

编码小结
1 初识编码
所谓编码,是信息从一种形式或格式转换为另一种形式的过程。
字符编码,从自然语言的字符的一个集合(如字母表或音节表),到其他东西的一个集合(如号码或电脉冲)的映射
ANSI:windows特有,在中国大陆即为GBK (DBCS Double Byte Charecter Set,双字节字符集)
UCS-2:即Unicode,(Universal Multiple-Octet Coded Character Set)
UTF:(UCS Transfer Format,用以存储和传输的格式)
BOM头:纯文本文件开始的几个表示编码格式的字节(Byte Order Mark)
| 编码方式 | BOM |
|---|---|
| UTF-8 | 0xEFBBBF |
| UnicodeBig | 0xFEFF |
| UnicodeSmall | 0xFFFE |
2 关于ANSI
ANSI不是某种特定的编码,而是windows在不同系统中表示不同的编码。
特别地,美国系统就是ASCII编码;韩国系统就是EUC-KR编码;中国系统就是GBK编码。
Winodows怎么区别ANSI背后真正的编码?
Windows code pages,即我们经常见到的cpxxx
cp936表示GBK,cp950表示Big5,cp437表示ASCII
3 系统编码的查看与修改
windows
查看:可在命令行下执行chcp来查看当前的code page
修改终端的active cp:在命令行输入chcp xxx(只在终端起作用,不影响系统默认的ANSI编码)
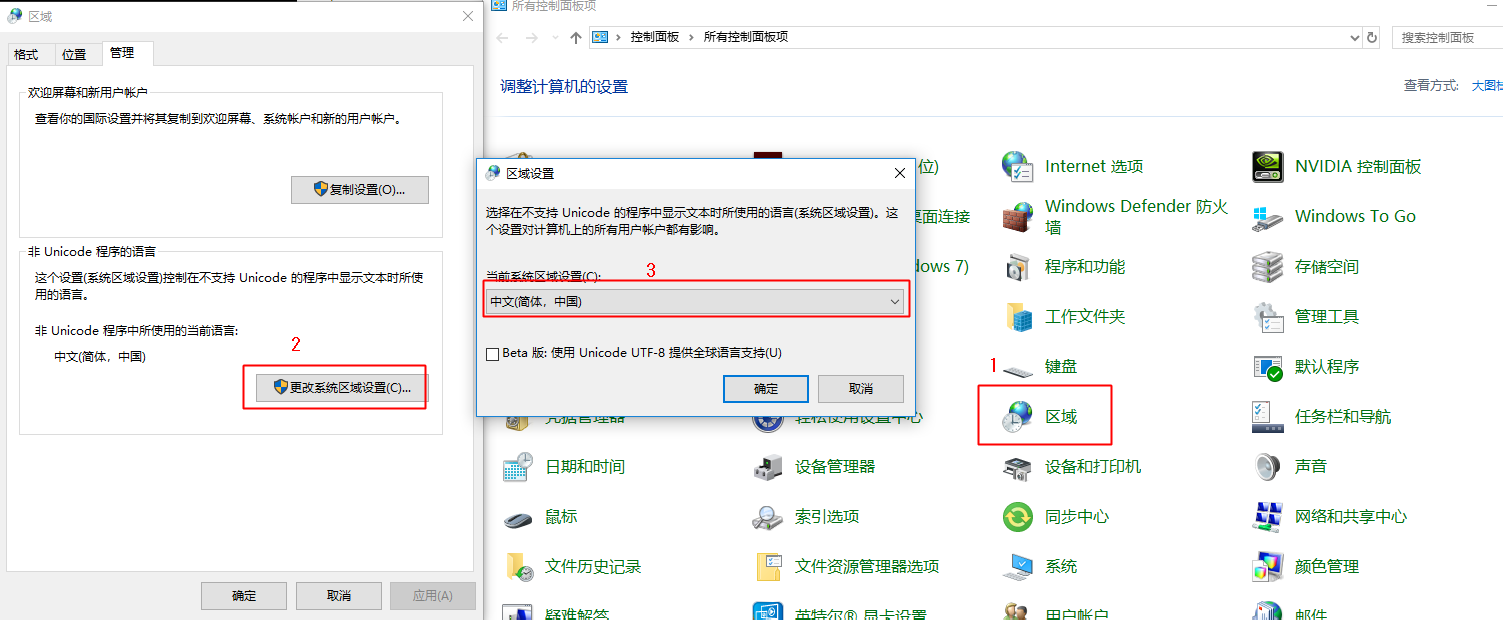
修改系统的cp(根据当前系统的locale来设置,控制面板=>区域=>修改系统区域设置)
Linux
查看:locale
LANGUAGE=
LC_CTYPE="en_US.UTF-8"
LC_NUMERIC=zh_CN.UTF-8
LC_TIME=zh_CN.UTF-8
LC_COLLATE="en_US.UTF-8"
LC_MONETARY=zh_CN.UTF-8
LC_MESSAGES="en_US.UTF-8"
LC_PAPER=zh_CN.UTF-8
LC_NAME=zh_CN.UTF-8
LC_ADDRESS=zh_CN.UTF-8
LC_TELEPHONE=zh_CN.UTF-8
LC_MEASUREMENT=zh_CN.UTF-8
LC_IDENTIFICATION=zh_CN.UTF-8
LC_ALL=
修改:export LC_ALL=zh_CN.GBK
变量优先级
LC_ALL > LC_* >LANG
LANG:所有没有设置的locale变量的默认locale
LANGUAGE:设置应用程序的界面语言
4 国标
区位码
早年的中国编码标准,由4个十进制数字表示一个字符,前两位为"区",后两位为"位"。汉字区号从16开始,位号从1开始。
区位码节选表
01-09区为特殊符号
16-55区为一级汉字,按拼音排序
56-87区为二级汉字,按部首笔画排序
GB2312
基于区位码,用双字节表示汉字和汉字字符,0xA0+区号,0xA0+位号。
以汉字“安”为例
区位码是1618(十进制)
GB2312编码是 0xA0 +16 0xA0 +18 ==> 0xB0 0xB2
GB2312编码范围是0xB0A1~0xF7FE(收录汉字6763+其他字符682)
全角半角
GB编码兼容ASCII,数字2有两个编码。
其中ASCII编码是0x32,由区位码(0218)而来的编码是0xA3B2。
前者单字节的是半角,后者双字节的是全角。
GBK
首字节在0x810xFE,尾字节在0x400xFE,剔除xx7F一条线
GBK和ASCII码区分
ASCII只有0-127(0x00~0x7F),高字节的最高位为0则为ASCII,为1则为中文
GB18030
- 变长编码
- 支持少数民族文字
- 收录范围包括繁体汉字以及日韩汉字
| 单字节 | 0x00-0x7F,与ASCII兼容 |
|---|---|
| 双字节 | 首字节0x81到0xFE,尾字节0x40到0xFE(不包括0x7F),与GBK兼容 |
| 四字节 | 第一个字节0x81到0xFE,第二个字节0x30到0x39,第三个字节0x81-0xFE,第四个字节0x30-0x39 |
5 Unicode与UTF-8
各国编码标准互不兼容,推出统一标准Unicode
两者关系可以类比成区位码同GB2312的关系
绝大多数程序只支持双字节,即UCS-2
UTF-8:针对Unicode的可变长字符编码(多字节串,第一个字节在C0到FD之间,后面的字节在80到BF之间)
Unicode与UTF-8的转换
| Unicode | UTF-8 | 有效位数 | 编码范围 |
