
hadoop windows平台开发环境搭建
1.前序
学习大数据,高配置的电脑是必不可少的,因为要安装很多的软件,尤其是虚拟机是比较耗性能,可能会出现卡顿的情况,非常影响程序编写。但是,低配置(windows系统下,无需安装虚拟机)也是可以搭建简单的单机模式的hadoop,可以达到初步了解hadoop操作与开发的功能。在windows系统下,关于hadoop安装与配置,以及简单的shell操作可以参考.......本文主要是在windows下,使用eclipse搭建hadoop环境。
前提条件:windows环境下,已经完成hadoop安装与配置工作,并且能够正常启动运行。
2.工具准备
(1)jdk1.8
(2)eclipse(Mars2)
(3)Hadoop2.7.4
(4)hadoop eclipse插件:hadoop-eclipse-plugin-2.7.4.jar
3.开发步骤:
(1)启动hadoop : start-yarn.sh、start-dfs.sh (配置hadoop看历史文章) ;
(2)windows本地配置Linux的主机IP映射:(不配置直接使用IP也行,这里是windows环境,直接使用localhost即可);
(3)将hadoop-eclipse-plugin-2.7.4.jar放进eclipse的plugins目录,启动eclipse;
(4)eclipse配置Hadoop。
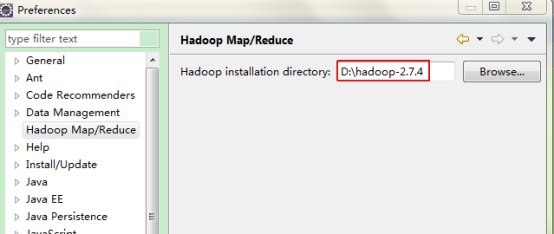
1)eclipse的Window->Preferences进入进行设置hadoop安装路径,如下图:
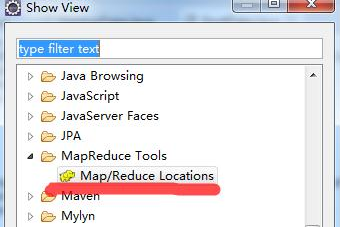
2)把map\reduce设置窗口调出显示,方便设置Window->Show View->Other找到Map/Reduce Locations,单击确定。
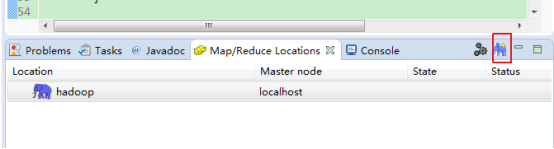
3)经过上面步骤后,在eclipse下面会显示如下(默认是没有下面那行hadoop localhost的,我这里因为已经设置了):
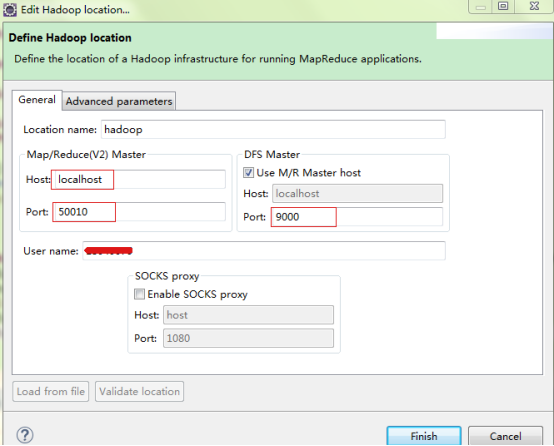
4)单击带+号的大象图标,就可以进入设置界面了。但是,这一步的设置是最容易出错的地方,我在前面配置文件中提到,只有hdfs文件系统的端口设置为9000了,其他的都是默认的,那么怎么知道我上面应该配置的是50010呢?很多时候,hadoop配置时可能显示可能是50020、50030等,这时候我们可以去看一下启动的hadoop窗口了,有一个namenode窗口,上面显示了我们要配置的这两个端口号。

在namenode或datanode窗口会看到9000端口:

5)切换MapReduce视图可以看到HDFS文件系统的信息:
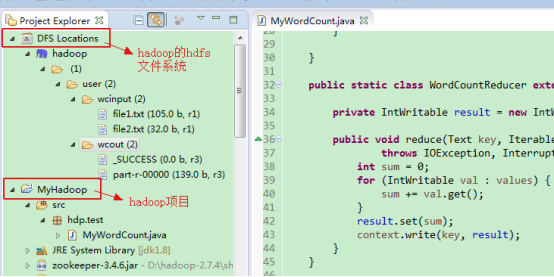
关于搭建hadoop项目,与典型案例的编码测试,可以参考:
https://blog.csdn.net/houjingjun/article/details/70198223
https://blog.csdn.net/yang1464657625/article/details/78453678
4. 创建Map/Reduce工程并进行开发调试
(1)创建map/reduce工程wordcount
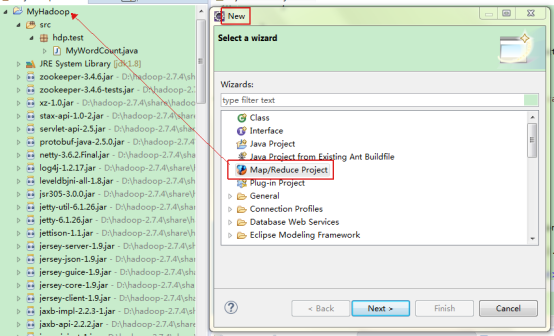
(2)新建测试类MyWordCount
代码:https://blog.csdn.net/houjingjun/article/details/70198223
package hdp.test; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; /** * 文本单词数统计 * @author lowi * map/reduce示例 * 说明:LongWritable, IntWritable, Text 均是 Hadoop中实现的用于封装 Java 数据类型的类,这些类实现了WritableComparable接口, * 都能够被串行化从而便于在分布式环境中进行数据交换,你可以将它们分别视为long,int,String 的替代品 */ public class MyWordCount { /** * map实现类 * * KEYIN:输入kv数据对中key的数据类型,对应于Object * VALUEIN:输入kv数据对中value的数据类型,对应于Text * KEYOUT:输出kv数据对中key的数据类型,对应于Text * VALUEOUT:输出kv数据对中value的数据类型,对应于IntWritable * */ public static class WordCountMapper extends Mapper<Object, Text, Text, IntWritable>{ private final IntWritable one=new IntWritable(1); //定义一个值为1的整型(int) private Text word=new Text(); //Text实现了BinaryComparable类可以作为key值 /* * Mapper接口中的map方法: * map方法是提供给map task进程来调用的,map task进程是每读取一行文本来调用一次我们自定义的map方法 * map task在调用map方法时,传递的参数: * 一行的起始偏移量LongWritable作为key * 一行的文本内容Text作为value */ public void map(Object key, Text value, Context context) throws IOException, InterruptedException{ //拿到一行文本内容,转换成String类型,并按照' ','\t','\n','\r','\f'等字符进行分割单词,组成单词数组 StringTokenizer stn=new StringTokenizer(value.toString()); while(stn.hasMoreTokens()){ word.set(stn.nextToken()); context.write(word, one); //输出<单词,1> } } } /** * reducer实现类 * * KEYIN:对应mapper阶段输出的key类型,对应于Text * VALUEIN:对应mapper阶段输出的value类型,对应于IntWritable * KEYOUT:reduce处理完之后输出的结果kv对中key的类型,对应于Text * VALUEOUT:reduce处理完之后输出的结果kv对中value的类型,对应于IntWritable * * 说明:在map与reducer之间的阶段,即shuffle阶段,将map发来的数据进行了聚合,排序等操作 */ public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ private IntWritable result = new IntWritable(); /* * reduce方法提供给reduce task进程来调用 * * reduce task会将shuffle阶段分发过来的大量kv数据对进行聚合,聚合的机制是相同key的kv对聚合为一组 * 然后reduce task对每一组聚合kv调用一次自定义的reduce方法 * 比如:<hello,1><hello,1><hello,1><tom,1><tom,1><tom,1> * hello组会调用一次reduce方法进行处理,tom组也会调用一次reduce方法进行处理 * 调用时传递的参数: * key:一组kv中的key * values:一组kv中所有value的迭代器 */ public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; //定义一个计数器 //通过value这个迭代器,遍历这一组kv中所有的value,进行累加 for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); //输出单词统计结果 } } //测试实现map/reducer类,主方法入口 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{ /* * JobConf:map/reduce的job配置类,向hadoop框架描述map-reduce执行的工作 * 构造方法:JobConf()、JobConf(Class exampleClass)、JobConf(Configuration conf)等 */ Configuration conf=new Configuration(); String[] cliArgs=new GenericOptionsParser(conf,args).getRemainingArgs(); //这里需要配置参数即输入和输出的HDFS的文件路径 if(cliArgs.length!