
第六周学习
Selective Kernel Networks
本文受生物学中“视皮层神经元的感受野大小受刺激的调节”的启发,提出了一种在CNN中对卷积核的动态选择机制,设计了一个称为选择性内核单元(SK)的构建块。其中,多个具有不同内核大小的分支在这些分支中的信息引导下,使用SoftMax进行融合。由多个SK单元组成SKNet,SKNet中的神经元能够捕获不同尺度的目标物体。

SK块主要包括三个部分:Split, Fuse,Select
-
Split
如图中所示,该操作主要是通过多个不同尺寸的卷积核输入进行卷积,图中采用的是大小分别为 \(3 \times 3\) 和 \(5 \times 5\) 的两个卷积核。为了提高效率,\(5 \times 5\) 的卷积核被替换为采用 \(3 \times 3\) 卷积核的空洞卷积。
-
Fuse
融合部分首先是将上一步的操作进行相加,即 \(\mathbf{U}=\widetilde{\mathbf{U}}+\widehat{\mathbf{U}}\),然后再通过一个全局平均值池化操作,即
\(s_{c}=\mathcal{F}_{g p}\left(\mathbf{U}_{c}\right)=\frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W} \mathbf{U}_{c}(i, j)\),最后通过一个全连接和激活函数,进行降维,即 \(\mathbf{z}=\mathcal{F}_{f c}(\mathbf{s})=\delta(\mathcal{B}(\mathbf{W} \mathbf{s}))\)。
-
Select
该操作按照信道的方向使用softmax,即
\[a_{c}=\frac{e^{\mathbf{A}_{c} \mathbf{z}}}{e^{\mathbf{A}_{c} \mathbf{z}}+e^{\mathbf{B}_{c} \mathbf{z}}}, b_{c}=\frac{e^{\mathbf{B}_{c} \mathbf{z}}}{e^{\mathbf{A}_{c} \mathbf{z}}+e^{\mathbf{B}_{c} \mathbf{z}}} \]然后与Split卷积后的特征进行乘和求和操作,即
\[\mathbf{V}_{c}=a_{c} \cdot \widetilde{\mathbf{U}}_{c}+b_{c} \cdot \widehat{\mathbf{U}}_{c}, \quad a_{c}+b_{c}=1 \]
Strip Pooling: Rethinking Spatial Pooling for Scene Parsing
本文主要提出了一种条带池化的方式,使得网络可以更加高效获取网络大范围感受野下的信息,从未提升网络的性能
-
Strip Pooling Module
![]()
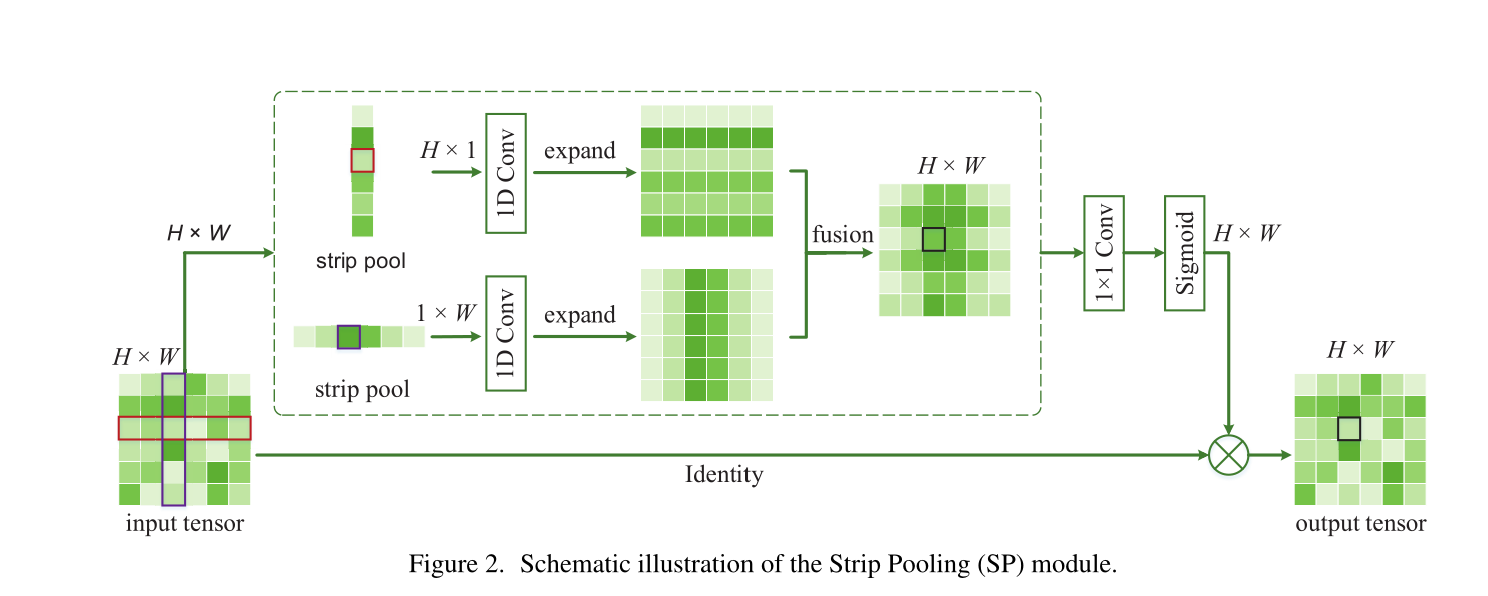
相比于传统的池化操作,作者采用了kernel大小分别为 \(1 \times H\) 和 \(W \times 1\) 的方式进行池化操作,公式表示为
在得到上面的池化结果之后会将得到的特征使用一个1维的卷积进行调和,之后就是在各自的方向上进行扩展,使其与先前的特征图大小一致,再将两个特征图进行融合:
之后,经过sigmoid激活与原特征图进行点乘得到最后的结果。整个流程如上图所示。
-
Mixed Pooling Module
在实际中Pyramid pooling module(PPM)被证明在分割场景是一种高效的性能增强方式,但是原始的PPM是依赖于方格形状的池化kernel的,这样的kernel在上面也论述了其存在的问题,因而文章在PPM的基础上对其进行改进,改进的机理就是使用strip pooling去替换方形的池化kernel。
![]()
- 对于长依赖,作者采用strip pooling操作去替换原有的global average pooling操作
- 对于短依赖,作者采用轻量化的PPM模块进行设计,解决局部依赖问题