|---|---|---|---|
| U-00000000 ~ U-0000007F | 0xxxxxxx | 7 | 0x00-0x7F |
| U-00000080 ~ U-000007FF | 110xxxxx 10xxxxxx | 11 | 0xC080-0xDFBF |
| U-00000800 ~ U-0000FFFF | 1110xxxx 10xxxxxx 10xxxxxx | 16 | 0xE08080-0xEFBFBF |
| U-00010000 ~ U-001FFFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 21 | 0xF0…-0xF7… |
| U-00200000 ~ U-03FFFFFF | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx | 26 | 0xF8…-0xFB… |
| U-04000000 – U-7FFFFFFF | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx | 31 | 0xFC…-0xFD… |
openssl实现(crypto/asn1/a_utf8.c)
- Unicode转UTF-8
int UTF8_putc(unsigned char *str, int len, unsigned long value)
{
if (!str)
len = 6; /* Maximum we will need */
else if (len <= 0)
return -1;
if (value < 0x80) {
if (str)
*str = (unsigned char)value;
return 1;
}
if (value < 0x800) {
if (len < 2)
return -1;
if (str) {
*str++ = (unsigned char)(((value >> 6) & 0x1f) | 0xc0);
*str = (unsigned char)((value & 0x3f) | 0x80);
}
return 2;
}
if (value < 0x10000) {
if (len < 3)
return -1;
if (str) {
*str++ = (unsigned char)(((value >> 12) & 0xf) | 0xe0);
*str++ = (unsigned char)(((value >> 6) & 0x3f) | 0x80);
*str = (unsigned char)((value & 0x3f) | 0x80);
}
return 3;
}
if (value < 0x200000) {
if (len < 4)
return -1;
if (str) {
*str++ = (unsigned char)(((value >> 18) & 0x7) | 0xf0);
*str++ = (unsigned char)(((value >> 12) & 0x3f) | 0x80);
*str++ = (unsigned char)(((value >> 6) & 0x3f) | 0x80);
*str = (unsigned char)((value & 0x3f) | 0x80);
}
return 4;
}
if (value < 0x4000000) {
if (len < 5)
return -1;
if (str) {
*str++ = (unsigned char)(((value >> 24) & 0x3) | 0xf8);
*str++ = (unsigned char)(((value >> 18) & 0x3f) | 0x80);
*str++ = (unsigned char)(((value >> 12) & 0x3f) | 0x80);
*str++ = (unsigned char)(((value >> 6) & 0x3f) | 0x80);
*str = (unsigned char)((value & 0x3f) | 0x80);
}
return 5;
}
if (len < 6)
return -1;
if (str) {
*str++ = (unsigned char)(((value >> 30) & 0x1) | 0xfc);
*str++ = (unsigned char)(((value >> 24) & 0x3f) | 0x80);
*str++ = (unsigned char)(((value >> 18) & 0x3f) | 0x80);
