20230210 组会学习
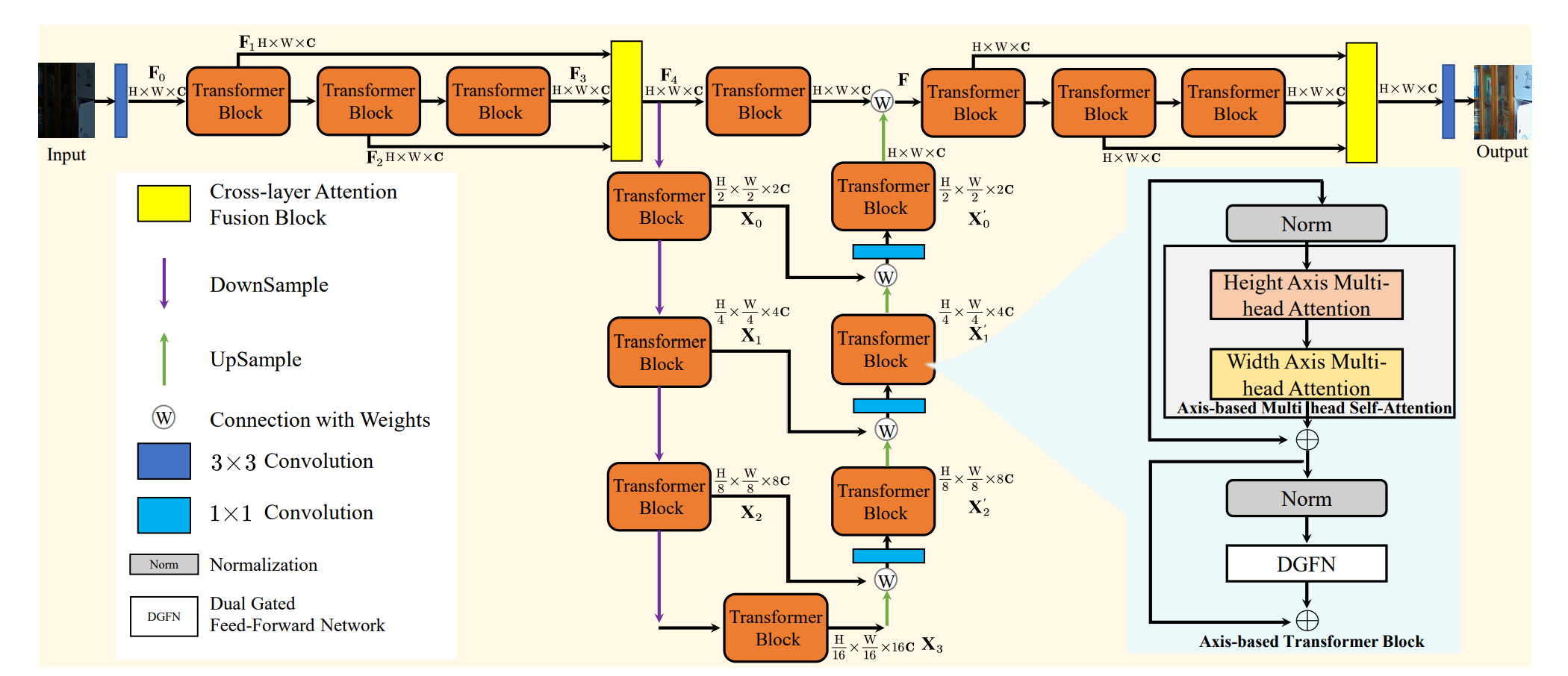
LLFormer
该方法主要是基于 Restormer 的改进,主要改进有以下三点
- 注意力机制改为了轴向注意力,降低了计算复杂度
- FFN 部分由原来的单门控改成了双门控机制,增加了交互
- 加入了 LayerAttention 模块,建立了不同层之间的交互关系
![总体结构]()
![]()
![]()


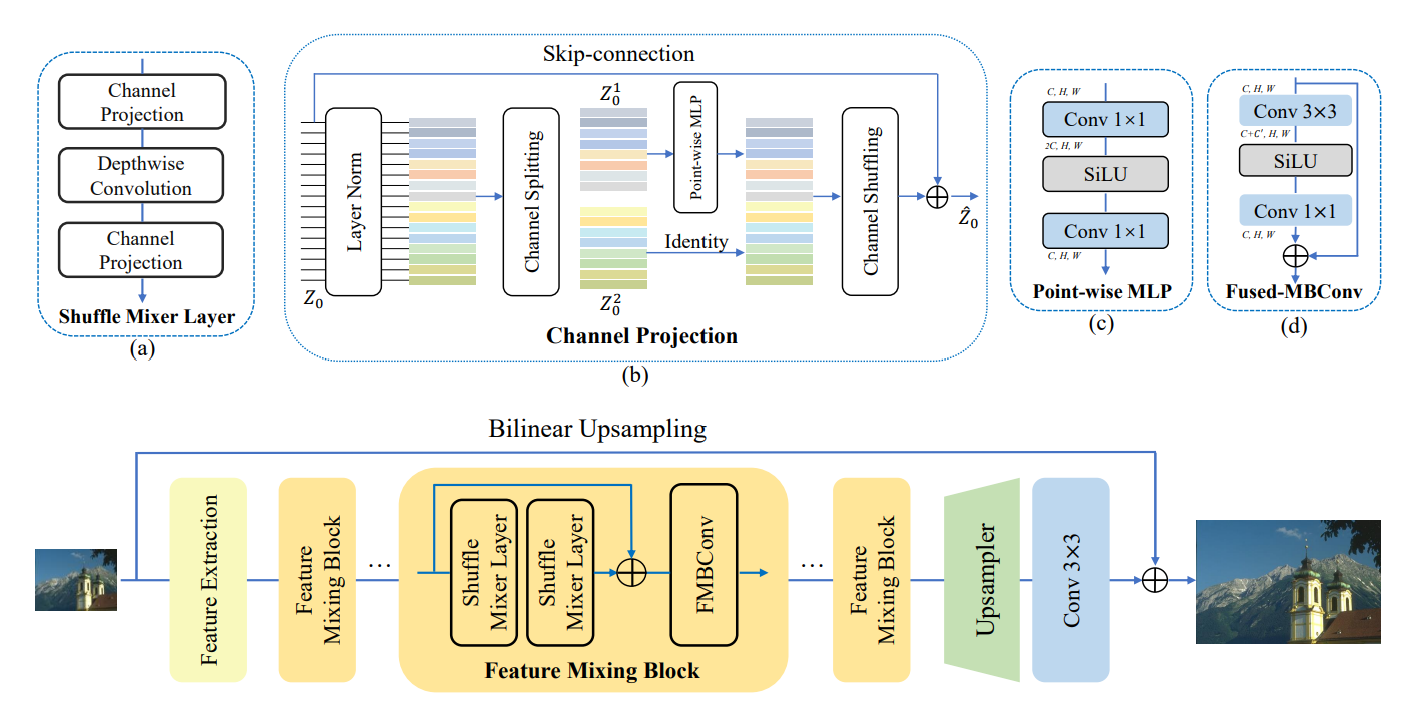
Shuffle-Mixer
