
hadoop知识系列一:hdfs
1.1 Hadoop架构
HDFS (Hadoop Distributed File System);Hadoop由三个模块组成:分布式存储HDFS、分布式计算MapReduce、资源调度引擎Yarn

分布式:利用一批通过网络连接的、廉价普通的机器,完成单个机器无法完成的存储、计算任务。
1.3 HDFS是什么
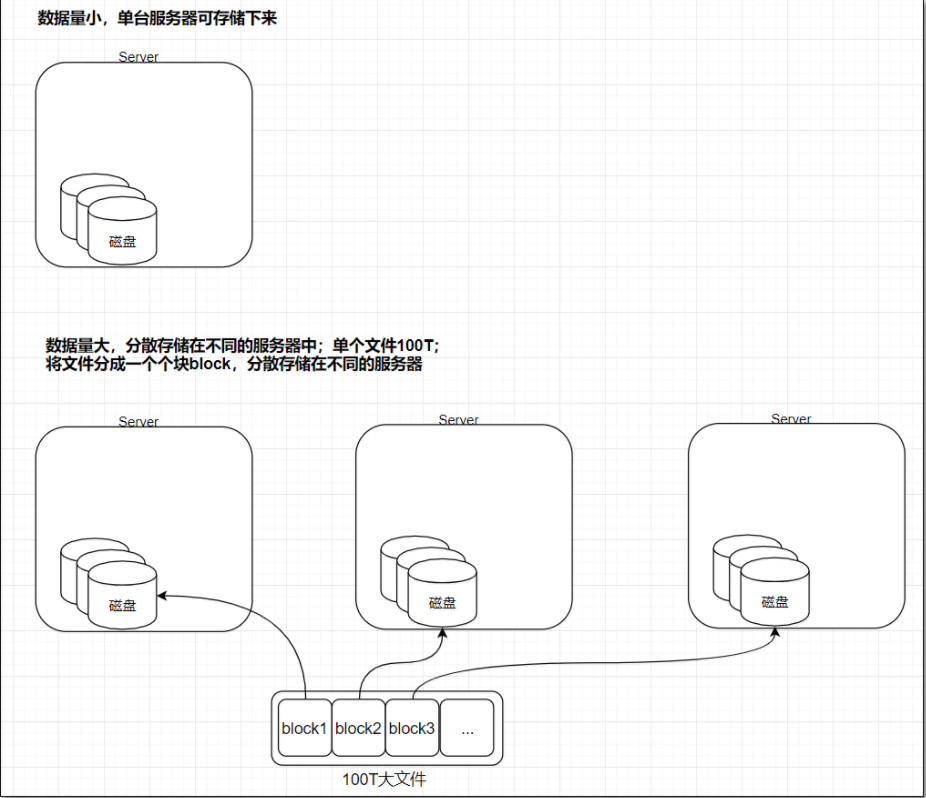
Hadoop分布式文件系统。适合存储大文件,不适合存储小文件。
高可用、容错、可扩展
2.1 数据块block
2.1.1 HDFS block块
-
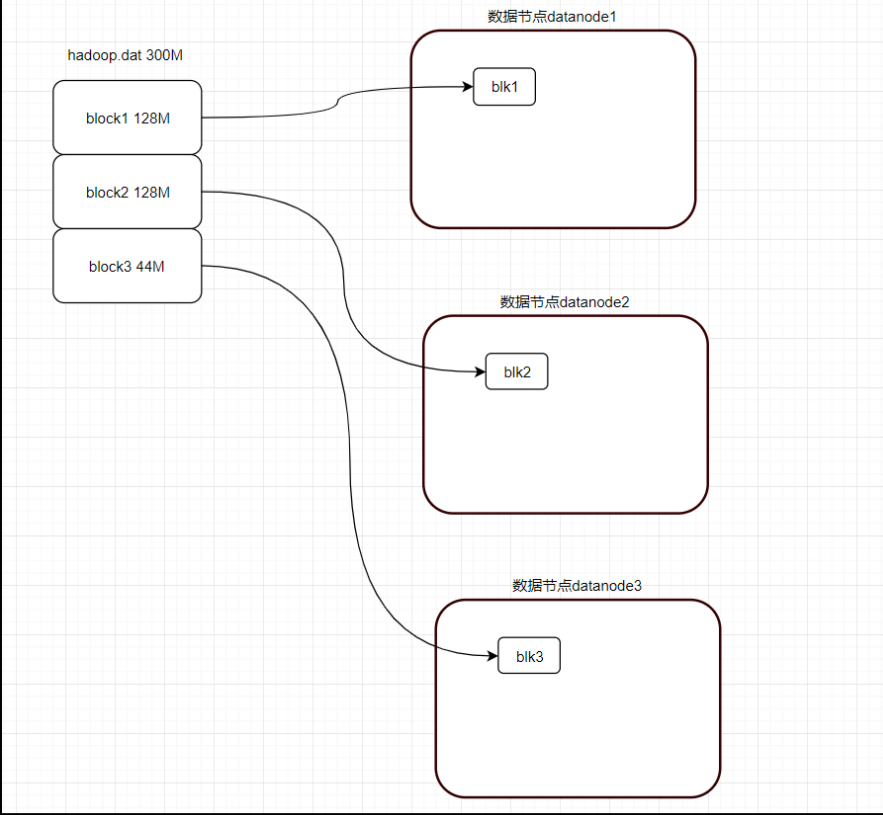
HDFS3.x上的文件,是按照128M为单位,切分成一个个block,分散的存储在集群的不同数据节点datanode上
-
问:HDFS中一个44M大小的块会不会占据128M的空间?
