《Learning Structured Representation for Text Classification via Reinforcement Learning》论文翻译.md
摘要
- 表征学习是自然语言处理中的一个基本问题。本文研究了如何学习文本分类的结构化表示。与大多数既不使用结构又依赖于预先指定结构的现有表示模型不同,我们提出了一种强化学习(RL)方法,通过自动覆盖优化结构来学习句子表示。我们演示了构建结构化表示的两种尝试:信息提取 LSTM(ID-LSTM)和层次结构LSTM(HS-LSTM)。id-lstm只选择与任务相关的重要单词,hs-lstm发现句子中的短语结构。两个表示模型中的结构发现被表述为一个连续的决策问题:结构发现的当前决策影响后续决策,可以通过策略梯度RL来解决。研究结果表明,该方法可以通过识别重要词汇,或与任务相关的结构,来学习任务友好型表示,而无需明确的结构注释,从而获得具有竞争力的性能。
简介
-
表征学习是人工智能中的一个基本问题,对自然语言处理尤为重要,文本分类作为NLP最常见的任务之一,在很大程度上依赖于所学的表示特征,在情感分析、问题分类、语言推理中得到了广泛的应用。文本分类的主流表示模型大致可以分为四种类型。词袋模型忽略了单词的顺序,包括深度平均网络和自动编码器;序列表示模型,如卷积神经网络和递归神经网络,考虑单词顺序,但没有使用任何结构;结构化表示模型,如树结构LSTM和递归自动编码器,使用预先指定的解析树构建结构化表示;基于注意力的方法模型,运用注意机制,通过对输入词或句子进行差异评分来构建表达。
-
然而,在现有的结构化表示模型中,结构要么作为输入提供,要么使用有监督的显式树库注释进行预测。对于具有自动优化结构的学习表示的研究很少。Yogatama等人建议构建二叉树结构,只对下游任务进行监督,但这种结构非常复杂,过于深入,导致分类性能不理想。在一个层次表示模型中,提出了捕捉潜在变量序列中潜在结构的方法。结构以一种潜在的、隐含的方式被发现。
-
在本文中,我们提出了一种强化学习(RL)方法,通过识别与任务相关的结构来构建结构化的句子表达,而不需要明确的结构注释。本文将结构发现表述为一个顺序决策问题:结构发现的当前决策(或行动)影响后续决策,这可以通过策略梯度法(Sutton等人2000)。延迟奖励用于指导结构发现策略的学习。奖励是根据文本分类器基于结构化表示的预测来计算的。只有在完成所有顺序决策后,表示才可用。
-
在我们的RL方法中,我们设计了两个结构化的表达模型:信息提炼的LSTM(ID-LSTM),它选择重要的、与任务相关的词来构建句子表达;以及层次结构的LSTM(HS-LSTM),发现短语结构并用两层LSTM构建句子表达。表示模型与策略网络和分类网络无缝集成。策略网络定义了结构发现策略,分类网络在结构化句子表示的基础上进行预测,方便了策略网络的奖励计算。
- 针对文本分类问题,提出了一种发现任务相关结构的强化学习方法来构建结构化的句子表示。提出了两种结构化的表示模型:信息蒸馏LSTM(ID-LSTM)和层次结构LSTM(HS-LSTM)。
- 即使没有明确的结构注释,我们的方法也能有效地识别与任务相关的结构。此外,性能比使用预先指定的解析结构的强基线更好或更具可比性。
方法论
- 本文的目标是通过发现重要的、与任务相关的结构来学习文本分类的结构化表示。我们认为,文本分类可以通过优化的、结构化的表示来改进。