作者通过 Feature Mixing Block 获取图像的局部和非局部信息
- Shuffle Mixer Layers 采用大核 DW 卷积获取非局部信息,并使用 CSS 策略降低计算复杂度
- 使用 FMBConv 获取局部信息
![]()
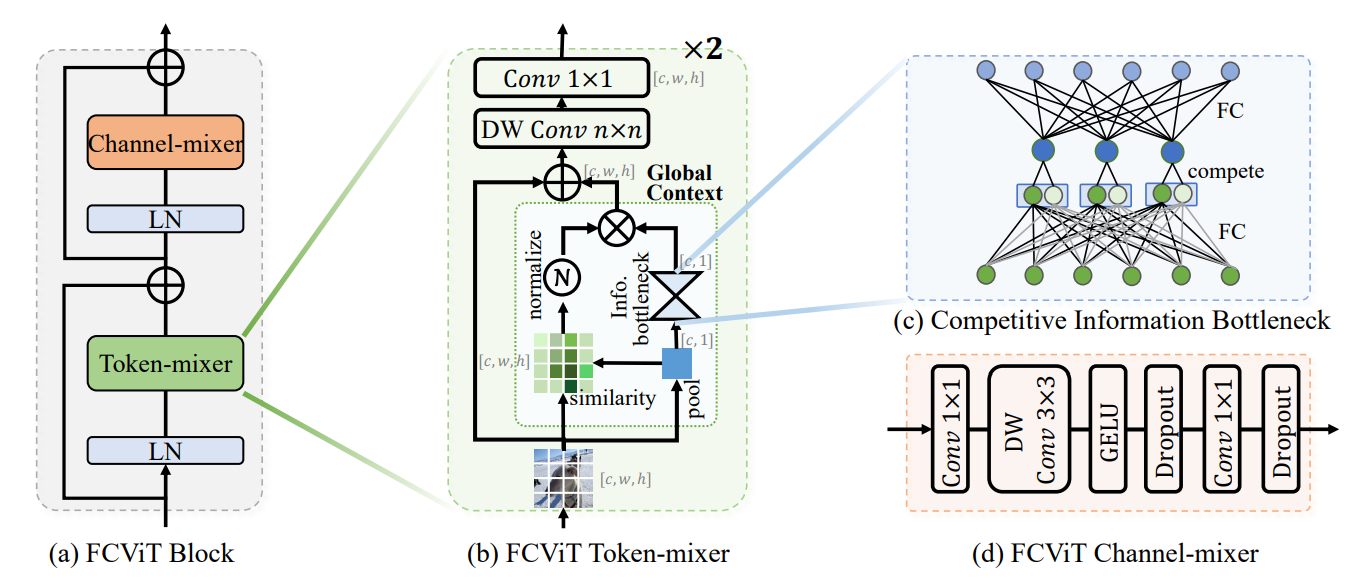
FCVit
作者观察到 Attention Maps 与 query 不相关,并且比较稀疏,从而提出将卷积和注意力结合的思想
- 计算 attention 时,去掉 query
- 将注意力加入到卷积计算中,增加全局依赖信息