=2){ System.err.println("Usage: MyWordCount <in> <out>"); System.exit(2); } Job myJob=Job.getInstance(conf, "my first job"); //设置job名称 myJob.setJarByClass(MyWordCount.class); //指定本job所在的jar包 myJob.setMapperClass(WordCountMapper.class);//设置wordCountJob所用的mapper逻辑类为哪个类 myJob.setReducerClass(WordCountReducer.class);//设置wordCountJob所用的reducer逻辑类为哪个类 myJob.setCombinerClass(WordCountReducer.class);//为job设置Combiner类 //设置最终输出的kv数据类型 myJob.setOutputKeyClass(Text.class); myJob.setOutputValueClass(IntWritable.class); //设置要处理的文本数据所存放的路径 FileInputFormat.addInputPath(myJob, new Path(cliArgs[0])); //设置输入路径 FileOutputFormat.setOutputPath(myJob, new Path(cliArgs[1])); //设置输出路径 //提交job给hadoop集群 boolean isSucced=myJob.waitForCompletion(true); System.out.println(isSucced); System.exit(isSucced? 0 : 1); } }
(3)设置WordCount运行参数
右键wordcount工程,Run As->Run Configurations
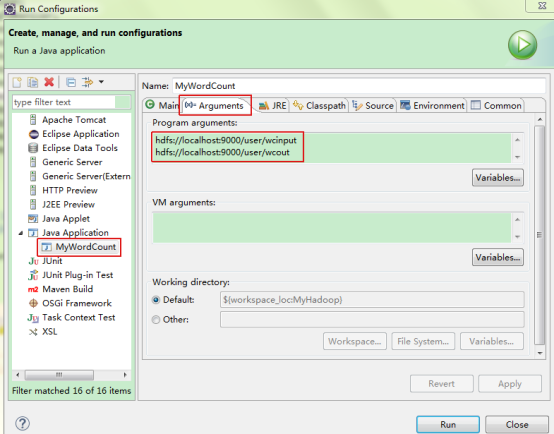
配置运行时的input和output两个参数,先把本地文件上传到了input目录,hdfs目录作为输出,其中out目录在hdfs中不存在,如果已经存在则先删除,或使用其他名字。
4)经过配置后,运行WordCount程序,一切正常的化在eclipse控制台打印的信息如下:
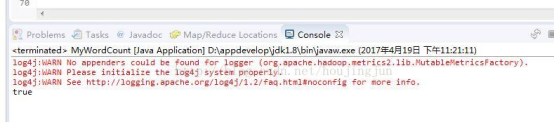
在配置过程中遇到的问题:
1)HADOOP_HOME和path配置出问题时,无法启动hadoop
2)在eclipse中配置map/reduce Locations时,报错往往是配置有问题,主要是端口,而不是插件或eclipse版本问题,如我就遇到如下报错
Hadoop异常:An internal error occurred during: “Map/Reduce location status updater”.
Java.lang.NullPointerException;
3)运行代码,无报错日志打印
方案:加入日志提示:
其中log4j.properties具体内容:
# Configure logging for testing: optionally with log file #log4j.rootLogger=debug,appender log4j.rootLogger=info,appender #log4j.rootLogger=error,appender #\u8F93\u51FA\u5230\u63A7\u5236\u53F0 log4j.appender.appender=org.apache.log4j.ConsoleAppender #\u6837\u5F0F\u4E3ATTCCLayout log4j.appender.appender.layout=org.apache.log4j.TTCCLayout
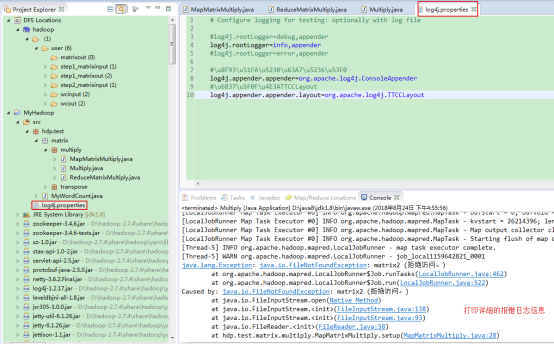
4)运行报错:Caused by: java.io.FileNotFoundException: matrix2 (拒绝访问。)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号