Embedding相关笔记
Word2Vec模型
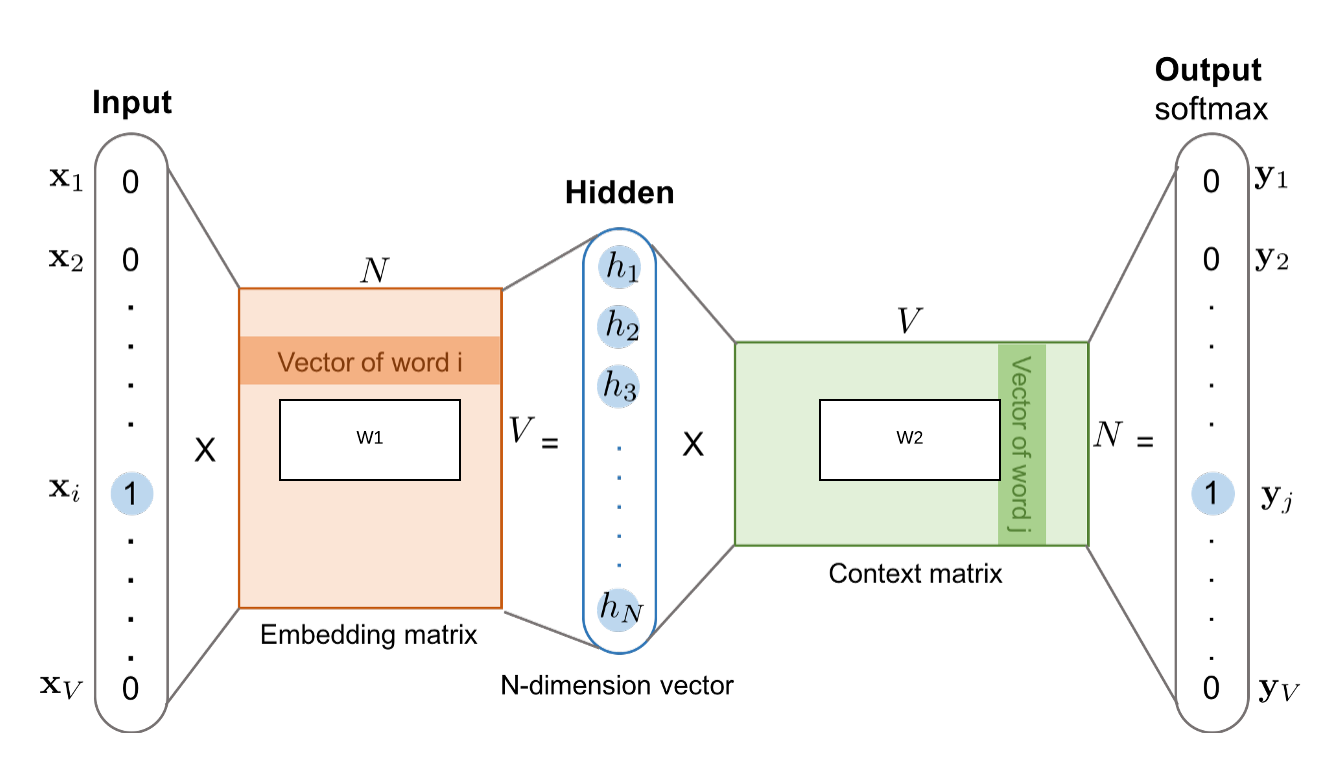
模型结构:
- 1个输入层:输入向量为词汇的one-hot编码
- 1个隐藏层:权值矩阵的形状为[vocab_size, hidden_size]
- 1个输出层:输出长度为vocab_size的向量,向量中每个元素对应词库中一个词的概率
模型训练:
- W2V有Skip-Gram和CBOW两种训练模式。从直观上理解:Skip-Gram是给定当前值来预测上下文。而CBOW是给定上下文,来预测当前值
Simple CBOW Model
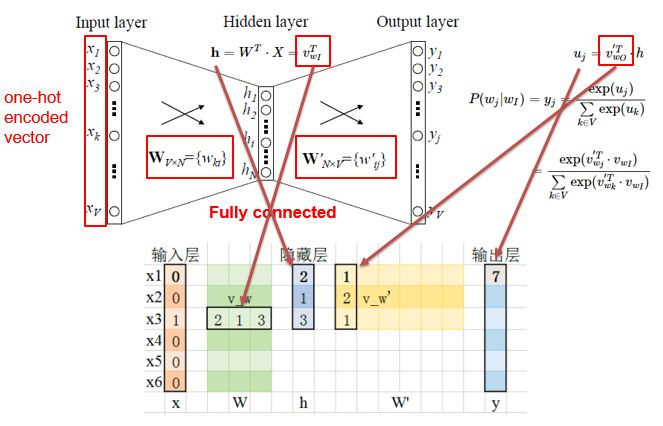
- 简单的CBOW 模型仅输入一个词,输出一个词
- 最终的输出需要经过softmax函数,将输出向量中的每一个元素归一化到0-1之间的概率,概率最大的,就是预测的词
CBOW Multi-Word Context Model
