
hadoop知识系列二:读写hdfs
一.hdfs读写流程
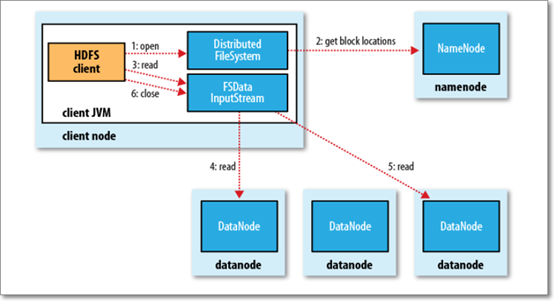
读:
步骤一. HDFS的client客户端调用分布式文件系统对象的open()方法,然后通过RPC(远程过程调用)方式调用NameNode的open(),本质就是获取DataNode的block locations信息(与客户端远近做了排序),并返回到客户端。
步骤二.HDFS客户端Client调用open()方法的同时,会生成输入流对象FSDataInputStream,再调用该输入流的read()方法(此时输入流对象已知道NN传回客户端的DN信息);
步骤三.输入流对象调用距离最近的DataNode去通过网络连接进行连接并读数据,依次DN1,DN2,DN3…(每读完一个datanode就关闭该连接的对象),读完所有数据关闭流对象。
注意:大文件会有很多block组成,相关的元数据信息会很多。每次只从NameNode中获取一批block,读完后,再获取下一批block进行读取,即:多批次执行完成读文件操作。
不正常情况如下:
1).假设:FSDataInputStream输入流对象,在读取最近的DN1,因为网络问题中断连接,此时,输入流对象会找到另外比较近的副本DN2去读;同时,输入流对象会记录下DN1有问题,后面输入流对象就不会再尝试到DN1上读取数据。
问:Datanode挂了,如何恢复?
答:1)各个DN节点,每隔一小时就会向NN发送block report信息,那么NN就会知道哪些block块缺失,比如缺失block1;2)当DN(存在block1副本)向NN发送心跳的时候,NN就会给DN返回复制block1的指令(将block1复制给其他数据节点),使得block1副本数维持3个。
2).假设:client读取的数据和开始存入DN的数据不一致时。
不一致:
1:读取另外一个副本的DN2的数据.
2.输入流对象告诉NN,DN1的块有问题读取不了,NN把DN1删掉,再把别的DN2上的副本复制到另外的DN副本数维持为3。
如何判断不一致?
当向DN存数据的同时与之对应也存了校验和checksum(通过CRC32算法得来,出问题概率非常小)。当client读取DN的时候,会把数据块block和校验和checkSum一并读取,然后client对读取的block进行计算校验和,并比较2个校验和是否相等,相等时数据一致。
二.写操作
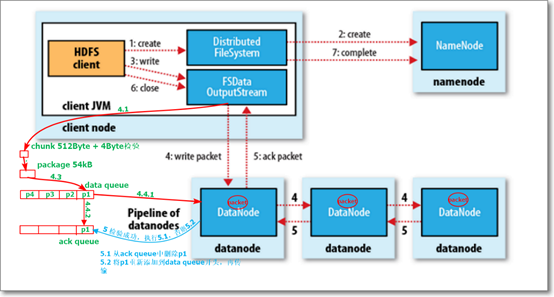
写:
正常情况下:
步骤一:client调用分布式文件系统对象的create(),然后通过RPC调用NN的create()这个方法。返回文件存储的数据节点信息(存在哪些节点)。
create()方法作用:
1).判断nn是否正常运行.
2).判断文件是否存在.
3).判断client是否有权限创建文件.
4).向edits.log写日志.