*str++ = (unsigned char)(((value >> 12) & 0x3f) | 0x80);
*str++ = (unsigned char)(((value >> 6) & 0x3f) | 0x80);
*str = (unsigned char)((value & 0x3f) | 0x80);
}
return 6;
}
- UTF-8转Unicode
int UTF8_getc(const unsigned char *str, int len, unsigned long *val)
{
const unsigned char *p;
unsigned long value;
int ret;
if (len <= 0)
return 0;
p = str;
/* Check syntax and work out the encoded value (if correct) */
if ((*p & 0x80) == 0) {
value = *p++ & 0x7f;
ret = 1;
} else if ((*p & 0xe0) == 0xc0) {
if (len < 2)
return -1;
if ((p[1] & 0xc0) != 0x80)
return -3;
value = (*p++ & 0x1f) << 6;
value |= *p++ & 0x3f;
if (value < 0x80)
return -4;
ret = 2;
} else if ((*p & 0xf0) == 0xe0) {
if (len < 3)
return -1;
if (((p[1] & 0xc0) != 0x80)
|| ((p[2] & 0xc0) != 0x80))
return -3;
value = (*p++ & 0xf) << 12;
value |= (*p++ & 0x3f) << 6;
value |= *p++ & 0x3f;
if (value < 0x800)
return -4;
ret = 3;
} else if ((*p & 0xf8) == 0xf0) {
if (len < 4)
return -1;
if (((p[1] & 0xc0) != 0x80)
|| ((p[2] & 0xc0) != 0x80)
|| ((p[3] & 0xc0) != 0x80))
return -3;
value = ((unsigned long)(*p++ & 0x7)) << 18;
value |= (*p++ & 0x3f) << 12;
value |= (*p++ & 0x3f) << 6;
value |= *p++ & 0x3f;
if (value < 0x10000)
return -4;
ret = 4;
} else if ((*p & 0xfc) == 0xf8) {
if (len < 5)
return -1;
if (((p[1] & 0xc0) != 0x80)
|| ((p[2] & 0xc0) != 0x80)
|| ((p[3] & 0xc0) != 0x80)
|| ((p[4] & 0xc0) != 0x80))
return -3;
value = ((unsigned long)(*p++ & 0x3)) << 24;
value |= ((unsigned long)(*p++ & 0x3f)) << 18;
value |= ((unsigned long)(*p++ & 0x3f)) << 12;
value |= (*p++ & 0x3f) << 6;
value |= *p++ & 0x3f;
if (value < 0x200000)
return -4;
ret = 5;
} else if ((*p & 0xfe) == 0xfc) {
if (len < 6)
return -1;
if (((p[1] & 0xc0) != 0x80)
|| ((p[2] & 0xc0) != 0x80)
|| ((p[3] & 0xc0) != 0x80)
|| ((p[4] & 0xc0) != 0x80)
|| ((p[5] & 0xc0) != 0x80))
return -3;
value = ((unsigned long)(*p++ & 0x1)) << 30;
value |= ((unsigned long)(*p++ & 0x3f)) << 24;
value |= ((unsigned long)(*p++ & 0x3f)) << 18;
value |= ((unsigned long)(*p++ & 0x3f)) << 12;
value |= (*p++ & 0x3f) << 6;
value |= *p++ & 0x3f;