HRNet:Deep High-Resolution Representation Learning for Human Pose Estimation
本文作者提出了 HRNet 主干网络来做人体关键点检测,让网络一直保持了高分辨率 representation,有利于更精确的关键点定位。

与传统的网络分辨率会随深度下降不同,HRNet 采用了一种并行的方式,作为主干网络,这使得网络一直保持了高分辨率 representation。
文中以第三个阶段为例,给出了具体的过程,如下图所示:
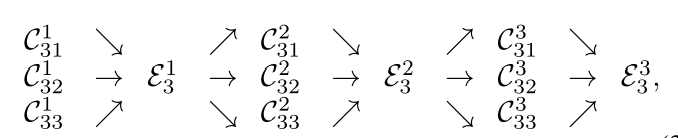

用公式表示为:
输入:\(\left\{\mathbf{X}_{1}, \mathbf{X}_{2}, \ldots, \mathbf{X}_{s}\right\}\),输出:\(\left\{\mathbf{Y}_{1}, \mathbf{Y}_{2}, \ldots, \mathbf{Y}_{s}\right\}\), 其中 \(\mathbf{Y}_{k}=\sum_{i=1}^{s} a\left(\mathbf{X}_{i}, k\right)\),
\(a\left(\mathbf{X}_{i}, k\right)\) 表示表示把输入 \(X\) 的分辨率 \(i\) 变为 \(k\)(通过上采样或者下采样)
交换 unit 操作后,最后会多生成出一个 parallel subnet,
分辨率倍率加一,小了一个 level。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号