Windows平台安装配置Hadoop2.5.2(不借助cygwin)
一、步骤:
1.JDK安装;
2.下载hadoop2.7.4.tar.gz,或者自行去百度下载;
3.下载hadooponwindows-master.zip【**能支持在windows运行hadoop的工具】。
二、安装hadoop2.7.4
下载hadoop2.7.4.tar.gz ,并解压到想要的目录下,放在D: \hadoop-2.7.4。
三、配置hadoop环境变量
1.windows环境变量配置
右键单击我的电脑 –>属性 –>高级环境变量配置 –>高级选项卡 –>环境变量 –> 单击新建HADOOP_HOME;
2.接着编辑环境变量path,将hadoop的bin目录加入到后面;
四、 修改hadoop配置文件
1、编辑“D: \hadoop-2.7.4\etc\hadoop”下的core-site.xml文件,将下列文本粘贴进去,并保存;
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/D:/hadoop-2.7.4/workplace/tmp</value> </property> <property> <name>dfs.name.dir</name> <value>/D:/hadoop-2.7.4/workplace/name</value> </property> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
2.编辑“D: \hadoop-2.7.4\etc\hadoop”目录下的mapred-site.xml(没有就将mapred-site.xml.template重命名为mapred-site.xml)文件,粘贴一下内容并保存;
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapred.job.tracker</name> <value>hdfs://localhost:9001</value> </property> </configuration>
3.编辑“D: \hadoop-2.7.4\etc\hadoop”目录下的hdfs-site.xml文件,粘贴以下内容并保存。请自行创建data目录,在这里我是在HADOOP_HOME目录下创建了workplace/data目录;
<configuration> <!-- 这个参数设置为1,因为是单机版hadoop --> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.data.dir</name> <value>/D: /hadoop-2.7.4/workplace/data</value> </property> </configuration>
4.编辑“D: \hadoop-2.7.4\etc\hadoop”目录下的yarn-site.xml文件,粘贴以下内容并保存:
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>8</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>8192</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>2048</value> <discription>single_mask_default_1024MB</discription> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>
5.编辑“D: \hadoop-2.7.4\etc\hadoop”目录下的yarn-env.sh文件,粘贴以下内容并保存:
JAVA_HEAP_MAX=-Xmx3072m
6.编辑“D: \hadoop-2.7.4\etc\hadoop”目录下的hadoop-env.cmd文件,将JAVA_HOME用 @rem注释掉,编辑为JAVA_HOME的路径,然后保存;
@rem set JAVA_HOME=%JAVA_HOME%
set JAVA_HOME=D:\java\jdk
报错内容:
ERROR org.apache.hadoop.yarn.server.nodemanager.NodeStatusUpdaterImpl: Unexpected error starting NodeStatusUpdater
org.apache.hadoop.yarn.exceptions.YarnRuntimeException: Recieved SHUTDOWN signal from Resourcemanager ,Registration of NodeManager failed, Message from ResourceManager: NodeManager from localhost doesn't satisfy minimum allocations, Sending SHUTDOWN signal to the NodeManager.
