自己意淫的一个简陋的Python网站扫描器
使用的模块 threading、optparse、urllib2
本地需要放字典,名字需大写。
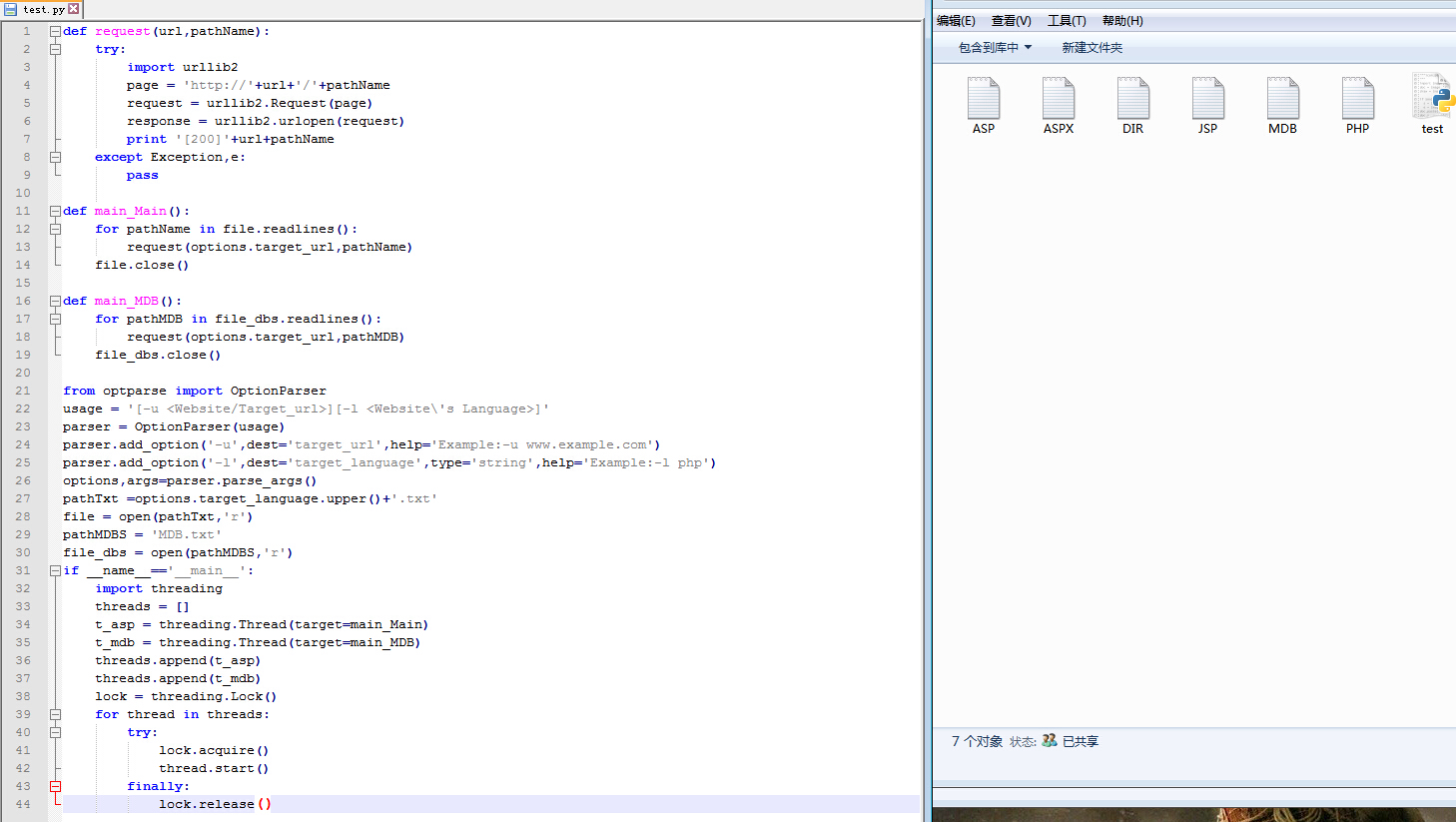
上代码
1 def request(url,pathName): 2 try: 3 import urllib2 4 page = 'http://'+url+'/'+pathName 5 request = urllib2.Request(page) 6 response = urllib2.urlopen(request) 7 print '[200]'+url+pathName 8 except Exception,e: 9 pass 10 11 def main_Main(): 12 for pathName in file.readlines(): 13 request(options.target_url,pathName) 14 file.close() 15 16 def main_MDB(): 17 for pathMDB in file_dbs.readlines(): 18 request(options.target_url,pathMDB) 19 file_dbs.close() 20 21 from optparse import OptionParser 22 usage = '[-u <Website/Target_url>][-l <Website\'s Language>]' 23 parser = OptionParser(usage) 24 parser.add_option('-u',dest='target_url',help='Example:-u www.example.com') 25 parser.add_option('-l',dest='target_language',type='string',help='Example:-l php') 26 options,args=parser.parse_args() 27 pathTxt =options.target_language.upper()+'.txt' 28 file = open(pathTxt,'r') 29 pathMDBS = 'MDB.txt' 30 file_dbs = open(pathMDBS,'r') 31 if __name__=='__main__': 32 import threading 33 threads = [] 34 t_asp = threading.Thread(target=main_Main) 35 t_mdb = threading.Thread(target=main_MDB) 36 threads.append(t_asp) 37 threads.append(t_mdb) 38 lock = threading.Lock() 39 for thread in threads: 40 try: 41 lock.acquire() 42 thread.start() 43 finally: 44 lock.release()
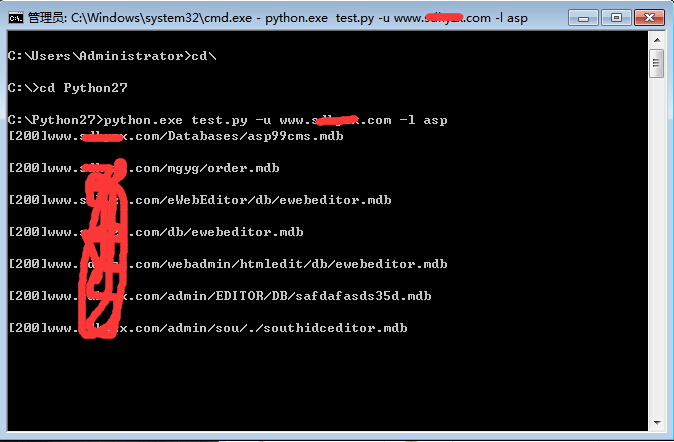
参数 -u url -l 网页语言

 浙公网安备 33010602011771号
浙公网安备 33010602011771号