答:不会。只占据44M大小的块,也就说block=<128M,以实际大小在block中存储。
-
问:这样存储有没有问题?
答:会有问题。如果datanode所在服务器宕机,部分数据可能会丢失,所以需要有副本block。
补充:
(1)HDFS为什么要是128M?
答:HDFS块比磁盘块要大,主要目的是为了最小化寻址开销。(块足够大,那么磁盘传输数据的时间会明显大于定位这个块开始位置的时间)
随着新代磁盘驱动器传输速率的提升,块的大小会设置的更大;
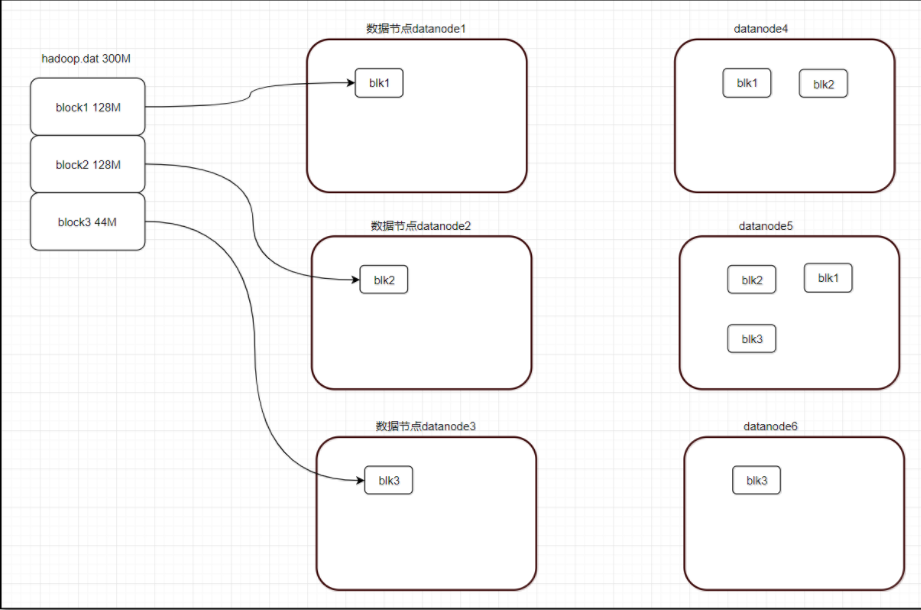
2.2 block副本
保正数据的可用及容错
-
replication = 3
-
hdfs-site.xml
<property> <name>dfs.replication</name> <value>3</value> </property>
-
实际机房中,会有机架,每个机架上若干服务器
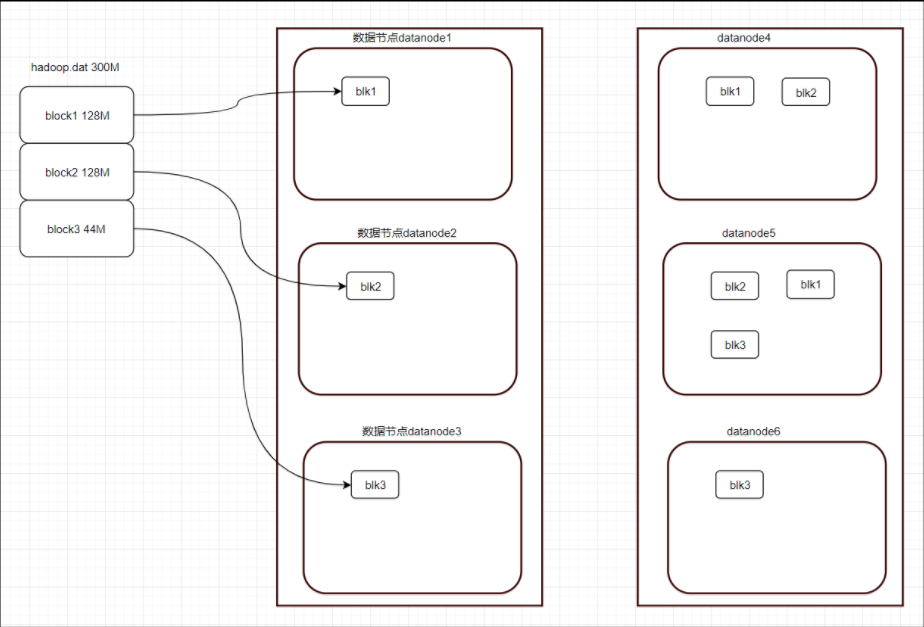
3.3 机架存储策略
机架感知策略:hdfs自动决策,不需要人工干预。
3个副本block在不同机架上存储策略(常用方式):副本1存储在机架1的datanode1上,副本2存储在机架2的datanode2(与副本1不同机架)上,副本3存储在副本1所在的同机架上不同数据节点上,即机架1的datanode3(即:副本3存储在机架1,或者存储在机架2的datanode4)。注意:同一机架的同一节点上,只能存储block的一个副本。