- 整个过程如图1所示。该模型由三个部分组成:策略网络(PNET)、结构化表示模型和分类网络(CNET)。PNET采用随机策略,对每个状态下的动作进行采样。它保持采样直到句子结束,并为句子生成操作序列。然后,结构化表示模型将动作转换为结构化表示。我们设计了两个表示模型:信息蒸馏LSTM(ID-LSTM)和层次结构LSTM(HS-LSTM)。CNET根据结构化表示进行分类,并为PNET提供奖励计算。由于奖励可以在最终表示可用时计算(完全由动作序列确定),因此可以通过策略梯度方法自然解决该过程(Sutton等人2000)。
![]()
- 显然,这三个部分交织在一起。PNET的状态表示是从表示模型中推导出来的,CNET依赖于从表示模型中获得的最终结构化表示来进行预测,PNET从CNET的预测中获得回报来指导策略的学习。
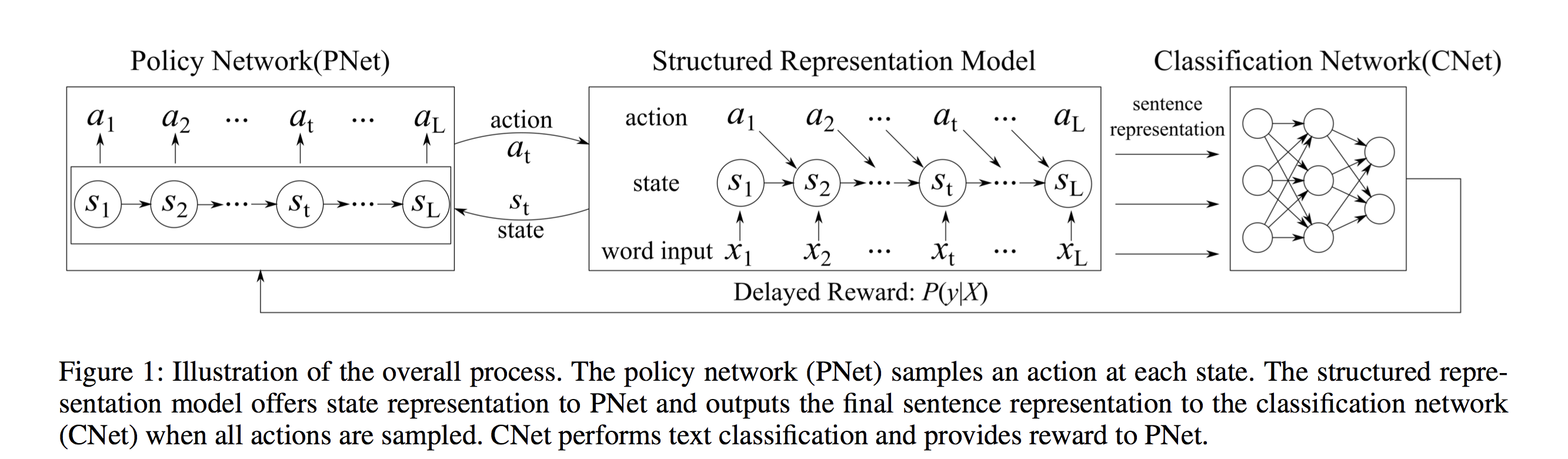
Policy Network (PNet) 策略网络
- 策略网络采用随机策略π(at|st;Θ) ,并使用延迟奖励来指导策略学习。它用从表示模型中获得表示的每个状态的概率对一个动作进行采样。为了获得基于CNET预测的延迟奖励,我们对整个句子进行了动作抽样。一旦确定了所有动作,表示模型将获得句子的结构化表示,并由cnet用来计算P(y|X)。用、P(y|X)计算的奖励用于策略学习。
- 我们简要介绍状态、动作、策略、奖励、目标函数:
-
State 状态对当前输入和以前的上下文进行编码,并且在两个表示模型中有不同的定义。下文将介绍状态st的详细定义。
-
Action and Policy 我们在两个设置中采用二进制操作,但含义不同。在id-lstm中,动作空间是{retain, delete},其中一个单词可以从最后一个句子表示中删除或保留。在hs-lstm中,动作空间是{inside, end},表示一个单词在短语内部或末尾。显然,每个动作都是两个表示模型中结构选择的直接指示器。
- 我们采用随机策略。让 at 表示在状态t 时的动作,策略定义如下:
![]()
- π(at|st; Θ) 表示选择动作at的概率, σ表示sigmoid函数,Θ = {W, b} 表示 PNet 的参数
- 在训练过程中,根据上述等式中的概率对动作进行抽样。在试验过程中,将选择最大概率的动作,以获得更好的预测。
![]()
- 我们采用随机策略。让 at 表示在状态t 时的动作,策略定义如下:
-
Reward 一旦策略网络对所有动作进行了抽样,句子的结构化表示将由我们的表示模型来确定,并且表示将传递给CN
et以获得P(y|X),其中y是类标签。奖励将根据预测分布(P(y|X))计算,并考虑结构选择的趋势,稍后将详细说明。这是一个典型的延迟奖励,因为在构建最终表示之前,我们无法获得它。 -
Objective Function 我们使用强化算法(Williams 1992)和策略梯度法(Sutton 2000)优化PNet的参数,旨在最大化预期reward,如下所示。
![]()
-
奖励仅在一个样本上计算,X = x1x2 ···xL. 因为步骤t+1的状态由前一步动作和状态t 决定,所以概率 p(s1) + p(st+1|st, at) =1
-
通过应用类似的技巧,使用以下梯度更新策略网络
![]()
-

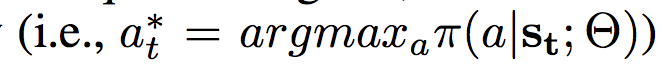
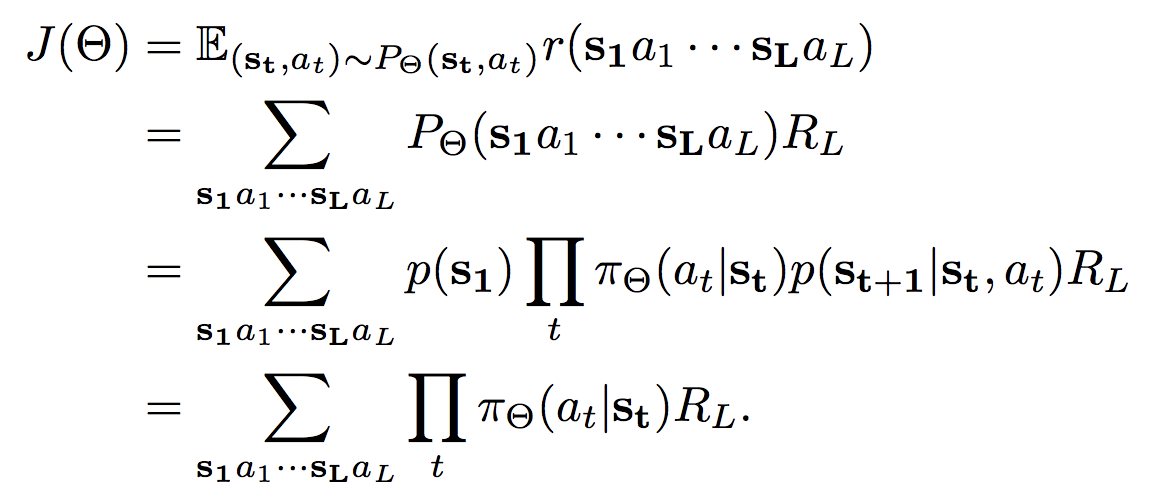