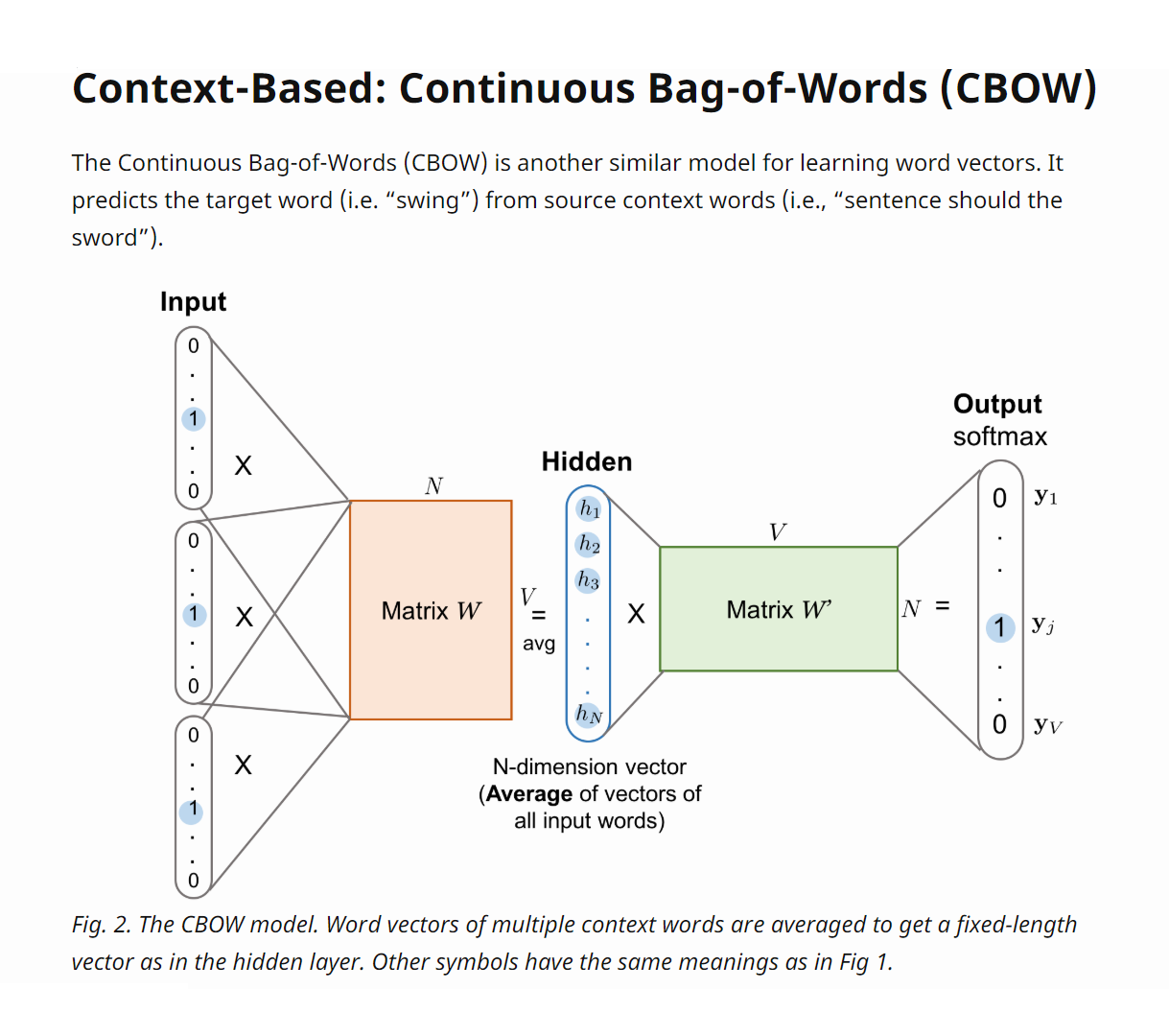
- 和simple CBOW的不同之处在于,输入由1个词变成了多个词,每个输入 Xik 到达隐藏层都会经过相同的权重矩阵W,隐藏层h的值变成了多个词乘上权重矩阵之后加和求平均值
Skip-gram
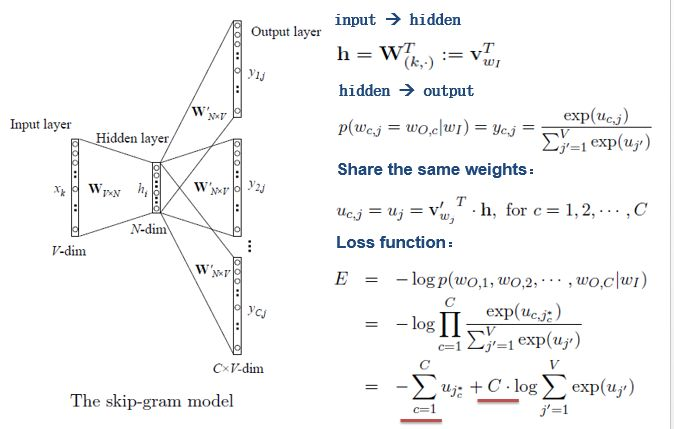
- Skip-gram输入层到隐藏层的原理和simple CBOW一样,不同的是隐藏层到输出层,损失函数变成了C个词损失函数的总和(期望输出上下文词汇),权重矩阵W’还是共享的
从效果上看,skip-gram的结果一般会比CBOW好一些,原因可能是CBOW在对多个词进行平均时带来了一些额外的信息损失
Deep Crossing
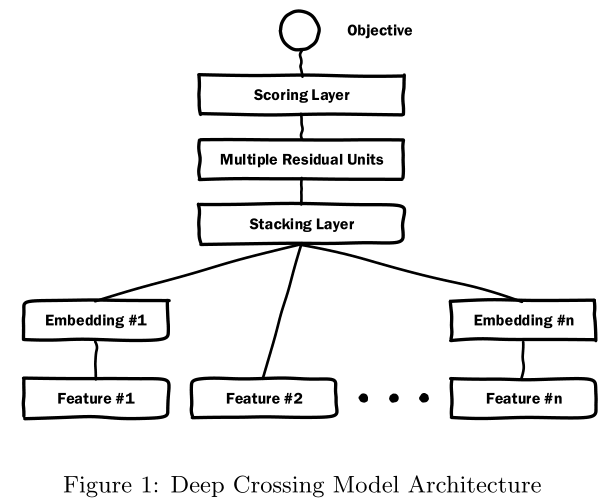
模型结构:
- 类别型特征(one-hot向量)先进入Embedding层,再拼入stacking层,数值型特征直接拼入stacking层
