

- 基本属性
与顺序容器的差别,按照关键字来保存和访问,而顺序容器是按照容器中的位置来顺序保存和访问。
map:每个元素是一对键值(key-valye)组合;set每个元素只包含关键字。。
每个根据关键字是否可以重复分成两类,又根据关键字是否有序保存分成两类。
map通过关键字而不是位置来访问
set 只想知道一个值是否存在时,set最有用。
map 经典例子—单词计数器
set 想忽略常见单词,用set保存想要忽略的单词。
- 操作
关联容器支持普通与位置无关的操作,不支持构造函数或插入操作这些接收一个元素值和一个数量值的操作。
关联容器还支持一些顺序容器不支持的操作和类型别名。此外,无序容器还提供一些调整哈希性能的操作。
关联容器的迭代器都是双向的。
关联容器的关键字类型必须定义比较的方法,默认使用<运算符。
传递给排序算法的可调用对象,必须满足与关联容器中关键字一样的类型要求。
关键字类型上定义一个严格弱序。
自定义的关键字比较操作比较在尖括号中紧跟着元素类型给出。比较操作类型应该是一种函数指针。
pair的构造函数默认对数据成员进行值初始化。其数据成员是public的,两个成员分别命名为first和second。
初始化方式 p (v1, v2) p={v1, v2} make_pair(v1, v2)
-
类型别名
- key_type
- mapped_type
- value_type 对set等于key_type;对map,pair<const key_type, mapped_type>
map的key也是const的
set的迭代器是const的 -
算法
通常不对关联容器使用泛型算法,可用于只读取元素的算法。
但很多这类算法会用到搜索序列,由于不能通过关键字进行快速查找,所有使用泛型算法几乎总是个坏主意。
实际编程中真要对关联容器使用算法,要么将它当做一个源序列,要么作为一个目的位置。
关联容器insert返回一个pair,包含一个指向具有指定关键字的元素,和一个指示插入是否成功的bool值。
对于允许重复关键字的关联容器,insert操作返回一个指向新元素的迭代器,无需返回一个bool值。
3个版本的erase
非const的map和无序map可以使用下标,如关键字不存在会创建一个元素。
c.at(k) 访问关键词为k的元素,若k不在c中,抛出out_of_range异常。
以上两个返回的是mapped_type,而解引用返回的是value_type
- 访问元素
find(k)查找元素是否存在,返回指向第一个关键字为k元素的迭代器,不存在则尾后
cout(k) 计数 返回关键字等于k的元素的数量
lower_bound(k) 返回一个迭代器,指向第一个关键字不小于k的元素
upper_bound(k) 返回一个迭代器,指向第一个关键字大于k的元素
equal_range(k) 返回一个迭代器pair,表示关键字等于k的元素的范围。不存在则pair两个成员都为end()
1以count和find配合遍历所有关键字为k的元素
2可以lower_bound和upper_bound配合获得所有元素的范围。如关键字不在容器中,lower_bound会返回第一个安全插入点,不影响容器中元素顺序的插入位置
3 qual_range 本质上跟第二种一样。
- 无序容器
- 不是通过比较运算符来组织元素,而是使用hash函数和关键字类型的==运算符