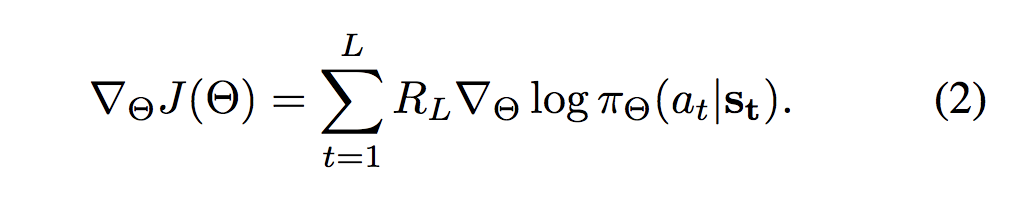
Structured Representation Models 结构化表示模型
Information Distilled LSTM (ID-LSTM) 信息蒸馏:
-
它的主要思想是通过提取句子中最重要的单词并删除不相关的单词来构建一个句子表示。这样,就可以了解更多与任务相关的分类表示。例如,在情感分类中,像“to”、“the”和“a”这样的词可能很少有助于完成任务。通过提取句子中最重要的单词,最终的表达可以被净化和浓缩,以便分类。
-
ID-LSTM将从PNET获得的动作转换为句子的结构化表示。形式上,给出一个句子X=x1x2····xl,从pnet得到相应的动作序列a=a1 a2···al。在该设置中,单词位置Xi中的每个动作
![]() 从{保留,删除}中选择,其中保留表示该单词被保留在句子中,并且删除意味着该单词被删除,并且它对最终句子表示没有贡献。
从{保留,删除}中选择,其中保留表示该单词被保留在句子中,并且删除意味着该单词被删除,并且它对最终句子表示没有贡献。
![]()
其中,Φ表示序列lstm的函数(包括所有门函数和更新函数),ct表示存储单元,ht表示位置t处的隐藏状态。注意,如果删除一个单词,则当前位置的存储单元和隐藏状态将从前一位置复制。 -
State:策略网络的状态定义如下:
![]()
⊕表示向量连接 ,Xt 表示 当前的词输入,为了丰富状态表示,包含了存储状态Ct-1- 为了进行分类,将ID-LSTM的最后一个隐藏状态作为分类网络(CNET)的输入:
![]()
其中 ,![]() ,
,![]() 是CNet的参数, d 是隐藏状态的维数,
是CNet的参数, d 是隐藏状态的维数, ![]() 是类别标签, K 是类别数量。
是类别标签, K 是类别数量。
- 为了进行分类,将ID-LSTM的最后一个隐藏状态作为分类网络(CNET)的输入:
-
Reward: 为了计算delayed reward RL,我们使用CNet输出概率的对数,即
![]() ,其中 Cg 是输入X的黄金标签。另外,为了鼓励模型删除更多无用的单词,我们通过计算删除单词数量与句子长度的比例来包含一个附加限制:
,其中 Cg 是输入X的黄金标签。另外,为了鼓励模型删除更多无用的单词,我们通过计算删除单词数量与句子长度的比例来包含一个附加限制:
![]()
其中 L‘ 表示删除单词的数量(也就是说,相应的动作是delete),![]() 是平衡这两个项的超参数。
是平衡这两个项的超参数。
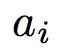 从{保留,删除}中选择,其中保留表示该单词被保留在句子中,并且删除意味着该单词被删除,并且它对最终句子表示没有贡献。
从{保留,删除}中选择,其中保留表示该单词被保留在句子中,并且删除意味着该单词被删除,并且它对最终句子表示没有贡献。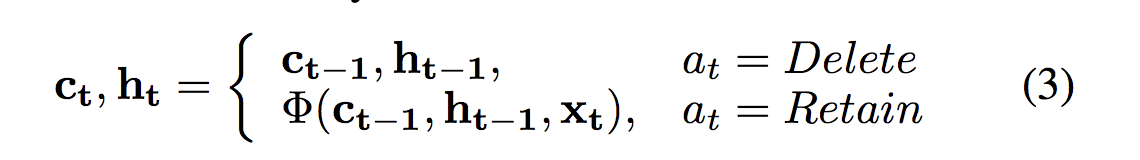
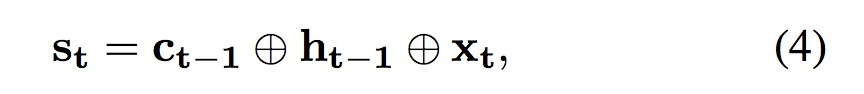
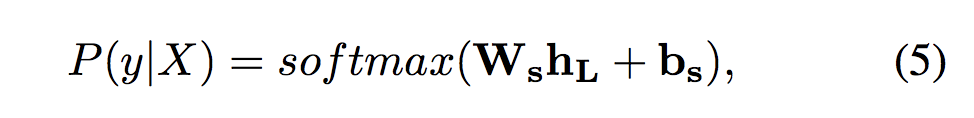
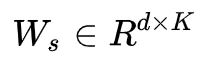 ,