注意:
(1)每次修改配置信息,先将配置中workplace下data、tmp文件下子文件与文件夹删除:data文件清空后还会再生成,然后再格式namonode: #hadoop namenode –format;
(2)但是待执行完毕即可,不要重复format。
五、替换文件
下载到的hadooponwindows-master.zip,解压,将bin目录(包含以下.dll和.exe文件)文件替换原来hadoop目录下的bin目录;(这个只是其中一种,其他的可以参考其他)
六、运行环境
1.运行cmd窗口,执行“hdfs namenode -format”;
2.运行cmd窗口,切换到hadoop的sbin目录,执行“start-all.cmd”,它将会启动以下4个进程。
成功后,如图:
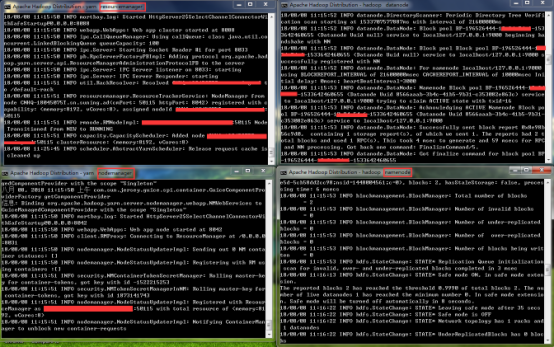
3.至此,hadoop服务已经搭建完毕。
注:(1)单机模式下,只需要开启namenode和datanode即可,不需要全部开启。此时操作命令:HADOOP_HOME\sbin目录,运行如下命令:start-dfs
注意两个命令目录位置不同,该命令运行后,会打开两个cmd窗口,分别启动datanode进程和namenode进程(如果要关闭hadoop则运行stop-dfs命令,我们这里要进行测试,暂时保持运行状态)。
七、上传测试,操作HDFS
根据你core-site.xml的配置,接下来你就可以通过:hdfs://localhost:9000来对hdfs进行操作了。
1.创建输入目录:
C:\WINDOWS\system32>hadoop fs -mkdir hdfs://localhost:9000/user/
C:\WINDOWS\system32>hadoop fs -mkdir hdfs://localhost:9000/user/wcinput
或者(进入sbin目录下):
D: \hadoop-2.7.4\sbin>hadoop fs -mkdir /user/
D: \hadoop-2.7.4\sbin>hadoop fs -mkdir /user/wcinput
2.上传数据到目录:(注意文件路径:D:\file1.txt)
C:\WINDOWS\system32>hadoop fs -put D:\file1.txt hdfs://localhost:9000/user/wcinput
C:\WINDOWS\system32>hadoop fs -put D:\file2.txt hdfs://localhost:9000/user/wcinput
或者(进入sbin目录下):(注意文件路径:/file1.txt)
D: \hadoop-2.7.4\sbin>hadoop fs -put /file1.txt /user/wcinput
D: \hadoop-2.7.4\sbin>hadoop fs -put /file2.txt /user/wcinput
3.查看文件
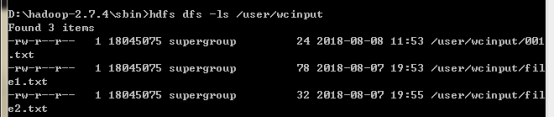
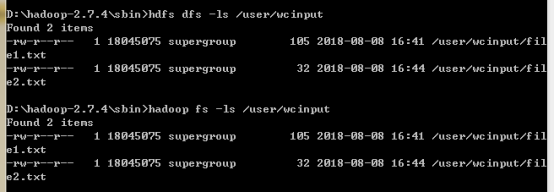
注意:这里等价于:
hdfs dfs -ls hdfs://localhost:9000/user/wcinput
hadoop fs -ls hdfs://localhost:9000/user/wcinput
(4)查看文件内容:
fdfs dfs –cat /user/wcinput/file1.txt

大功告成。
八、附录:hadoop自带的web控制台GUI
1.资源管理GUI:http://localhost:8088/
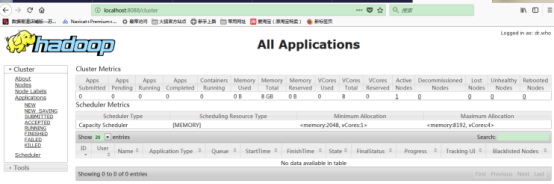
2.节点管理GUI:http://localhost:50070/;
参考:
https://blog.csdn.net/antgan/article/details/52067441
https://blog.csdn.net/flygoa/article/details/52230745
https://blog.csdn.net/houjingjun/article/details/70198223
https://blog.csdn.net/fly_leopard/article/details/51250443

 浙公网安备 33010602011771号
浙公网安备 33010602011771号