就能满足,因为Fmodify_time 是一个索引,索引排序是有序的。后面测试小哥用相同的数据验证不丢数据,事情就告一段落了。
二、问题验证和解决篇
巧着,18年下半年花了2个月时间在学习mysql,在学习limit 分页查找的官方文档里有看到这么一段话:https://dev.mysql.com/doc/refman/5.7/en/limit-optimization.html
(1)如果在使用order by列中的多个行具有相同的值,则服务器可以按任何顺序自由返回这些行,并且可能根据整体执行计划的不同而不同。换句话说,这些行的排序顺序相对于无序列是不确定的。
(2)影响执行计划的一个因素是 LIMIT,因此ORDER BY 使用和不使用查询LIMIT可能会返回不同顺序的行。如果确保使用和不使用相同的行顺序很重要,请LIMIT在ORDER BY子句中包含其他列以使记录具有确定性,
比如使用主键。
那这么说,之前开发说通过order by 索引能使得结果返回有序就是有问题的了,带着这个疑问和官方文档的demo,结合实际的这个缺陷,做了个小验证。
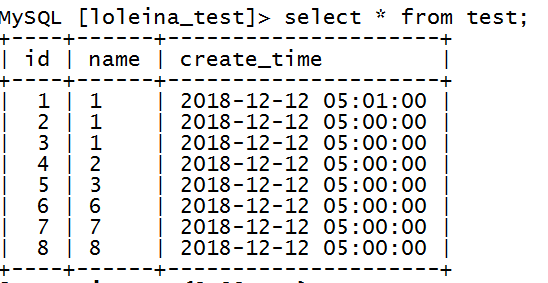
(1)建表如下: 主键:id,索引:create_time
CREATE TABLE `test` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `create_time` timestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`), KEY `index_time` (`create_time`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=latin1
(2)插入数据如下:
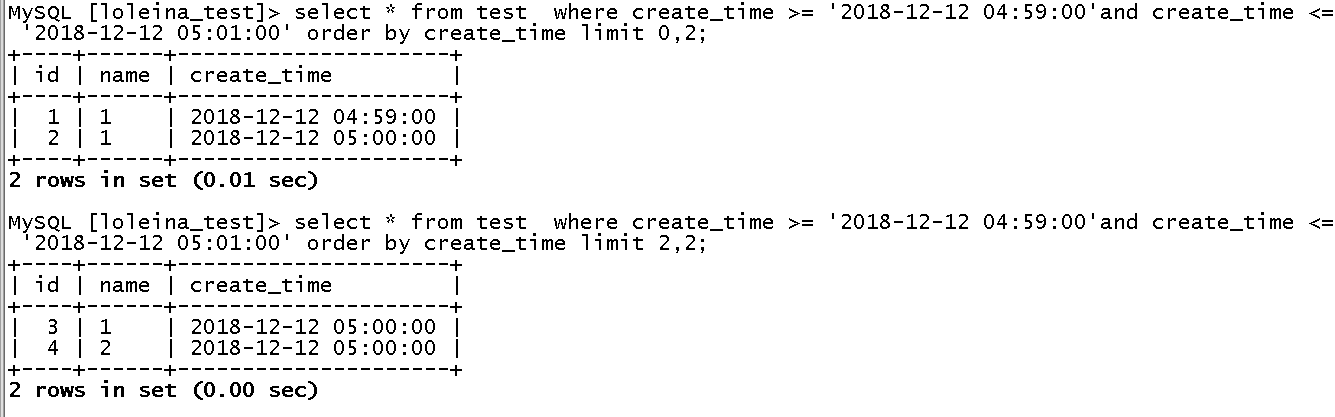
(3)模拟分页查找,不使用order by。结果如下:

测试结果:丢数据id=1的记录,id=7的数据重复导致。看来这个问题是真的存在的。那按照开发哥哥的解决方法加上order by create_time就没问题了?