,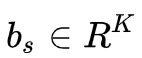 是CNet的参数, d 是隐藏状态的维数,
是CNet的参数, d 是隐藏状态的维数, 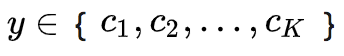 是类别标签, K 是类别数量。
是类别标签, K 是类别数量。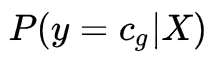 ,其中 Cg 是输入X的黄金标签。另外,为了鼓励模型删除更多无用的单词,我们通过计算删除单词数量与句子长度的比例来包含一个附加限制:
,其中 Cg 是输入X的黄金标签。另外,为了鼓励模型删除更多无用的单词,我们通过计算删除单词数量与句子长度的比例来包含一个附加限制: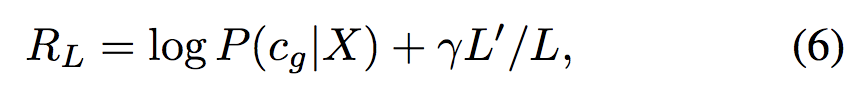
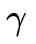 是平衡这两个项的超参数。
是平衡这两个项的超参数。Hierarchically Structured LSTM (HS-LSTM) 层次化结构模型
-
层次模型已广泛应用于文档级分类(Tang、Qin和Liu 2015;Ghosh等人2016)和语言建模(Chung、Ahn和Bengio,2017)。在这些研究的启发下,我们提出了一种层次结构的LSTM(hs-lstm),它可以通过在句子中发现层次结构来构建结构化的表示。我们认为,通过识别句子中的子结构可以获得更好的句子表示。这个过程是通过在每个单词位置的{inside,end}中抽样一个动作来实现的,其中inside表示单词在短语中,end表示短语的结尾。hs-lstm将动作转换为句子的层次结构表示。准确地说,本文中的词组应理解为子结构或段。
-
在hs-lstm中,有两个层次的结构:一个单词层次lstm连接一系列单词形成一个短语,另一个短语层次lstm连接短语形成句子表示。单词级lstm的转换取决于−1处的操作。如果−1处的操作是结束End,则位置t处的单词是短语的开始,单词级lstm从零初始化状态开始。如果动作是Inside,单词级别lstm将从以前的状态继续。过程的形式描述如下:
![]()
其中![]() 表示字级LSTM的转换函数,
表示字级LSTM的转换函数,![]() 是存储器单元,并且
是存储器单元,并且 ![]() 是位置t处的隐藏状态。
是位置t处的隐藏状态。 -
Phrase-LSTM的转换取决于在当前位置的动作,这表明短语是否完全构造(见方程8)。当处于End时,一个短语在位置t结束,并且word-LSTM的隐藏状态将被传输到phrase-LSTM中。如果动作是Inside,则表示phrase-LSTM从前面的位置复制变量。用公式表示为:
![]()
其中![]() 表示phrase-LSTM的转换函数。请注意,phrase-LSTM的输入是
表示phrase-LSTM的转换函数。请注意,phrase-LSTM的输入是![]() ,即word-LSTM的隐藏状态。
,即word-LSTM的隐藏状态。 -
HS-LSTM的行为依赖于
![]() 和
和 ![]() 两种动作。可以清楚地看出,
两种动作。可以清楚地看出,![]() 和
和![]() 之间的动作组合表示单词
之间的动作组合表示单词![]() 在短语中的位置。
在短语中的位置。
![]()
-
State: 策略网络的状态定义如下:
![]()