- 加入了 Bottleneck 结构,通过竞争增加信息
![]()
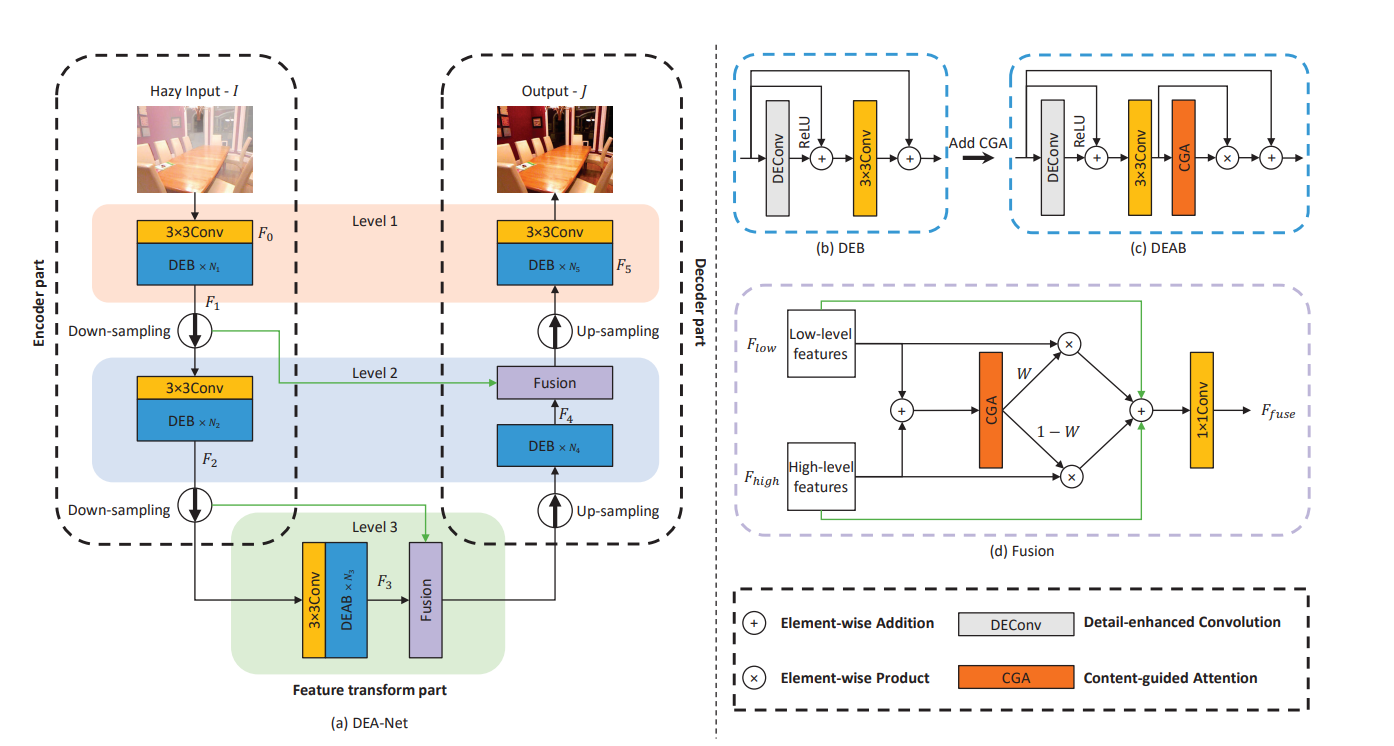
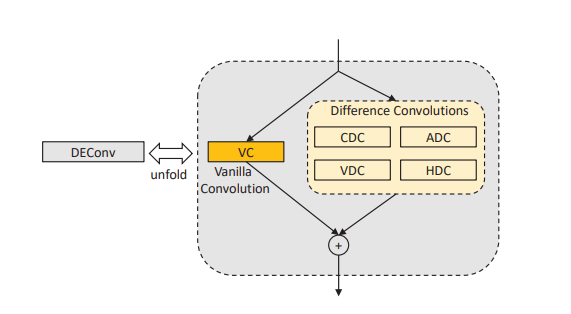
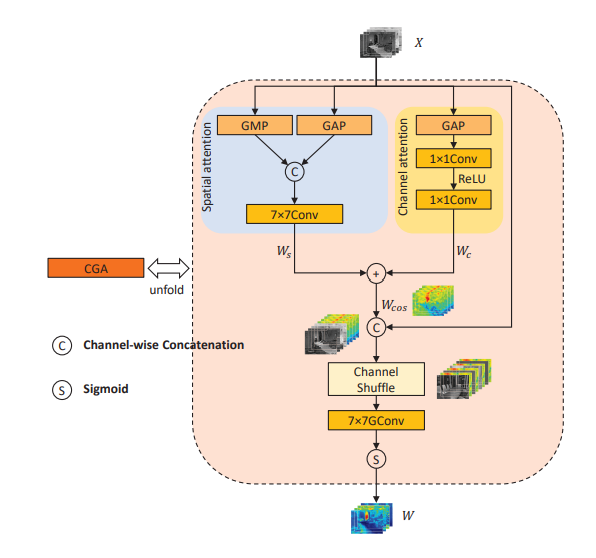
DEA-Net
作者认为现有的 CNN 方法重点在于加大深度和宽度,没有充分利用先验知识,并且对待雾的不均匀性,采用不平等的方法。于是作者提出了以下两点方案
- DEConv:利用差分卷积,提取边缘特征