(4)模拟分页查找,使用order by + create_time(索引),如下:

测试结果:丢数据id=7的记录,id=3的数据重复导致。看来加了索引排序,还是有问题的,开发哥哥的“解决方法”实际是不能解决问题的。
(5)模拟分页查找,使用order by + create_time(索引)+ id(主键),如下:

测试结果:未丢数据。
分页查找limit M,N 的基本原理,就是服务器查找M+N条,然后返回从M条开始的后N条,导致上面问题出现的本质原因,还是mysql服务器查询后的数据排序不稳定导致。同小节的官方文档有说明当LIMIT row_count 和ORDER BY一起使用的时候,mysql不会对整个结果集排序,而是只对row_count 行的数据进行排序然后就返回。
If you combine LIMIT row_count with ORDER BY, MySQL stops sorting as soon as it has found the first row_count rows of the sorted result, rather than
sorting the entire result. If ordering is done by using an index, this is very fast. If a filesort must be done, all rows that match the query
without the LIMIT clause are selected, and most or all of them are sorted, before the firstrow_count are found. After the initial rows have been
found, MySQL does not sort any remainder of the result set.
三、未解之谜篇
大致的原理已经理清了,但是还有几个问题是没想明白的:
问题一: 如果构造测试数据的时,把id =1的记录,时间2018-12-12 05:01:00 修改为2018-12-12 04:59:00,不加order by 都不会出现丢数据和重复数据的问题:

这是为什么?数据的不同对结果是有影响的!!!那测试的时候数据要怎么构造呢?才能保证输入的数据都是有代表的呢?这个现象背后的原理是什么呢?
问题二:使用索引排序 order by+索引,是不稳定的?
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
2019.01.28 问题跟进
问题二:使用索引排序 order by+索引,是不稳定的?
这个问题有“问题“,虽然order by 和 where 条件语句都是使用了index,但是并不确定所有的分页查找的sql都是使用索引排序。比如:
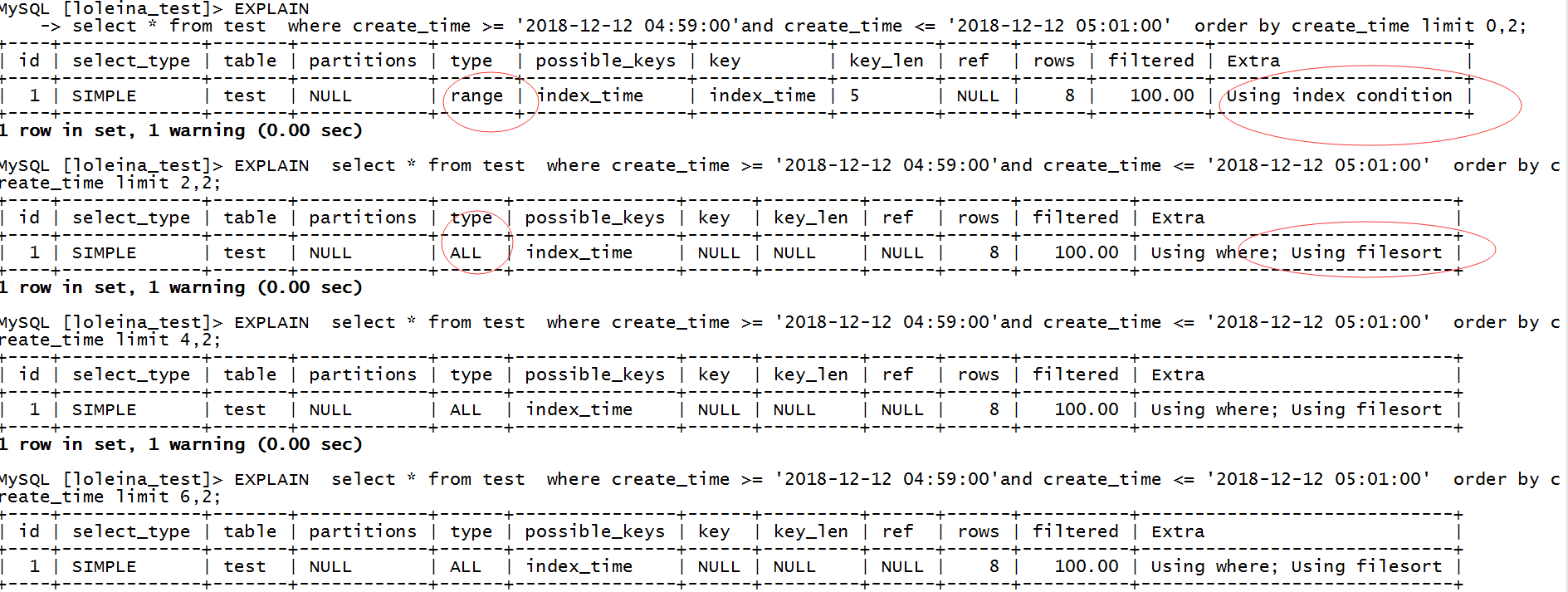
从第二个sql开始,执行计划就已经开始出现Using where; Using filesort ,跟之前第一条sql的执行计划是完全不一样的, 第二条sql之后就不能利用索引来避免排序,filesort并不意味着就是文件排序,其实也有可能是内存排序,这个主要由sort_buffer_size参数与结果集大小确定。MySQL内部实现排序主要有3种方式,常规排序,优化排序和优先队列排序,主要涉及3种排序算法:快速排序、归并排序和堆排序。