这样存储的好处:
(1)副本1和副本2存储在不同机架上,为了防止其中一个机架宕机,使得数据丢失。
(2)副本3和副本1存储在同一机架不同数据节点上,为了更好的利用机架上服务器之间快速的带宽;
问:副本3为什么不放在机架3上?
答:除了上面(2)的原因,还有就是不同的2个机架同时宕机的情况,概率极低。综合考虑,以上面的存储策略更好。
机架与机架之间通信,需要经过多个交换机(至少3个)进行通信,而且距离可能比较远。如果是3个副本都放在不同的机架上,在并发比较高的情况下,机架间的带宽是很容易被打满,使得整体集群的响应速度变慢。
注意:机房的带宽是非常宝贵的资源。
2.4 block的一些操作
设置文件副本数,有什么用?
作用:(1)多副本,可以提高读操作的速度;(2)多副本,可以防止数据的丢失。
hadoop fs -setrep -R 4 /path
查看文件的块信息?
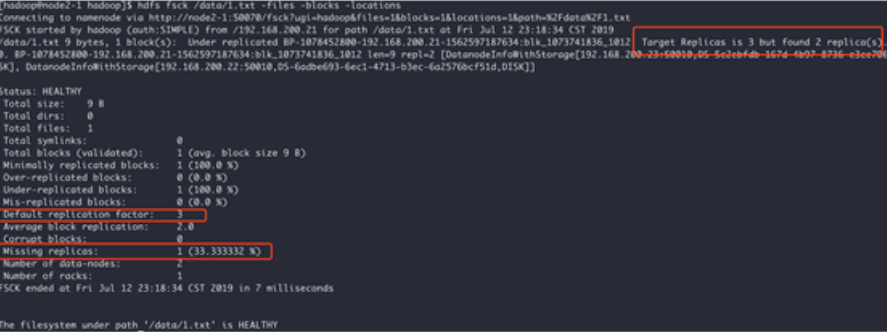
主要是查看文件的块信息,包括实际有几个副本,缺失几个副本。
hdfs fsck /02-041-0029.mp4 -files -blocks -locations
三. HDFS体系架构
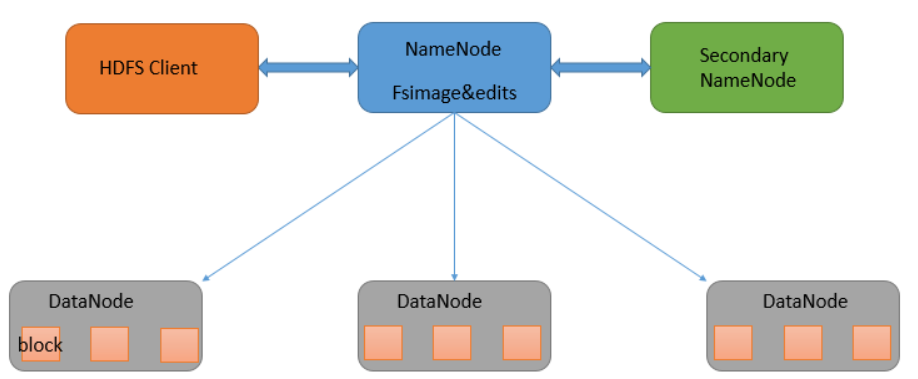
HDFS是主从架构Master/Slave、管理节点/工作节点
3.1 NameNode
-
fs文件系统,用来存储、读取数据
-
读文件 -> 找到文件 -> 在哪 + 叫啥?