其中![]() 表示向量级联。 状态表示由word-level和phrase-level表示组成。
表示向量级联。 状态表示由word-level和phrase-level表示组成。- 为了进行分类,phrase-LSTM(
![]() )的最后隐藏状态被作为分类网络(CNet)的输入:
)的最后隐藏状态被作为分类网络(CNet)的输入:
![]()
- 为了进行分类,phrase-LSTM(
-
Reward: 不同于ID-LSTM的reward,ID-LSTM尽可能多地删除单词,但是HS-LSTM的reward要求一个好的短语结构不应包含太多或太少的短语,phrase长度应该控制在3-4个之间最理想。因此使用了一个短语数量的单峰函数来反映结构选择的趋势。我们使用函数 f(x) = x+0.1/x ,这是一个最小值为
![]() 的单峰函数。正式表示为:
的单峰函数。正式表示为:
![]()
其中 L' 表示短语的数量(动作结束的次数)。![]() 是一个超参数。其中L=10有大约3~4个短语,这与我们的观察结果一致。
是一个超参数。其中L=10有大约3~4个短语,这与我们的观察结果一致。
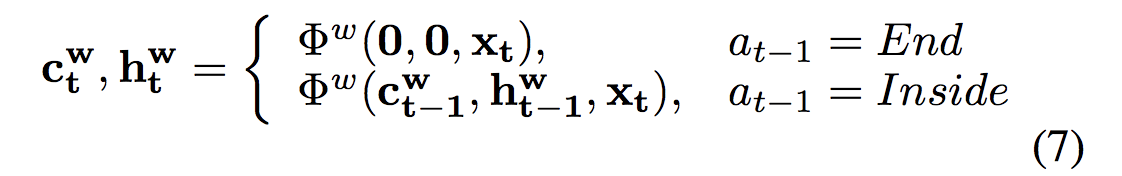
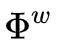 表示字级LSTM的转换函数,
表示字级LSTM的转换函数,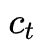 是存储器单元,并且
是存储器单元,并且 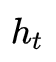 是位置t处的隐藏状态。
是位置t处的隐藏状态。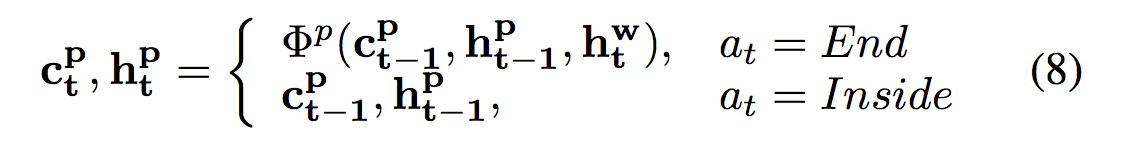
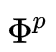 表示phrase-LSTM的转换函数。请注意,phrase-LSTM的输入是
表示phrase-LSTM的转换函数。请注意,phrase-LSTM的输入是 ,即word-LSTM的隐藏状态。
,即word-LSTM的隐藏状态。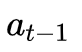 和
和 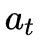 两种动作。可以清楚地看出,
两种动作。可以清楚地看出,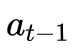 和
和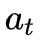 之间的动作组合表示单词
之间的动作组合表示单词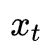 在短语中的位置。
在短语中的位置。
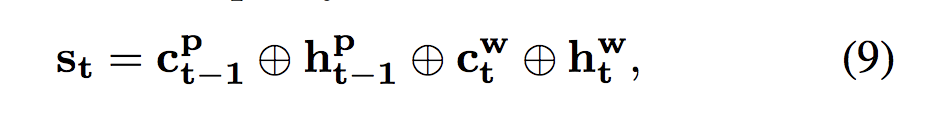
 表示向量级联。 状态表示由word-level和phrase-level表示组成。
表示向量级联。 状态表示由word-level和phrase-level表示组成。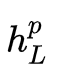 )的最后隐藏状态被作为分类网络(CNet)的输入:
)的最后隐藏状态被作为分类网络(CNet)的输入: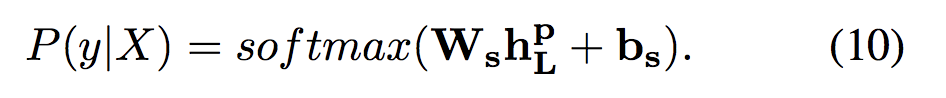