步骤二:client调用create()方法的同时,会生成输出流对象FSDataOutputStream。调用输出流对象的write(),并通过RPC方式告知NN,要进行addblock操作;此时,NN就返回block副本可存储的3个DN的信息给输出流对象。
步骤三:在将数据写到DN之前,数据先写到chunk(512Byte+4Byte)里面(写满chunk的时候,先计算一下校验值(4Byte),再写到chunk(516Byte)里),再写到package(64kb)里面,package写满之后,放到数据队列(data queue)中,同时会存到确认队列(ack queue);这时候DataStreamer对象会从数据队列取出一个package向3个DN节点写数据(写数据的同时会将package存到确认队列-ack queue,同时会删除数据队列中该package数据),DN1->DN2->DN3。当传输到最后一个数据节点的时候,会计算一下package新的校验值,与package里面自带的校验值进行比对判断,是否相等,如果相等传输成功;如果不相等,没有传输成功。
步骤四:并通过pipeline通道逐层返回ack信息到第一个数据节点,每层都对比校验值,如果不成功,ack queue会再次放到data queue当中进行传输.如果成功,删除ack queue内的pakage。关闭输出流对象,分布式文件系统RPC到NN调用complete().
注意:package分别存储到不同的队列的目的:防止写数据过程中,p没有传输成功,可以将ack queue中数据p在放到data queue中重新传输。
异常情况下:
例如:在DN传输数据的时候,网络中断,即:block副本2未成功传输,hdfs会:
1.关闭pipeline.
2.把已经完成DN1的block中已有id,version变成新的id,version.
3.DN通过心跳机制告诉NN新的id,version,把old(id,version)的block删除.
4.构建新的pipeline,跳过故障的DN,走完正常的2个datanode后续步骤.写完之后,告诉namenode数据节点上block副本写入的情况。通过心跳的方式,NN告知DN执行缺失副本的复制操作,即:从存在block副本的DN复制副本到新的节点中,维持3个副本。
三.Hadoop HA高可用:
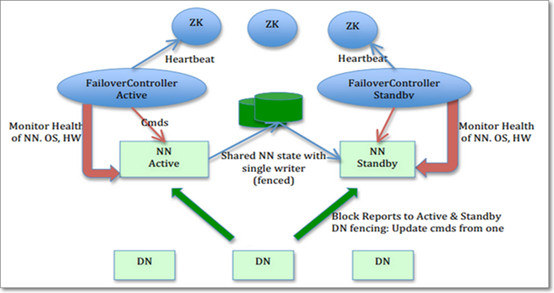
分析:
NN(备Strandby)与NN(主Active)的元数据通过共享存储(NFC,QJM,zookeeper)保持一致,DN向两个NN进行注册,并同时通过“心跳”方式,定期向2个NN发送block report(保证Namenode一直包含最新的元数据)。当Active中断之后,Standby可以做热备。
如何做到?
每个NN上面都有zkfc(故障恢复控制器:监控namenode健康状况)的进程,会时不时 ping NN判断NN是否是活的,发现NN死了之后,该NN的zkfc进程就会通知zk集群,zk集群再告诉其他的zkfc进程,让Standby生效变为active。
三.联邦:
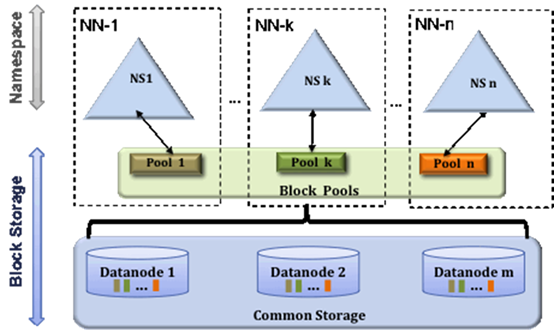
分析:
每个NN的内存是有限的,也同时造成DN存储的数据是有上限的。
多个NN,分解单个NN的压力,把数据放到块池里.
(1)多个namenode相互独立,不需要相互协调,只需管理各自的命名空间和块。一个namenode失效,不会影响与其相关的其他datanode为其他namenode提供服务。
(2) 每个命名空间管理自己的一组块(即:块池block pool),块池共享所有的数据节点存储。
(3)理解:数据节点是物理概念,而块池是逻辑概念(即:一组块的逻辑组合),块池中各个块实际存储再各个不同的数据节点中。
命名空间管理基本原理:各个命名空间挂载到全局“挂载表”,实现数据全局共享。——客户端挂载表。
特点:(1)扩展性(2)高吞吐量(3)良好隔离性。
缺点:不能解决单点问题,namenode还需要配置后备名称节点backnamenode。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号