-
window -> 虚拟机说明.txt

HDFS也是fs,它也有metadata;由NameNode存储在其内存中。
-
管理节点,负责管理文件系统和命名空间,存放了HDFS的元数据;
-
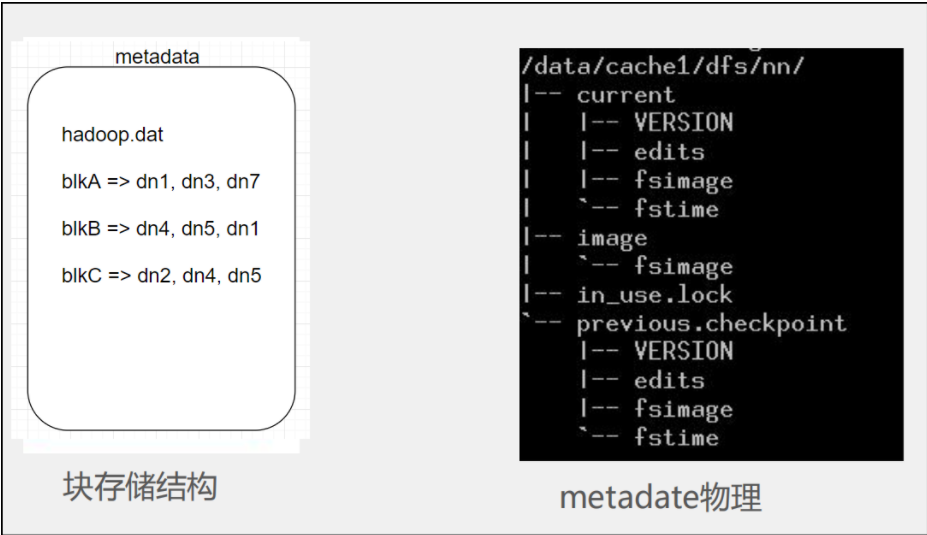
元数据:文件系统树、所有的文件和目录、每个文件的块列表、块所在的datanode等;
-
文件、block、目录占用大概150Byte字节的元数据;所以HDFS适合存储大文件,不适合存储小文件;
-
元数据信息以命名空间镜像文件fsimage和编辑日志(edits log)的方式保存。
fsimage(内存中):元数据镜像文件 ,保存了文件系统目录树信息以及文件和块的对应关系;
edits log:日志文件 ,保存文件系统的更改记录。
注意:fsimage保存在内存中,editslog最终会持久化到磁盘中。
3.2 DataNode
-
存储block,以及block元数据包括数据块的长度、块数据的校验和、时间戳
3.3 SeconddaryNameNode
-
为什么元数据存储在NameNode在内存中?
答:内存读取速度快。
-
这样做有什么问题?