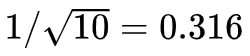 的单峰函数。正式表示为:
的单峰函数。正式表示为: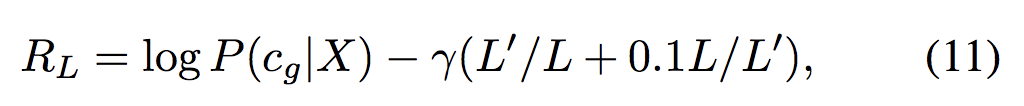
 是一个超参数。其中L=10有大约3~4个短语,这与我们的观察结果一致。
是一个超参数。其中L=10有大约3~4个短语,这与我们的观察结果一致。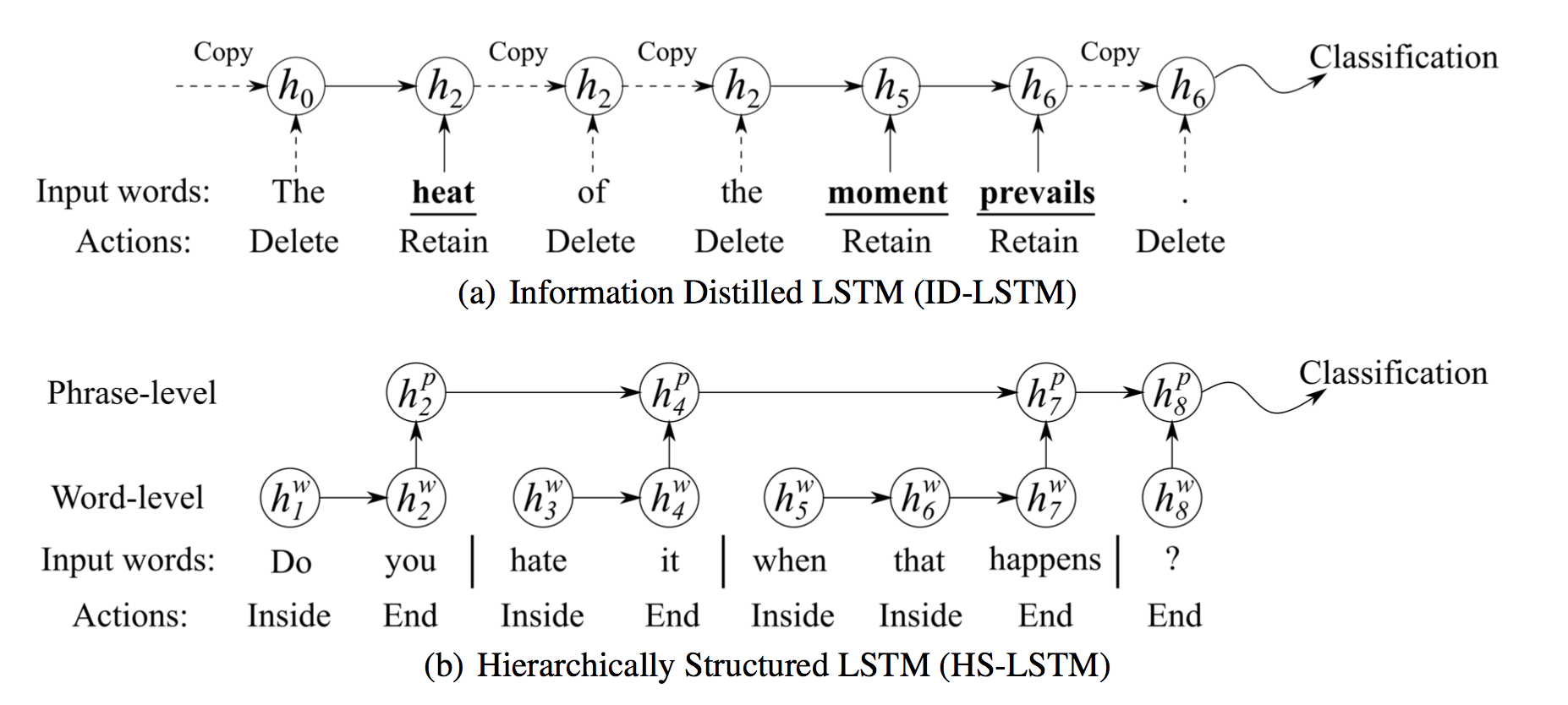
Classification Network
- 分类网络根据从ID-LSTM或HS-LSTM获得的结构化表示在类标签上产生概率分布。cnet由Ws和Bs参数化,分别如等式5和等式10所示,此处不再重复。
- 为了训练CNet,我们采用交叉熵作为损失函数:
![]()
pˆ(y, X)表示 样例X的黄金热分布, P(y|X)表示的像(5)、(10)公式定义的预测分布
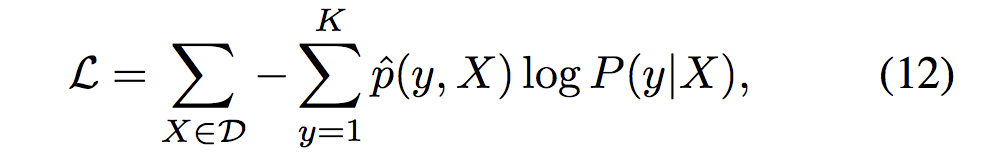
训练过程
- 由于PNET、表示模型和CNET是交织在一起的,所以需要联合训练。如算法所述。1、整个培训过程包括三个步骤。我们先对表示模型和CNET进行预训练,然后对PNET进行预训练,同时保持其他两个模型的参数不变。最后,我们共同训练了这三个部分。
![]()
- 由于从零开始训练RL非常困难,而且差异很大,因此我们对RL模块进行了一些预热启动结构的预训练。对于ID-LSTM,我们使用不删除任何内容的原始句子来执行预培训。对于hs-lstm,我们将一个句子分成比句子长度平方根短的短语,并使用一些非常简单的启发式方法。请注意,用于预分析的结构与以前工作中使用的分析结构非常不同,因为分析结构严重依赖于分析工具,并且容易出错,因此成本更高。

实验
Experimental Setting and Training Details
- 表示模型中隐藏状态的维数为300。词向量使用GloVe 300维词向量(Pennington、Socher和Man-ning 2014)初始化,并与其他参数一起更新。为了平滑策略梯度的更新,将抑制因子乘以公式2并设置为0.1。γ在id-lstm Reward中设置为0.05×K(式6),在hs-lstm Reward中设置为0.1×k(式11),其中K是类别数。
- 在训练过程中,采用Adam算法(Kingma和BA 2015)对参数进行优化,学习率设为0.0005。我们在CNet中在分类层前采用Dropout,概率为0.5。最小批量设为5。
Datasets and Baselines
-
Datasets 我们在各种数据集上评估了我们的模型,用于情感分类、主观性分析和主题分类。
- MR:此数据集包含正面/负面评论(Pang和Lee,2005)。
- SST:Stanford Sentiment Treebank,一个包含五个类别的公共情绪分析数据集
- Subj:主观数据集。任务是将句子分类为主观或客观(庞和李2004)。
- AG:AG的新闻语料库,是一个大型主题分类数据集。主题包括世界,体育,商业和科技。
-
Baselines 我们选择了三种类型的baselines:不使用特定结构的基本神经模型,依赖预先指定解析结构的模型,以及通过attention机制提取重要信息的模型。
- LSTM: 序列LSTM。我们使用的版本在(Tai、Socher和Manning,2015)中提出。
- Bi-LSTM: 双向LSTM,常用于文本分类。