- 在关键字没有明显的序关系的情况下,无序容器是很有用的。或者在某些应用场合维护元素的序的代价非常高贵,此时无序容器也是很有用的。
- 理论上hash技术能获得更好地平均性能,但要达到需要性能测试和调优工作。通常使用无序容器更为简单。
-
管理桶
- 无序容器的性能依赖于哈希函数的质量和桶的数量大小。
| 无序容器管理操作 | |
|---|---|
| c.bucket_count() | 正在使用的桶的数量 |
| c.max_bucket_count() | 容器能容纳的最多的桶的数量 |
| c.bucket_size(n) | 第n个桶中有多少个元素 |
| c.bucket(k) | 关键字为k的元素在哪个桶中 |
| 桶迭代 | |
| local_iterator | 可以访问桶中元素迭代器的类型 |
| const_local_iterator | const版本 |
| c.begin(n), c.end(n) | |
| c.cbegin(n), c.cend(n) | |
| 哈希策略 | |
| c.load_factor() | 每个桶的平均元素数量,返回float |
| c.max_load_factor() | c试图维护的平均桶大小,在需要时会添加新桶 |
| c.rehash(n) | 重组存储,桶数>=n且>size/max_load_factor |
| c.reserve(n) | 重组存储,使得c可以保存n个元素且不必rehash |
自定义类类型的无序容器,必须提供自己版本的hash模板版本,还有比较函数(或==)
树
-
二叉树
- 如果平衡,搜索性能逼近二分查找。相比连续内存空间的二分查找优点是,增删时不需要移动大段的内存数据,甚至通常是常数开销。实际使用的二叉树加上平衡算法。
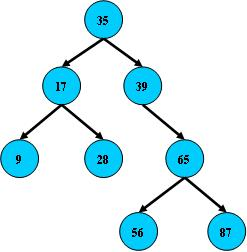
-
红黑树
- 子女个数可以有多个,主要减少io的次数,减小树的层数,同时解决平衡问题,保证至少半满。
- 性能等价与二分查找
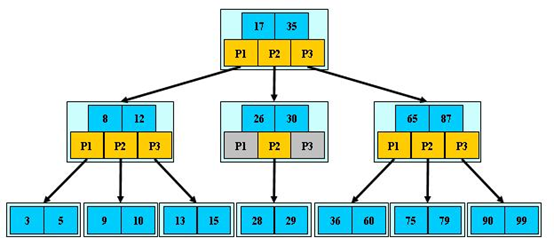
-
B+树
- 内部节点并没有指向具体数据的指针,同一个盘块中可以容纳更多的关键字数量,一次性读入内存的关键字就更多,IO读写次数就降低了。
- 指针指向一个半开区间 [ ),叶子节点之间增加指针,方便遍历或范围查找。
- 所有数据都保存在叶子节点中,保证每次搜索都花费相同的时间,查询效率更稳定。
- 所有关键字都出现在链表中(稠密索引),非叶子节点相当于是叶子节点的索引(稀疏索引),叶子节点相当于是存储数据的数据层。
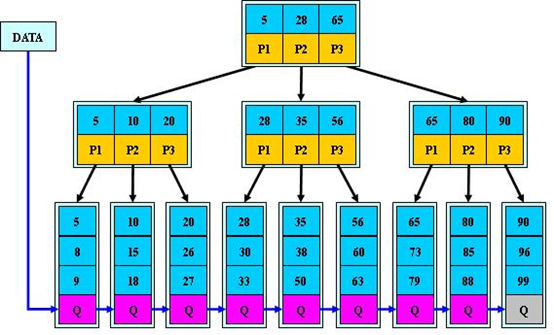
-
B*树
- 至少2/3满,提高块利用率。
- B+树分裂只影响到原结点和父结点,故不需要兄弟指针
- 分配新节点的概率低。
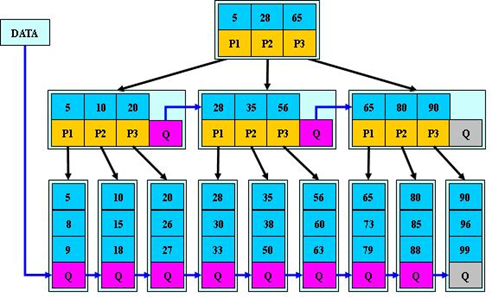
-
R树
- 高维空间的搜索问题,把B树的思想扩展到了多维空间。
- 最小边界矩阵进行空间分割。
- 最佳应用范围是2到6维,更高维的存储会变得非常复杂。
- 变体R*树。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号