数据结构与算法 - 希尔排序
希尔排序
希尔排序,它是由 D.L.Shell 于1959 年提出而得名。根据它的名字很难想象算法的核心思想。它的核心思想是把一个序列分组,对分组后的内容进行插入排序,这里的分组只是逻辑上的分组,不会重新开辟存储空间。它其实是插入排序的优化版,插入排序对基本有序的序列性能好,希尔排序利用这一特性把原序列分组,对每个分组进行排序,逐步完成排序。
以 arr = [ 8, 1, 4, 6, 2, 3, 5, 7 ] 为例,通过 floor(8/2) 来分为 4 组,8 表示数组中元素的个数。分完组后,对组内元素进行插入排序。
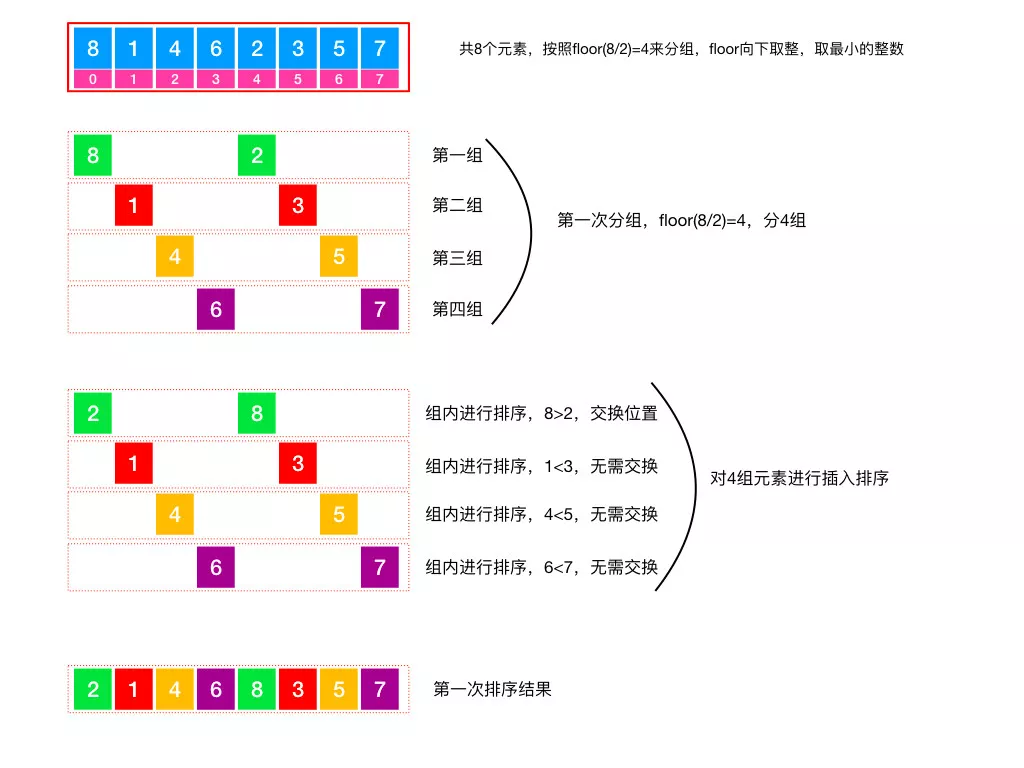
「 利用第 1 次分组结果进行第 2 次分组 」
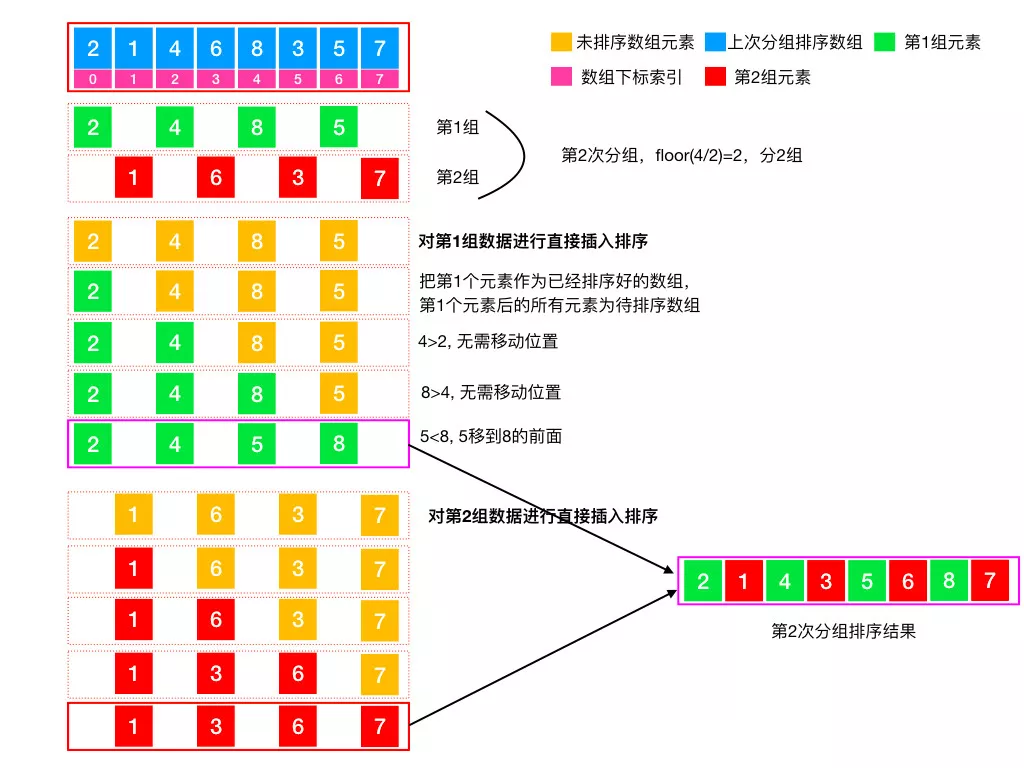
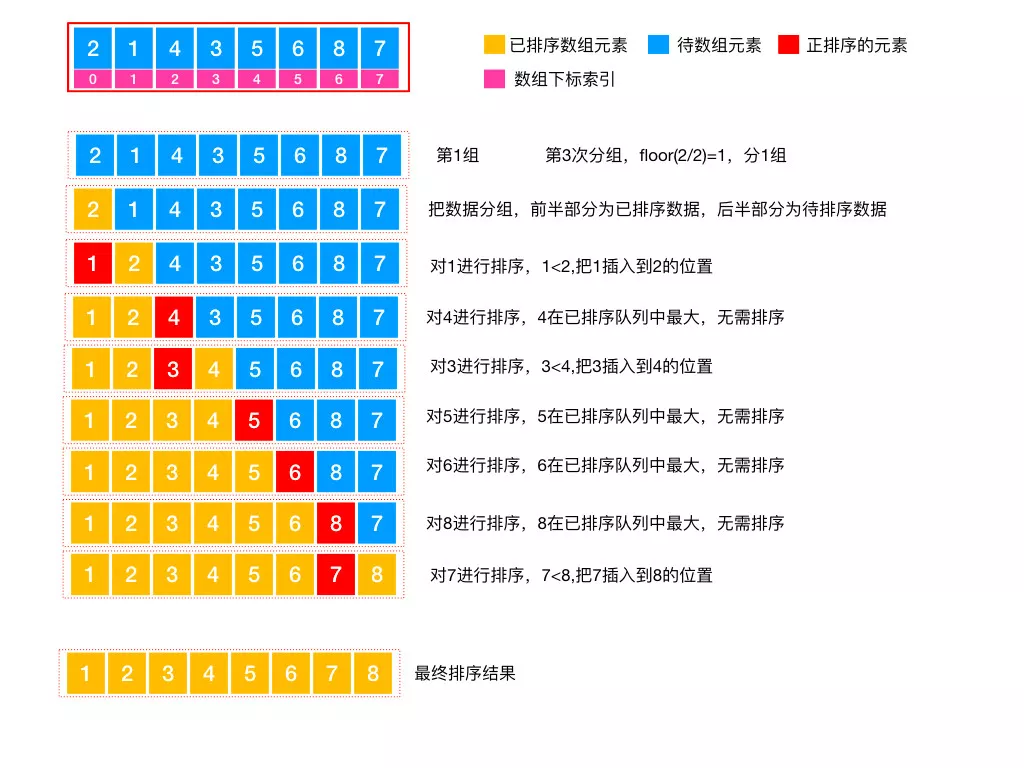
「 利用第 2 次分组结果进行最后一次分组 」
代码实现
#include <iostream>
#include <vector>
#include <priority_queue>
using namespace std;
void shell_sort(vector<int> &nums) {
int len = nums.size();
for(int gap = floor(len/2); gap > 0; gap = floor(gap/2)) {
for(int i = gap; i < len; i++) {
for(int j = i - gap; j >= 0 && nums[j] > nums[j+gap]; j-=gap) {
// swap nums[j] and nums[j+gap]
nums[j] = nums[j] ^ nums[j+gap];
nums[j+gap] = nums[j] ^ nums[j+gap];
nums[j] = nums[j] ^ nums[j+gap];
}
}
}
}
特点
稳定性:它可能会把相同元素分到不同的组中,那么两个相同的元素就有可能调换相对位置,故不稳定。
空间复杂度:由于整个排序过程是在原数据上进行操作,故为 \(O(1)\);
时间复杂度:希尔排序的时间复杂度与增量序列的选取有关,例如希尔增量时间复杂度为\()(n^2)\),而Hibbard增量的希尔排序的时间复杂度为 \(\frac{3}{2}O(\log n)\),希尔排序时间复杂度的下界是 \(n*\log n\)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号