在学习其他文档了解到,在5.5版本中没有这个问题。产生这个现象的原因就是5.6针对limit M,N的语句采用了优先队列,而优先队列采用堆实现,使用的是堆排序算法,比如上述的例子order by create_time limit 4,2 limit 0,2 需要采用大小为2的大顶堆;limit 2,4需要采用大小为4的大顶堆。堆排序是非稳定的(对于相同的key值,无法保证排序后与排序前的位置一致),所以导致分页重复的现象。而解决这个问题的有效方法就是可以在排序中加上唯一值,比如主键id。
那为什么第一条执行sql的时候Extra = Using index condition,不需要访问表,直接拿数据呢? 后面sql执行全部都是Extra = Using where; Using filesort ,估计就是跟sort_buffer_size参数有关
学习参考文档:《数据库内核月报 - 2015 / 06》 链接:http://mysql.taobao.org/monthly/2015/06/04/
《MySQL排序原理》 https://blog.csdn.net/eagle89/article/details/81315981
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
优化order by 方法:
1 加大 max_length_for_sort_data 参数的设置
在 MySQL 中,决定使用老式排序算法还是改进版排序算法是通过参数 max_length_for_ sort_data 来决定的。当所有返回字段的最大长度小于这个参数值时,MySQL 就会选择改进后的排序算法,反之,则选择老式的算法。所以,如果有充足的内存让MySQL 存放须要返回的非排序字段,就可以加大这个参数的值来让 MySQL 选择使用改进版的排序算法。
2 去掉不必要的返回字段
当内存不是很充裕时,不能简单地通过强行加大上面的参数来强迫 MySQL 去使用改进版的排序算法,否则可能会造成 MySQL 不得不将数据分成很多段,然后进行排序,这样可能会得不偿失。此时就须要去掉不必要的返回字段,让返回结果长度适应 max_length_for_sort_data 参数的限制。
3 增大 sort_buffer_size 参数设置
这个值如果过小的话,再加上你一次返回的条数过多,那么很可能就会分很多次进行排序,然后最后将每次的排序结果再串联起来,这样就会更慢,增大 sort_buffer_size 并不是为了让 MySQL选择改进版的排序算法,而是为了让MySQL尽量减少在排序过程中对须要排序的数据进行分段,因为分段会造成 MySQL 不得不使用临时表来进行交换排序。
但是这个值不是越大越好:
1 Sort_Buffer_Size 是一个connection级参数,在每个connection第一次需要使用这个buffer的时候,一次性分配设置的内存。
2 Sort_Buffer_Size 并不是越大越好,由于是connection级的参数,过大的设置+高并发可能会耗尽系统内存资源。
3 据说Sort_Buffer_Size 超过2M的时候,就会使用mmap() 而不是 malloc() 来进行内存分配,导致效率降低。

