weka简单数据分类报告
1.观察数据集:
在weka中打开测试集votetest.arff,观察到数据集共有435个实例,每个实例是一个国会议员的投票信息以及派别,共有17个二元属性,其中一个为类别属性。并且该数据集带有一定的缺失值。国会议员通常按照其党政路线进行投票,本实验通过对议员投票情况(16个属性)对其类别属性进行分类,得到两种派系对政策投票的大致方案。数据集中数据没有与实验无关属性,不进行过滤。
2.使用C4.5决策树算法进行分类训练
C4.5决策树算法能够处理具有缺省值的数据,使用信息增益率作为属性选择标准,能对生成树剪枝(参考《数据挖掘与机器学习--WEKA应用技术与实践》)。C4.5在weka中的实现是J48决策树。选择J48进行分类。
训练结果:
使用C4.5决策树分类器训练数据集(435个实例),得到树形结构如上图所示,共有6个叶子节点。分类模型的准确率为97.2414%,正确分类的实例有423个,Kappa统计量为0.9418,平均绝对误差为0.0519,ROC面积为0.986;混淆矩阵中被错误分类的数据:6个republican被误分为democrat,6个democrat被误分为republican。
测试:使用测试集进行预测
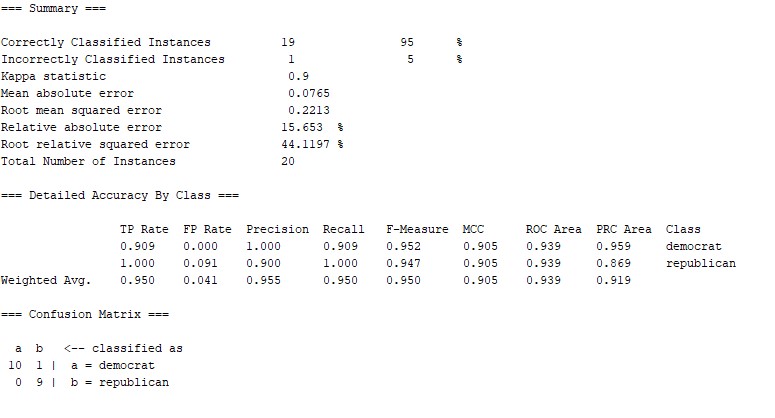
预测结果:
预测准确率为95%,ROC面积为0.939,20个实例中有19个预测正确,一个错误。根据混淆矩阵得:一个republican被错误分类到democrat。
3.基于规则的分类器进行分类训练
分类模型的规则使用析取范式R=(r1 V r2 V … V rk),规则ri的形式:(Condition)->yi,规则左边是属性测试的合取,右边为预测类别。本实验采用的JRip分类器实现了命题规则学习,重复增量修剪以减少产生错误。(参考《数据挖掘与机器学习--WEKA应用技术与实践》)
分类训练构建模型:
训练结果:
分类训练得到的规则共有4个。分类模型的准确率为96.5517%,正确分类的实例有420个,Kappa统计量为0.9277,平均绝对误差为0.0615,ROC面积为0.976;混淆矩阵中被错误分类的数据:10个republican被误分为democrat,5个democrat被误分为republican。
预测:

预测结果:
预测准确率为95%,ROC面积为0.939,20个实例中有19个预测正确,一个错误。根据混淆矩阵得:一个republican被错误分类到democrat。
4.基于K最近邻算法的分类器进行分类训练
通过找出与测试样本相近的训练样本,用最近邻的类别标签确定测试样本的类别标签。IBK分类器是一种k-最邻近分类器,可用多种不同搜索算法加快寻找最近邻。(参考《数据挖掘与机器学习--WEKA应用技术与实践》)
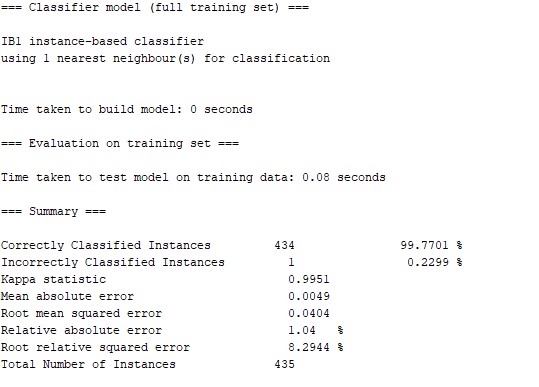
训练结果:
K-最邻近分类模型的准确率为99.7701%,正确分类的实例有434个,Kappa统计量为0.9951,平均绝对误差为0.0049,ROC面积为1.000;混淆矩阵中被错误分类的数据:1个democrat被误分为republican。
预测:
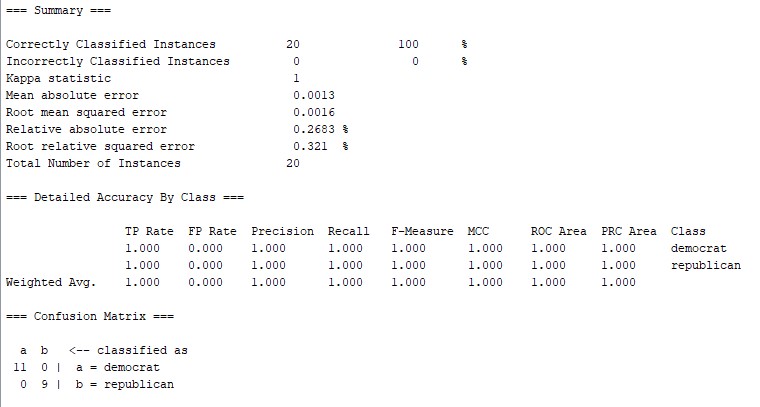
预测结果:对20个实例的预测全部正确,预测正确率为100%。
5、比较
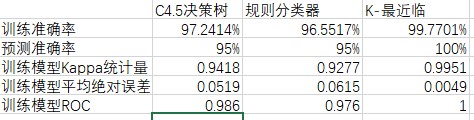
在本实验中KNN算法相比于C4.5决策树、规则分类具有更好的分类效果
6.总结:
根据议员对各个法案的投票,采用KNN算法可以进行更准确的分类,并根据分类模型可以大概率地推测出议员所属党系。一个议员对法案的投票通过与否基本不会偏离所属党派的主要策略。那么一个议员的属性在特征空间里相似的样本中大多属于某一类,则说明其观点大多一致,属于同一党派。KNN算法对这种党派分类与现实符合,从实例具有的全部属性进行判断。而决策树以及规则的分类模型条件划分是对个别属性是否来判断确定,但是对党派的划分条件不应该只根据局部的几个属性进行判断,所以从现实角度看这两种算法也不合适。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号