答:1)如果namenode宕机,数据就会丢失。因为只有一个主节点。
2)namenode重启时,需要将FsImage加载到内存中,再逐条执行EditLog中记录,使得FsImage保持最新。如果EditLog很大,重启过程会很慢,namenode就长期处于"安全模式",无法提供写操作。
-
怎么解决?
secondaryNameNode作用:
(1)作为checkpoint,备份元数据信息(edits log和fsimage);
(2)完成合并FsImage和editLog,减少editLog大小,提升namenode从故障中恢复的速度。
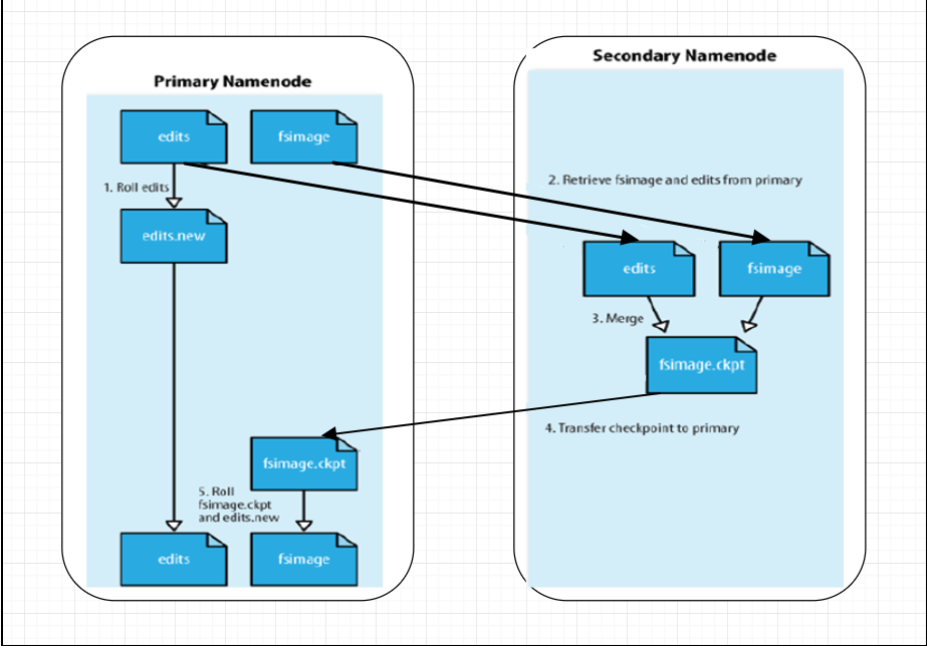
1)客户端client在向hdfs写数据时,会生成元数据、以及操作日志信息,并将它们写入内存中。当内存写满后,会将内存中的信息写到磁盘中。即:写到edits log日志文件里。
注意:双缓存异步写的策略:这里是2块内存,当其中一个内存1写满后会阻止再向内存1写日志;此时,内存2会接收写日志信息。2个内存轮流切换,保证持续的写操作。
合并流程:
1)当t1(当前时间)-t(集群启动时间)>1小时,这时候就触发checkpoint(检查点:对重要的内容做备份)的动作;
2)此时,secondaryNameNode会通过HttpGet方式把fsimage和edits拉到内存中,合并成fsimage.ckpt,再传回到NameNode,重命名回fsimage 。
3)在checkpoint的过程中,client还在向edits写日志,会滚动生成一个edits new的文件,最终会重命名为edits。
触发checkpoint情况(任意一种):1.一百万个事务(edits log中);2. t1-t >1 hour
注意:(2)(3)是并行执行;从合并角度看,是secondaryNamenode为NameNode设置了一个检查点。
secondaryNameNode故障恢复流程:(不优雅)
方式一:当namenode挂掉重启时,如何恢复元数据?先将fsimage(磁盘镜像文件)拉取到内存中;再将edits log文件重新执行一遍,才能真正恢复元数据信息。
引入secondaryNameNode好处:故障恢复变快原因,由于日志通过snn进行了合并,减小了edits log文件;使得恢复元数据过程,不需要花费大量时间来执行edits log文件内容;如果nn宕机又无法重启,此时snn可以充当nn主节点的角色。
方式二:snn如何充当nn角色:1)执行hdfs namenode-importCheckpoint 将fsimage.ckpt拉取到内存中(2)执行hadoop-daemon.sh start namenode命令进行角色转换。
这2种方式,都有短暂的服务中断,都有可能造成数据的丢失。
它一般部署在另外一台节点上,因为它需要占用大量的CPU时间,并需要与namenode一样多的内存,来执行合并操作。
4. HDFS机制
4.1 心跳机制
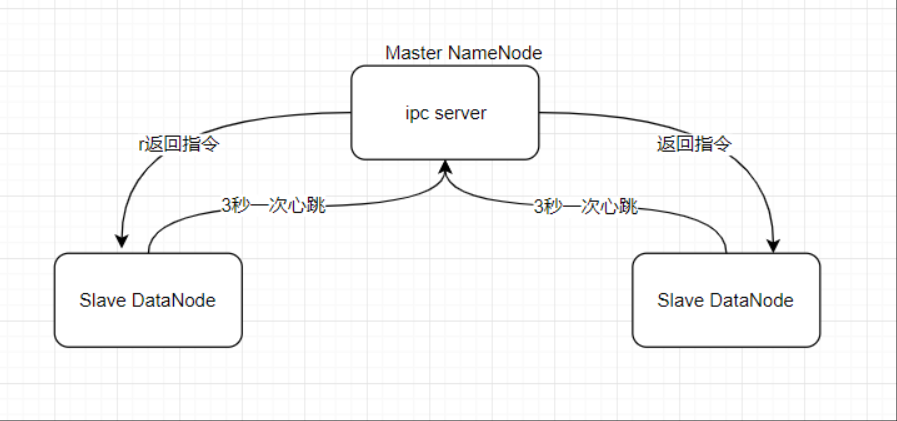
工作原理:
-
master启动的时候,会开一个ipc server在那里。
-
slave启动,连接master,每隔3秒钟向master发送一个“心跳”,携带状态信息;如果超过10分钟还未向master发送心跳,master会认为该slave DatatNoe不可用。