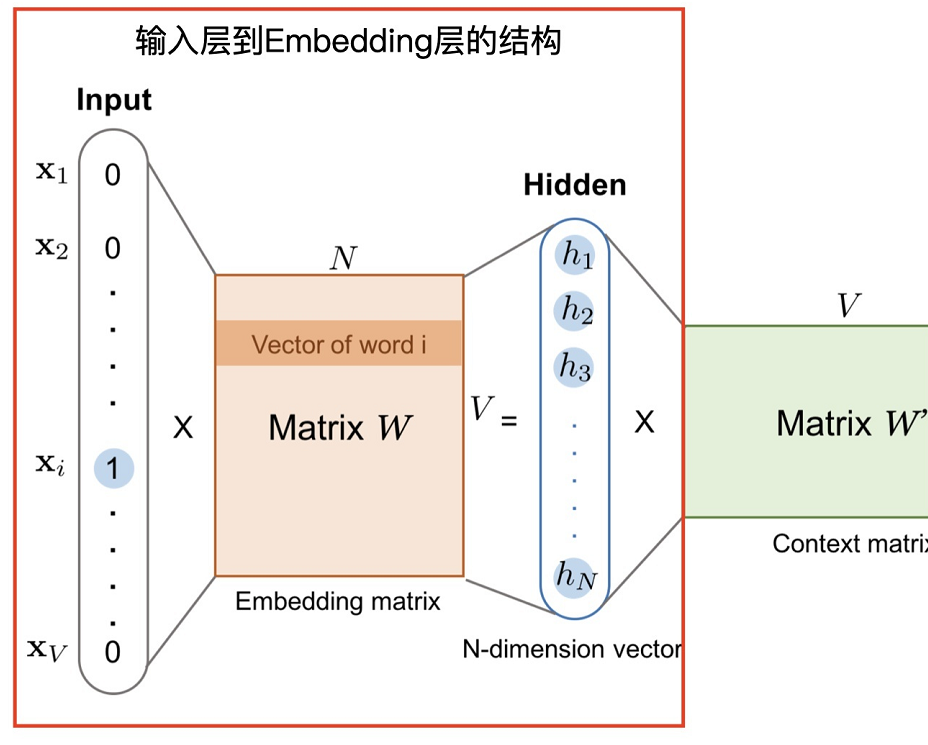
- Embedding层其实就是一个fully connect的隐藏层,起到对one-hot特征进行降维的作用
- stacking层会把不同的 Embedding 特征和数值型特征拼接在一起,形成新的包含全部特征的特征向量
- stacking再往上是由数个全连接层组成的MLP结构
- scoring层输出最后的结果
t-SNE数据降维
t-SNE(t-distributed stochastic neighbor embedding)是用于降维的一种机器学习算法,常用于高维数据可视化
t-SNE的两大优势:
- 对于不相似的点,用一个较小的距离会产生较大的梯度来让这些点排斥开来。
- 这种排斥又不会无限大(梯度中分母),避免不相似的点距离太远。
四个不足:
- 主要用于可视化,很难用于其他目的
- t-SNE倾向于保存局部特征,对于本征维数(intrinsic dimensionality)本身就很高的数据集,基本无法完整的映射到2-3维的空间
- t-SNE没有唯一最优解,且没有预估部分。如果想要做预估,可以考虑降维之后,再构建一个回归方程之类的模型去做。但是要注意,t-sne中距离本身是没有意义,都是概率分布问题。
- 训练太慢。有很多基于树的算法在t-sne上做一些改进
>>> import numpy as np
>>> from sklearn.manifold import TSNE
>>> X = np.array([[0, 0, 0], [0, 1, 1], [1, 0, 1], [1, 1, 1]])
>>> X_embedded = TSNE(n_components=2, learning_rate='auto',
... init='random').fit_transform(X)
>>> X_embedded.shape
(4, 2)