- CNN: 卷积神经网络(Kim 2014)
- RAE(Recursive autoencoder):在预先定义的解析结构上定义的递归自动编码器(Socher等人2011)。
- Tree-LSTM:树结构的LSTM 依赖于预定义的解析结构(tai、socher和manning 2015)。
- Self-Attention:采用结构化的自我注意模型,自我注意机制和特殊的正则化项构造句子嵌入(Lin等。2017)。
-
隐藏向量的维度和这些基线中使用的单词向量与我们的模型相同。其他参数设置与引用一致。
![]()
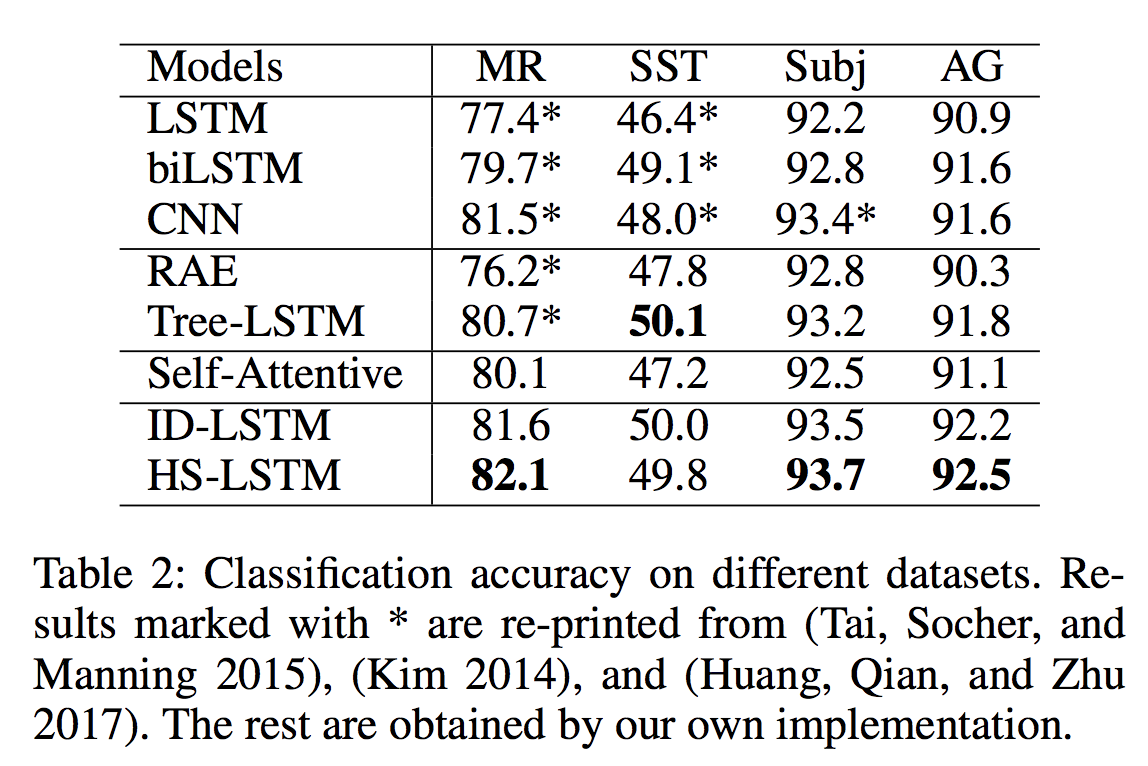
分类结果
表2列出的分类结果表明,我们的模型在不同的数据集和不同的任务之间都具有较好的表现。我们的模型比没有使用结构(LSTM,biLSTM和CNN)的基本模型,使用解析结构(RAE和Tree-LSTM)的模型以及基于attention的模型(Self-Attentive)都要好。与预先指定的解析结构相比,自动发现的结构似乎对分类更友好。这些结果证明了通过发现任务相关结构来学习结构化表示的有效性。
结构分析
为了研究发现的结构及其对分类性能的影响,我们从定性和定量两个角度进行结构分析。

-
ID-LSTM
* 定性分析(Qualitative analysis):ID-LSTM能够有效地去除与任务无关的单词,并且仍然能够提供具有竞争力的性能。如表3所示,id-lstm删除了“and”、“of”和“the”等不相关的词。我们的模型甚至可以删除句子中的连续子序列,例如“than it first set to be”或“the outer limits of”。有趣的是,分类器能够正确地对文本进行分类,即使没有这些无关的词。以情感分类为例,我们观察到ID-LSTM的保留词主要是情感词和否定词,表明该模型可以提取重要的任务相关词。这些例子表明,一个纯化的表示可以有益于分类任务。因此,我们认为并非所有的单词都是特定分类任务所必需的。
![]()
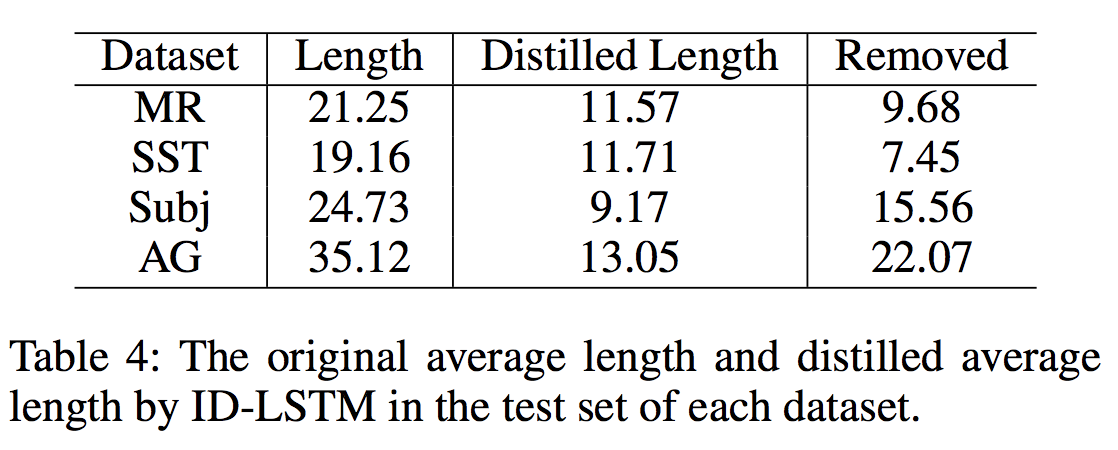
* 定量分析(Quantitative analysis):进一步分析了ID-LSTM去除的无关信息和提取的重要信息。我们比较了每个数据集测试集中id-lstm给出的原始句子长度和蒸馏长度,如表4所示。对于情绪分类,我们分别从mr/sst/subj的句子中删除了大约9.68/7.45/15.56个单词。对于主题分类,我们从ag的句子中删除了大约22个单词(从35.12到13.05)。有趣的是,id-lstm从句子中删除了大约或超过一半的单词。这表明文本分类可以使用高度净化、浓缩的信息来完成。由此推断,这样的分类任务只能用重要的关键字来完成,而我们的模型具有提取这些重要的、与任务相关的关键字的效果。![]()
-
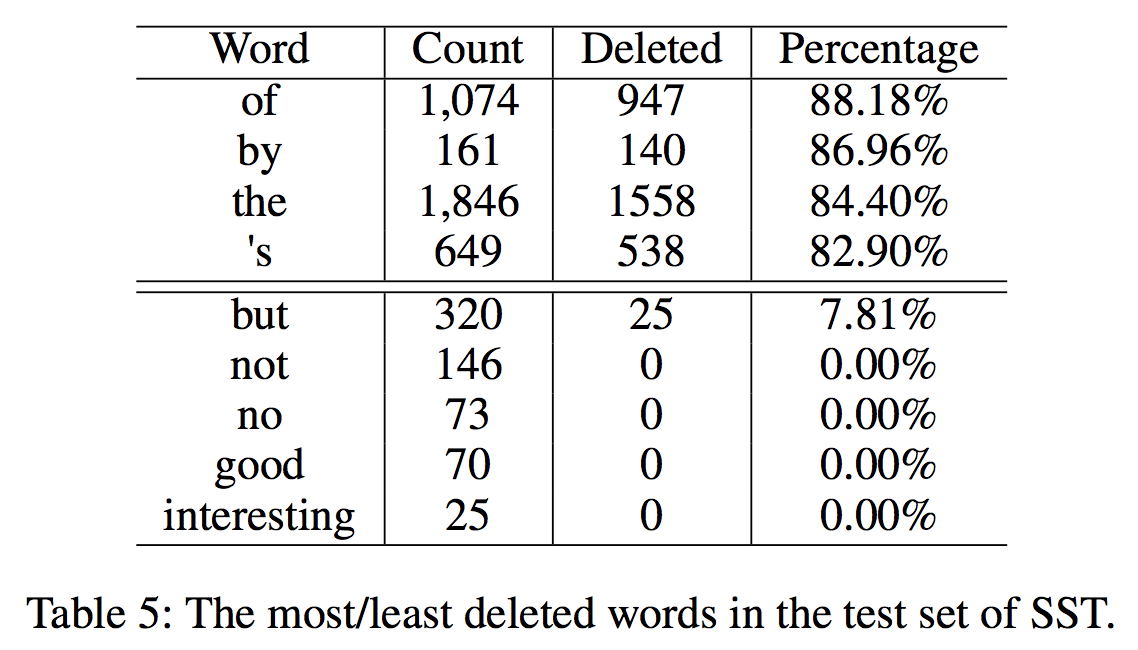
此外, 以情感分类为例,分析了哪些类型的词汇被删除和保留。表5列出了SST数据集中ID-LSTM删除最多和最少的单词,按删除百分比(删除/计数)排序。一方面,删除最多的词是非内容词(介词等),一般与感情分类无关。这表明ID-LSTM能够过滤不相关的单词。另一方面,ID-LSTM能够为任务保留重要的单词。例如,正如我们所知,感情和否定词对于情感分类很重要。如表5所示,“good”和“interesting”等情感词很少被删除。ID-LSTM不会删除“not”或“no”。对于过渡词,“but”出现了320次,只有7.81%被删除。