if (value < 0x4000000)
return -4;
ret = 6;
} else
return -2;
*val = value;
return ret;
}
6 区分不同编码
- 有BOM头
直接根据BOM头区分
- 没有BOM头
需要大量的编码分析
通常应用会有自己庞大的词库,常见词组编码组合,匹配度越高,越有可能是该编码。
7 Urlencode
不同于上面的编码,上面的编码时字符和数字的对应,url编码是字符替换,将非ASCII字符和一些容易引起问题的字符替换。
uri允许的字符分为保留字符和未保留字符


8 X509证书中DN项的string类型(crypto/asn1/a_mbstr.c)
-
输入编码控制
openssl中定义了以下编码格式 MBSTRING_ASC(ASCII),MBSTRING_BMP(UCS-2),MBSTRING_UNIV(UCS-4), MBSTRING_UTF8(UTF-8) 默认是MBSTRING_ASC,可以在证书请求命令中加-utf8设置为MBSTRING_UTF8 `openssl req -new -key test.key-config test.conf -out test.req -utf8` 注意输入编码格式要跟配置文件实际的编码一致 -
输出编码控制
输出的编码格式由String类型决定
ASN1 String类型 编码 Numeric,Printable,IA5,T61 MBSTRING_ASC BMP MBSTRING_BMP Universal MBSTRING_UNIV UTF8 MBSTRING_UTF8 可以通过配置文件中string_mask控制证书DN项的String类型
string_mask 支持的String类型 default PrintableString, T61String, BMPString pkix PrintableString, BMPString utf8only UTF8Strings nombstr PrintableString, T61String -
openssl中生成证书请求时,String类型的确认
Numeric < Printable < IA5 < T61 < BMP < Universal < UTF8
根据DN项的字符范围,选择最小的符合类型
-
避免证书中出现中文乱码
-
将配置文件转码成UTF-8格式(GBK转UTF-8)
iconv -f GBK -t UTF-8 old.conf -o new.conf -
证书请求时加上-utf8
openssl req -new -key test.key -config new.conf -out test.req -utf8
9 vim中的各种encoding
支持中文编码的基础
- 编译时包含+multi_byte和+iconv两个特性,可以用
:version命令查看
编码设置项
-
encoding(enc)
vim内部的使用编码,影响vim内部的buffer,菜单文本,消息文本等 Unix下默认等于locale,Windows下则是当前code page 只在启动的时候设置一次,建议始终设置为utf-8 -
fileencodings(fencs)
打开文件时,会从此列表中所列选项逐一探测文件编码,并且将fileencoding设置为最终探测到的字符编码方式。最好将unicode放到最前面,latin1放到最后面。 -
fileencoding(fenc)
打开文件时,会根据所识别的编码设置 保存文件时,会根据filecoding的设置值来保存 -
termencoding(tenc)
在终端环境下使用时,用来告诉vim当前终端所使用的编码,用来显示
vim中编码转换
- 打开文件,从fileencoding转成encoding,然后将转换后的内容放到buffer里面。在转换过程中如果含有不支持的字符,会丢失
- 保存文件,相反的过程
- 终端使用vim的时候,将内部编码转换为termencoding显示。如果含有不支持的字符会显示问号,但是不影响编辑。如果没有设置,则直接使用encoding,不转换
推荐设置
:set encoding=utf-8
:set termencoding=utf-8
:set fileencoding=utf-8
:set fileencodings=ucs-bom,utf-8,cp936,gb18030,big5,euc-jp,euc-kr,latin1
fencview
内置的编码识别机制,识别率是很低的
推荐使用fencview,该插件使用词频统计的方式识别编码,正确率非常高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号