- 通过 CGA 为每个通道获得一个 SIM,并且充分混合通道注意力和空间注意力,保证信息交互。
![]()
![]()
![]()
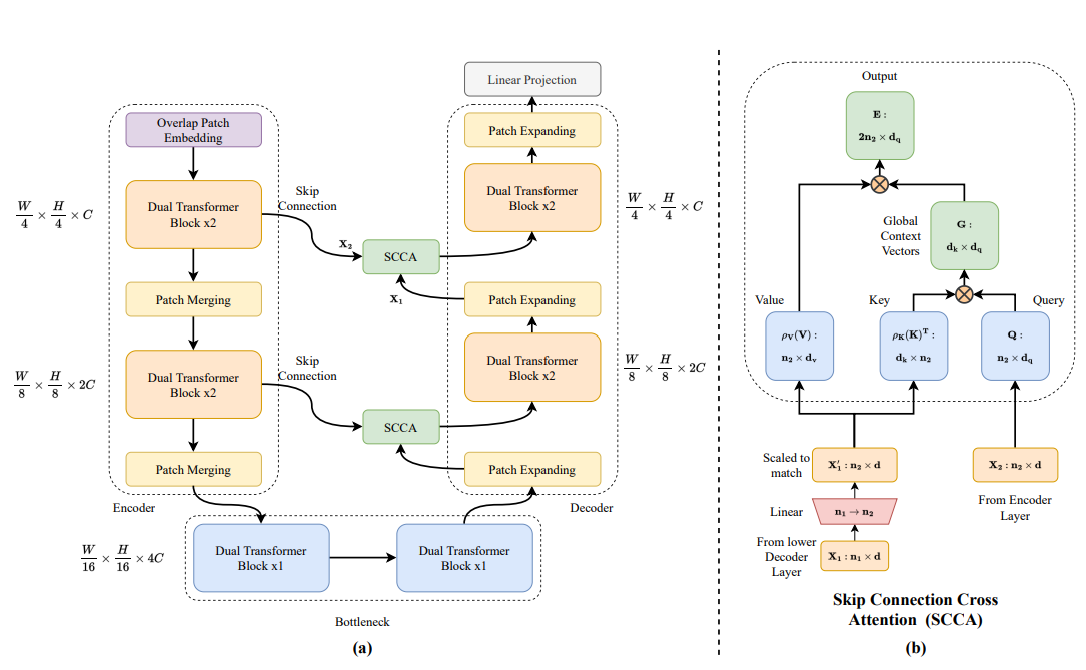
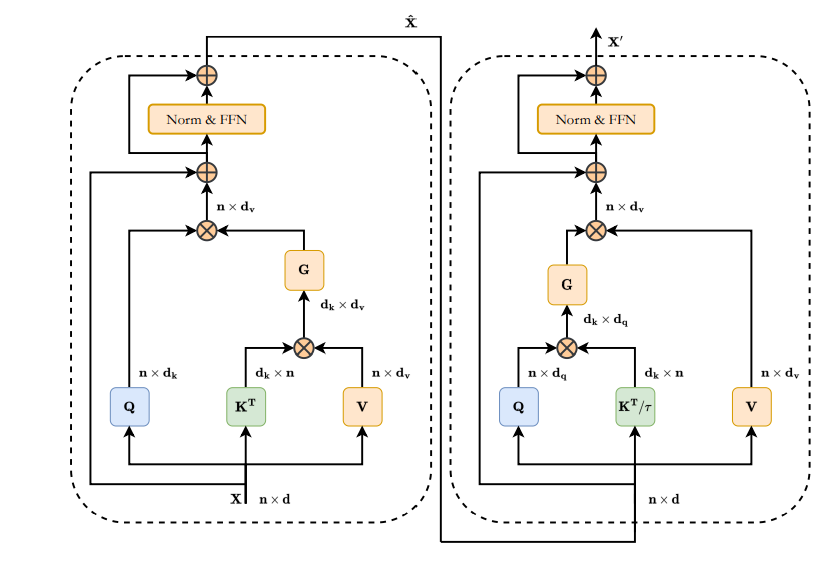
DAE-Former
改进的 U-Net 结构,降低了计算量
- Dual Transformer Block 分别计算空间和通道上的注意力
- 采用 SCCA 进行交互
![]()
![]()
总结
本次组会大多数内容是对 Transformer 结构的改进。主要有两个部分,一是对 Attention 的改进,二是对 FFN 的改进。
- 注意力部分的改进,大多数在于降低计算量和增加通道的信息。其中计算量对于高光谱的多模态融合方向很难考虑,增加通道的交互应该是借鉴的重点。
- FFN 部分的改进大多比较容易直接应用,也可以借鉴到融合的交互中。
论文中也有许多 CNN 和 注意力结合的工作,该部分的借鉴意义比较大。个人认为,CNN 的效果在高光谱的多模态融合方向要比注意力更具有优势,但由于缺乏全局的信息,可以考虑将注意力融入 CNN 的尝试。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号