知识图谱笔记
对近期读到的几篇有关知识图谱的文章进行总结摘录
本文更好的阅览格式见:https://www.zybuluo.com/lokvahkoor/note/1659844
认知智能
- 人类与动物在认知水平上的核心差异:语言能力。语言认知能力的核心是理解和解释能力
我们现在每天获取信息大都是通过微博、微信、头条、知乎等,事实上这些媒体都存在大量的推荐算法,我们现在的认知和世界观很大程度上是由这些推荐算法塑造的,所以一定程度上我们人类在逐步的把人类的认知世界的任务交给机器,所以智能机器将会成为认知世界的新主体。
知识工程
在实现认知智能的过程中有一门重要学科:知识工程。知识工程脱胎于人工智能最重要的学派之一:符号主义。符号主义认为认知即计算;知识是人工智能的核心和基础,知识的表示、推理和运用是人工智能的核心。其代表性人物是Newell和Simon,他们曾经提出符号主义的理论基础:物理符号系统。这一理论认为智能的本质就是符号的操作和运算。这一理念被知识工程的鼻祖Edward Feigenbaum重新阐释为AI系统=知识+推理,知识工程正是在这样的基础上蓬勃发展起来的。知识工程是一门以专家系统的构建和运用为主要内容的学科,而专家系统则是一类利用专家的知识和推理能力来解决实际问题的系统。
传统知识工程
传统知识工程(上世纪7、80年代)是典型的自上而下的做法,严重依赖专家和人的干预,需要领域专家先把知识表达出来,然后需要知识工程师把领域专家的语言描述为计算机可以表达和处理的形式,以及用户的反馈。
大数据知识工程
- 大数据工程以2012年Google发布其知识图谱系统为开端。
- 知识图谱的核心是自动化的知识获取。
- 知识图谱支撑的应用,大部分是简单应用:以实体(词汇)为中心的知识表示,表达的往往是实体的属性和关系;它的推理极为简单,往往都是基于路径或者上下位词的简单推理,以及基于分布式表示的推理,比如基于embedding向量相似性的一些推理。所以知识图谱这几年的发展,解决了大规模简单应用的场景。
- 总体上,现在获取的都是简单的词汇、实体和世界知识。
- 针对面向互联网的百科知识获取,目前基本实现了从自动数据获取->自动抽取->自动验证三个环节的完整闭环
- 其中的自动验证是通过一个大规模众包平台,以阅读理解验证码的形式进行验证
- 从百科文本抽取简单知识(比如“姚明老婆是谁”“姚明出生在哪里”这类百科知识)准确率可以做到90%
- 大数据知识工程解决的问题:
- 词汇鸿沟问题(vocabulary gap)
- 很多时候用户所提供的搜索关键词,与厂家提供的文档、商品之间存在着巨大的词汇表达差异
- 缺失的因果链条
- 碎片化数据的关联与融合
- 比如,告诉我们身份证,往往表示为ID,这样一种关联就可以告诉我们这两个字段是可以匹配的
- 提升机器的自然语言理解水平
- 体现在词汇实体理解上
- 词汇鸿沟问题(vocabulary gap)
- 知识图谱的应用模式:
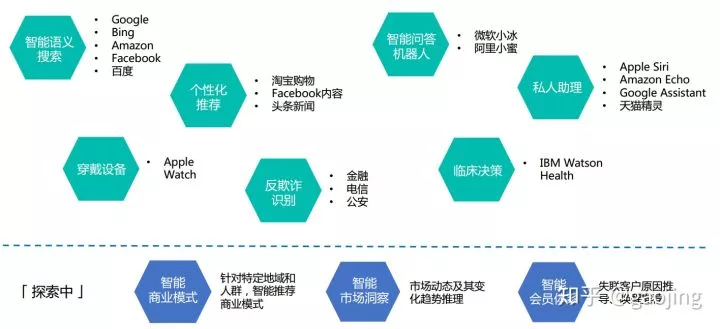
- 知识图谱技术链:
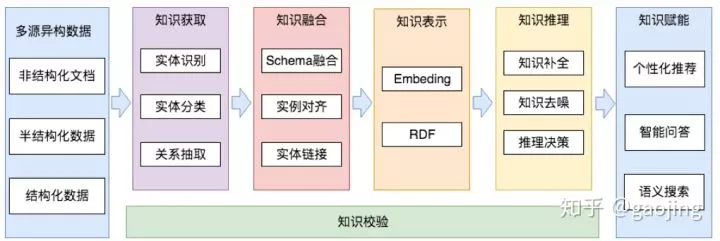
知识图谱的未来
- 从大规模、简单的应用场景向小规模、复杂应用场景切换
- 从大规模综合领域的推荐系统转向细分行业中解决具体问题的分析系统
- 挑战体现在:密集的专家知识、有限的数据资源和深度的知识应用
- 细分行业中具体复杂的问答系统
- 工业设备/复杂系统的故障诊断
- 这些领域中往往缺乏高质量的,可直接使用的数据
工程细节
-
要让图谱能够work,那么:
-
首先需要定义实体;
-
建立外部数据和图谱关联的媒介层;
-
关联到图谱之后,决定进行的操作
-
-
图数据库是必须的么?