-
master通过这个心跳的返回值,向slave节点传达指令
作用:
-
Namenode全权管理数据块的复制,它周期性地从集群中的每个Datanode接收心跳信号和块状态报告(Blockreport)。接收到心跳信号意味着该Datanode节点工作正常。块状态报告包含了一个该 Datanode上所有数据块的列表
-
DataNode启动后向NameNode注册,通过后,周期性(1小时)的向 NameNode上报所有的块的列表;
每3秒向NamNode发一次心跳,返回NameNode给该DataNode的命令(如复制块数据到另一台机器,或删除某个数据块)。如果NameNode超过10分钟没有收 到某个DataNode 的心跳,则认为该节点不可用。
-
hadoop集群刚开始启动时,会进入安全模式(99.9%),就用到了心跳机制
num/total <99.9%,total:hdfs元数据中block个数,是指唯一block个数,不考虑副本的情况;num:每个dataNode向NN上报的block report list中唯一block个数,不考虑副本(副本被统计过的就不会再统计)。
如何均衡?$HADOOP_HOME/sbin/start-balancer.sh -t 5%
5.
-
NameNode存储着文件系统的元数据,每个文件、目录、块大概有150字节的元数据;
-
因此文件数量的限制也由NN内存大小决定,如果小文件过多则会造成NN的压力过大,也使得集群实际存储的数量受到限制,浪费磁盘资源。
-
HAR文件方案(本质启动mr程序,所以需要启动yarn)-即可以使用shell命令,合并小文件
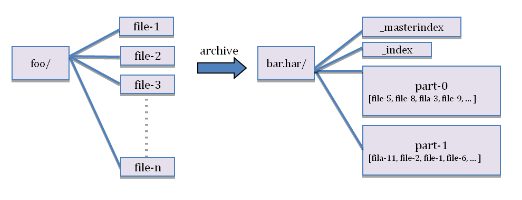
# 创建archive文件
hadoop archive -archiveName test.har -p /testhar -r 3 th1 th2 /outhar # 原文件还存在,需手动删除
# 查看archive文件
hdfs dfs -ls -R har:///outhar/test.har
# 解压archive文件
hdfs dfs -cp har:///outhar/test.har/th1 hdfs:/unarchivef
hadoop fs -ls /unarchivef # 顺序
hadoop distcp har:///outhar/test.har/th1 hdfs:/unarchivef2 # 并行,启动MR
-
Sequence Files方案
将这些文件放到一个SequenceFile文件,然后就以数据流的方式处理这些文件,也可以使用MapReduce进行处理。一个SequenceFile是可分割的,所以MapReduce可将文件切分成块,每一块独立操作。不像HAR,SequenceFile支持压缩。在大多数情况下,以block为单位进行压缩是最好的选择,因为一个block包含多条记录,压缩作用在block之上,比reduce压缩方式(一条一条记录进行压缩)的压缩比高。把已有的数据转存为SequenceFile比较慢。比起先写小文件,再将小文件写入SequenceFile,一个更好的选择是直接将数据写入一个SequenceFile文件,省去小文件作为中间媒介。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号