-
总之,定性和定量分析结果表明,ID-LSTM能够去除句子中不相关的单词,提取与任务相关的单词。ID-LSTM能够有效地提取特定于任务的关键字,而经过纯化、浓缩的表示方法更易于分类。
-
-
HS-LSTM
-
定性分析:表3显示了HS-LSTM发现的一些有趣的结构。在给定的例子中,“much smarter”、“and more attentive”和“an interesting book”等短语是与任务相关的重要短语。我们还发现hs-lstm发现的结构在长度和内容上比传统短语更灵活,因为hs-lstm有时无法找到正确的短语之间的边界。但是,正如我们提到的,对于没有显式结构注释的任何模型来说,这都是非常困难的。
![]()
在表6中,我们列出了一些示例来说明预定义结构(用于预培训)与hs-lstm发现的结构之间的区别。这些例子表明,我们的RL方法学习构建与预先定义的结构完全不同的结构。预定义的结构是用一些非常简单的启发式方法构建的,因此是碎片化的。相比之下,hs-lstm倾向于发现更完整和更长的短语。![]()
然而,hs-lstm确实能够识别具有清晰边界的常见短语类型。我们在表7中列出了hs-lstm发现的不同类型的更多示例。由hs-lstm发现的名词和介词短语通常是长的、有表达性的、与任务相关的。相比之下,动词短语比名词短语短。除了语法短语,我们的模型还发现一些有趣的特殊短语,如表7所示。
-
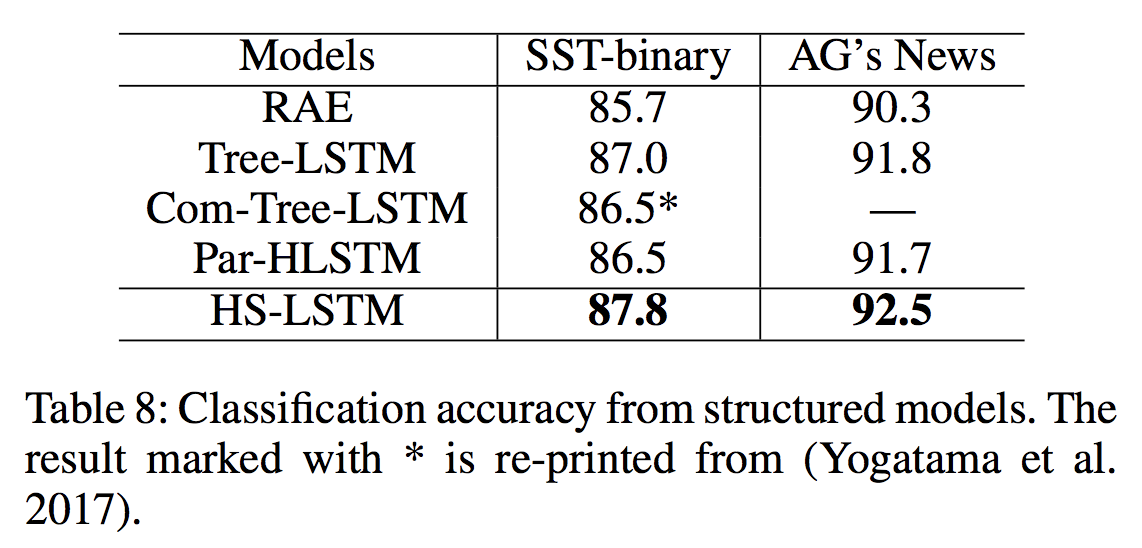
定量分析:首先,我们将HS-LSTM与其他结构化模型进行比较,以调查分类任务是否可以从发现结构中受益。Baselines包括依赖解析结构的模型,以及学习组成深层树结构的Com-Tree-LSTM。我们还比较了Par-HLSTM,它具有相同的结构化表示模型,只是短语结构由斯坦福分析器(Klein and Manning 2003)给出,而不是强化学习。表8中的结果表明,HS-LSTM优于其他结构化模型,表明发现结构可能比用解析器提供的模型更与任务相关且优势更大。
![]()
然后,我们计算了表9中由hs-lstm发现的结构统计数据,包括平均词组数和每个词组的单词数。一个短语中的平均单词数在不同的数据集中是稳定的:每个结构大约有4或5个单词。然而,这可能符合鼓励结构选择的预期(见等式11)。
![]()
-
总之,我们的hs-lstm能够发现与任务相关的结构,然后构建更好的结构化句子表示。定性和定量的结果表明,这些发现的结构是任务友好的,适用于文本分类。
-



结论
本文提出了一种通过发现任务相关结构来学习句子表征的强化学习方法。在RL框架下,我们采用了两种表示模型:ID-LSTM,它提取与任务相关的单词,形成纯句子表示;HS-LSTM,它发现短语结构,形成层次句子表示。大量的实验表明,该方法具有最先进的性能,能够在不需要显式结构注释的情况下发现有趣的任务相关结构。
作为未来的工作,我们将把这种方法应用到其他类型的序列中,因为结构发现(或重新构造输入)的思想可以推广到其他任务和领域。
posted on 2019-06-13 10:57 logicalsky 阅读(1107) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号