- 图数据库不是必须的,就查询型性能来说,关系型数据库完爆图数据库,图数据库的好处只是提供了一个比较严禁和完善的知识图谱体系架构,从实体到概念,从概念到本体,各种schema定义清晰
- 如果对知识图谱不是很理解,可以尝试使用图数据库,但是缺点是容易被框架束缚,对于各种实体定义是很花时间的,如果只作为核心的推理层,还是能接受的。前期在业务上实际上是不推荐使用的。
-
除了NER我们还有哪些能够关联实体的方式?
- 搜索引擎:elasticsearch的DSL 直接查 label,同义词,desc,就能拿到一堆候选集合,然后我们只要建立一个模型,判断候选集是不是在文本中出现,做一个rerank,基本就能拿到挺好的结果
- 字符匹配,这个依赖是我们有完善的同义词词关系,然后也可以搞个模型,把实体的特征和文本的特征一拼接,让模型判断是不是 文本中存在这个实体,偷懒的方式就是只要匹配到关键词,就算命中这个实体,最好是要分词了,没有也没关系,加一个同义词就能匹配上了,可能会有歧义,那实际上是看对实体的类型划分,划分明确的话,模型还是可以判断的出来的
-
知识表示的主要方法:
- 基于离散符号的知识表示法:
- RDF(Triple-based Assertion Model) 三元组模型,构建方式主要是主-谓-宾有向标记图和RDFS(simple Vocabularty and schema)
- OWL(Web Ontology language):是一种W3C开发的网路本体语言,用于对本体进行语义描述
- SPARQL(Protocol and RDF Query Language) :RDF的查询语言,支持主流图形数据库。下图URI/IRI为主要网络协议,主要数据存储格式是RDF与XML
- 基于连续向量的知识表示:
- KG embedding 主要是KG中实体与关系映射到一个低维的向量空间,主要的方法有张量分解、NN、距离模型(现有的词向量模型基于连续向量空间来表示)
- 基于离散符号的知识表示法:
-
实体抽取
- 传统方法(HMM(隐马尔科夫模型) CRF(条件随机场) SVM、最大熵分类模型等方法进行处理。现在能采用深度学习,比如CNN\RNN\LSTM及LSTM-CRF
-
实体链接
- 目的是将实体提及与知识库中对应实体进行链接 ,主要解决实体名的歧义性与多样性问题,是文本中实体名指向真实世界实体的任务。
- 知识图谱-实体抽取与实体链接
-
知识图谱构建流程
- 自底向上:
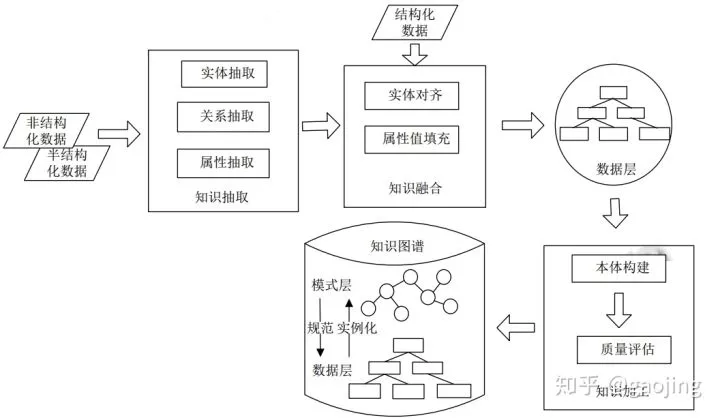
- 自顶向下:
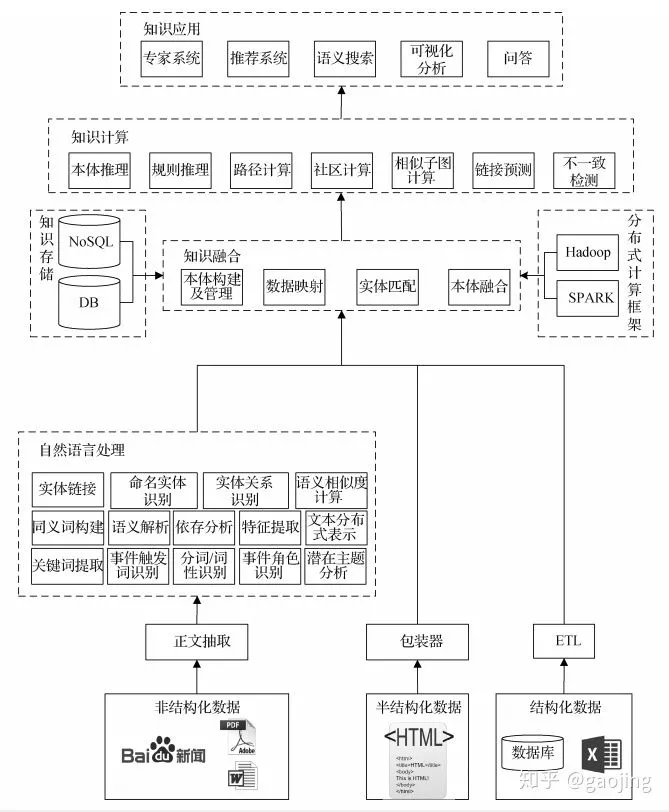
- 自底向上:
项目案例
- 利用网络上公开的数据构建一个小型的证券知识图谱/知识库
https://github.com/lemonhu/stock-knowledge-graph.git - 农业领域知识图谱: 使用爬虫获取Wikidata数据构建
https://github.com/CrisJk/Agriculture-KnowledgeGraph-Data.git
参考:

